
Kratos技术系列|从Kratos设计看Go微服务工程实践


导读
github.com/go-kratos/kratos(以下简称Kratos)是一套轻量级 Go 微服务框架,致力于提供完整的微服务研发体验,整合相关框架及周边工具后,微服务治理相关部分可对整体业务开发周期无感,从而更加聚焦于业务交付。Kratos在设计之初就考虑到了高可扩展性,组件化,工程化,规范化等。对每位开发者而言,整套 Kratos 框架也是不错的学习仓库,可以了解和参考微服务的技术积累和经验。
接下来我们从Protobuf、开放性、规范、依赖注入这4个点了解一下Kratos 在Go微服务工程领域的实践。

曹国梁
6年Go微服务研发经历
腾讯云高级研发工程师
Kratos Maintainer,gRPC-go contributor

基于Protocol Buffers(Protobuf)的生态
在Kratos中,API定义、gRPC Service、HTTP Service、请求参数校验、错误定义、Swagger API json、应用服务模版等都是基于Protobuf IDL来构建的:
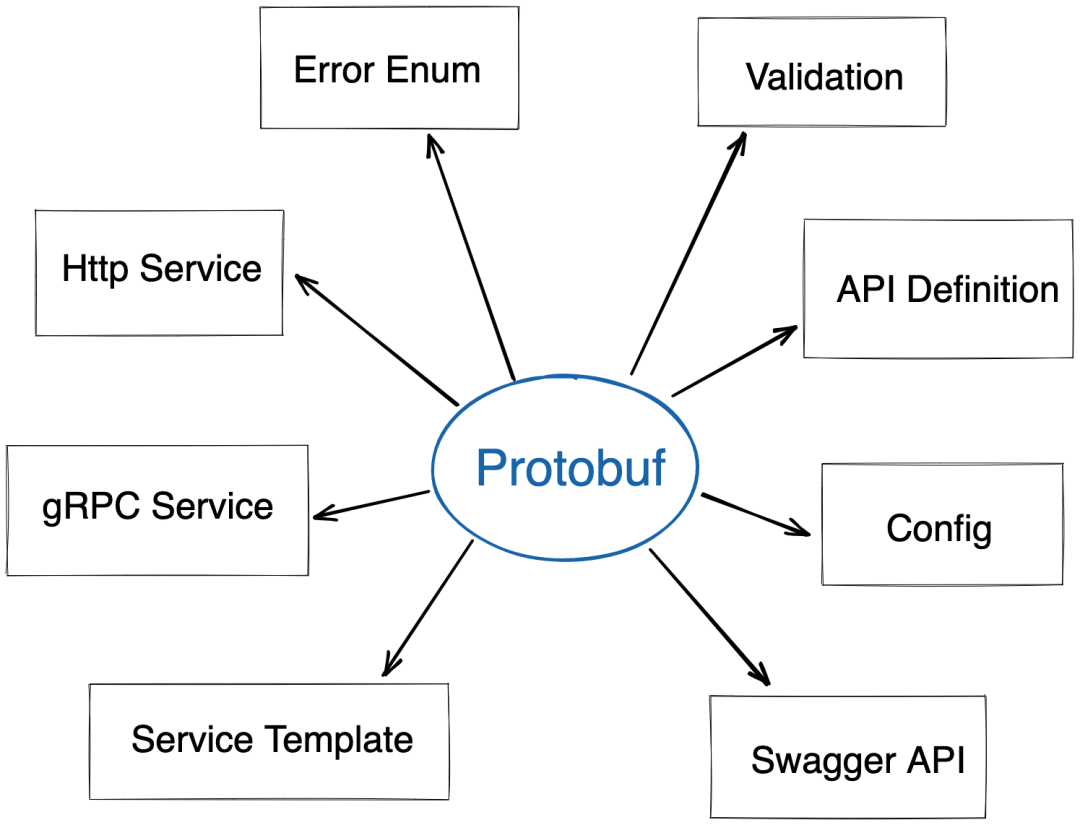
举一个简单的helloworld.proto例子:
syntax = "proto3";package helloworld;import "google/api/annotations.proto";import "protoc-gen-openapiv2/options/annotations.proto";import "validate/validate.proto";import "errors/errors.proto";option go_package = "github.com/go-kratos/kratos/examples/helloworld/helloworld";// The greeting service definition.service Greeter {// Sends a greetingrpc SayHello (HelloRequest) returns (HelloReply) {option (google.api.http) = {// 定义一个HTTP GET 接口,并且把 name 映射到 HelloRequestget: "/helloworld/{name}",};// 添加API接口描述(swagger api)option (grpc.gateway.protoc_gen_openapiv2.options.openapiv2_operation) = {description: "这是SayHello接口";};}}// The