
Chrome 浏览器运行原理你了解多少?
浏览器基础
进程架构
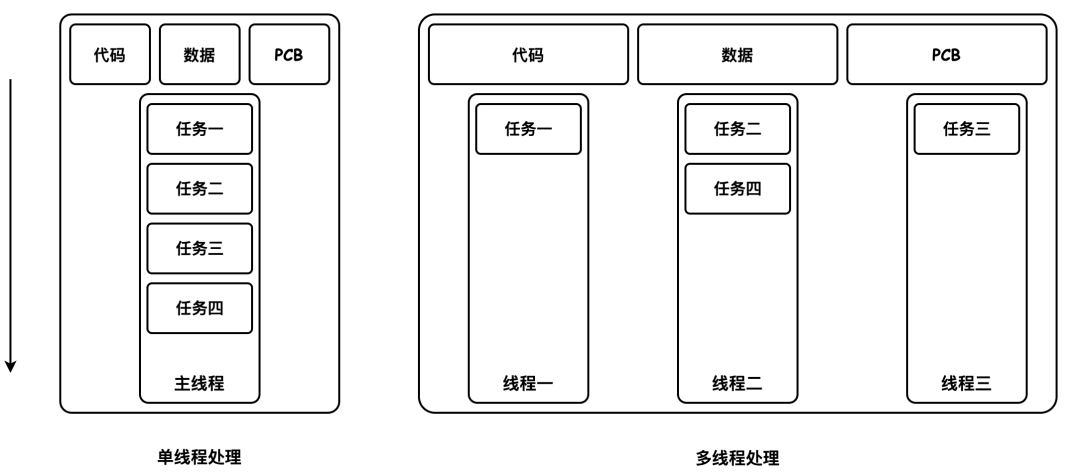
进程是操作系统资源分配的最小单位;线程是计算机中独立运行、CPU 任务调度的最小单位。
进程是程序的运行实例,启动一个程序时,操作系统会为该程序创建一块内存,用于存放代码段、数据段和进程控制块(PCB)。
代码段存储程序代码;数据段存储程序运行时使用、产生的运算数据,如全局变量、局部变量等;进程控制块是操作系统管理和控制进程的数据结构,具体包括进程标识符信息、处理机状态信息、进程调度信息和进程控制信息。
-
同一个进程的任意线程执行出错,都会导致整个进程的崩溃。
-
线程之间共享进程的数据。
-
当一个进程关闭后,操作系统会回收进程所占用的内存。
-
进程之间相互隔离,进程间通信需要使用 IPC 机制。
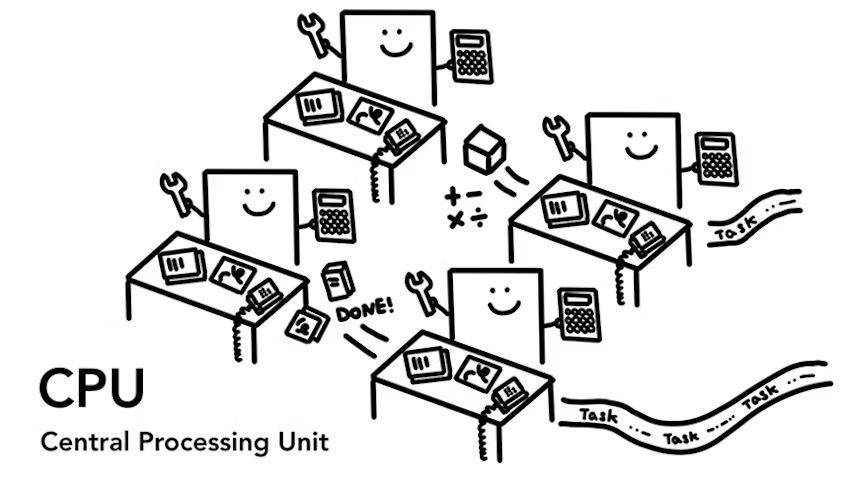
CPU 被视为计算机的大脑。CPU 的每个核心可以逐一处理许多不同的任务。在现代硬件中,CPU 通常会存在多个核心,从而为计算机提供更强的算力。
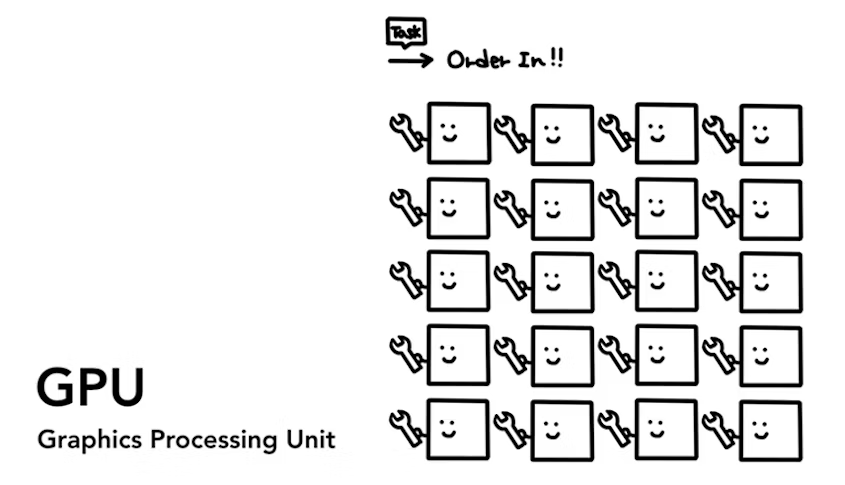
与 CPU 不同,GPU 擅长同时处理多个简单任务,GPU 通常拥有数千个流处理器(Stream Processor)和数百个内存控制器,每个流处理器都可以处理一个数据元素,从而实现高度并行化的计算。
由于 GPU 的并行计算结构、高速内存、专用计算单元、更高的时钟频率等硬件优势,使得 GPU 可以更好地处理大规模简单相似数据,应用于如图像和视频处理、深度学习和人工智能、科学计算和数值模拟、游戏和虚拟现实等大数据计算场景。
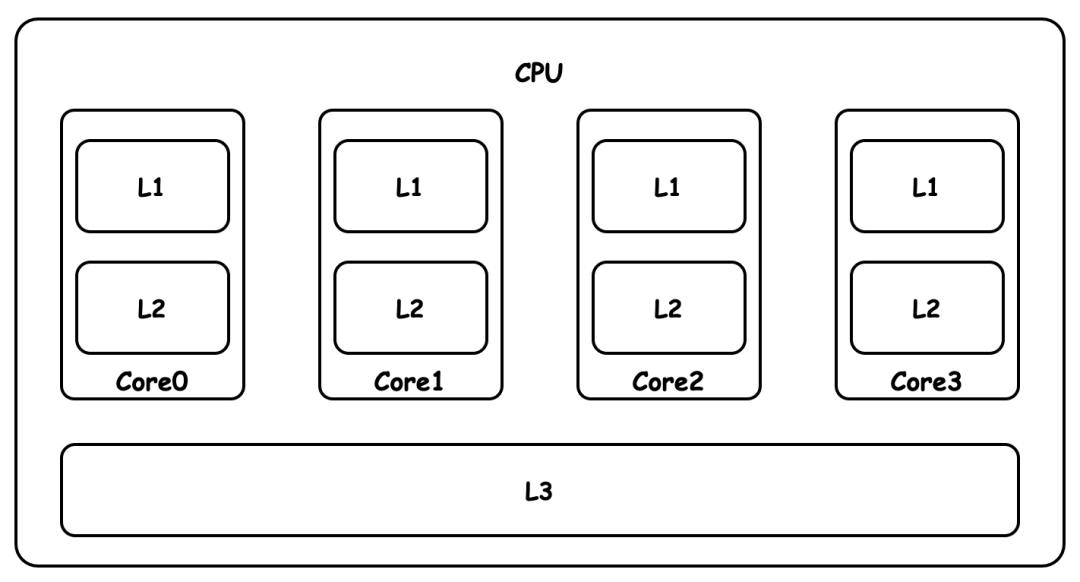
CPU 缓存主要分为三个级别:L1、L2 和 L3。其中 L1 高速缓存是计算机系统内最快的缓存,内存大小一般为 256KB 到 2MB 左右;L2 缓存比 L1 缓存稍慢,但内存更大,通常在 256 KB 到 8MB 之间;L3 缓存是最大的 CPU 缓存单元,内存大小为 4MB 到 50MB。多核 CPU 允许线程并行执行,每个 CPU 核心拥有单独的 L1 和 L2 缓存,而 L3 缓存可以核心间共享。
单进程浏览器
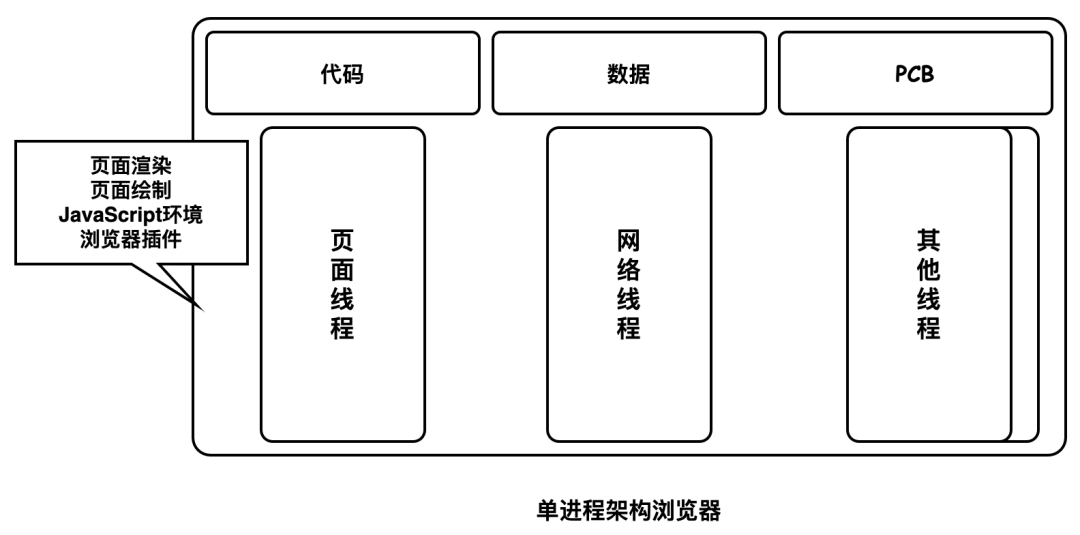
单进程浏览器是指浏览器的所有功能模块都是运行在同一个进程里,这些模块包含了网络、插件、JavaScript 运行环境、渲染引擎和页面等。在 2007 年之前,市面上浏览器都是单进程的。多个功能模块运行在同一进程必然造成不稳定、不流畅和不安全的问题。
-
不稳定性,插件模块和渲染模块都是不稳定的,一旦某个模块发生意外则整个浏览器都会崩溃。
-
不流畅性,所有页面的渲染模块、JavaScript 执行环境以及插件都是运行在同一个线程中的,这就意味着同一时刻只能有一个模块可以执行。除此之外,内存泄露也是导致浏览器卡顿的重要原因。
-
不安全性,插件可以使用 C/C++ 等代码编写,意味着插件可以获取到操作系统的任意资源,如果是恶意插件,那么它就可能会释放病毒、窃取账号密码,引发安全性问题。
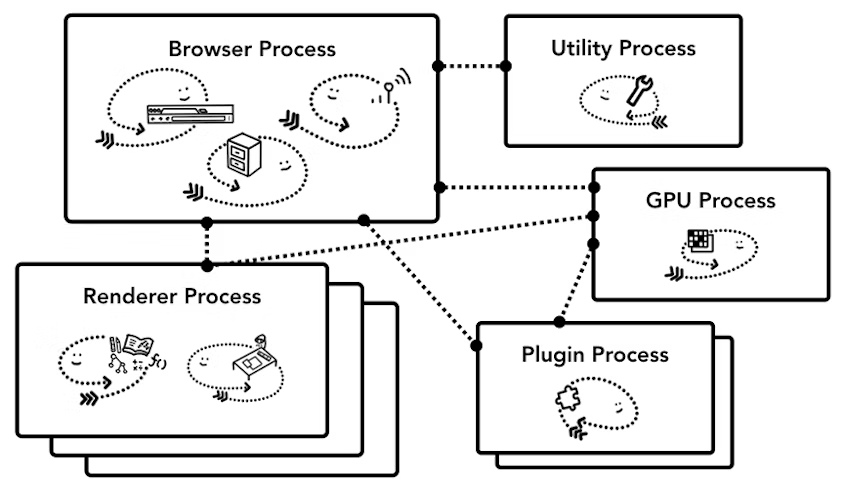
多进程浏览器
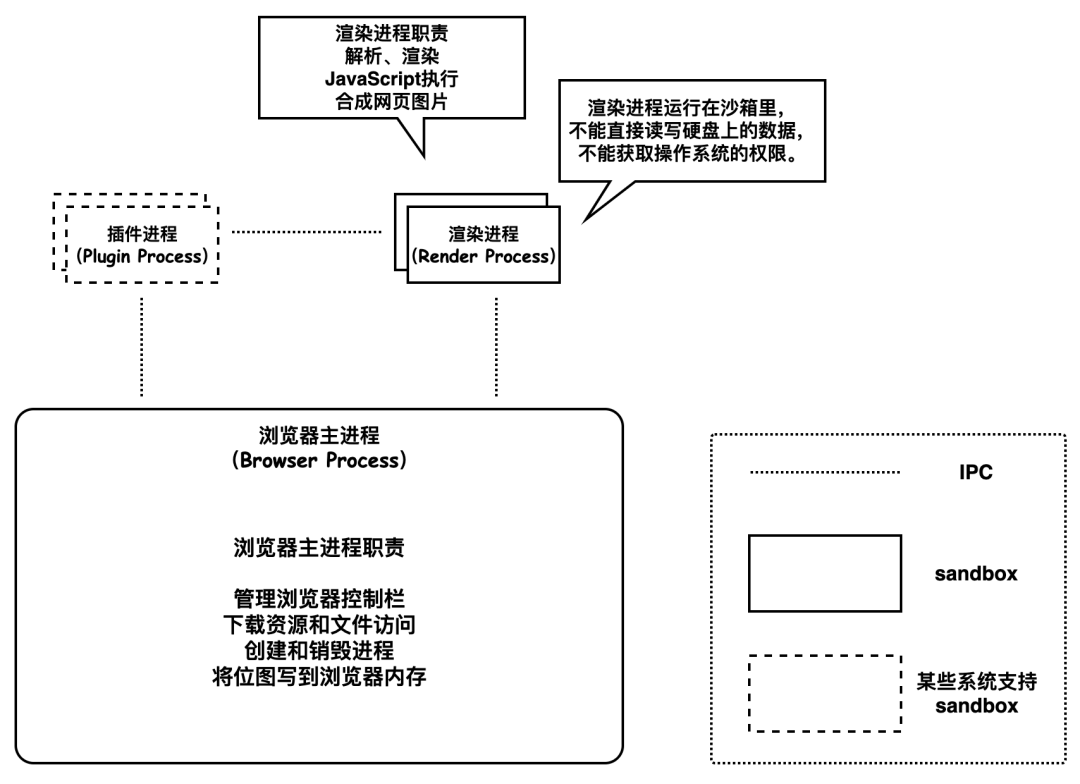
a)早期 Chrome 进程架构图
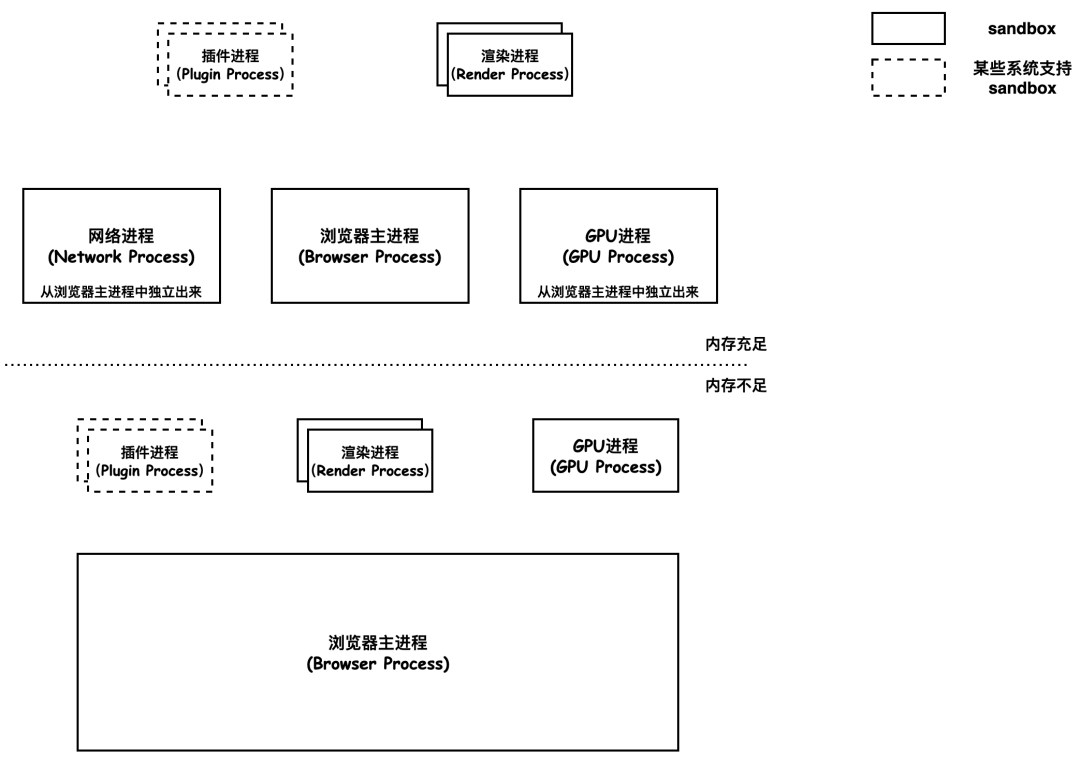
b)当前 Chrome 进程架构图
多进程架构的浏览器解决了单进程浏览器存在的三大问题:进程是相互隔离的,所以当一个页面或者插件崩溃时,不会影响到浏览器和其他页面;JavaScript 运行在渲染进程,而渲染进程间是相互隔离的,出错只会影响当前的渲染页面,关闭一个页面时,整个渲染进程也会被关闭,该进程所占用的内存都会被系统回收,内存泄露问题也不会相互影响;渲染进程和插件进程使用安全沙箱,即使执行恶意程序,也无法突破沙箱去获取系统权限。
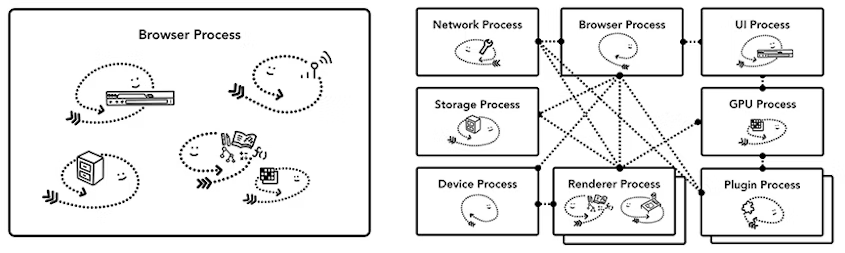
-
浏览器主进程:控制包括地址栏、书签、后退和前进按钮的“chrome”应用程序。处理 Web 浏览器的不可见的特权部分,例如网络请求和文件访问。
-
渲染进程:控制除 Tab 栏之外的所有浏览器展示相关部分。
-
插件进程:控制网站使用的任何插件,如 Flash 插件。
-
GPU 进程:独立于其他进程,用于处理 GPU 任务。被单独拆分出一个进程,因为 GPU 处理来自多个应用程序的请求并将它们绘制在同一个表面上。
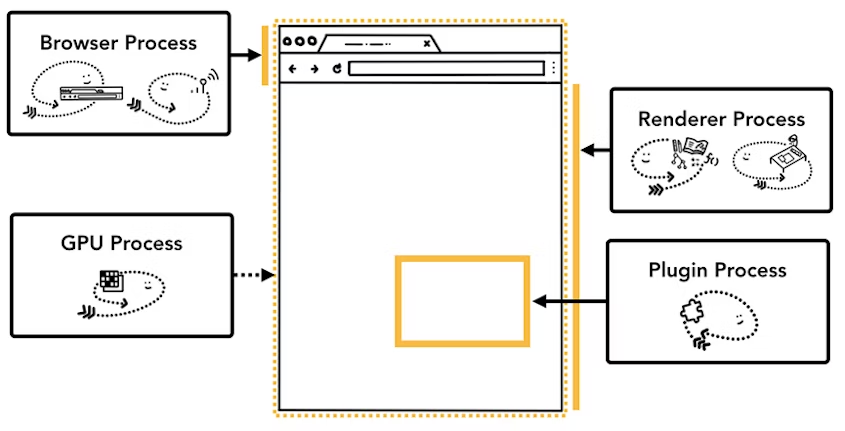
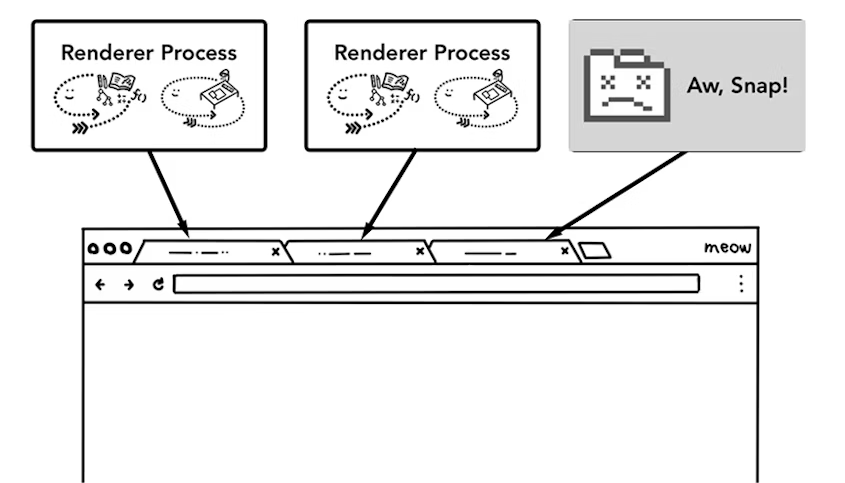
Chrome 使用多渲染进程的好处是当打开 3 个 Tab 页,其中一个失去响应时,将其关闭也不会影响其他 Tab 页的正常运行。而在单渲染进程里,任何一个 Tab 页出错,都会使整个渲染进程失去响应,所有的页面都会报错。
分成多个渲染进程额外的优势是安全性和沙盒化。因为操作系统提供限制权限的方法,浏览器可以对具体进程的某些功能进行沙盒化,以确保其安全性。
网络请求
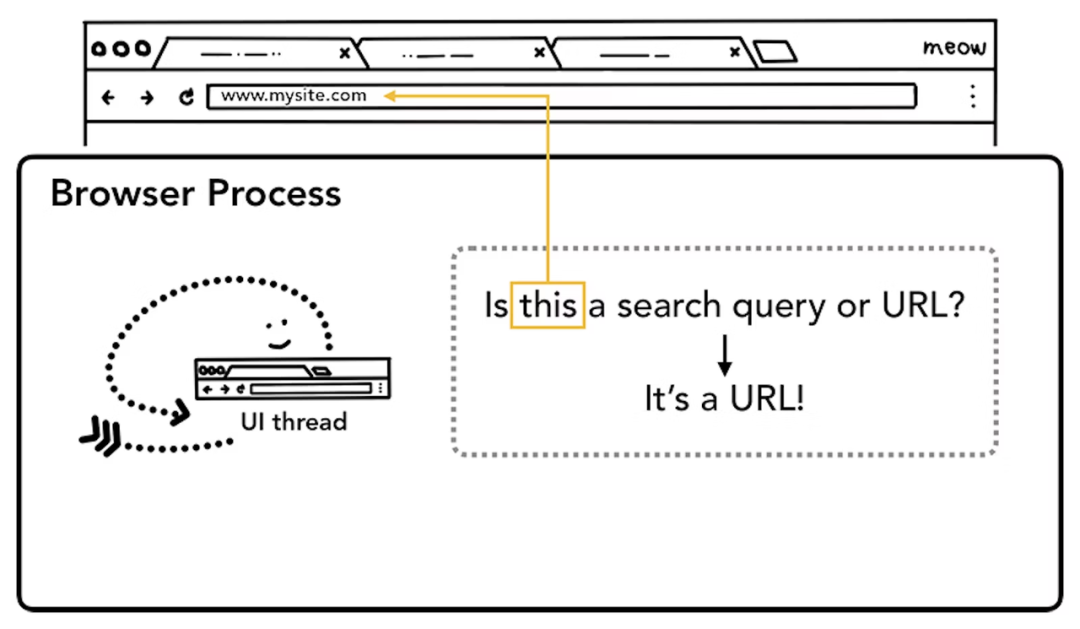
从输入 URL 到页面最终展示的整个流程需要多个进程的配合。这个过程大致可以描述为如下。
-
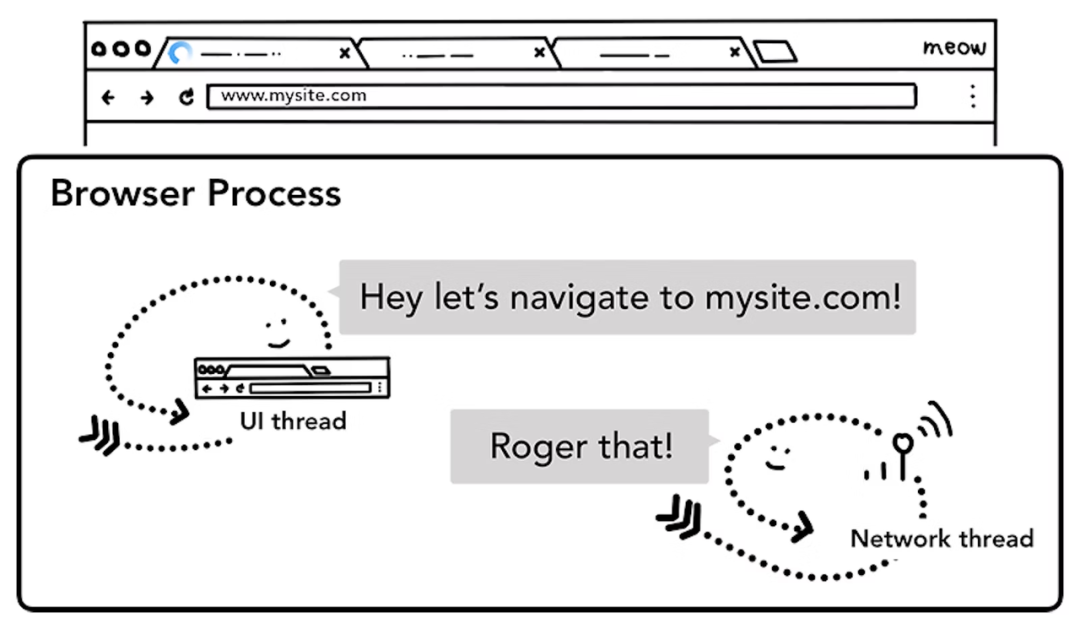
浏览器进程的 UI 线程接收到用户输入的 URL 请求,浏览器进程便将该 URL 转发给网络线程 /进程。
-
网络线程发起 URL 请求。
-
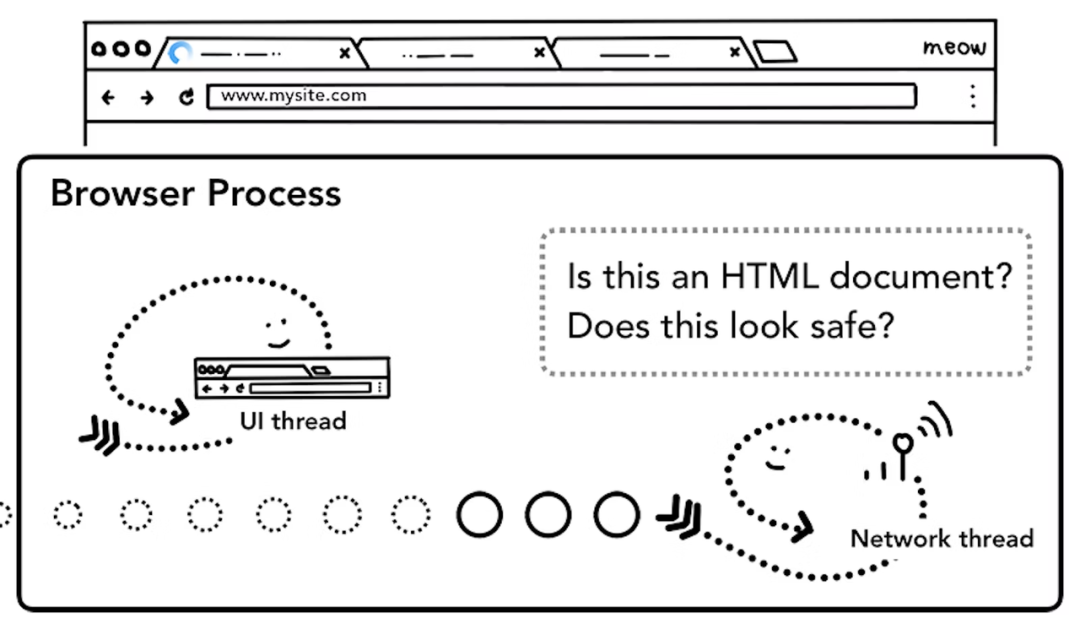
网络线程接收到响应头数据,解析响应头数据,并将数据转发给浏览器进程。
-
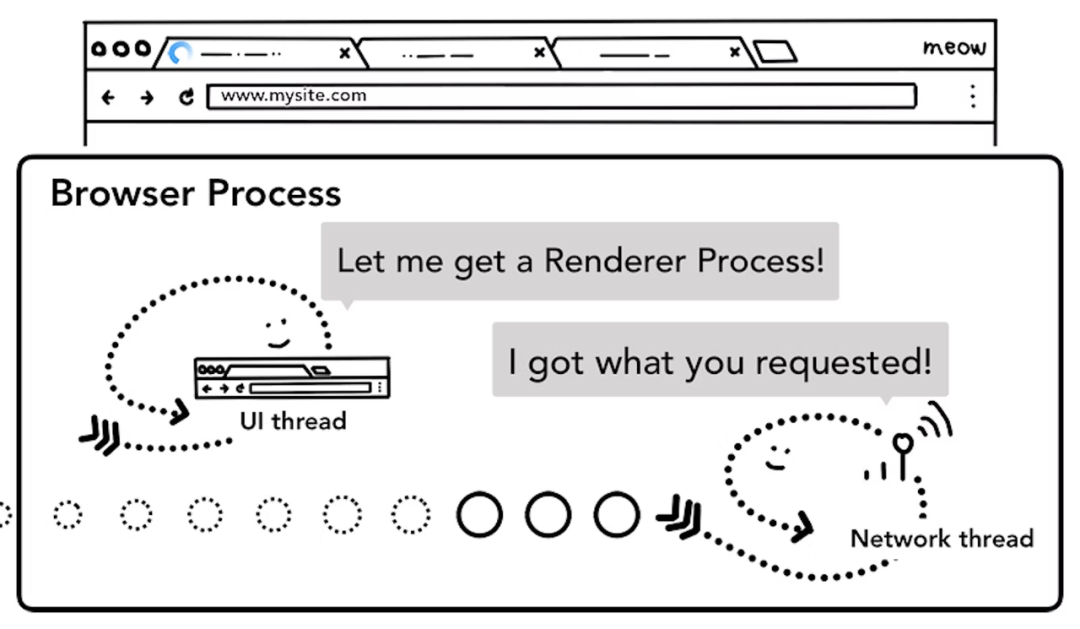
浏览器进程接收到网络线程的响应头数据之后,发送“提交导航” (Commit Navigation)消息到渲染进程;
