
【Nodejs】1546- 有用的内置 Node.js APIs
前言
在构建你的第一个Node.js应用程序时,了解node开箱即用的实用工具和API是很有帮助的,可以帮助解决常见的用例和开发需求。
有用的Node.js APIs
「Process」:检索有关环境变量、参数、CPU使用情况和报告的信息。 「OS」:检索Node正在运行的操作系统和系统相关信息。比如CPU、操作系统版本、主目录等等。 「Util」:有用和常见方法的集合。用于帮助解码文本、类型检查和对比对象。 「URL」:轻松创建和解析URL。 「File System API」:与文件系统交互。用于创建、读取、更新以及删除文件、目录和权限。 「Events」:用于触发和订阅Node.js中的事件。其工作原理与客户端事件监听器类似。 「Streams」:用于在更小和更容易管理的块中处理大量数据,以避免内存问题。 「Worker Threads」:用来分离不同线程上的函数执行,以避免瓶颈。对于CPU密集型的JavaScript操作很有用。 「Child Processes」:允许你运行子进程,你可以监控并在必要时终止子进程。 「Clusters」:允许你跨核fork任何数量的相同进程,以更有效地处理负载。
Process
process[1]对象提供有关你的Node.js应用程序以及控制方法的信息。可以使用该对象获取诸如环境变量、CPU和内存使用情况等信息。process是全局可用的:你可以在不import的情况下使用它。尽管Node.js文档推荐你显示地引用:
import process from 'process';
process.argv:返回一个数组。该数组的前两个元素是Node.js的可执行路径和脚本名称。索引为2的数组项是传递的第一个参数。process.env:返回包含环境名称与值的键值对对象。比如process.env.NODE_ENV。process.cwd():返回当前的工作目录。process.platform:返回一个识别操作系统的字符串:'aix','darwin'(macOS),'freebsd','linux','openbsd','sunos',或者'win32'(Windows)。process.uptime():返回Node.js进程已运行的秒数。process.cpuUsage():返回当前进程的用户和系统CPU时间的使用情况--例如{ user: 12345, system: 9876 }。将该对象传给该方法,以获得一个相对的读数。process.memoryUsage():返回一个以字节为单位描述内存使用情况的对象。process.version:返回Node.js版本的字符串。比如18.0.0。process.report:生成诊断报告[2]。process.exit(code):退出当前应用程序。使用退出码0来表示成功,或在必要时使用适当的错误代码[3]。
OS
[OS](https://nodejs.org/dist/latest/docs/api/os.html "OS")API与process类似。但它也可以返回有关Node.js运行的操作系统的信息。它提供了诸如操作系统版本、CPU和启动时间等信息。
os.cpus():返回一个包含每个逻辑CPU核信息的对象数组。Clusters部分引用os.cpus()来fork进程。在一个16核CPU中,你会有16个Node.js应用程序的实例在运行以提高性能。os.hostname():操作系统主机名。os.version():标识操作系统内核版本的字符串。os.homedir():用户主目录的完整路径。os.tmpdir():操作系统默认临时文件目录的完整路径。os.uptime():操作系统已运行的秒数。
Util
util[4]模块提供了各种有用的JavaScript方法。其中最有用的是util.promisify(function)[5],该方法接收错误优先类型的回调函数,并返回基于promise的函数。Util模块还可以帮助处理一些常见模式,诸如解码文本、类型检查和检查对象。
util.callbackify(function):接收一个返回promise的函数,并返回一个基于回调的函数。util.isDeepStrictEqual(object1, object2):当两个对象严格相等(所有子属性必须匹配)时返回true。util.format(format, [args]):返回一个使用类printf格式[6]的字符串。util.inspect(object, options):返回一个对象的字符串表示,用于调试。与使用console.dir(object, { depth: null, color: true });类似。util.stripVTControlCharacters(str):剥离字符串中的ANSI转义代码。util.types:为常用的JavaScript和Node.js值提供类型检查。比如:import util from 'util';
util.types.isDate( new Date() ); // true
util.types.isMap( new Map() ); // true
util.types.isRegExp( /abc/ ); // true
util.types.isAsyncFunction( async () => {} ); // true
URL
URL[7]是另一个全局对象,可以让你安全地创建、解析以及修改web URL。它对于从URL中快速提取协议、端口、参数和哈希值非常有用,而不需要借助于正则。比如:
{
href: 'https://example.org:8000/path/?abc=123#target',
origin: 'https://example.org:8000',
protocol: 'https:',
username: '',
password: '',
host: 'example.org:8000',
hostname: 'example.org',
port: '8000',
pathname: '/path/',
search: '?abc=123',
searchParams: URLSearchParams { 'abc' => '123' },
hash: '#target'
}
你可以查看并更改任意属性。比如:
myURL.port = 8001;
console.log( myURL.href );
// https://example.org:8001/path/?abc=123#target
然后可以使用URLSearchParams[8] API修改查询字符串值。比如:
myURL.searchParams.delete('abc');
myURL.searchParams.append('xyz', 987);
console.log( myURL.search );
// ?xyz=987
还有一些方法可以将文件系统路径转换[9]为URL,然后再转换[10]回来。
`dns`[11]模块提供名称解析功能,因此你可以查询IP地址、名称服务器、TXT记录和其他域名信息。
File System API
fs[12] API可以创建、读取、更新以及删除文件、目录以及权限。最近发布的Node.js运行时在fs/promises中提供了基于promise的函数,这使得管理异步文件操作更加容易。
你将经常把fs和path结合起来使用,以解决不同操作系统上的文件名问题。
下面的例子模块使用stat和access方法返回一个有关文件系统对象的信息:
// fetch file information
import { constants as fsConstants } from 'fs';
import { access, stat } from 'fs/promises';
export async function getFileInfo(file) {
const fileInfo = {};
try {
const info = await stat(file);
fileInfo.isFile = info.isFile();
fileInfo.isDir = info.isDirectory();
}
catch (e) {
return { new: true };
}
try {
await access(file, fsConstants.R_OK);
fileInfo.canRead = true;
}
catch (e) {}
try {
await access(file, fsConstants.W_OK);
fileInfo.canWrite = true;
}
catch (e) {}
return fileInfo;
}
当传递一个文件名时,该函数返回一个包含该文件信息的对象。比如:
{
isFile: true,
isDir: false,
canRead: true,
canWrite: true
}
filecompress.js主脚本使用path.resolve()将命令行上传递的输入和输出文件名解析为绝对文件路径,然后使用上面的getFileInfo()获取信息:
#!/usr/bin/env node
import path from 'path';
import { readFile, writeFile } from 'fs/promises';
import { getFileInfo } from './lib/fileinfo.js';
// check files
let
input = path.resolve(process.argv[2] || ''),
output = path.resolve(process.argv[3] || ''),
[ inputInfo, outputInfo ] = await Promise.all([ getFileInfo(input), getFileInfo(output) ]),
error = [];
上述代码用于验证路径,必要时以错误信息终止:
// use input file name when output is a directory
if (outputInfo.isDir && outputInfo.canWrite && inputInfo.isFile) {
output = path.resolve(output, path.basename(input));
}
// check for errors
if (!inputInfo.isFile || !inputInfo.canRead) error.push(`cannot read input file ${ input }`);
if (input === output) error.push('input and output files cannot be the same');
if (error.length) {
console.log('Usage: ./filecompress.js [input file] [output file|dir]');