request message containing the user's name.message HelloRequest {// 增加name字段参数校验,字符数需在1到16之间string name = 1 [(validate.rules).string = {min_len: 1, max_len: 16}];}// The response message containing the greetingsmessage HelloReply {string message = 1;}enum ErrorReason {// 设置缺省错误码option (errors.default_code) = 500;// 为某个错误枚举单独设置错误码USER_NOT_FOUND = 0 [(errors.code) = 404];CONTENT_MISSING = 1 [(errors.code) = 400];;}
以上是一个简单的helloworld服务定义的例子,这里我们定义了一个Service叫Greeter,给Greeter添加了一个SayHello的接口,并根据googleapis规范给这个接口添加了Restful风格的HTTP接口定义,然后还利用openapiv2添加了接口的Swagger API描述,同时还给请求消息结构体HelloRequest中的name字段加上了参数校验,最后我们在文件的末尾还定义了这个服务可能返回的错误码。
这时我们在终端中执行:kratos proto client api/helloworld/ helloworld.proto 便可以生成以下文件:
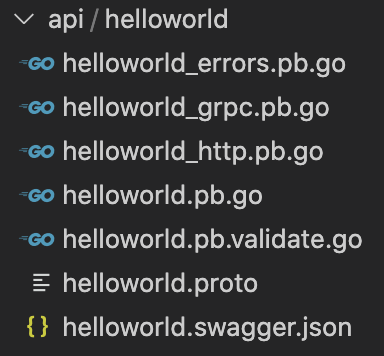
由上,我们看到Kraots脚手架工具帮我们一键生成了上面提到的能力。从这个例子中,我们可以直观感受到使用使用Protobuf带来的开发效率的提升,除此之外Kratos还有以下优点:
清晰:做到了定义即文档,定义即代码
收敛,统一:将逻辑都收敛统一到一起,通过代码生成工具来保证HTTP Service、grpc Service等功能具有一致的行为
跨语言:众所周知Protobuf是跨语言的,java、go、python、php、js、c等等主流语言都支持
拥抱开源生态:比如Kratos复用了google.http.api、protoc-gen-openapiv2、protoc-gen-validate 等等一些犀利的Protobuf周边生态工具或规范,这比起自己造一个IDL的轮子要容易维护得多,同时老的使用这些轮子的gRPC项目迁移成本也更低
开放性
一个基础框架在设计的时候就要考虑未来的可扩展性,那Kratos是怎么做的呢?