-
渲染进程接收到“提交导航”的消息之后,和网络线程建立数据管道,准备接收 HTML 数据;
-
渲染进程向浏览器进程“确认提交”,准备接受和解析页面数据。
-
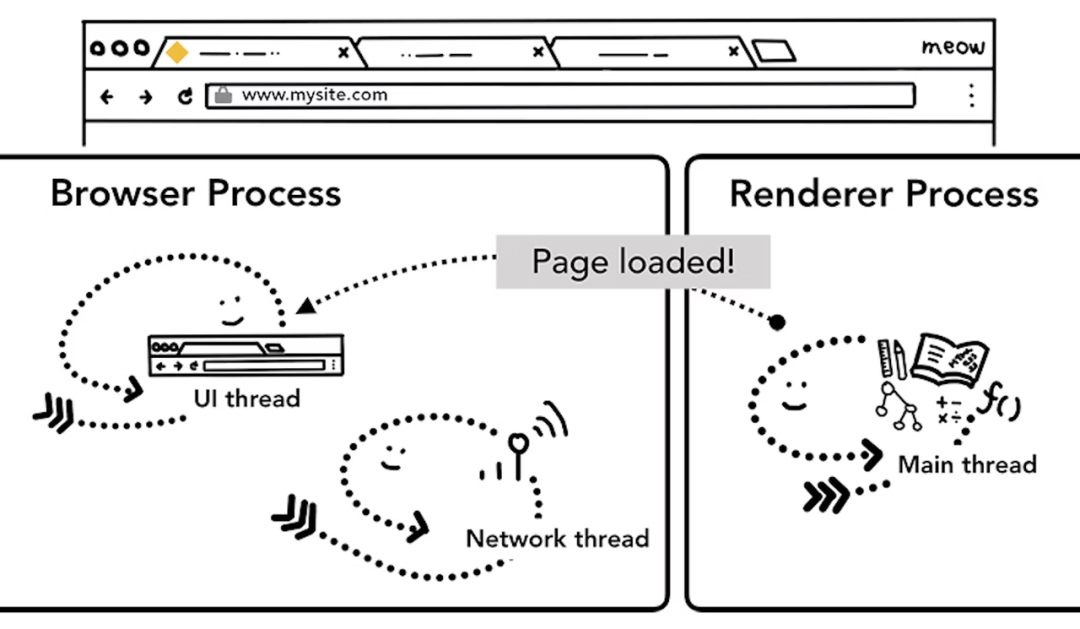
浏览器进程接收到渲染进程“提交文档”的消息后,开始移除旧文档,然后更新浏览器进程中的页面状态。
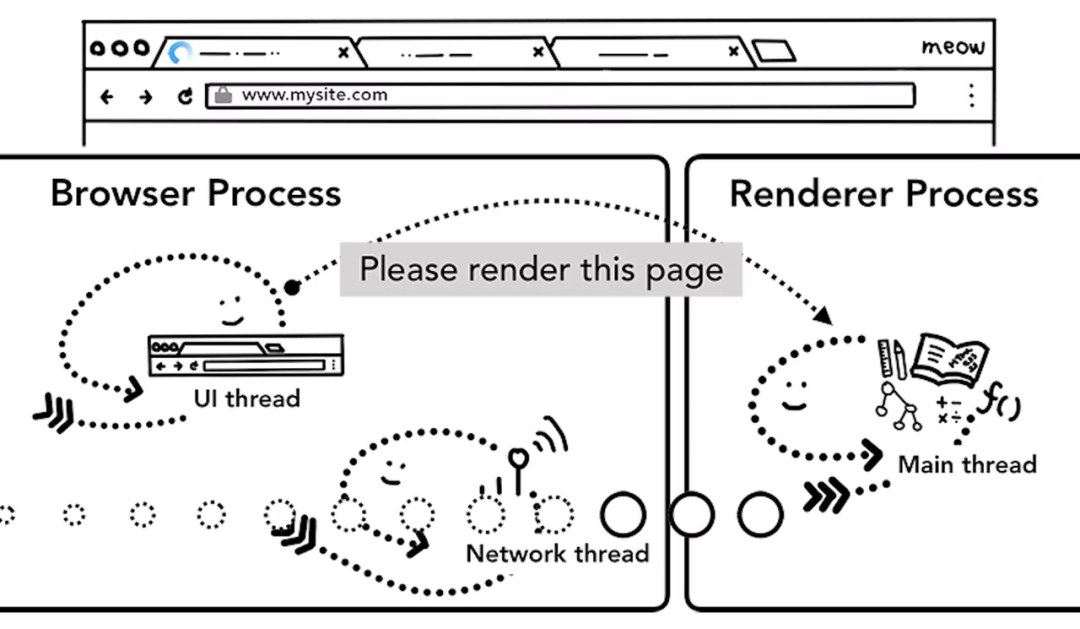
-
网络线程 - 内存资源受限的设备呈现为线程,充足的设备为进程。
V8 引擎基础
数据存储
| 类型 | 描述 | 分类 |
|---|---|---|
| boolean | 只有 true 和 false 两个值 | 基本类型 |
| undefined | 没有被赋值的变量的默认值 | 基本类型 |
| number | | 基本类型 |
| string | 字符串用于表示文本数据,不可修改 | 基本类型 |
| bigint | 支持更大范围的整数值 | 基本类型 |
| symbol | 符号类型唯一并且不可修改 | 基本类型 |
| object | 对象类型是一组属性的集合,包括 null | 引用类型 |
| function | 函数是可重复使用的代码块 | 引用类型 |
安全数字
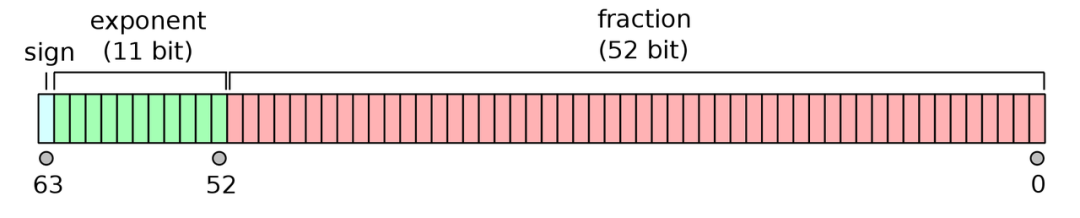
JavaScript 的数值类型是基于 IEEE 754 标准[1] 的双精度 64 位二进制格式,其中 1 位代表符号位(sign),11 位指数(E),52 位尾数(F)。规约数阶码范围
在 IEEE754 标准的浮点数表示除 NaN 外的浮点数据,包括
-
有符号零
-
有限非零
-
规约浮点数(normalized number),指数部分的二进制位非全 0 或者非全 1
-
非规约浮点数(denormalized number),指数部分的二进制位为全 0
-
有符号无穷大
-
NaN
-
Quiet NaN
-
Signaling NaN
规约浮点数计算公式
非规约浮点数计算公式
非规约数,这类数字指数部分全为 0,尾数部分不全为 0。非规约数的偏移量比规约数偏移量小 1,64 位非规约浮点数偏移量为 1022。
综上所述Number.MAX_VALUE是规约浮点数值为
Number.MIN_VALUE是非规约浮点数值为
Number.EPSILON表示 1 与 Number 可表示的大于 1 的最小的浮点数之间的差值为
特殊值
-
指数位全 0,尾数位全 0,表示 ±0。
-
指数位全 1,尾数位全 0,表示 ±∞。
-
指数位全 1,尾数位不全为 0,表示 NaN。
0.1 + 0.2 === 0.3 // false 0.30000000000000004 误差绝对值小于Number.EPSILON
18.366667 - 16.466667 === 1.9 // false 1.8999999999999986 误差绝对值大于Number.EPSILON
-
-
非规约浮点数计算公式 - 用非规约数表示更接近 0 的数字。所以最小值指数始终为 -1022。
-
Number.MIN_VALUE - 并非代表最小负数,而是 JavaScript 所能表示大于 0 的最小浮点数。
属性顺序
在 ES6 之前,一个对象键 / 属性的排列顺序是依赖于浏览器的具体实现。尽管绝大多数的浏览器引擎都是按照创建的顺序进行枚举的,但开发者们一直被强烈建议不要依赖于这个顺序。
从 ES6 开始,属性排列顺序是由[[OwnPropertyKeys]]算法定义的,这个规范定义[2]适用于对象的所有属性(字符串或符号),不管是否可枚举。但这个顺序只对Reflect.ownKeys、Object.getOwnPropertyNames和Object.getOwnPropertySymbols有保证。
规范定义对象属性的具体顺序为:
-
首先,按照数字属性名升序排列;
-
其次,按照创建顺序枚举字符串属性名;
-
最后,按照创建顺序枚举符号属性名。
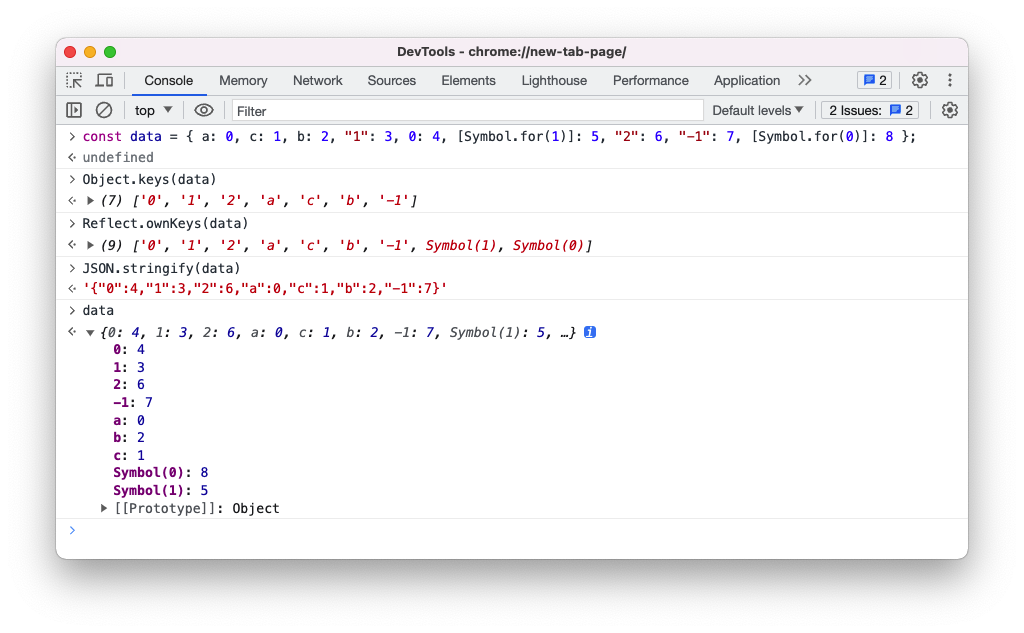
获取对象属性列表的 API 遵循的算法各不一样。
-
for...in和Reflect.enumerate使用[[Enumerate]]算法,属性顺序与浏览器的具体实现相关,不由规范约束。
-
Object.keys虽然先使用[[OwnPropertyKeys]]算法获取属性列表,但是会过滤不可枚举属性,还会重新排序以遵循具体实现相关的行为特性,所以属性排序同for...in一致,细节可以参考规范[3]。
// literal declaration of an object
const data = { a: 0, c: 1, b: 2, "1": 3, 0: 4, [Symbol.for(1)]: 5, "2": 6, "-1": 7, [Symbol.for(0)]: 8 };
// use Object.keys() to show all properties of the object
['0', '1', '2', 'a', 'c', 'b', '-1']
// use Reflect.ownKeys() to show all properties of the object
['0', '1', '2', 'a', 'c', 'b', '-1', Symbol(1), Symbol(0)]
// use JSON.stringify() to show all properties of the object
'{"0":4,"1":3,"2":6,"a":0,"c":1,"b":2,"-1":7}'
// fold mode. hint: This value was evaluated upon first expanding. It may have changed since then.
{0: 4, 1: 3, 2: 6, a: 0, c: 1, b: 2, -1: 7, Symbol(1): 5, Symbol(0): 8 }
// unfold mode