console.error('\n ' + error.join('\n '));
process.exit(1);
}
然后用readFile()将整个文件读成一个名为content的字符串:
// read file
console.log(`processing ${ input }`);
let content;
try {
content = await readFile(input, { encoding: 'utf8' });
}
catch (e) {
console.log(e);
process.exit(1);
}
let lengthOrig = content.length;
console.log(`file size ${ lengthOrig }`);
然后JavaScript正则表达式会删除注释和空格:
// compress content
content = content
.replace(/\n\s+/g, '\n') // trim leading space from lines
.replace(/\/\/.*?\n/g, '') // remove inline // comments
.replace(/\s+/g, ' ') // remove whitespace
.replace(/\/\*.*?\*\//g, '') // remove /* comments */
.replace(/<!--.*?-->/g, '') // remove <!-- comments -->
.replace(/\s*([<>(){}}[\]])\s*/g, '$1') // remove space around brackets
.trim();
let lengthNew = content.length;
产生的字符串用writeFile()输出到一个文件,并有一个状态信息展示保存情况:
let lengthNew = content.length;
// write file
console.log(`outputting ${output}`);
console.log(`file size ${ lengthNew } - saved ${ Math.round((lengthOrig - lengthNew) / lengthOrig * 100) }%`);
try {
content = await writeFile(output, content);
}
catch (e) {
console.log(e);
process.exit(1);
}
使用示例HTML文件运行项目代码:
node filecompress.js ./test/example.html ./test/output.html
Events
当发生一些事情时,你经常需要执行多个函数。比如说,一个用户注册你的app,因此代码必须添加新用户的详情到数据库中,开启一个新登录会话,并发送一个欢迎邮件。
// example pseudo code
async function userRegister(name, email, password) {
try {
await dbAddUser(name, email, password);
await new UserSession(email);
await emailRegister(name, email);
}
catch (e) {
// handle error
}
}
这一系列的函数调用与用户注册紧密相连。进一步的活动会引起进一步的函数调用。比如说:
// updated pseudo code
try {
await dbAddUser(name, email, password);
await new UserSession(email);
await emailRegister(name, email);
await crmRegister(name, email); // register on customer system
await emailSales(name, email); // alert sales team
}
你可以在这个单一的、不断增长的代码块中管理几十个调用。
Events[13] API提供了一种使用发布订阅模式构造代码的替代方式。userRegister()函数可以在用户的数据库记录被创建后触发一个事件--也许名为newuser。
任意数量的事件处理函数都可以订阅和响应newuser事件;这不需要改变userRegister()函数。每个处理器都是独立运行的,所以它们可以按任意顺序执行。
客户端JavaScript中的事件
事件和处理函数经常在客户端JavaScript中使用。比如说,当用户点击一个元素时运行函数:
// client-side JS click handler
document.getElementById('myelement').addEventListener('click', e => {
// output information about the event
console.dir(e);
});
在大多数情况下,你要为用户或浏览器事件附加处理器,尽管你可以提出你自己的自定义事件[14]。Node.js的事件处理在概念上是相似的,但API是不同的。
发出事件的对象必须是Node.js EventEmitter类的实例。这些对象有一个emit()方法来引发新的事件,还有一个on()方法来附加处理器。
