
腾讯云超火开源数据库产品架构揭秘
Redis&Tendis
Tendis混合存储版整体架构
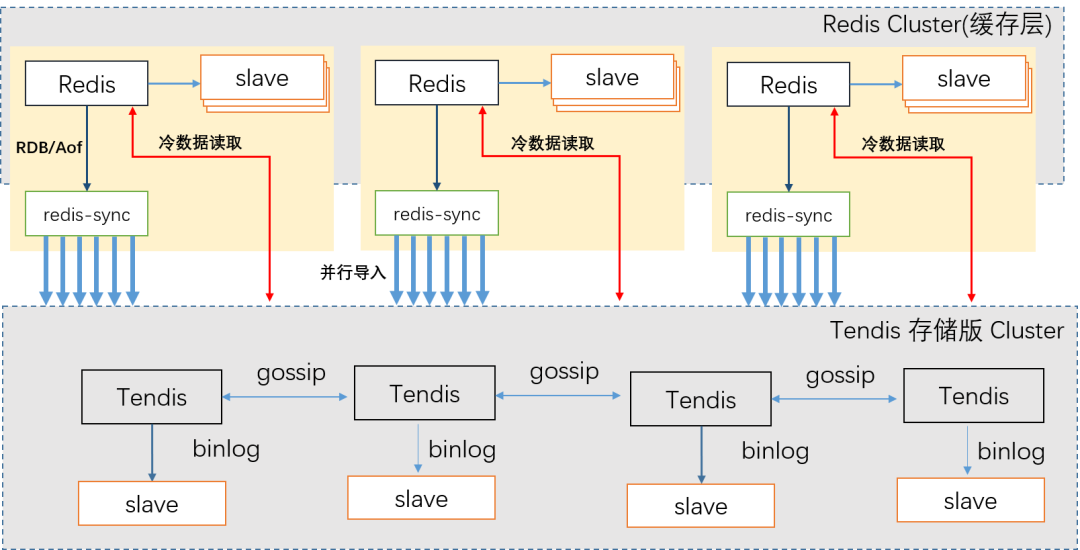
缓存层Redis Cluster
一、版本控制
如下所示, 在 redisObject 中添加 64bits, 其中 48bits 用于版本控制。
typedef struct redisObject {unsigned type:4;unsigned encoding:4;unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or* LFU data (least significant 8 bits frequency* and most significant 16 bits access time). */int refcount;/* for hybrid storage */unsigned flag:4; /* OBJ_FLAG_... */unsigned reserved:4;unsigned counter:8; /* for cold-data-cache-policy */unsigned long long revision:REVISION_BITS; /* for value version */void *ptr;} robj;
2020 年 6 月份上线的 1:1 版的冷热混合存储, 缓存层 Redis 存储全量的 Keys 和热 Values(All Keys + Hot values), 存储层 Tendis 存储全量的 Keys 和 Values(All Keys + All values)。在上线运行了一段时间后, 发现全量 Keys 的内存开销特别大, 冷热混合的收益并不明显。为了进一步释放内存空间, 提高缓存的效率, 我们放弃了 Redis 缓存全量 Keys 的方案, 驱逐的时候将 key 和 Value 都从缓存层淘汰。