{
0: 4,
1: 3,
2: 6,
-1: 7
a: 0,
b: 2,
c: 1,
Symbol(0): 8,
Symbol(1): 5
}
Reflect.ownKeys、Object.getOwnPropertyNames和Object.getOwnPropertySymbols的属性顺序是可预测且可靠的,由 ECMAScript 规范保证。而for...in、Object.keys和JSON.stringify的属性顺序是根据浏览器具体实现相关的排序算法所决定的,是不可预测且不可靠的。
-
数字属性名 - 字符串形式的数字属性,会先转换成数字,但不包括负数。
-
Reflect.enumerate- 已废弃,较新版本的浏览器已经移除该方法。
对象属性
JavaScript 对象的数字属性被称为排序属性,字符串 属性被称为命名属性。隐藏类由指针 map 寻址,排序属性由指针 elements 寻址,命名属性由指针 properties 寻址。
与 map、elements 和 properties 同层级的其他属性被称为对象内属性,保存在对象本身,访问速度最快。当命名属性数量比较少时,指针 properties 会以线性结构有序保存属性,被称为快属性;当命名属性数量比较多时,指针 properties 会以非线性结构无序保存属性,被称为慢属性。
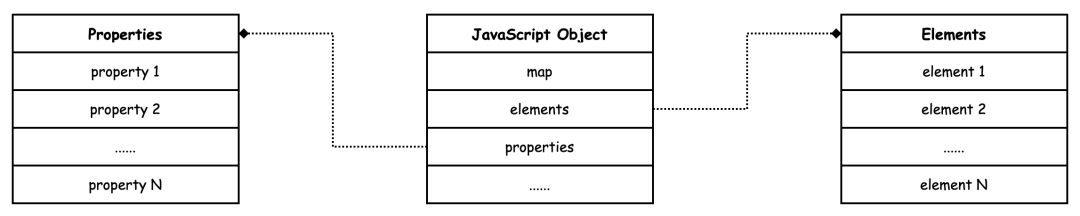
对象是一系列键值对的集合,通常是以字典的形式进行存储的。但字典是非线性的数据结构,查询效率会低于线性数据结构。考虑到绝大多数对象的可枚举属性比较有限,因此 V8 为这类对象开辟线性的存储空间以提升存储和访问的效率。
为解析 V8 的对象属性管理机制,在新版本 Chrome 浏览器做以下论证。
图 a 与图 b 均是正整数形式的字符串,区别在于后者会有前缀。如图所示,由中括号包裹的属性为排序属性,否则为命名属性。前者被认定为数字属性,后者被认定为字符串属性。也就是说,数字属性并不是根据类型转换后的结果才判定的。
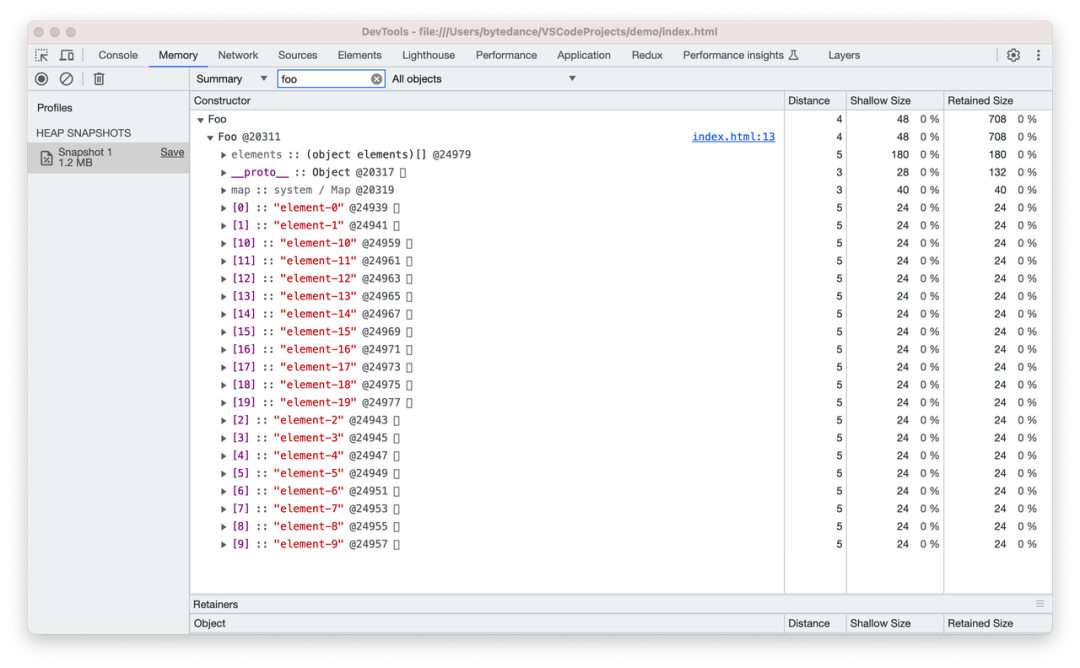 a)无前缀正整数字符串
a)无前缀正整数字符串
 b)有前缀正整数字符串
b)有前缀正整数字符串
考虑到数字属性的有序性,所以排序属性均由指针 element 寻址,但相较于对象内属性会多一次索引查询。当命名属性数量小于等于 9 个时,见图 c,会以对象内属性的形式直接存储到对象本身,大于 9 个的部分则根据创建顺序有序存储于指针 properties 指向的内存区域。
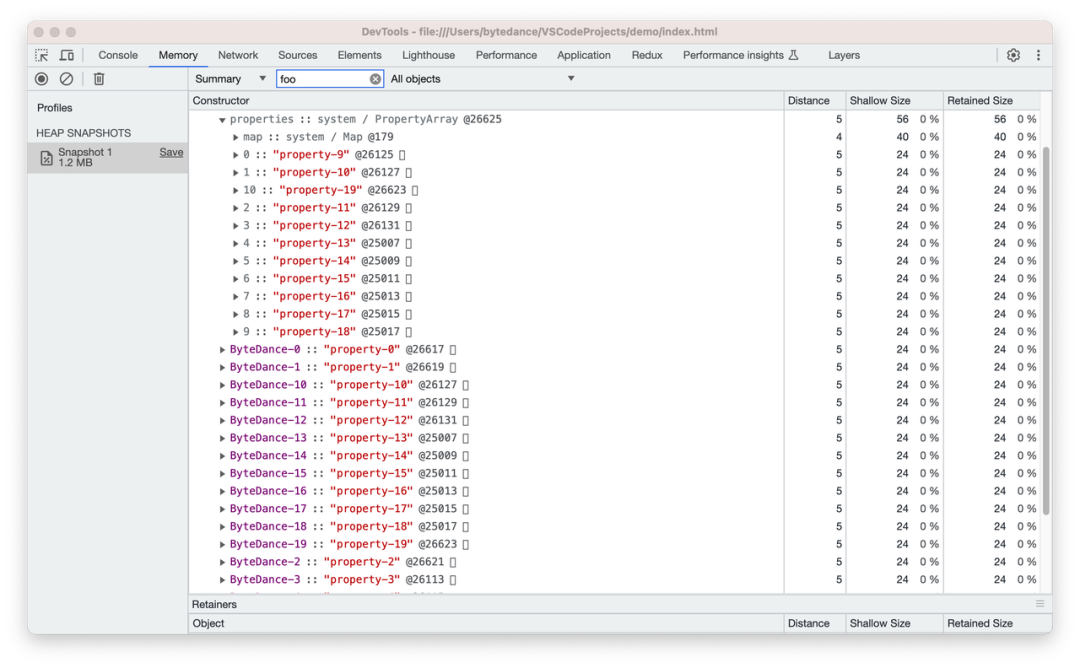 c)循环创建命名属性 20 个
c)循环创建命名属性 20 个
 d)循环创建排序属性和命名属性各 20 个
d)循环创建排序属性和命名属性各 20 个
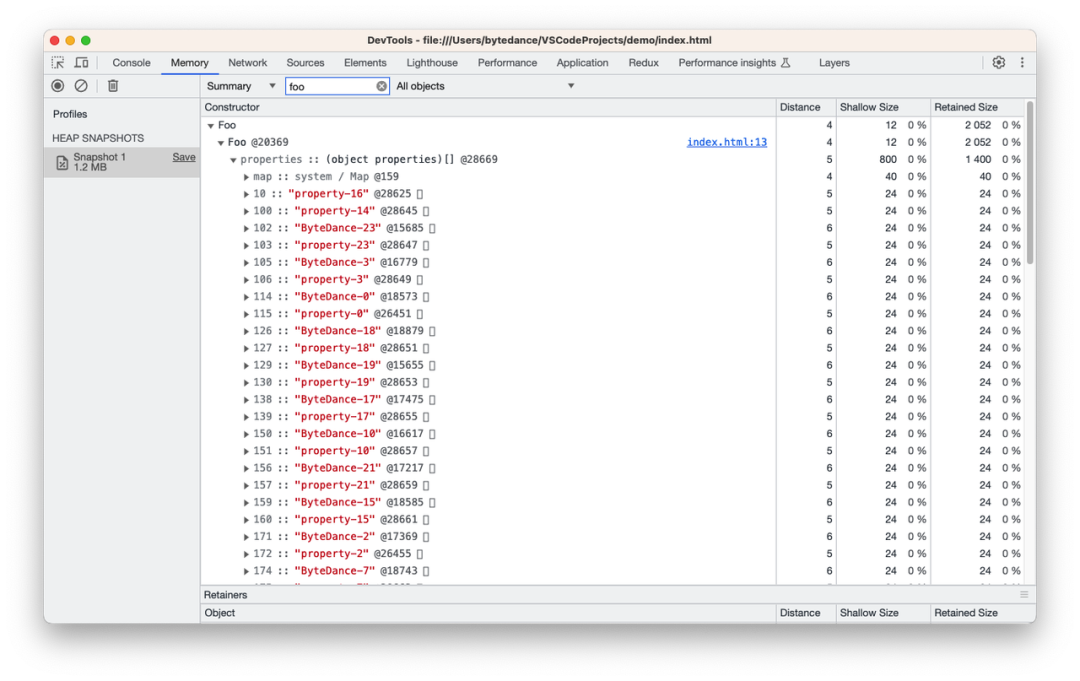
在静态代码里,目标对象每存在一个数字属性,则会增加命名属性的对象内属性的额度。 这里需要注意的是静态代码,可以对比图 c、图 d 和图 e 得出上述结论。图 c 与图 d 的区别在于多了 20 次生成数字属性的循环操作,假设是运行时的动态扩容,那么对象内属性个数应该会增加 20 个,而不是 1 个。
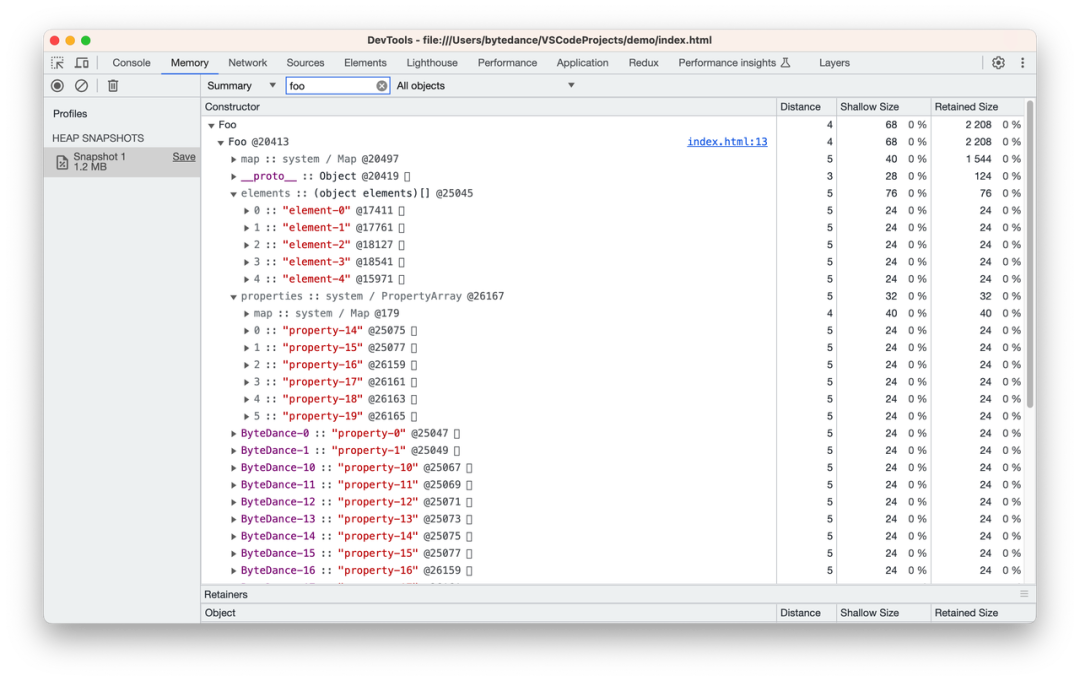 e)静态代码生成数字属性
e)静态代码生成数字属性
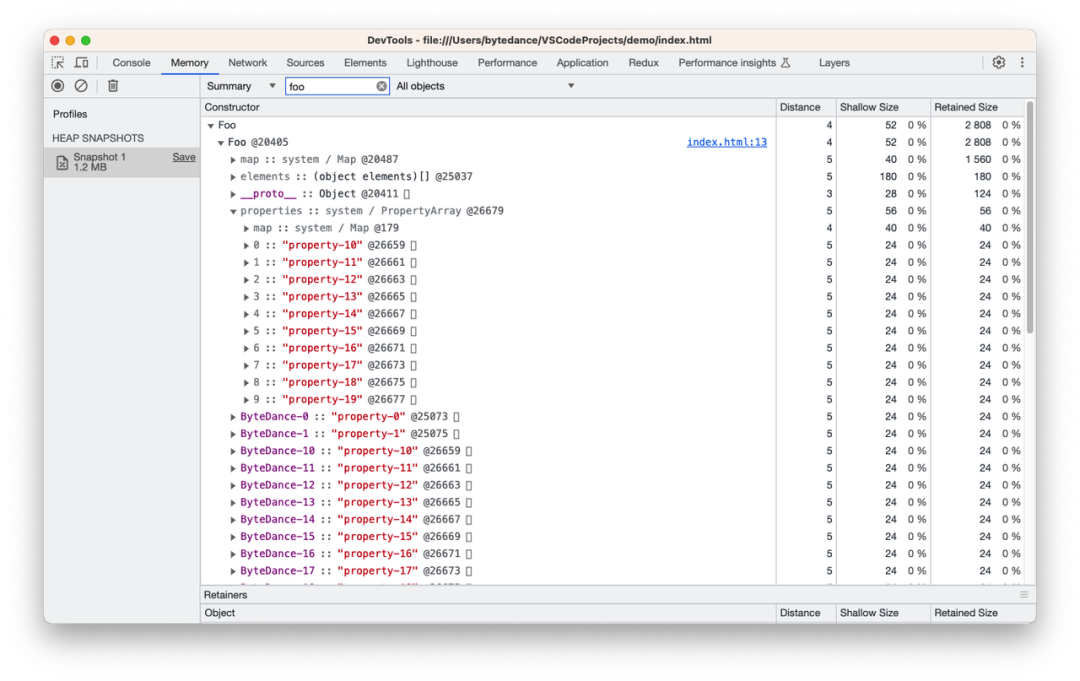 f)快属性降级慢属性个数边界
f)快属性降级慢属性个数边界
图 d 与 图 e 的区别在于前者是利用 for 循环生成 20 个数字属性,而后者是静态代码里手写了 5 个数字属性。不难察觉,前者只扩容了 1 个对象内属性额度,而后者扩容了 5 个对象内属性额度。
在没有触发扩容的前提下,快属性降级慢属性的命名属性边界值为 25 个,如图 c 和图 f 所示,即命名属性数量小于 25 时,properties 指向内存的存储形式为线性结构,大于等于 25 个时,存储形式会变为非线性结构。
// 图a代码
function Foo() {
for (let i = 0; i < 20; i++) {
this[`${i}`] = `property-${i}`;
}
}
// 图b代码
function Foo() {
for (let i = 0; i < 20; i++) {
this[`0${i}`] = `property-${i}`;
}
}
// 图c代码
function Foo() {
for (let i = 0; i < 20; i++) {
this[`ByteDance-${i}`] = `property-${i}`;
}
}
// 图d代码
function Foo() {
for (let i = 0; i < 20; i++) {
this[`${i}`] = `element-${i}`;
}
for (let i = 0; i < 20; i++) {
this[`ByteDance-${i}`] = `property-${i}`;
}
}
// 图e代码
function Foo() {
this['0'] = 'element-0';
this['1'] = 'element-1';
this['2'] = 'element-2';
this['3'] = 'element-3';
this['4'] = 'element-4';
for (let i = 0; i < 20; i++) {
this[`ByteDance-${i}`] = `property-${i}`;
}
}
// 图f代码
function Foo() {
for (let i = 0; i < 25; i++) {
this[`ByteDance-${i}`] = `property-${i}`;
}
}
const foo = new Foo();
综上所述,总结归纳为以下几点:
-
排序属性总由指针 element 寻址。
-
快属性和慢属性是针对于命名属性的底层优化。