事件示例项目[15]提供了一个类,该类可以在预定的时间间隔内触发一个tick事件。./lib/ticker.js模块导出一个default class,并extends EventEmitter:
// emits a 'tick' event every interval
import EventEmitter from 'events';
import { setInterval, clearInterval } from 'timers';
export default class extends EventEmitter {
其constructor必须调用父构造函数。然后传递delay参数到start()方法:
constructor(delay) {
super();
this.start(delay);
}
start()方法检查delay是否有效,如有必要会重置当前的计时器,并设置新的delay属性:
start(delay) {
if (!delay || delay == this.delay) return;
if (this.interval) {
clearInterval(this.interval);
}
this.delay = delay;
然后它启动一个新的间隔计时器,运行事件名称为"tick"的emit()方法。该事件的订阅者会收到一个包含延迟值和Node.js应用程序启动后秒数的对象:
// start timer
this.interval = setInterval(() => {
// raise event
this.emit('tick', {
delay: this.delay,
time: performance.now()
});
}, this.delay);
}
}
主event.js入口脚本导入了该模块,并设置了一秒钟的delay时段(1000毫秒)。
// create a ticker
import Ticker from './lib/ticker.js';
// trigger a new event every second
const ticker = new Ticker(1000);
它附加了每次tick事件发生时触发的处理函数:
// add handler
ticker.on('tick', e => {
console.log('handler 1 tick!', e);
});
// add handler
ticker.on('tick', e => {
console.log('handler 2 tick!', e);
});
第三个处理器仅使用once()方法对第一个tick事件进行触发:
// add handler
ticker.once('tick', e => {
console.log('handler 3 tick!', e);
});
最后,输出当前监听器的数量:
// show number of listenersconsole.log(`listeners: ${ // show number of listeners
console.log(`listeners: ${ ticker.listenerCount('tick') }`);
使用node event.js运行代码。
输出显示处理器3触发了一次,而处理器1和2在每个tick上运行,直到应用程序被终止。
Streams
上面的文件系统示例代码在输出最小化的结果之前将整个文件读入内存。如果文件大于可用的RAM怎么办?Node.js应用程序将以"内存不足(out of memory)"错误失败。
解决方案是流。这将在更小、更容易管理的块中处理传入的数据。流可以做到:
可读:从文件、HTTP请求、TCP套接字、标准输入等读取。 可写:写入到文件、HTTP响应、TCP套接字、标准输出等。 双工:既可读又可写的流。 转换:转换数据的双工流。
每块数据都以Buffer对象[16]的形式返回,它代表一个固定长度的字节序列。你可能需要将其转换为字符串或其他适当的类型进行处理。
该示例代码有一个filestream[17]项目,它使用一个转换流来解决filecompress项目中的文件大小问题。和以前一样,它在声明一个继承Transform的Compress类之前,接受并验证了输入和输出的文件名:
import { createReadStream, createWriteStream } from 'fs';
import { Transform } from 'stream';
// compression Transform
class Compress extends Transform {
constructor(opts) {
super(opts);
this.chunks = 0;
this.lengthOrig = 0;
this.lengthNew = 0;
}
_transform(chunk, encoding, callback) {
const
data = chunk.toString(), // buffer to string
content = data
.replace(/\n\s+/g, '\n') // trim leading spaces
.replace(/\/\/.*?\n/g, '') // remove // comments
.replace(/\s+/g, ' ') // remove whitespace