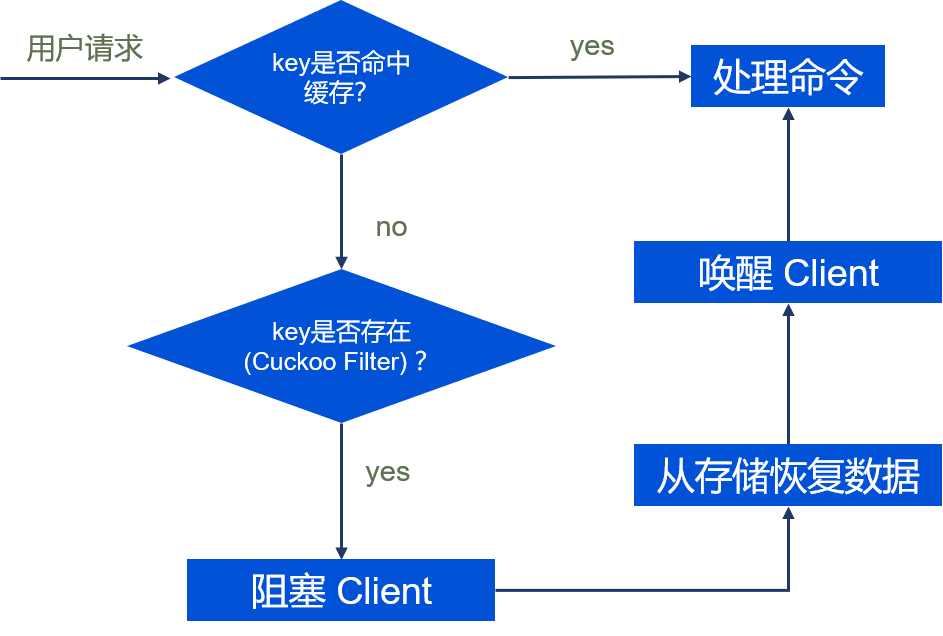
如果缓存层不存储全量的 Keys, 就会出现缓存击穿和缓存穿透的问题。为了解决这一问题, 缓存层引入 Cuckoo Filter 表示全量的 keys 。我们需要一个支持删除、可动态伸缩并且空间利用率高的 Membership Query 结构, 经过我们的调研和对比,最终选择 Dynamic Cuckoo Filter。
项目初期参考了 RedisBloom 中 Cuckoo Filter 的实现, 在开发的过程中也遇到了一些坑,RedisBloom 实现的 Cuckoo Filter 在删除的时候会出现误删, 最终给 RedisBloom 提 PR 修复了问题。
最终采用将 Key 和 Value 同时从缓存层淘汰, 降低内存的收益很大。比如现网的一个业务, 总共有 6620 W 个 Keys , 在缓存全量 Keys 的时候 占用 18408 MB的内存, 在 Key 降冷后 仅仅占用 593MB 。
当缓存层 Redis 内存使用到达 maxmemory, 系统将按照 maxmemory-policy 的内存策略将 Key/Value 从缓存层驱逐, 释放内存空间。(驱逐是指将 Key/Value 从缓存层中淘汰掉, 存储层 和 缓存层的 Cuckoo Filter 依然存在该 Key;
如果配置 value-eviction-policy, 后台会定期将用户 N 天未访问的 Key/Value 被驱逐出内存;
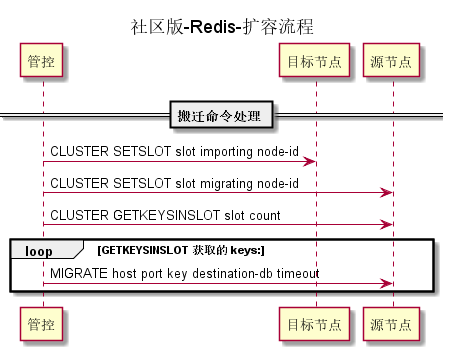
2) 管控端向目标节点下发slot同步命令: cluster slotsync beginSlot endSlot [[beginSlot endSlot]...]