-
最早创建的 9 个命名属性以对象内属性的形式存储。
-
触发快属性降级慢属性的条件是命名属性大于等于 25 个。
-
静态代码每次增加数字属性都会扩容对象内属性的数量。
排序属性 - 亦称为数组索引属性,包括数值类型、BigInt 类型、无前缀数字字符串类型。
命名属性 - 亦称为常规属性,非数值型字符串,包括 Symbol。
对象内属性 - In-object Properties,与 properties、elements 处于同一层级,因此少一次寻址操作。
线性结构有序 - elements 为排序后的顺序,properties 为创建时的顺序。
新版本 Chrome 浏览器 - 114.0.5735.198(正式版本) (x86_64)
内存分配
基本类型的值存储于栈空间,引用类型的值存储于堆空间。通常情况下,调用栈用于维护代码执行时的上下文状态,直接影响代码的执行效率,所以内存都不会设置太大,主要用来存放一些基本类型的值和引用类型的地址。而堆空间很大,引用类型占用的空间普遍比较大,所以这一类数据会被存放到堆中。但堆空间分配内存和回收内存会占用较长的时间。为了节约内存开销,基本类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址。
const foo = () => {
const a = 'JIMU';
const b = a;
const c = { team: 'JnQ' };
const d = c;
};
foo();
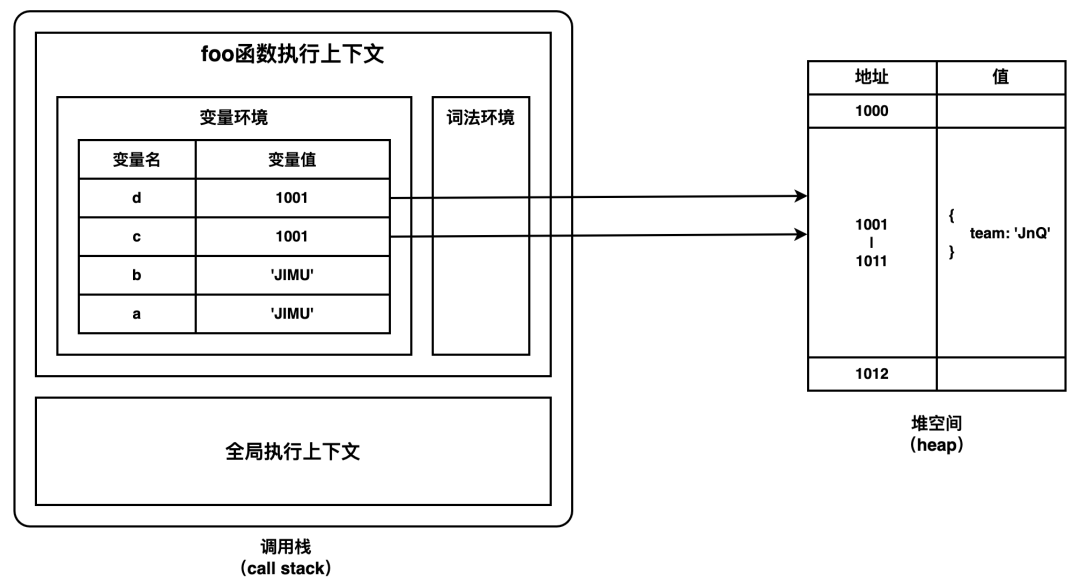
内存管理
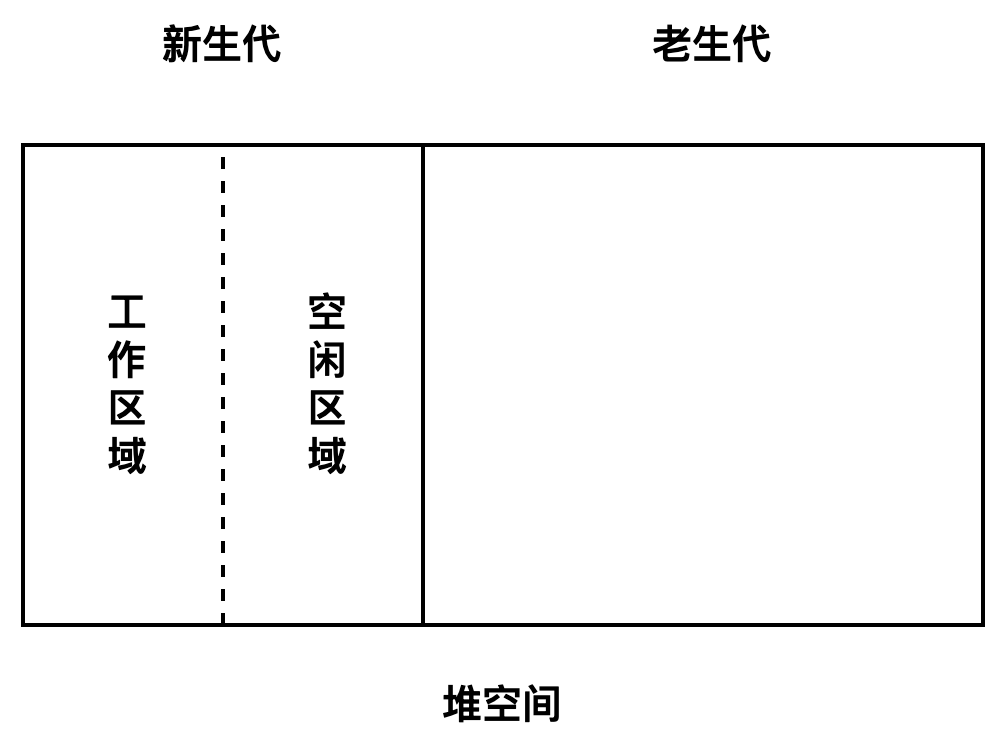
垃圾回收算法被分为两种,一个是 Major GC,主要使用了 Mark-Sweep & Mark-Compact 算法,针对的是堆内存中的老生代进行垃圾回收;另外一个是 Minor GC,主要使用了 Scavenger 算法,针对于堆内存中的新生代进行垃圾回收。V8 引擎的新生代内存大小 32MB(64 位)、16MB(32 位) ;老生代初始内存大小为 512MB(64 位)、256MB(32 位),默认配置下最大可以增加到 4GB。
const int kSystemPointerSize = sizeof(void*); // 32位 -> 4;64位 -> 8
static const int kHeapLimitMultiplier = kSystemPointerSize / 4;
// 老生代初始极值
static const size_t kMaxInitialOldGenerationSize = 256 * MB * kHeapLimitMultiplier;
static const size_t kOldGenerationLowMemory = 128 * MB * kHeapLimitMultiplier;
-
新生代(new space),大多数的对象开始都会被分配在这里,这个区域相对较小但是垃圾回收特别频繁,该区域被分为两半,一半用来分配内存,另一半用于在垃圾回收时将需要保留的对象复制过来。
-
Semi Space,from space 和 to space 动态更换。
-
采用Scavenge算法(复制算法)进行垃圾回收。
-
对象晋升:对象是否经历过一次 Scavenge 算法;To 空间的内存占比是否已经超过 25%。
-
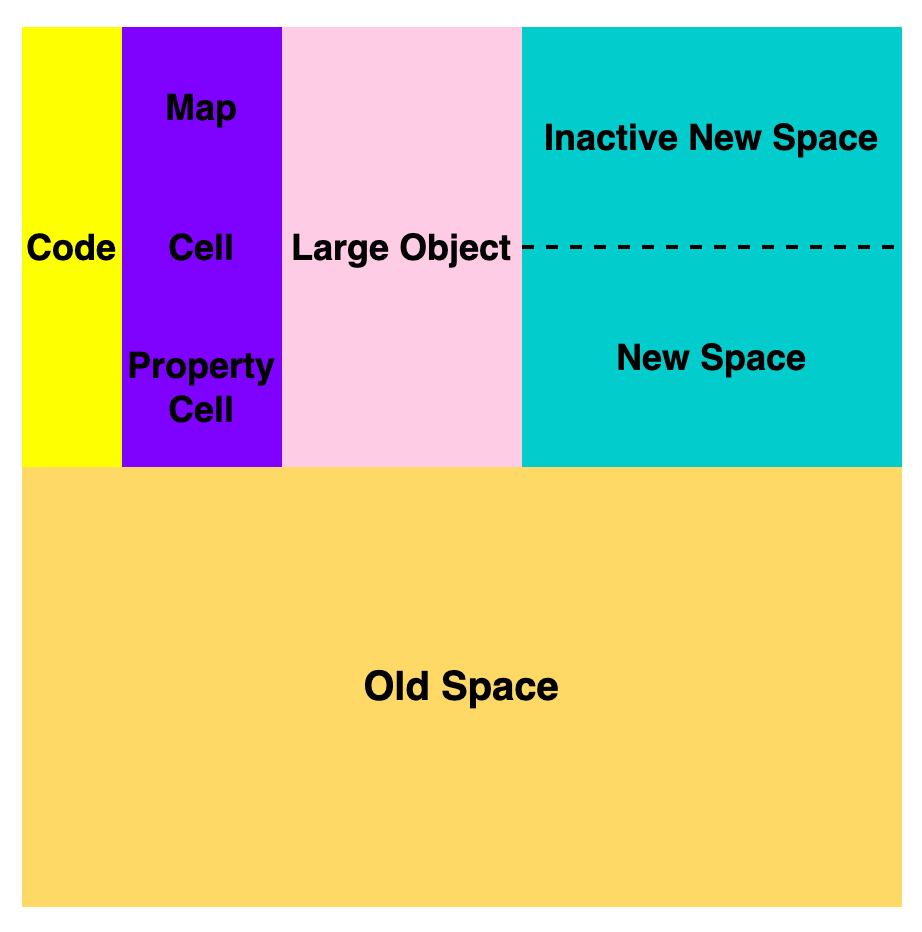
老生代(old space),新生代中的对象在存活一段时间后就会被转移到老生代内存区,相对于新生代该内存区域的垃圾回收频率较低。老生代又分为老生代指针区和老生代数据区,前者包含大多数可能存在指向其他对象的指针的对象,后者只保存原始数据对象,这些对象没有指向其他对象的指针。
-
大对象区(large object space):存放体积超越其他区域大小的对象,每个对象都会有自己的内存,垃圾回收不会移动大对象区。
-
代码区(code space):代码对象,会被分配在这里,唯一拥有执行权限的内存区域。
-
Map 区(map space):存放 Cell 和 Map,每个区域都是存放相同大小的元素,结构简单,可以理解为隐藏类。
JavaScript 在运行时,对象的属性是可以被修改的,这对于 V8 是存在不确定性的。像 C++ 这类静态语言,在编译阶段就确定对象的结构,可以直接通过偏移量来查询目标对象的各项属性值,因此运行效率非常高。V8 对每个对象做出两个假设:
-
对象创建完成后不会添加新的属性。
-
对象创建完成后不会删除属性。
基于上述假设,V8 会给每个对象创建隐藏类(Hideen Class),用于记录该对象的基础布局信息,具体包括:
-
对象的所有属性。
-
所有属性的相对偏移值。
那么当 V8 访问某个对象的某个属性时,就会先去隐藏类中查找该属性相对于该对象的偏移量,也就能去内存中直接取值,从而跳过一系列的查找过程,大大提升 V8 查找对象的属性值的效率。
V8 的每个对象都有 map 属性,该字段指向该对象的隐藏类。当两个对象的结构相同时,就会复用同一个隐藏类,这样可以减少隐藏类的创建次数以及减少存储空间。而当结构发生变更时,就会重新创建隐藏类。因此在开发过程中,为提高 V8 引擎性能,需要注意以下几点:
-
尽量使用字面量一次性初始化完整的对象属性。
-
尽量保证初始化时属性的顺序一致。
-
尽量避免使用 delete 方法。
// --allow-natives-synta 指向同一地址,故复用同一个隐藏类
const JnQ = { name: 'JnQ', owner: 'Qi Huang', TL: 'Sijie Cai' };
const TCSplus = { name: 'TCS', owner: 'Guangyu Song', TL: 'Sijie Cai' };
// 重新创建隐藏类 Case 1
const JnQInfo = {}; // 新建隐藏类第 1 次
JnQInfo.platform = ['Jimu', 'Juren', 'Rock']; // 新建隐藏类第 2 次