.replace(/\/\*.*?\*\//g, '') // remove /* comments */
.replace(/<!--.*?-->/g, '') // remove <!-- comments -->
.replace(/\s*([<>(){}}[\]])\s*/g, '$1') // remove bracket spaces
.trim();
this.chunks++;
this.lengthOrig += data.length;
this.lengthNew += content.length;
this.push( content );
callback();
}
}
当一个新的数据块准备好时,_transform方法被调用。它以Buffer对象的形式被接收,并被转换为字符串,被最小化,并使用push()方法输出。一旦数据块处理完成,一个callback()函数就会被调用。
应用程序启动了文件读写流,并实例化了一个新的compress对象:
// process streamconst readStream = createReadStream(input), wr// process stream
const
readStream = createReadStream(input),
writeStream = createWriteStream(output),
compress = new Compress();
console.log(`processing ${ input }`)
传入的文件读取流定义了.pipe()方法,这些方法通过一系列可能(或可能不)改变内容的函数将传入的数据输入。在输出到可写文件之前,数据通过compress转换进行管道输送。一旦流结束,最终on('finish')事件处理函数就会执行:
readStream.pipe(compress).pipe(writeStream).on('finish', () => {
console.log(`file size ${ compress.lengthOrig }`); console.log(`output ${ output }`); console.log(`chunks readStream.pipe(compress).pipe(writeStream).on('finish', () => {
console.log(`file size ${ compress.lengthOrig }`);
console.log(`output ${ output }`);
console.log(`chunks ${ compress.chunks }`);
console.log(`file size ${ compress.lengthNew } - saved ${ Math.round((compress.lengthOrig - compress.lengthNew) / compress.lengthOrig * 100) }%`);
});
使用任意大小的HTML文件的例子运行项目代码:
node filestream.js ./test/example.html ./test/output.html
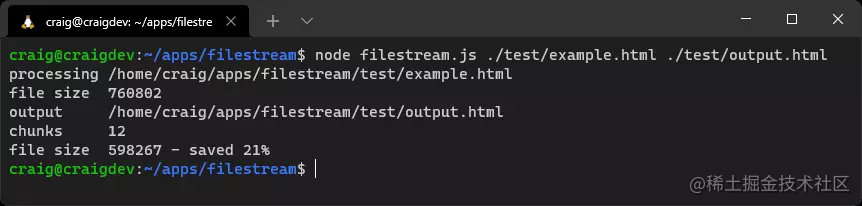
这是对Node.js流的一个小例子。流处理是一个复杂的话题,你可能不经常使用它们。在某些情况下,像Express这样的模块在引擎盖下使用流,但对你的复杂性进行了抽象。
你还应该注意到数据分块的挑战。一个块可以是任何大小,并以不便的方式分割传入的数据。考虑对这段代码最小化:
<script type="module">
// example script
console.log('loaded');
</script>
两个数据块可以依次到达:
<script type="module">
// example
以及:
<script>
console.log('loaded');
</script>
独立处理每个块的结果是以下无效的最小化脚本:
<script type="module">script console.log('loaded');</script>
解决办法是预先解析每个块,并将其分割成可以处理的整个部分。在某些情况下,块(或块的一部分)将被添加到下一个块的开始。
尽管会出现额外的复杂情况,但是最好将最小化应用于整行。因为<!-- -->和/* */注释可以跨越不止一行。下面是每个传入块的可能算法:
将先前块中保存的任何数据追加到新块的开头。 从数据块中移除任意整个 <!--到-->以及/*到*/部分。将剩余块分为两部分。其中 part2以发现的第一个<!--或/*开始。如果两者都存在,则从part2中删除除该符号以外的其他内容。如果两者都没有找到,则在最后一个回车符处进行分割。如果没有找到,将part1设为空字符串,part2设为整个块。如果part2变得非常大--也许超过100,000个字符,因为没有回车符--将part2追加到part1,并将part2设为空字符串。这将确保被保存的部分不会无限地增长。缩小和输出 part1。保存 part2(它被添加到下一个块的开始)。
该过程对每个传入的数据块都会再次运行。
Worker Threads
官方文档[18]是这么说的:Workers(线程)对于执行CPU密集型的JavaScript操作很有用。它们对I/O密集型的工作帮助不大。Node.js内置的异步I/O操作比Workers的效率更高。