3) 目标节点向源节点发送 sync [slot ...], 命令请求同步slot数据
4) 源节点生成指定 slot 数据的一致性快照全量数据(RDB), 并将其发送给目标节点
5) 源节点开始持续发送增量数据(Aof)
6) 管控端定位获取源节点和目标节点的落后值 (diff_bytes), 如果落后值在指定的阈值内, 管控端向目标节点发送 cluster slotfailover (流程类似 Redis 的 cluster failover, 首先阻塞源节点写入, 然后等待目标节点和源节点的落后值为 0, 最后将 搬迁的 slots 归属目标节点)
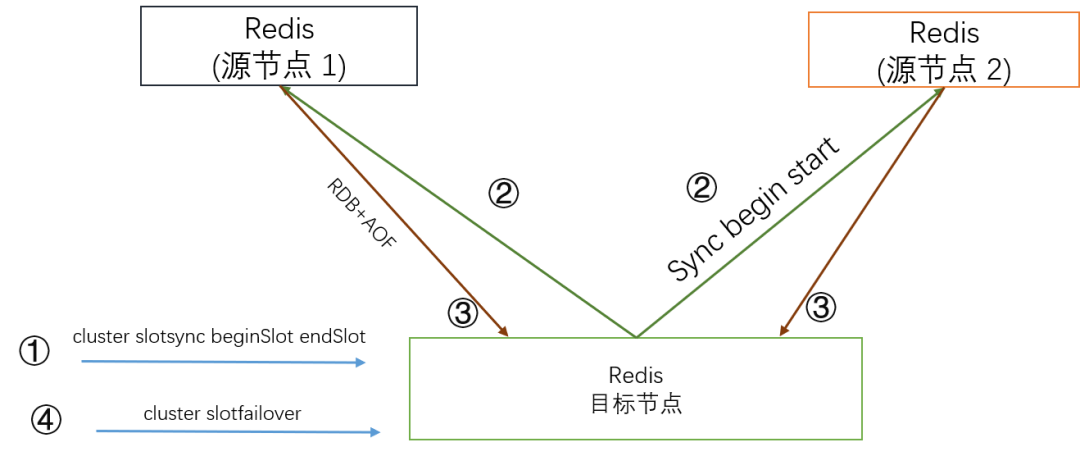
同步层 Redis-sync
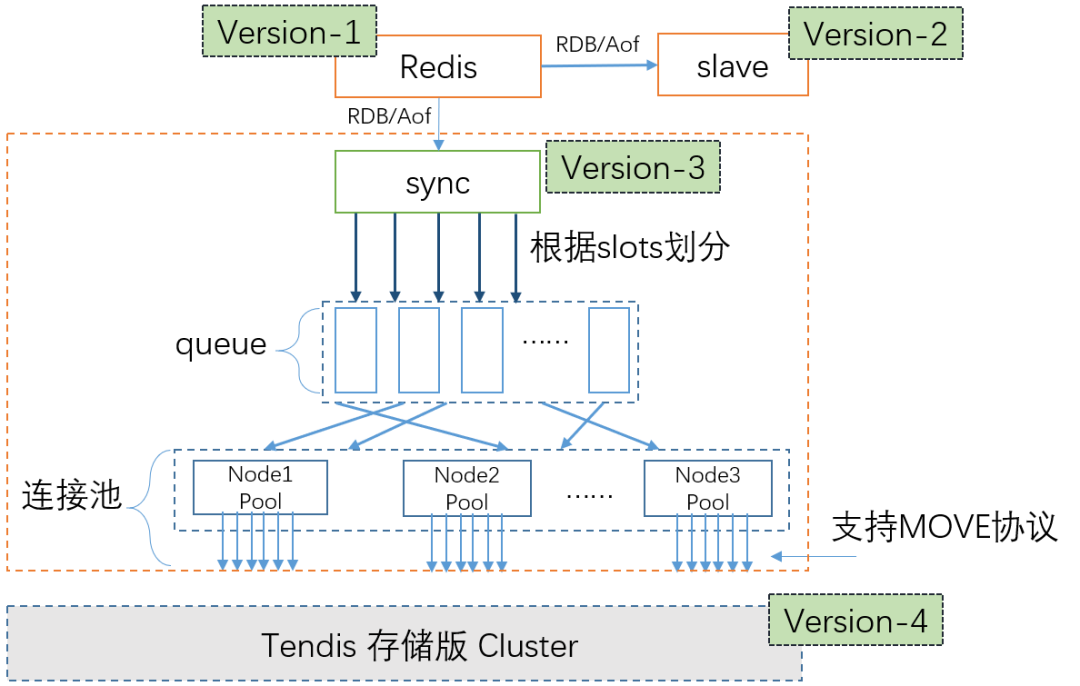
针对问题 2, Redis-sync 会在并行和串行模式之间进行转换。比如收到 FLUSHDB 命令, 这是需要将 FLUSHDB 命令 前的命令都执行完, 再执行 FLUSHDB 命令。
针对问题 3, Redis-sync 会定期将已发送给存储层的 aof 的 Version 持久化到 存储层。如何 Redis-sync 故障, 首先从 存储层获取上次已发送的位置, 然后向对应的 Redis 节点发送 psync, 请求同步。
针对问题 4, Redis-sync 会定期从存储层获取 Slot 到 Tendis 节点的映射关系, 并且维护这些 Tendis 节点的连接池。请求从 缓存层到达, 然后计算请求所属的 slot, 然后发送到正确的 Tendis 节点。
存储层 Tendis Cluster
Tendis 是兼容 Redis 核心数据结构与协议的分布式高性能 KV 数据库, 主要具有以下特性:

评论