JnQInfo.member = 13; // 新建隐藏类第 3 次
JnQInfo.meeting = 'Firday'; // 新建隐藏类第 4 次
// 重新创建隐藏类 Case 2
const JnQInfo = { platform: ['Jimu', 'Juren', 'Rock'], member: 13, meeting: 'Firday' }; // 新建隐藏类第 1 次
delete JnQInfo.meeting; // 新建隐藏类第 2 次
delete JnQInfo.platform; // 新建隐藏类第 3 次
// 重新创建隐藏类 Case 3
const jimu = { member: 8, owner: 'Zhihao Cao' }; // 新建隐藏类第 1 次
const quality = { owner: 'Xue Zhang', member: 4 }; // 新建隐藏类第 2 次
新生代内存大小 - 网传主流说法,没有找到具体的源码,仅做参考。
结构相同 - 相同的属性名称;相等的属性个数;一致的属性顺序。
垃圾回收
-
根节点认定:全局对象;本地函数的局部变量和参数;当前嵌套调用链上的其他函数的变量和参数。
-
标记-整理
-
经历一次标记-清除后,内存空间可能会出现不连续的状态,即内存碎片;
-
假设在老生代中有 A、B、C、D 四个对象;
-
在垃圾回收的标记阶段,将对象 A 和对象 C 标记为活动的;
-
在垃圾回收的整理阶段,将活动的对象往堆内存的一端移动;
-
在垃圾回收的清除阶段,将活动对象左侧的内存全部回收。
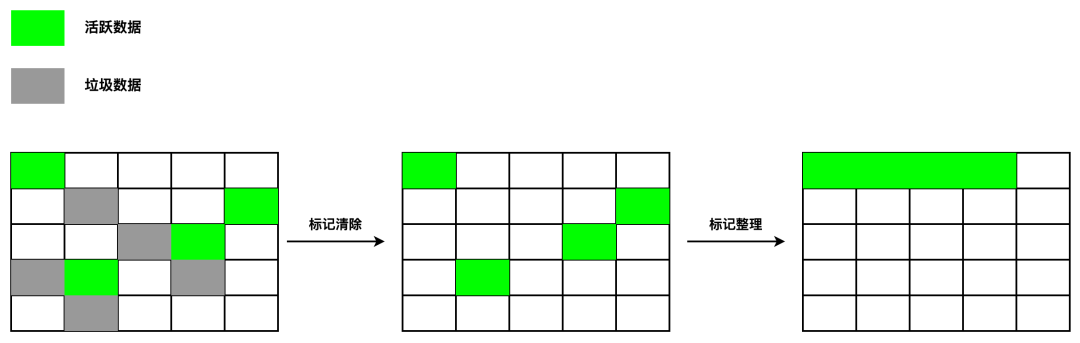
-
增量标记
-
由于 JS 的单线程机制,垃圾回收的过程会阻碍主线程同步任务的执行,待执行完垃圾回收后才会再次恢复执行主任务的逻辑,这种行为被称为全停顿(stop-the-world)。在标记阶段同样会阻碍主线程的执行,一般来说,老生代会保存大量存活的对象,如果在标记阶段将整个堆内存遍历一遍,那么势必会造成严重的卡顿。
-
因此,为了减少垃圾回收带来的停顿时间,V8 引擎又引入了Incremental Marking(增量标记)的概念,即将原本需要一次性遍历堆内存的操作改为增量标记的方式,先标记堆内存中的一部分对象,然后暂停,将执行权重新交给 JS 主线程,待主线程任务执行完毕后再从原来暂停标记的地方继续标记,直到标记完整个堆内存。这个理念其实有点像 React 框架中的 Fiber 架构,只有在浏览器的空闲时间才会去遍历Fiber Tree执行对应的任务,否则延迟执行,尽可能少地影响主线程的任务,避免应用卡顿,提升应用性能。
-
得益于增量标记的好处,V8 引擎后续继续引入了延迟清理(lazy sweeping)和增量式整理(incremental compaction),让清理和整理的过程也变成增量式的。同时为了充分利用多核 CPU 的性能,也将引入并行标记和并行清理,进一步地减少垃圾回收对主线程的影响,为应用提升更多的性能。
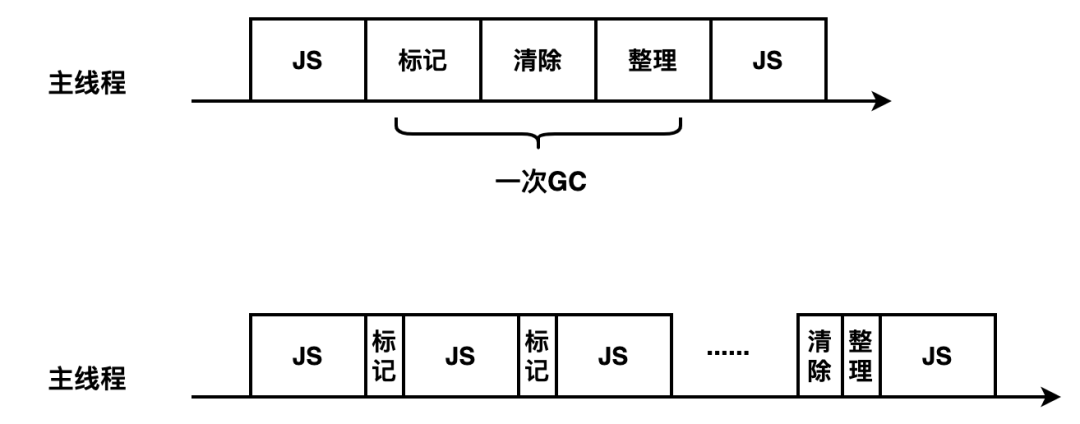
编译解析
编译型语言在程序执行之前,需要经过编译器的编译过程,并且编译之后会直接保留机器能读懂的二进制文件,这样每次运行程序时,都可以直接运行该二进制文件,而不需要再次重新编译了。比如 C/C++、GO 等都是编译型语言。而由解释型语言编写的程序,在每次运行时都需要通过解释器对程序进行动态解释和执行。比如 JavaScript、Python 等都属于解释型语言。
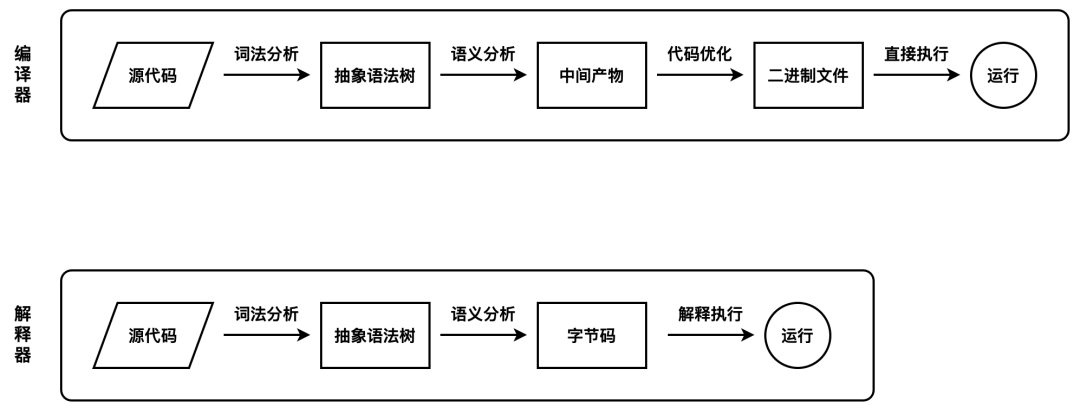
V8 在执行过程中既有解释器 Ignition[4],又有编译器 TurboFan[5],此外较新版本的 Chrome 增加了一种中间层编译器 Maglev[6],V8 可以使用 jsvu[7] 进行本地调试。
解释编译具体步骤包括:
-
生成抽象语法树和执行上下文
-
词法分析,即分词(tokenize),根据预设规则将每一行代码拆分成不可再分的 tokens。
-
语法分析,即解析(parse),根据语法规则将 tokens 组合转化为抽象语法树。
-
执行上下文,代码执行过程中的环境信息。
-
生成字节码
-
字节码[8]介于 AST 和机器码之间。字节码需要通过解析器将其转换为机器码后才能执行。
-
解释器 Ignition 会根据 AST 生成字节码,并解释执行字节码。
-
V8 最早并没有字节码,直接将 AST 转换为机器码效率更加高效,但机器码的内存占用远远大于字节码,这在移动端的问题更加突出。
// JavaScript Code - 8 lines of code
const foo = (day) => {
const department = 'Data-TnS-FE';
const team = 'JnQ';
return day % 2 === 0 ? department : team;
};
for (let day=0; day < 0x20227; day++) {
foo(day);
}
// V8 bytecode - 19 lines of code
// --print-bytecode
CreateClosure [0], [0], #0
StaCurrentContextSlot [2]
LdaZero
Star11
LdaUndefined
...
// Machine Code - 140 lines of code
// --print-code
REX.W leaq rbx,[rip+0xfffffff9]
REX.W cmpq rbx,rcx
jz 0x174944159 <+0x19>
movl rdx,0x84
call [r13+0x50a0]
int3l
movl rbx,[rcx-0xc]
REX.W addq rbx,r14
testb [rbx+0x16],0x20
jnz 0x1149c5a00 (CompileLazyDeoptimizedCode) ;; near builtin entry
...