1. Server Transport
我们先看下服务协议层的代码:

上面是Kratos RPC服务协议层的接口定义,这里我们可以看到如果想要给Kratos新增一个新的服务协议,只要实现Start()、Stop()、Endpoint()这几个方法即可。这样的设计解耦了应用和服务协议层的实现,使得扩展服务协议更加方便。
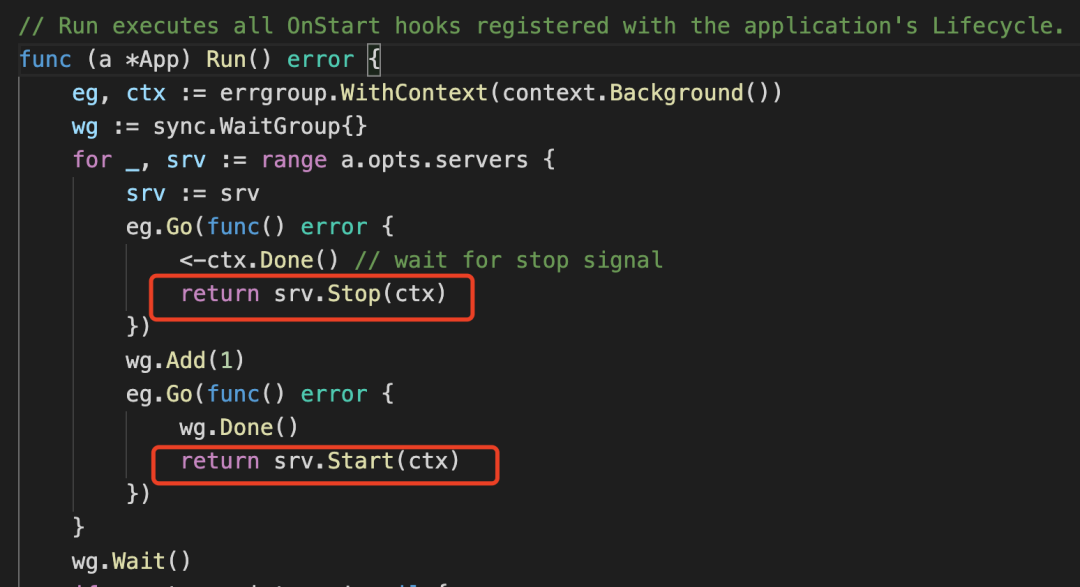
从上图中我们可以看到App层无需关心底层服务协议的实现,只是一个容器管理好应用配置、服务生命周期、加载顺序即可。
2. Log
我们再看一个Kratos日志模块的设计:
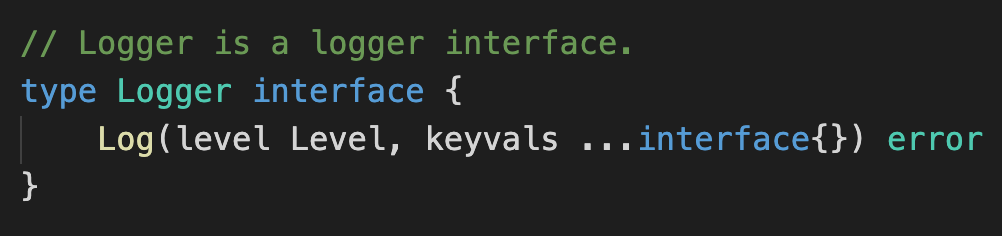
这里Kratos定义了一个日志输出接口Logger,它的设计的非常简单 - 只用了一个方法、两个输入、一个输出。我们知道一个包暴露的接口越少,越容易维护,同时对使用和实现方的心智负担更小,扩展日志实现会变得更容易。但问题来了,这个接口从功能上来讲似乎只能输出日志level和固定的kv paris,如何能支持更高级的功能?比如输出 caller stack、实时timestamp、 context traceID ?这里我们定义了一个回调接口Valuer:

这个Valuer可以被当作key/value pairs中的value被Append到日志里,并被实时调用。
我们看一下如何给日志加时间戳的Valuer实现:

使用时只要在原始的logger上再append一个固定的key和一个动态的valuer即可:
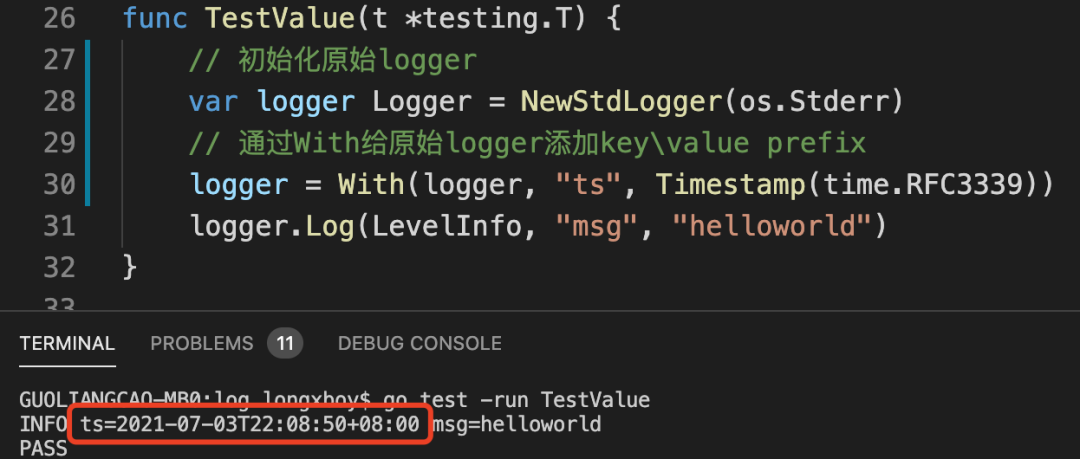
这里的With是一个Helper function,里面new了一个新的logger(也实现了Logger接口),并将key\value pairs暂存在新的logger里,等到Log方法被调用时再通过断言.(Valuer)的方式获取值并输出给底层原始的logger。
所以我们可以看到仅仅通过两个简单的接口+一个Helper function的组合我们就实现了日志的大多数功能,这样大大提高了可扩展性。实际上还有日志过滤、多日志源输出等功能也是通过组合使用这两接口来实现,这里待下次分享再展开细讲。
3. Tracing
最后我们来看下Kratos的Tracing组件,这里Kratos采用的是CNCF项目OpenTelemetry。
OpenTelemetry在设计之初就考虑到了组件化和高可扩展性,其实现了OpenTracing和W3C Trace Context的规范,可以无缝对接zipkin、jaeger等主流开源tracing系统,并且可以自定义Propagator 和 TraceProvider。通过otel.SetTracerProvider()我们可以轻易得替换Span的落地协议和格式,从而兼容老系统中的trace采集agent;通过otel.SetTextMapPropagtor()我们可以替换Span在RPC中的Encoding协议,从而可以和老系统中的服务互相调用时也能兼容。