假设一个用户可以在你的Express应用程序中触发一个复杂的、十秒钟的JavaScript计算。该计算将成为一个瓶颈,使所有用户的处理程序停止。你的应用程序不能处理任何请求或运行其他功能,除非它计算完成。
异步计算
处理来自文件或数据库数据的复杂计算可能问题不大,因为每个阶段在等待数据到达时都是异步运行。数据处理发生在事件循环的不同迭代中。
然而,仅用JavaScript编写的长运行计算,比如图像处理或机器学习算法,将占用事件循环的当前迭代。
一种解决方案就是worker线程。这类似于浏览器的web worker以及在独立线程上启动JavaScript进程。主线程和worker线程可以交换信息来触发或者终止程序。
Workers和事件循环
Workers对CPU密集型JavaScript操作很有用,尽管Node.js的主事件循环仍应用于异步I/O活动。
示例代码有一个worker项目[19],其在lib/dice.js中导出diceRun()函数。这是将任意数量的N面骰子投掷若干次,并记录总分的计数(应该是正态分布曲线的结果):
// dice throwing
export function diceRun(runs = 1, dice = 2, sides = 6) {
const stat = [];
while (runs > 0) {
let sum = 0;
for (let d = dice; d > 0; d--) {
sum += Math.floor( Math.random() * sides ) + 1;
}
stat[sum] = (stat[sum] || 0) + 1;
runs--;
}
return stat;
}
index.js中的代码启动一个进程,每秒钟运行一次并输出一条信息:
// run process every second
const timer = setInterval(() => {
console.log(' another process');
}, 1000);
调用diceRun()函数,将两个骰子抛出10亿次:
import { diceRun } from './lib/dice.js';
// throw 2 dice 1 billion times
const
numberOfDice = 2,
runs = 999_999_999;
const stat1 = diceRun(runs, numberOfDice);
这将暂停计时器,因为Node.js事件循环在计算完成之前不能继续下一次迭代。
然后,将上述代码在一个新的Worker中尝试相同的计算。这会加载一个名为worker.js的脚本,并在配置对象上的workerData属性传递计算参数:
import { Worker } from 'worker_threads';
const worker = new Worker('./worker.js', { workerData: { runs, numberOfDice } });
事件处理器被附加到运行worker.js脚本的worker对象上,以便它能接收传入的结果:
// result returned
worker.on('message', result => {
console.table(result);
});
以及处理错误:
// worker error
worker.on('error', e => {
console.log(e);
});
以及在处理完成后进行整理:
// worker complete
worker.on('exit', code => {
// tidy up
});
worker.js脚本启动diceRun()计算,并在计算完成后向父脚本发布一条消息--该消息由上面的message处理器接收:
// worker threadimport { workerData, parentPort } from 'worker_threads';import { diceRun } from './lib/dice.js';
// worker thread
import { workerData, parentPort } from 'worker_threads';
import { diceRun } from './lib/dice.js';
// start calculation
const stat = diceRun( workerData.runs, workerData.numberOfDice );
// post message to parent script
parentPort.postMessage( stat );
在worker运行时,计时器并没有暂停,因为它是在另一个CPU线程上执行的。换句话说,Node.js的事件循环继续迭代,而没有长延迟。
使用node index.js运行项目代码。
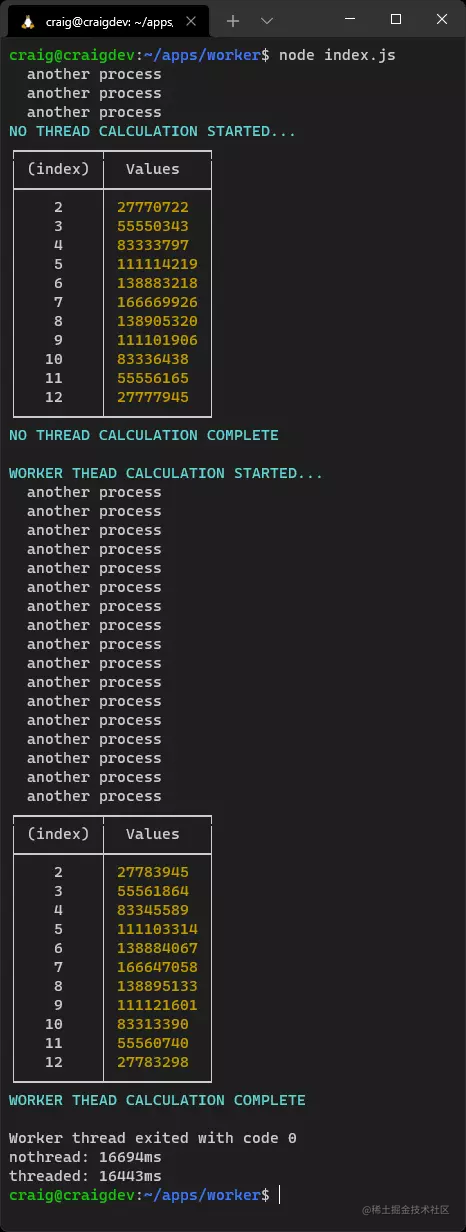
你应该注意到了,基于worker的计算运行速度稍快,因为线程完全专用于该进程。如果你的应用程序中遇到性能瓶颈,请考虑使用worker。
Child Processes
有时需要调用那些不是用Node.js编写的或者有失败风险的应用程序。
真实案例
我写过一个Express应用程序,该程序生成了一个模糊的图像哈希值,用于识别类似的图形。它以异步方式运行,并且运行良好,直到有人上传了一个包含循环引用的畸形GIF(动画帧A引用了帧B,而帧B引用了帧A)。
哈希值的计算永不结束。该用户放弃了并尝试再次上传。一次又一次。整个应用程序最终因内存错误而崩溃。