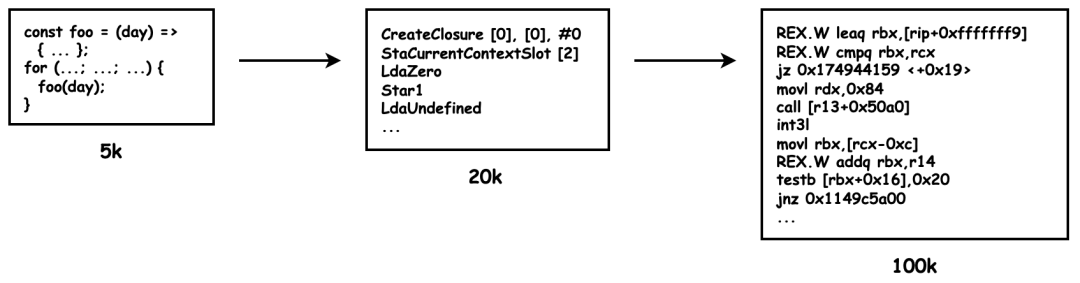
-
执行代码
-
Ignition 负责生成、解析和执行字节码。执行字节码的过程中如果发现一段代码被重复执行多次,就会将其标记为为热点代码(HotSpot),那么后台的编译器 TurboFan 就会把该段热点字节码编译为更为高效的机器码(即时编译,JIT),当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就可以兼顾代码的执行效率和内存占用。
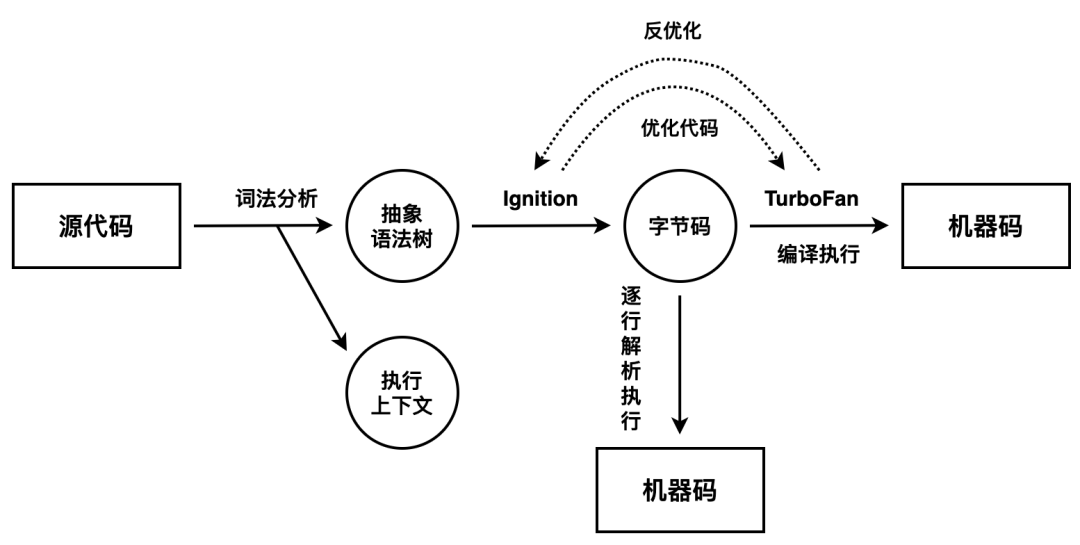
惰性解析是指解析器在解析的过程中,如果遇到函数声明,那么会跳过函数内部的代码,并不会为其生成 AST 和字节码,而仅仅生成顶层代码的 AST 和字节码。
-
一次性解析和编译所有的 JavaScript 代码会增加编译时间,严重影响到首次执行 JavaScript 代码的速度。
-
一次性解析和编译所有 JavaScript 代码会增加内存占用,解析完成的字节码和编译后的机器代码将会一直占用内存。
Machine Code - 汇编语言本质是机器码的助记符,可以理解为两者等价。
循环机制
事件循环
每个渲染进程都有一个主线程负责处理 DOM、计算样式、排版布局、运行 JavaScript 代码以及响应交互行为。单线程来调度这些任务就需要消息队列和事件循环分别承担任务存储和处理的工作。
渲染进程有专门用来接收其他进程传进来消息的 IO 线程。消息队列的任务类型[9]有很多,如外设输入事件、文件读写、定时器、解析 DOM、样式计算、布局计算、CSS 动画等等。
“先进先出”是队列的特点,鉴于这个属性,就需要解决两个问题。
-
如何处理高优先级的任务。
-
每个宏任务中都包含了一个微任务队列,宏任务执行完成后,会立即执行当前宏任务的微任务队列。
-
如何解决单任务执行时间过长。
消息队列分为执行队列和延迟队列两种。
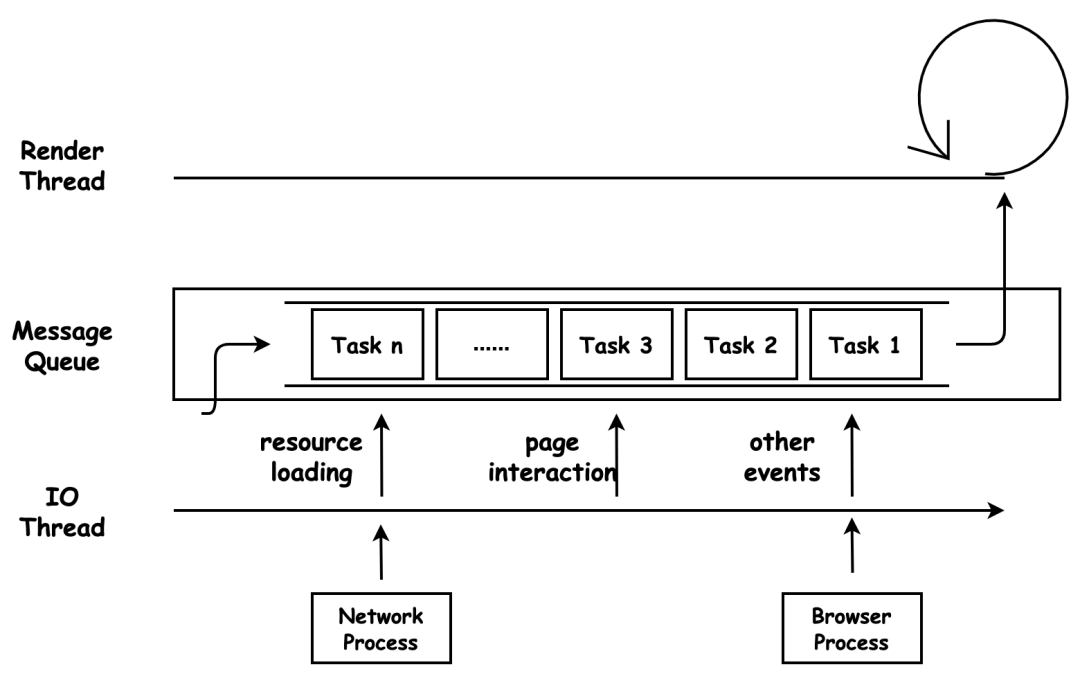
消息队列的任务是通过事件循环来执行的,WHATWG 规范[10]是这么定义事件循环的宏任务执行过程:
-
从多个消息队列中选出一个最老的任务,这个任务称为 oldestTask;
-
循环系统记录任务开始执行的时间,并把这个 oldestTask 设置为当前正在执行的任务;
-
当任务执行完成之后,删除当前正在执行的任务,并从对应的消息队列中删除掉这个 oldestTask;
-
最后统计执行完成的时长等信息。
任务调度
一个事件循环模型有一个或者多个任务队列,任务队列是集合,而不是队列。因为事件循环处理模型从所选队列中选出第一个可执行的任务,而不是按照“先进先出”的原则。微任务队列不是任务队列,每个事件循环模型只且只有一个微任务队列,微任务队列是队列实现。并非所有事件都使用任务队列进行调度;许多是在其他任务执行期间派生的。
immediate_incoming_queue; // PostTask enqueues tasks here
immediate_work_queue; // SequenceManager takes immediate tasks here.
delayed_work_queue; // PostDelayedTask enqueues tasks here.
delayed_incoming_queue; // SequenceManager takes delayed tasks here.
immediate_incoming_queue存放的任务在immediate_work_queue清空以后进入等待执行,为了提高效率,两个队列会在清空时进行职能互换。delayed_incoming_queue中的任务,将在延迟时间到期以后进入delayed_work_queue等待执行。任务产生以后会先进入到相应的incoming_queue等待,work_queue存放即将被执行的任务。
延迟队列用于定时器或其他需要延时执行的任务,例如setTimeout,由于执行任务都由渲染进程主线程来完成的缘故,定时器存在以下几个问题:
-
如果当前任务执行时间过长,会影响定时器任务的执行。
-
定时器存在嵌套关系,最短时间间隔为 4 毫秒[11]。
-
未激活的页面,定时器最小执行间隔是 1000 毫秒。
-
延迟执行时间的最大值是 2147483647 毫秒(约 24.8 天)。
异步回调有两种形式,第一种是把异步回调函数封装成一个宏任务,添加到消息队列尾部,当循环系统执行到该任务的时候执行回调函数;第二种方式的执行时机是在主函数执行结束之后、当前宏任务结束之前执行回调函数,这通常都是以微任务形式体现的。
在当前宏任务中的 JavaScript 快执行完成时,也就在 JavaScript 引擎准备退出全局执行上下文并清空调用栈的时候,JavaScript 引擎会检查全局执行上下文中的微任务队列,然后按照顺序执行队列中的微任务。如果在执行微任务的过程中,产生了新的微任务,同样会将该微任务添加到微任务队列中,V8 引擎一直循环执行微任务队列中的任务,直到队列为空才算执行结束。也就是说在执行微任务过程中产生的新的微任务并不会推迟到下个宏任务中执行,而是在当前的宏任务中继续执行。