工程流程
我们知道在工程实践的时候,强规范和约束往往比自由和更多的选择更有优势,那么在Go工程规范这块我这里主要介绍三块:
1. 面向包的设计规范
Go 是一个面向包名设计的语言,Package 在 Go 程序中主要起到功能隔离的作用,标准库就是很好的设计范例。Kratos也是可以按包进行组织代码结构,这里我们抽取Kratos根目录下主要几个Package包来看下:
/cmd: 可以通过 go install 一键安装生成工具,使用户更加方便地使用框架。
/api: Kratos框架本身的暴露的接口定义
/errors: 统一的业务错误封装,方便返回错误码和业务原因。
/config: 支持多数据源方式,进行配置合并铺平,通过 Atomic 方式支热更配置。
/internal:存放对外不可见或者不稳定的接口。
/transport: 服务协议层(HTTP/gRPC)的抽象封装,可以方便获取对应的接口信息。
/middleware: 中间件抽象接口,主要跟transport 和 service 之间的桥梁适配器。
/third_party: 第三方外部的依赖
可以看到Kratos的包命名清晰简短,按功能进行划分,每个包具有唯一的职责。
在设计包时我们还需要考虑到以下几点:
包的设计必须以使用者为中心,直观且易于使用,包的命名必须旨在描述它提供的内容,如果包的名称不能立即暗示这一点,则它可能包含一组零散的功能。
包的目的是为特定问题域而提供的,为了有目的,包必须提供,而不是包含。包不能成为不同问题域的聚合地,随着时间的推移,它将影响项目的简洁和重构、适应、扩展和分离的能力。
高便携性,尽量减少依赖其他代码库,一个包与其它包依赖越少,一个包的可重用性就越高。
不能成为单点依赖,当包被单一的依赖点时,就像一个公共包(common),会给项目带来很高的耦合性。
2. 配置
首先,我们来看下常见的基础框架是怎么初始化配置的:
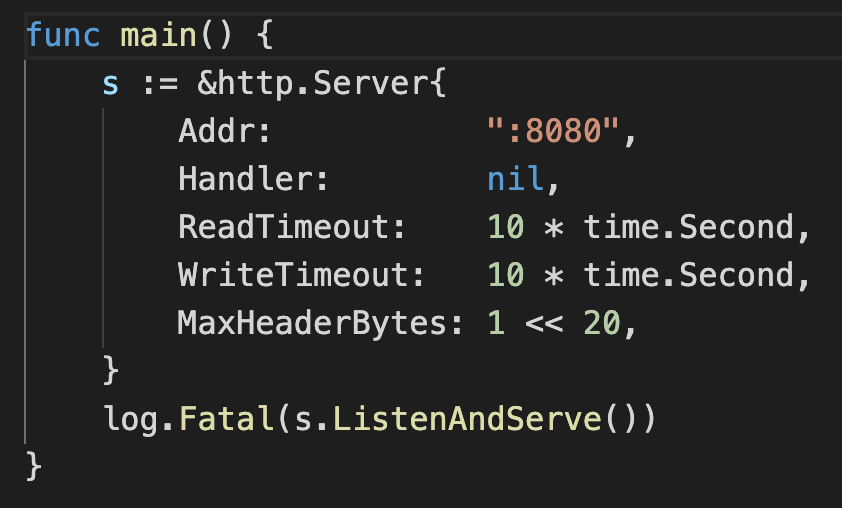
这是Go标准库HTTP Server配置初始化的例子,但是这样做会有如下几个问题:
&http.Server{}由于是一个取址引用,里面的参数可能会被外部运行时修改,这种运行时修改带来的危害是不可把控的。
无法区分nil和0值,当里面的参数值为0的时候,不知道是用户未设置还是就是被设置成了0。
难以分辨必传和选传参数,只能通过文档说明来隐式约定,没有强约束力。
那么Kraots是怎么解决这些问题的呢?答案就是Functional Options 。我们看下transport/http/client.go的代码:
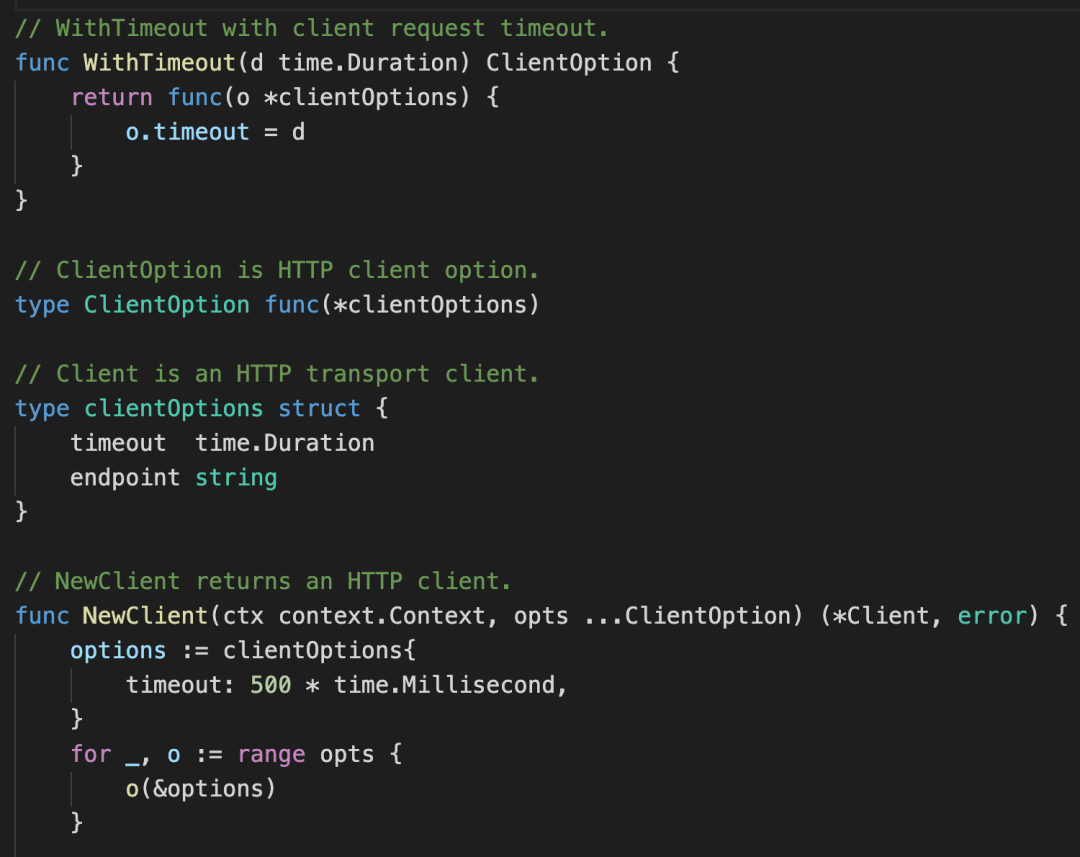
Client.go中定义了一个回调函数ClientOption,该函数接受一个定义了一个存放实际配置的未导出结构体clientOptions的指针,然后我们在NewClient的时候,使用可变参数进行传递,然后再初始化函数内部通过 for 循环调用修改相关的配置。
这么做有这么几个好处:
由于clientOptions结构体是未导出的,那么就不存在被外部修改的可能。
可以区分0值和未设置,首先我们在new clientOptions时会设置默认参数,那么如果外部没有传递相应的Option就不会修改这个默认参数。
必选参数显示定义,可选值则通过Go可变参数进行传递,很好的区分必传和选传。
3. Error规范
Kratos为微服务提供了统一的Error模型:

Code用作外部展示和初步判断,服务端无需定义大量全局唯一的XXX_NOT_FOUND,而是使用一个标准Code.NOT_FOUND错误代码并告诉客户端找不到某个资源。错误空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性。同时这种标准的大类Code的存在也对外部的观测系统更友好,比如可以通过分析Nginx Access Log中的HTTP StatusCode来做服务端监控和告警。
Reason是具体的错误原因,可以用来更详细的错误判定。每个微服务都会定义自己Reason,那么要保持全局唯一就需要加上领域前缀,比如User_XXX。
Message错误信息可以帮助用户轻松快捷地理解和解决API 错误
Metadata中则可以存放一些标准的错误详情,比如retryInfo、error stack等
这种强制规范,避免了开发人员直接透传Go的error 从而导致一些敏感信息泄露。
接下来我们看下Error结构体还实现了哪些接口:
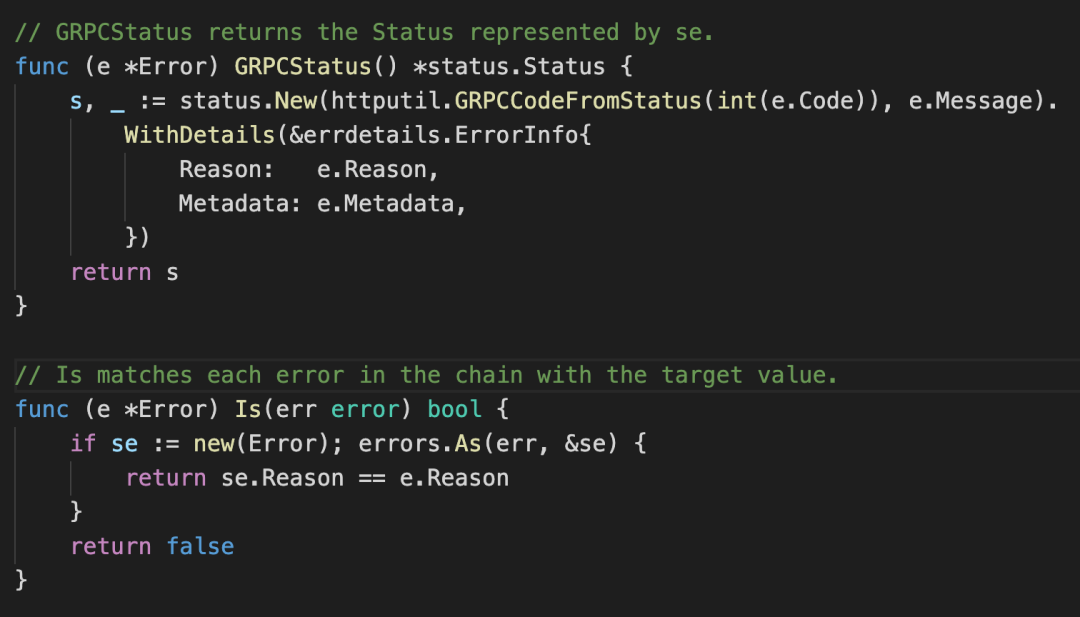
实现了GRPCStatus () *status.Status 接口,这样就实现了从http status code到grpc status code的转换,这样Kratos Error可以被gRPC直接转成google.rpc.Status传递出去。
实现了标准库errors包的Is (error) bool接口,这样使用者可以直接调用errors.Is()来比较两个erorr中的reason是否相等,避免了使用==来直接判断error是否相等这种错误姿势。
依赖注入
依赖注入 (Dependency Injection)可以理解为一种代码的构造模式,按照这样的方式来写,能够让你的代码更加容易维护,一般在Java的项目中见到的比较多。