该问题通过在子进程中运行散列算法最终被解决。Express应用程序保持稳定,因为它启动、监控并在计算时间过长时终止了计算。
child process API[20]允许你运行子进程,如有必要你可以监控并终止。这里有三个选项:
spawn:生成子进程。fork:特殊类型的spawn,可以启动一个新的Node.js进程。exec:生成shell并运行一条命令。运行结果被缓冲,当进行结束时返回一个回调函数。
不像worker线程,子进程独立于Node.js主脚本,并且无法访问相同的内存。
Clusters
当你的Node.js应用程序在单核上运行时,你的64核服务器CPU是否没有得到充分利用?Cluster[21]允许你fork任何数量的相同进程来更有效地处理负载。
对于os.cpus()返回的每个CPU,初始的主进程可能会fork自己一次。当一个进程失败时,它也可以处理重启,并在fork的进程之间代理通信信息。
集群的工作效果惊人,但你的代码可能变得复杂。更简单和更强大的选择包括:
进程管理器比如PM2[22],它提供了一个自动集群模式 容器管理系统,如Docker[23]或Kubernetes[24]
都可以启动、监控和重启同一个Node.js应用程序的多个独立实例。即使有一个失败了,该应用程序也会保持活动状态。
总结
本文提供了一个比较有用的Node.js API的例子,但我鼓励你浏览文档,自己去发现它们。文档总体上是好的,并展示了简单的例子,但它在某些地方可能是简略的。
以上就是本文的所有内容,如果对你有所帮助,欢迎点赞收藏转发~
本文译自:https://www.sitepoint.com/useful-built-in-node-js-apis/ 作者:Craig Buckler
参考资料
process: https://nodejs.org/dist/latest/docs/api/process.html
[2]诊断报告: https://nodejs.org/dist/latest/docs/api/report.html
[3]错误代码: https://nodejs.org/dist/latest/docs/api/process.html#exit-codes
[4]util: https://nodejs.org/dist/latest/docs/api/util.html
[5]util.promisify(function): https://nodejs.org/dist/latest/docs/api/util.html#utilpromisifyoriginal
[6]args])`:返回一个使用[类printf格式: https://en.wikipedia.org/wiki/Printf_format_string
[7]URL: https://nodejs.org/dist/latest/docs/api/url.html
[8]URLSearchParams: https://nodejs.org/dist/latest/docs/api/url.html#class-urlsearchparams
[9]转换: https://nodejs.org/dist/latest/docs/api/url.html#urlpathtofileurlpath
[10]转换: https://nodejs.org/dist/latest/docs/api/url.html#urlfileurltopathurl
[11]dns: https://nodejs.org/dist/latest/docs/api/dns.html
fs: https://nodejs.org/dist/latest/docs/api/fs.html
[13]Events: https://nodejs.org/dist/latest/docs/api/events.html
[14]自定义事件: https://developer.mozilla.org/zh-CN/docs/Web/API/CustomEvent
[15]事件示例项目: https://github.com/spbooks/ultimatenode1/tree/main/ch12/event
[16]Buffer对象: https://nodejs.org/dist/latest/docs/api/buffer.html
[17]filestream: https://github.com/spbooks/ultimatenode1/tree/main/ch12/filestream
[18]官方文档: https://nodejs.org/api/worker_threads.html#worker-threads
[19]worker项目: https://github.com/spbooks/ultimatenode1/tree/main/ch12/worker
[20]child process API: https://nodejs.org/dist/latest/docs/api/child_process.html
[21]Cluster: https://nodejs.org/dist/latest/docs/api/cluster.html
[22]PM2: https://pm2.keymetrics.io/
[23]Docker: https://www.docker.com/
[24]Kubernetes: https://kubernetes.io/