早期 Mutation Event 采用观察者的设计模式,当 DOM 有变动时就会立刻触发相应的事件,这种方式属于同步回调,频繁触发会导致页面性能问题。MutationObserver 将响应函数改成异步调用,可以不用在每次 DOM 变化都触发异步调用,而是等多次 DOM 变化后,一次触发异步调用,同时为了保证实时性,MutationObserver 触发的回调会进入微任务队列。
2147483647 毫秒 - Chrome、Safari、Firefox 都是以 32 个 bit 来存储延时值,超出
的最大范围则会立即执行(等价于 0 毫秒)。
页面渲染
工作原理
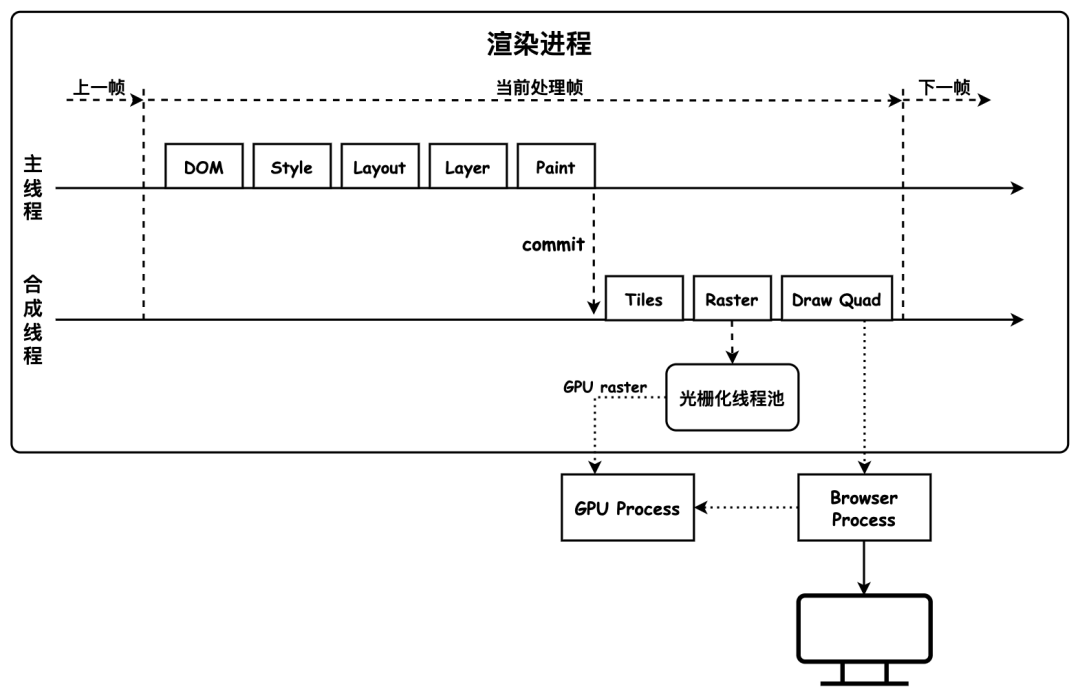
-
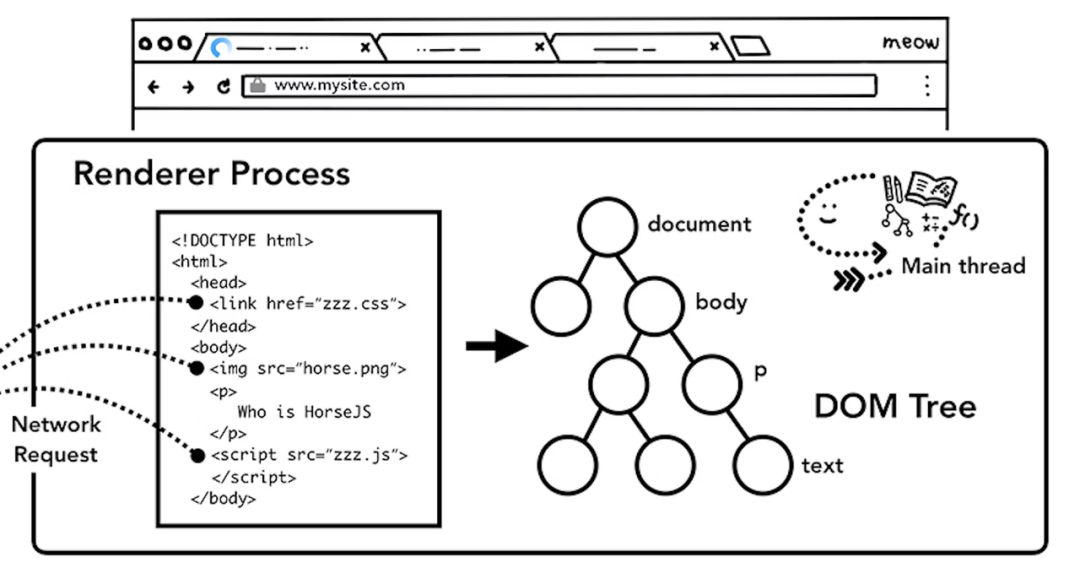
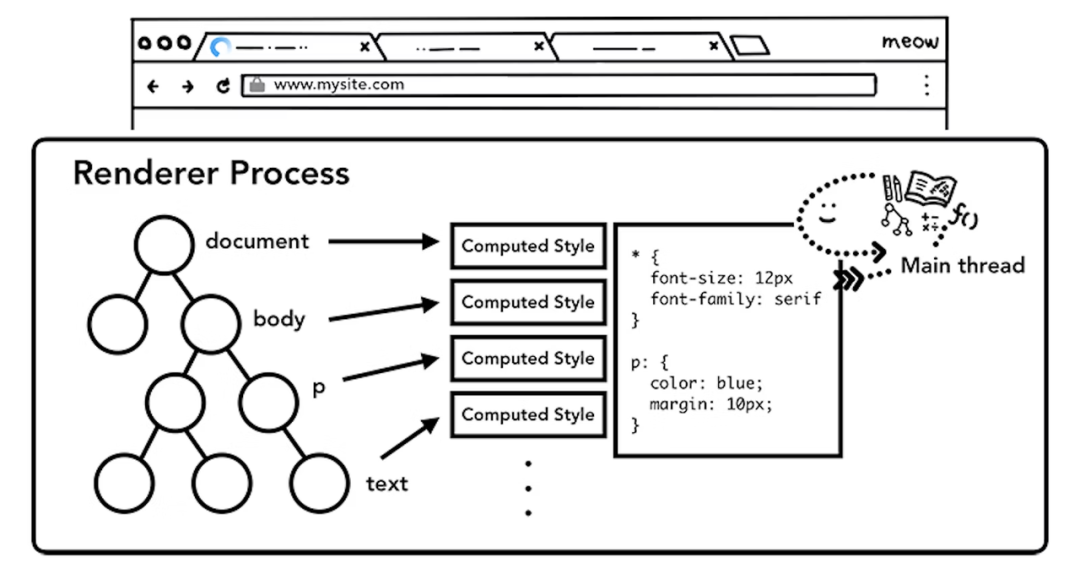
主线程调用 HTML 解析器将 HTML 解析成 DOM 树,根节点即document对象;
-
主线程调用 CSS 解析器将 CSS 解析为 CSSOM 树,即和 DOM 树的节点一一对应的计算样式;
-
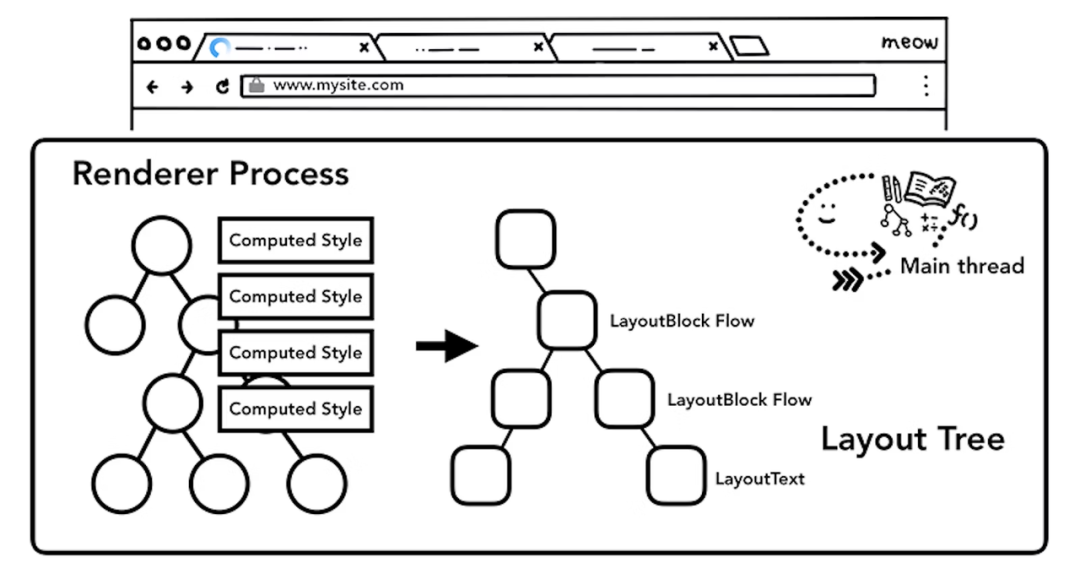
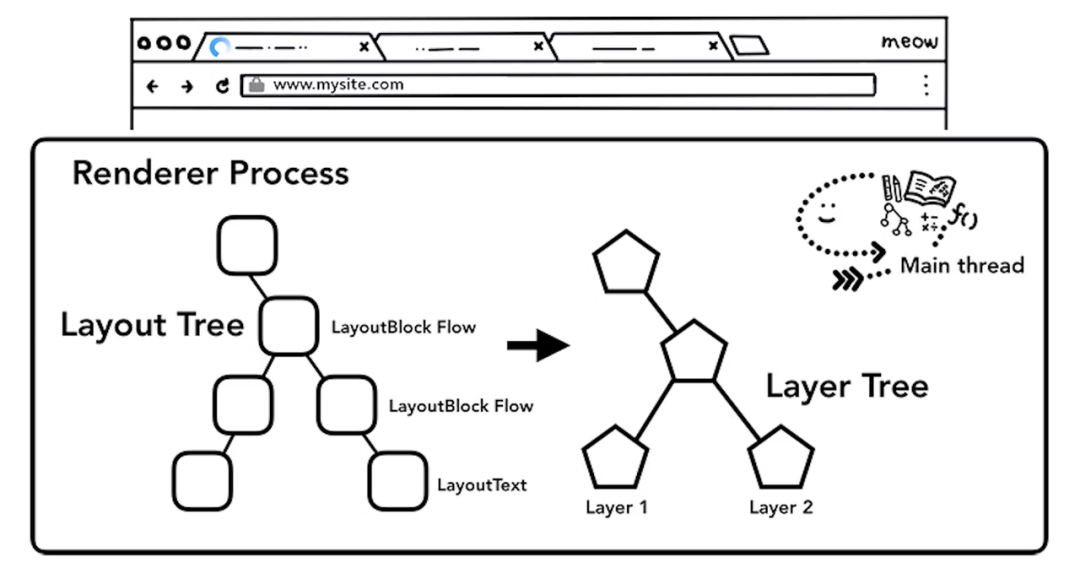
主线程结合 DOM 树和 CSSOM 树,生成布局树(Layout Tree);
-
主线程为特定节点[12]生成专用的图层,构成对应的图层树(Layer Tree);
-
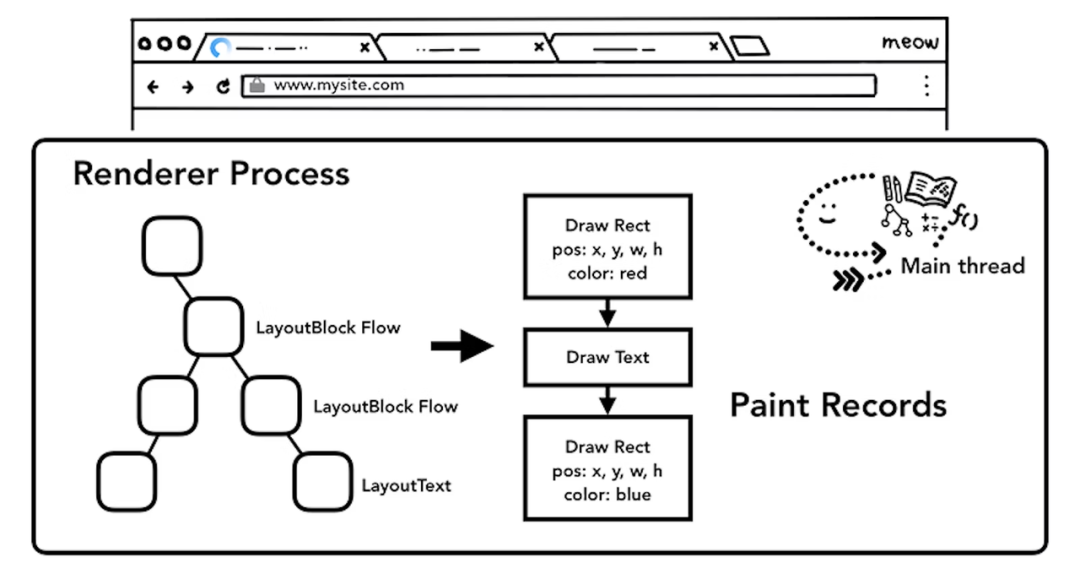
绘制(Paint),主线程将具体工作拆分成多个绘制指令,按序构成待绘制列表(Paint Record);
-
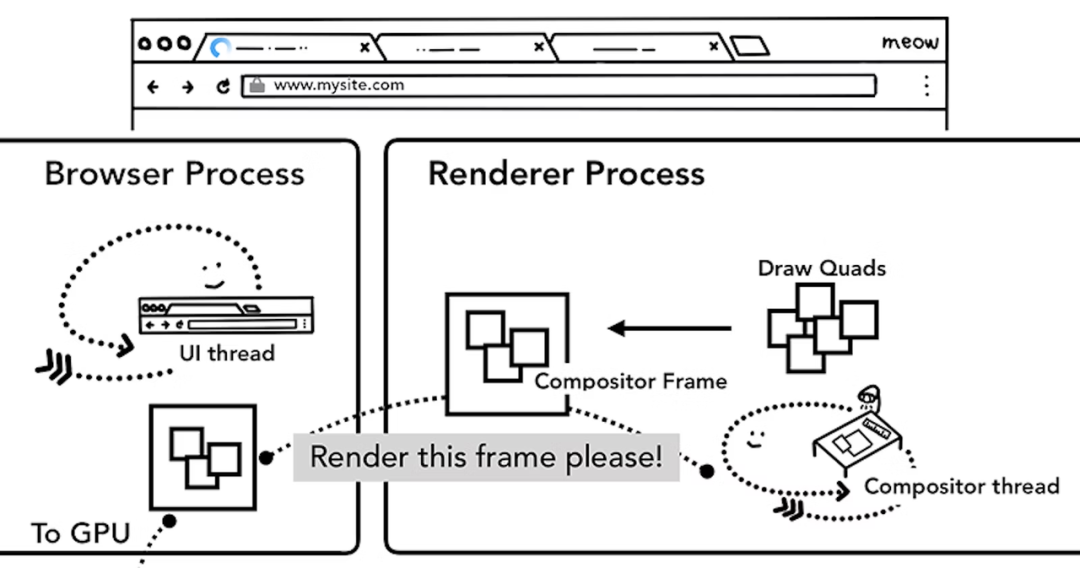
栅格化(Raster),合成线程执行绘制操作,将图层分为图块(Tiles),由栅格化线程将图块转化 位图;
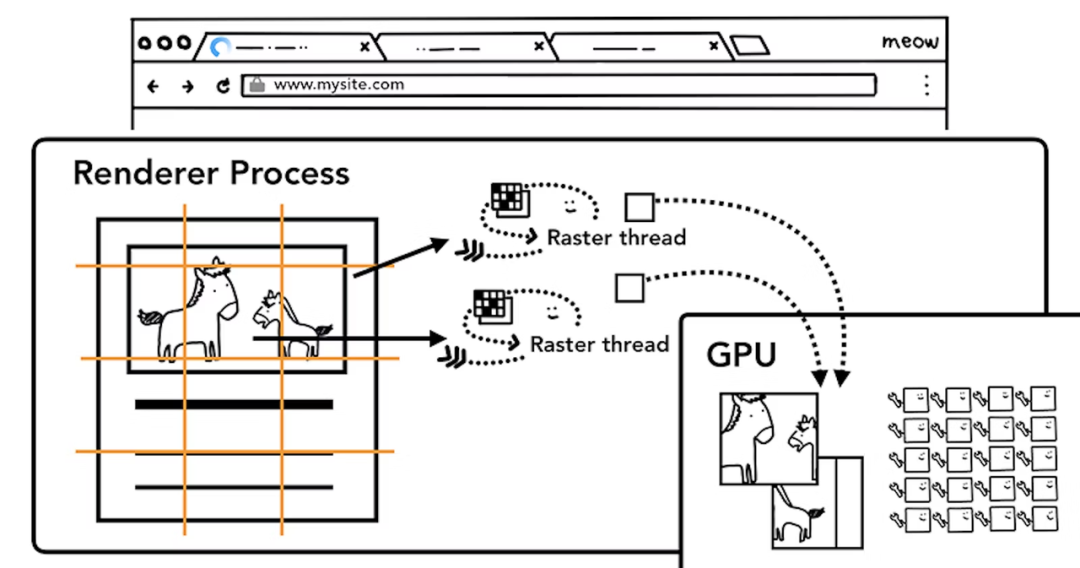
-
合成和显示,完成光栅化后,合成线程会触发 Draw Quad 命令[13],生成合成帧,由 Chromium Viz[14] 完成显示。
重排(reflow),也称为回流,当渲染树节点发生改变且影响节点的几何属性或空间位置。
-
添加或者删除可见的 DOM 元素;
-
元素位置改变 —— display、float、position、overflow 等等;
-
元素尺寸改变 —— 边距、填充、边框、宽度和高度;
-
内容改变 —— 比如文本改变或者图片大小改变而引起的计算值宽度和高度改变;
-
浏览器窗口尺寸改变。
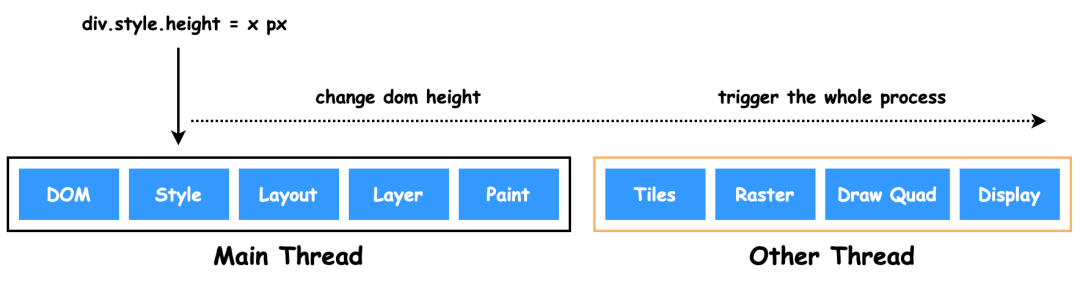
重绘(repaint),渲染树节点发生改变,但不影响该节点在页面中的空间位置和大小。例如:颜色。会跳过 Layout 和 Layer 阶段。
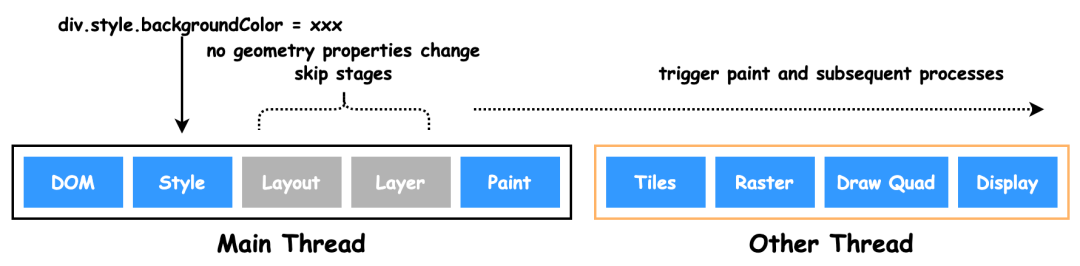
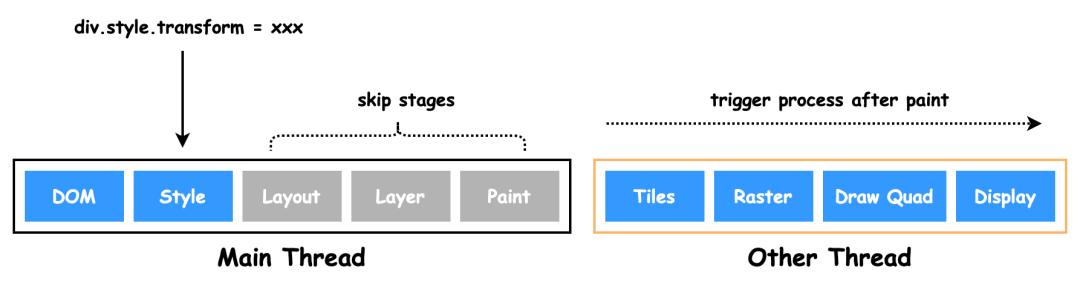
合成(composite),跳过布局和绘制,只执行后续的合成操作。例如:CSS 的 transform。避开重排和重绘,在非主进程上执行合成动画操作,效率最高。
重排必将引起重绘,而重绘不一定会引起重排。
注:另一偏宏观的理解,结合 DOM 树和 CSSOM 树,生成渲染树(Render Tree)。
布局树 - display: none的节点在 DOM 树上,但不会在 Layout 树上;而::before的节点不在 DOM 树上,却会出现在 Layout 树上。
特定节点 - 1.拥有层叠上下文;2.需要剪裁的地方(如超出可视区间的文本);3.滚动条。
图块转换 位图 - 优先处理可视区间(view point)内的图块,保存于 GPU 内存(集成显卡使用主内存;独立显卡使用显存)。
Draw Quad - 图块的内存偏移地址、页面绘制区域等元数据。
合成 帧 - 一系列 Draw Quad 指令的集合。
Chromium Viz - 合成线程通过 IPC 传递给浏览器进程内的 Chromium Viz,再传给 GPU 显示到屏幕上。当触发滚动事件时,合成线程会发送给 GPU 新的合成帧以显示。
常用工具

打开一个网页会启动多个进程,包括浏览器主进程、GPU 进程、渲染进程、插件进程、网络进程等等。从 TCS 页面内唤起一个任务链接,则 TCS 页和任务页会共享同一个渲染进程;而单独新建标签页并输入相同任务的链接,则会新增一个渲染进程。
 a)由 TCS 页面唤起任务子页面
a)由 TCS 页面唤起任务子页面
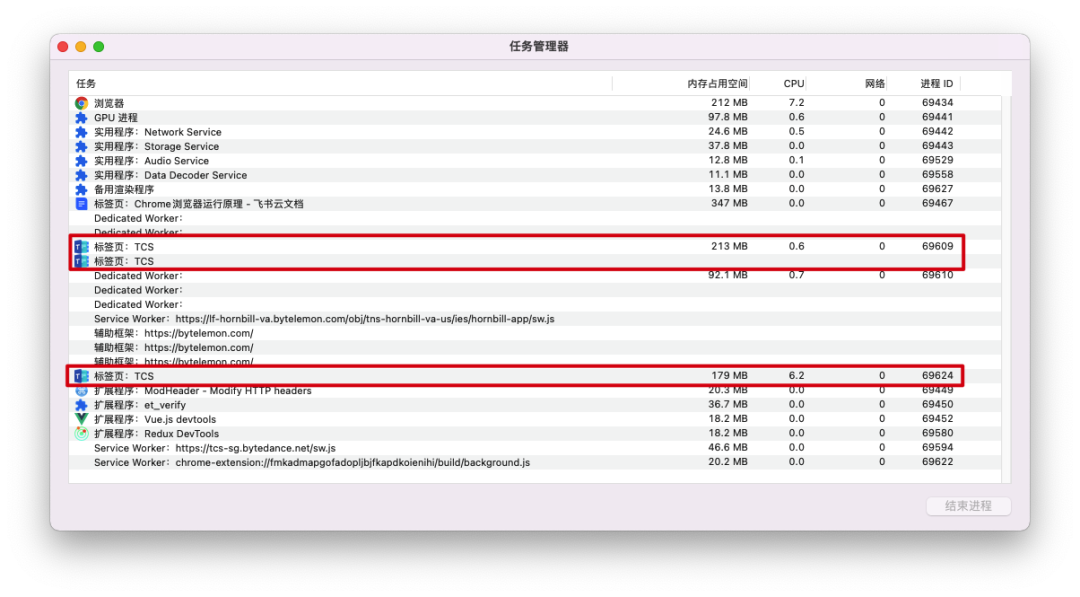 b)新建标签页打开任务链接
b)新建标签页打开任务链接
Chrome 开发者工具有很多重要的面板,比如与性能相关的有网络面板、Performance 面板、内存面板等,与调试页面相关的有 Elements 面板、Sources 面板、Console 面板等。
| 名称 | 描述 |
|---|---|
| Elements | 查看 DOM 结构,编辑 CSS 样式,测试和调整页面显示内容。 |
| Console | JavaScript 的运行 Shell,查看页面中 JavaScript 的交互信息。 |
| Sources | 加载的所有文件,编辑文件内容,支持调试功能。 |