依赖注入初看起来比较违反直觉,那么为什么Go也需要依赖注入?假设我们要实现一个用户访问计数的功能。我们先看看不使用依赖注入的项目代码:
type Service struct {redisCli *redis.Client}func (s *Service) AddUserCount(ctx context.Context) {//do some business logics.redisCli.Incr(ctx, "user_count")}func NewService(cfg *redis.Options) *Service {return &Service{redisCli: redis.NewClient(cfg)}}
这种方式比较常见,在项目刚开始或者规模小的时候没什么问题,但我们如果考虑下面这些因素:
Redis是基础组件,往往会在项目的很多地方被依赖,那么如果哪天我们想整体修改redis sdk的甚至想把redis 整体替换成mysql时,需要在每个被用到的地方都进行修改,耗时耗力还容易出错。
很难对App这个类写单元测试,因为我们需要创建一个真实的redis.Client。
使用依赖注入改造后的Service:
type DataSource interface{Incr(context.Context, string)}type Service struct {dataSource DataSource}func (s *Service) AddUserCount(ctx context.Context) {//do some business logics.dataSource.Incr(ctx, "user_count")}func NewService(ds DataSource) *Service {return &Service{dataSource: ds}}
上面代码中我们把*redis.Client实体替换成了一个DataSource接口,同时不控制dataSource的创建和销毁,把dataSource生命周期控制权交给了上层来处理,以上操作有三个主要原因:
因为Service层已不再关心dataSource的创建和销毁,这样当我们需要修改dataSource实现的时候,只要在上层统一修改即可,无需在各个被依赖的地方一一修改。
因为依赖的是一个接口,我们写单元测试的时候只要传递一个mock后的Datasource实现即可 。
这里dataSource这个基础组件不再被会到处创建,可以做到复用一个单例节省资源开销。
Go 的依赖注入框架有两类,一类是通过反射在运行时进行依赖注入,典型代表是 uber 开源的 dig,另外一类是通过 generate 进行代码生成,典型代表是 Google 开源的 wire。使用 dig 功能会强大一些,但是缺点就是错误只能在运行时才能发现,这样如果不小心的话可能会导致一些隐藏的 bug 出现。使用 wire 的缺点就是功能限制多一些,但是好处就是编译的时候就可以发现问题,并且生成的代码其实和我们自己手写相关代码差不太多,更符合直觉,心智负担更小。所以Kratos更加推荐 wire,Kratos的默认项目模板中 kratos-layout 也正是使用了 google/wire 进行依赖注入。
