
5张图带你了解Pulsar的存储引擎BookKeeper

1 使用场景
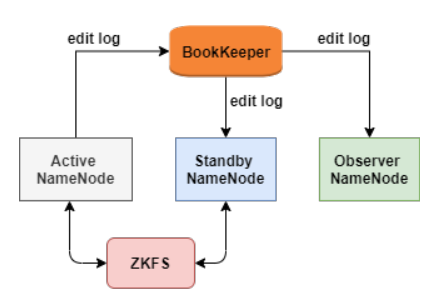
ZKFC是一个Zookeeper的客户端,主要用来监测和管理NameNode状态,每个NameNode机器上都会运行一个ZKFC,它的职责主要有三个:
健康检查 Zookeeper会话管理 选举,当集群中一个Active NameNode宕机,Zookeeper会自动选择一个节点作为新的Active NameNode。
一致性:因为edit log保存的是HDFS的元数据,对一致性要求很高 低延迟:为了不丢数据,需要低延迟 高吞吐:为了支持更多的NameNode节点,需要高吞吐
2 节点对等
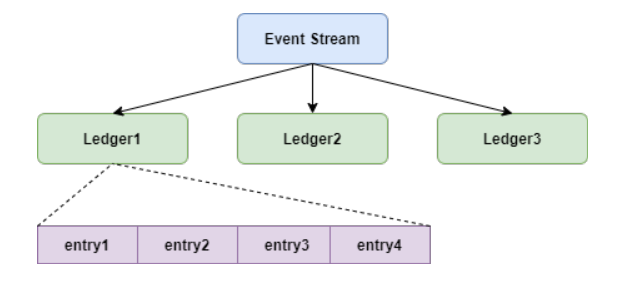
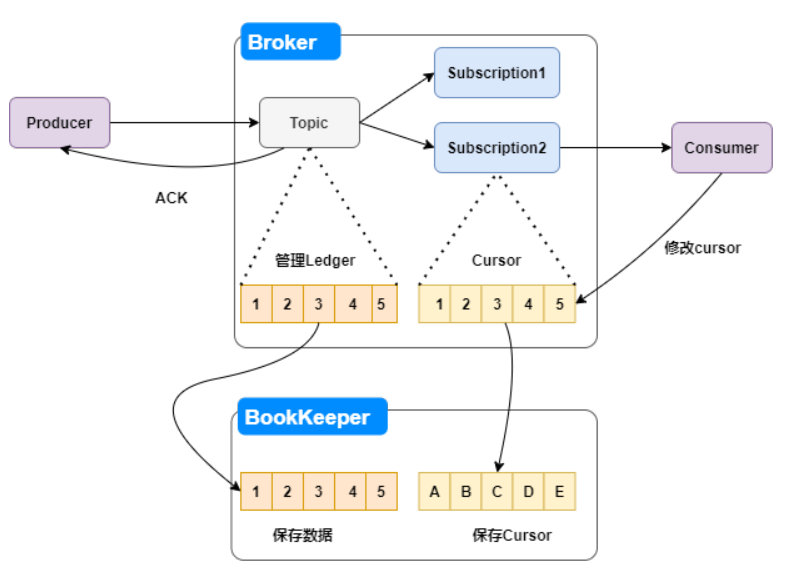
Ledger也就是Pulsar中的segment。
openLedger(组内节点数目、数据备份数目、等待刷盘节点数目)
2.1 数据读写
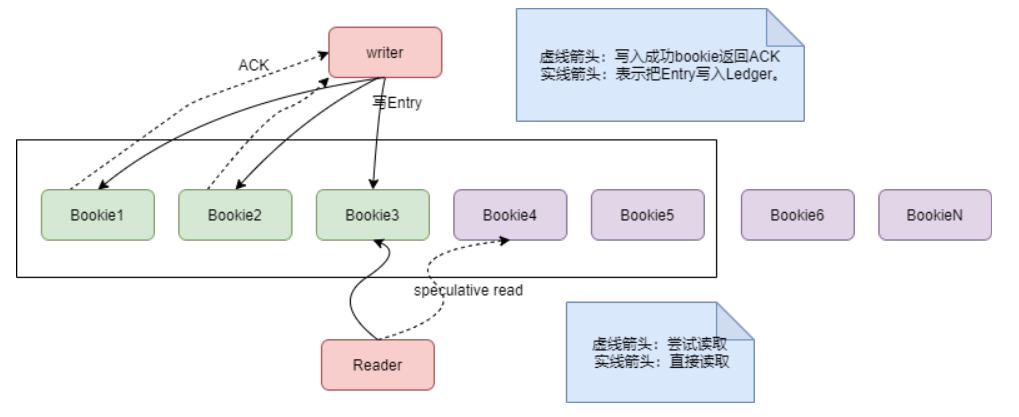
2.2 读高可用
2.3 写高可用
记录出错的entry id 对故障节点的数据进行封装 关闭当前的Ledger,重新打开一个新的Ledger,这个Ledger会重新选择bookie节点,1、2、3、4、6。 如果bookie5恢复,就不再提供写服务了,只提供读服务。 如果不能恢复,就把bookie5的数据,从其他节点的备份中恢复到新的节点上,这个过程需要根据Ledger id跟5取模来判断是否落到bookie5上,数据恢复过程并不影响Reader,因为其他两份数据可以继续提供服务。
3 I/O模型
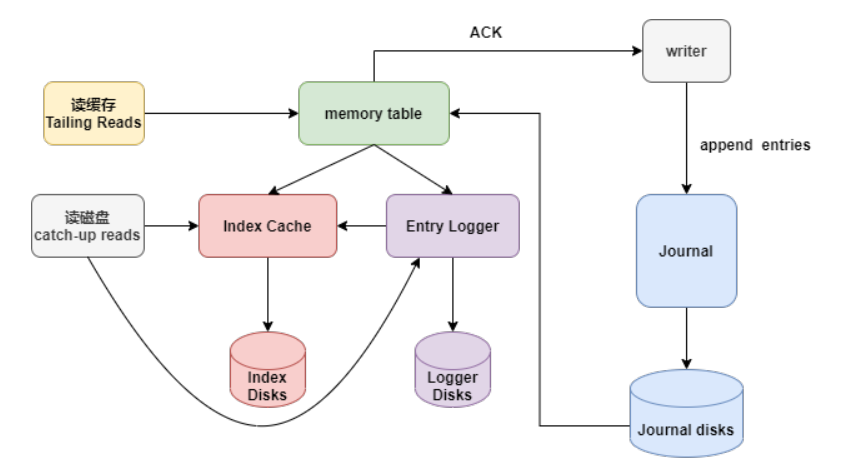
Writer写入的数据首先到达Journal,Journal将数据进行group后刷到到Journal盘,这个刷盘的数据顺序跟writer写入顺序一致。
Writer写入Journal Disk是实时刷盘。
Journal Disk的数据会写入memory table进行数据整理,把同一个topic的数据整理到一起。 把整理好的数据刷盘。Index Disk保存entry的index,对应entry在Logger Disks的offset。
3.1 读写分离
3.2 强一致性
3.3 灵活SLA
4 Pulsar中的使用

推荐阅读

华为最美小姐姐被外派墨西哥后...

国内有程序员电视剧了,结果看了一分钟,就吐了...
男女洗澡前后区别,太形象了!
END


顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」
评论