我们来看下wire使用方式:
我们首先要定义一个ProviderSet,这个Set会返回构建依赖关系所需的组件Provider。如下所示,Provider往往是一些简单的工厂函数,这些函数不会太复杂:
type RedisSource struct {redisCli *redis.Client}// RedisSource实现了Datasource的Incr接口func (ds *RedisSource) Incr(ctx context.Context, key string) {ds.redisCli.Incr(ctx, key)}// 构建实现了DataSource接口的Providerfunc NewRedisSource(db *redis.Client) *RedisSource {return &RedisSource{redisCli: db}}// 构建*redis.Client的Providerfunc NewRedis(cfg *redis.Options) *redis.Client {return redis.NewClient(cfg)}// 这是一个Provider的集合,告诉wire这个包提供了哪些Providervar ProviderSet = wire.NewSet(NewRedis, NewRedisSource)
接着我们要在应用启动处新建一个wire.go文件并定义Injector,Injctor会分析依赖关系并将Provider串联起来构建出最终的Service:
// +build wireinjectfunc initService(cfg *redis.Options) *service.Service {panic(wire.Build(redisSource.ProviderSet,//使用 wire.Bind 将 Struct 和接口进行绑定了,表示这个结构体实现了这个接口,wire.Bind(new(data.DataSource), new(*redisSource.RedisSource)),service.NewService),)}
最后执行wire .后自动生成的代码如下:
//go:generate go run github.com/google/wire/cmd/wire//+build !wireinjectfunc initService(cfg *redis.Options) *service.Service {client := redis2.NewRedis(cfg)redisSource := redis2.NewRedisSource(client)serviceService := service.NewService(redisSource)return serviceService}
由此我们可以看到只要定义好组件初始化的Provider函数,还有把这些Provider组装在一起的Injector就可以直接生成初始化链路代码了,上手还是相对简单的,生成的代码所见即所得,容易Debug。
综上可见,Kratos是一款凝结了开源社区力量以及Go同学们大量微服务工程实践后诞生的一款微服务框架。现在腾讯云微服务治理治理平台(微服务平台TSF)也已支持Kratos框架,给Kratos赋予了更多企业级服务治理能力、提供多维度服务,如:应用生命周期托管、一键上云、私有化部署、多语言发布。
(扫描二维码查看Go接入TSF腾讯云文档)
免费体验馆
消息队列CKafka
分布式、高吞吐量、高可扩展性的消息服务,具备数据压缩、同时支持离线和实时数据处理等优点。
扫码即可免费体验
免费体验路径:云产品体验->基础->消息队列CKafka
消息队列TDMQ
一款基于 Apache 顶级开源项目 Pulsar 自研的金融级分布式消息中间件。其计算与存储分离的架构设计,使得它具备极好的云原生和 Serverless 特性,用户按量使用,无需关心底层资源。
扫码点击“立即使用”,即可免费体验
微服务平台TSF
稳定、高性能的技术中台。一个围绕着应用和微服务的 PaaS 平台,提供应用全生命周期管理、数据化运营、立体化监控和服务治理等功能。TSF 拥抱 Spring Cloud 、Service Mesh 微服务框架,帮助企业客户解决传统集中式架构转型的困难,打造大规模高可用的分布式系统架构,实现业务、产品的快速落地。
扫码点击“免费体验”,即可免费体验
微服务引擎TSE
高效、稳定的注册中心托管,助力您快速实现微服务架构转型。
扫码点击“立即申请”,即可免费体验
弹性微服务TEM
面向微服务应用的 Serverless PaaS 平台,实现资源 Serverless 化与微服务架构的完美结合,提供一整套开箱即用的微服务解决方案。弹性微服务帮助用户创建和管理云资源,并提供秒级弹性伸缩,用户可按需使用、按量付费,极大程度上帮用户节约运维和资源成本。让用户充分聚焦企业核心业务本身,助力业务成功。
扫码点击“立即申请”,即可免费体验
往期
推荐
《【阵容扩大】三位腾讯Maintainer加入Apache Pulsar生态项目RocketMQ-on-Palsar》
《Apache Pulsar事务机制原理解析|Apache Pulsar 技术系列》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!