| Network | 页面所有网络请求内容,查看请求行、请求头、请求体、时间线以及请求瀑布图等信息。 |
| Performance | 记录和查看页面生命周期内的各种事件,常用于分析执行过程中影响性能的因素。 |
| Memory | 查看运行过程中的 JavaScript 内存占用情况,追踪是否存在内存泄露的情况。 |
| Application | 查看页面的数据存储情况,PWA 基础数据、IndexedDB、Web SQL、Cookie 等。 |
| Security | 展示安全相关的信息。 |
| Audits | 对当前网页进行网络诊断,给出一些优化建议。 |
| Layers | 展示渲染过程的分层的基础信息。 |
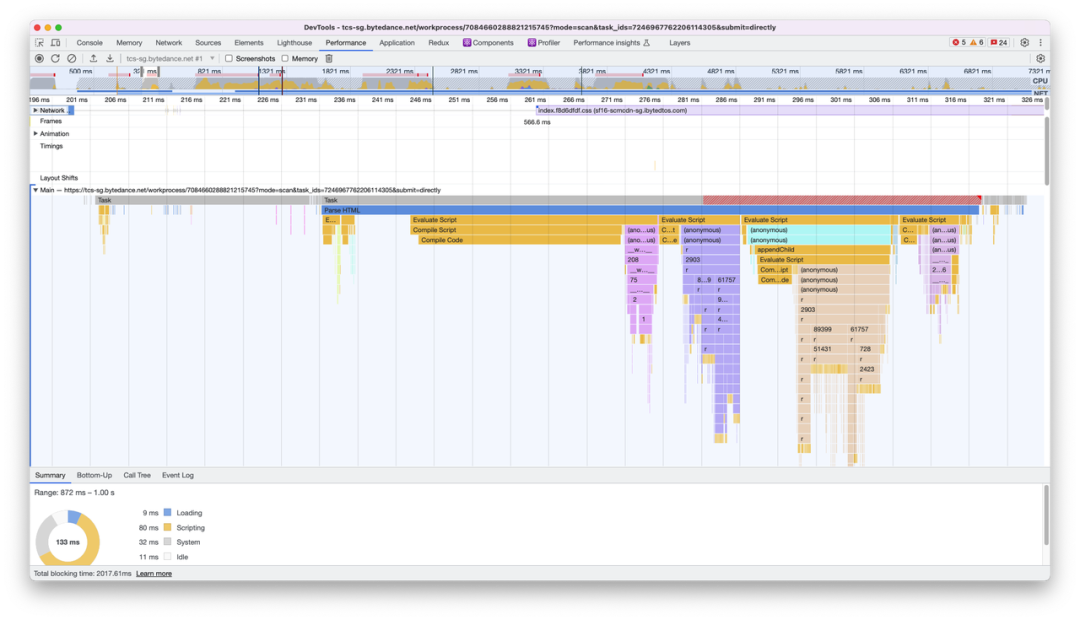
网络面板由控制器、过滤器、抓图信息、时间线、详细列表和下载信息概要 6 个区域构成。
性能优化
加载阶段
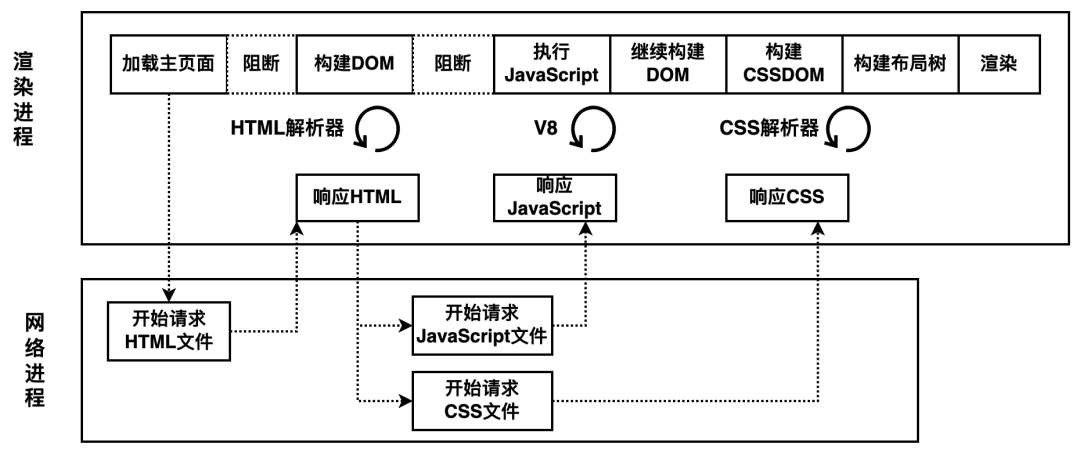
在构建 DOM 的过程中需要 HTML 和 JavaScript 文件,在构造渲染树的过程中需要用到 CSS 文件,以上文件会阻塞首次渲染,被称为关键资源。而图片、音频、视频等文件不会阻塞页面的首次渲染。因此,影响加载阶段的因素包括:
-
关键资源个数。关键资源个数越多,首次页面的加载时间就会越长。
-
关键资源大小。关键资源内容越小,其整个资源的下载时间就越短,阻塞渲染的时间也就越短。
-
请求关键资源需要多少个 RTT(Round Trip Time)。RTT[15] 是网络中一个重要的性能指标,表示从发送端发送数据开始,到发送端收到来自接收端的确认,总共经历的时延。
交互阶段
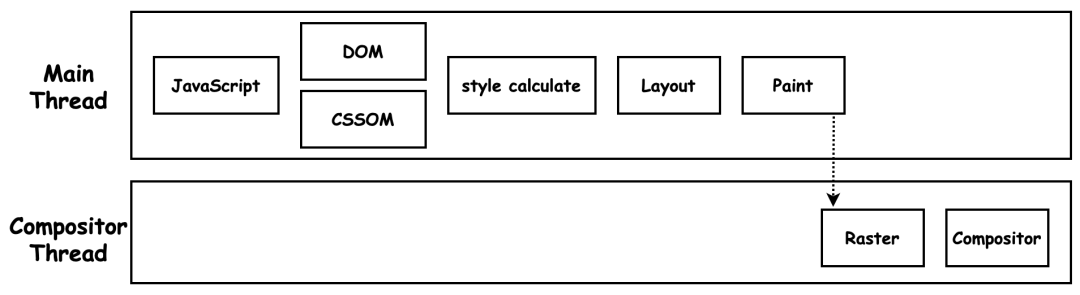
交互阶段优化本质就是帧的渲染速度。大部分的新帧都是由 JavaScript 修改 DOM 或者 CSSOM 而触发的。另外一部分新帧是由 CSS 来触发的,如渐变、变形、动画等特效。
布局信息的修改会导致重排,影响起始于布局阶段,性能开销最大;诸如颜色变化的非布局样式变更则会导致重绘,影响起始于绘制阶段,性能开销较小;而由 CSS 触发的特效,则只会影响合成阶段,且无需渲染主线程参与,因而性能开销最小。因此,影响交互阶段的因素包括:
-
JavaScript 脚本执行时间,JavaScript 的执行会霸占主线程执行其他渲染任务的时间。如果执行时间过长,则会阻塞渲染帧的更新。
-
强制同步布局,JavaScript 强制将计算样式和布局操作提前到当前任务。
const foo = () => {
const main = document.getElementById('root');
const li = document.createElement('li');
const text = document.createTextNode('JnQ Forever');
li.appendChild(text);
main.appendChild(li);
// 此时的offsetHeight还是旧的数据,
// 所以需要立即执行布局操作以获取最新的值
console.log(main.offsetHeight);
};
-
页面布局抖动,JavaScript 执行过程多次触发强制同步布局或抖动操作。
-
频繁的垃圾回收,垃圾回收操作会占用主线程,从而影响到其他任务的执行,严重时会产生掉帧、不流畅的问题,所以尽可能避免小颗粒对象的产生。
强制同步布局 - 正常情况下执行 JavaScript 添加元素是在一个任务中执行的,重新计算样式布局是在另外一个任务中执行。但如果代码里需要获取变更后的样式,则会强制让渲染引擎执行一次布局操作,即强制同步布局。
浏览器安全
页面安全
两个 URL 的协议、域名和端口都相同则称为同源。同源策略在 DOM、Web 数据和网络三个层面均有体现。
-
DOM 同源,页面 A 和页面 B 属于同源网站,且页面 B 由页面 A 唤起,所以在页面 B 的控制台里可以操控页面 A 的 DOM 的展示,其中页面 A 获取到的 opener 指向页面 A 的 window 对象。如果页面 A 和页面 B 的域名不是同源的,那么即使是由页面 A 唤起,页面 B 也无法操作页面 A 的内容。
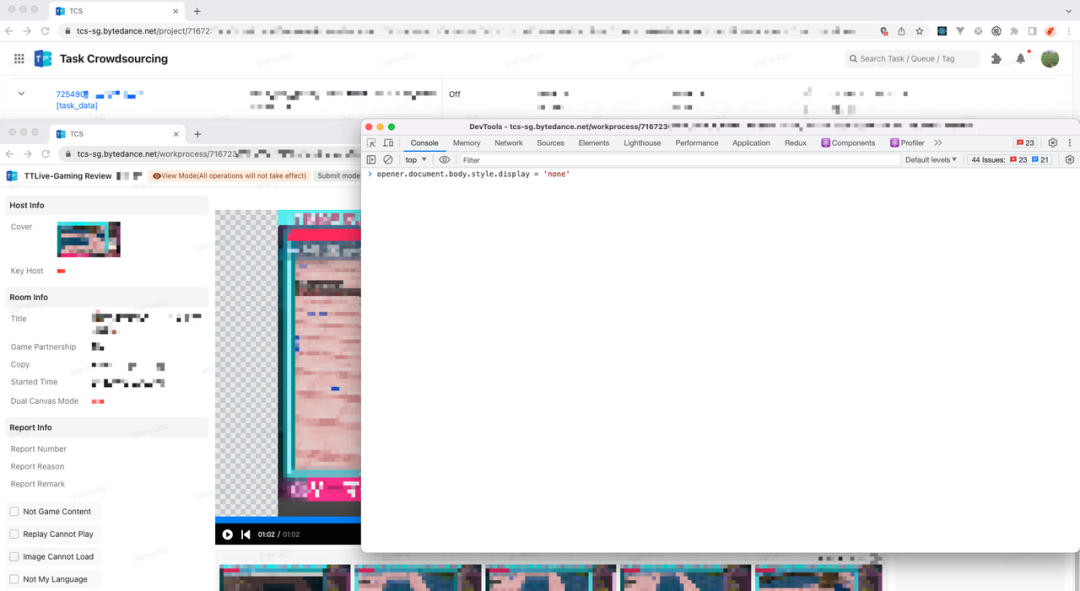 a) 在页面 B 的控制台里输入指令
a) 在页面 B 的控制台里输入指令
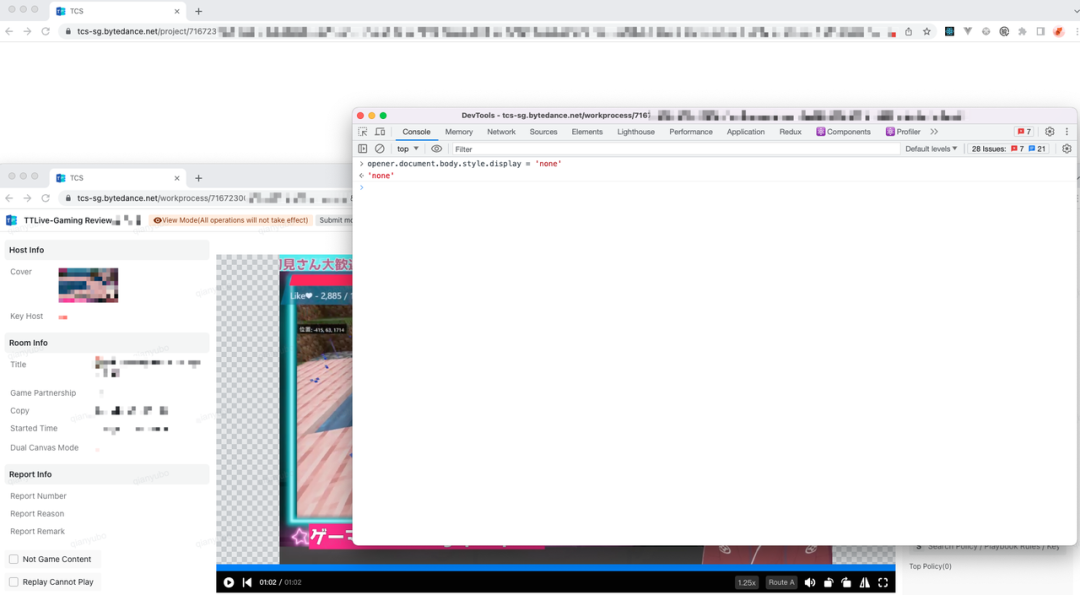
b) 输入的隐藏样式在页面 A 生效
-
数据同源,同源策略限制不同源站点读取当前站点的 Cookie、IndexDB 和 LocalStorage 等数据。
-
网络同源,限制通过 XMLHttpRequest 等方式将站点的数据发送给不同源的站点。
通过 HTML 标签加载的混合资源,只会给出警告,是能够正常加载的。而使用 XMLHttpRequest 时,浏览器会阻止请求。
以下例子中,左图为 JIMU 图片组件(原生标签)加载 http 资源,右图为 JIMU 直播组件(XMLHttpRequest)加载 http 资源。
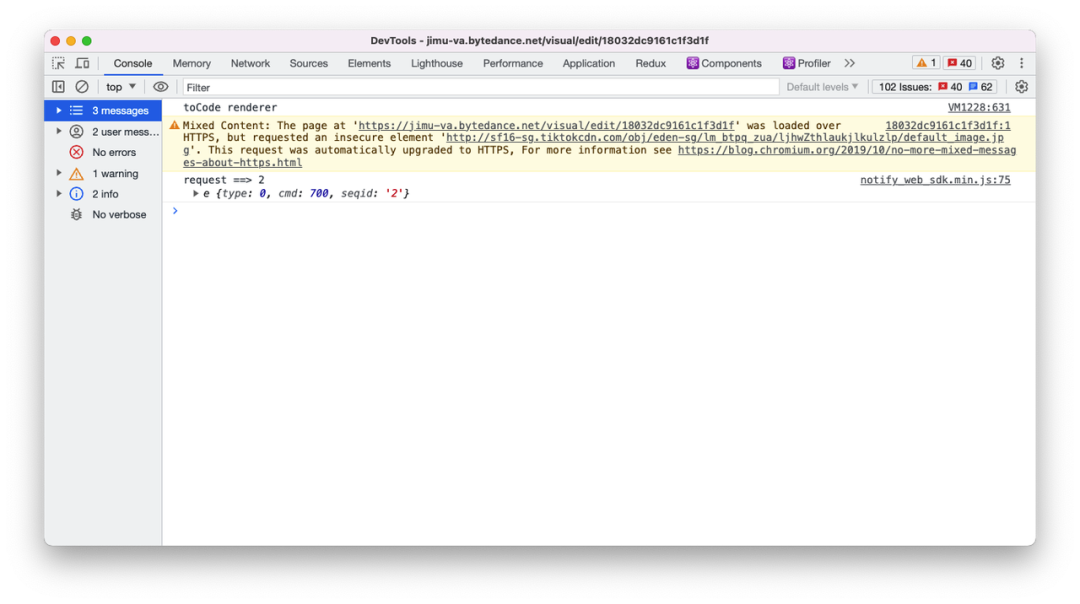
c) 原生标签加载 HTTP 资源
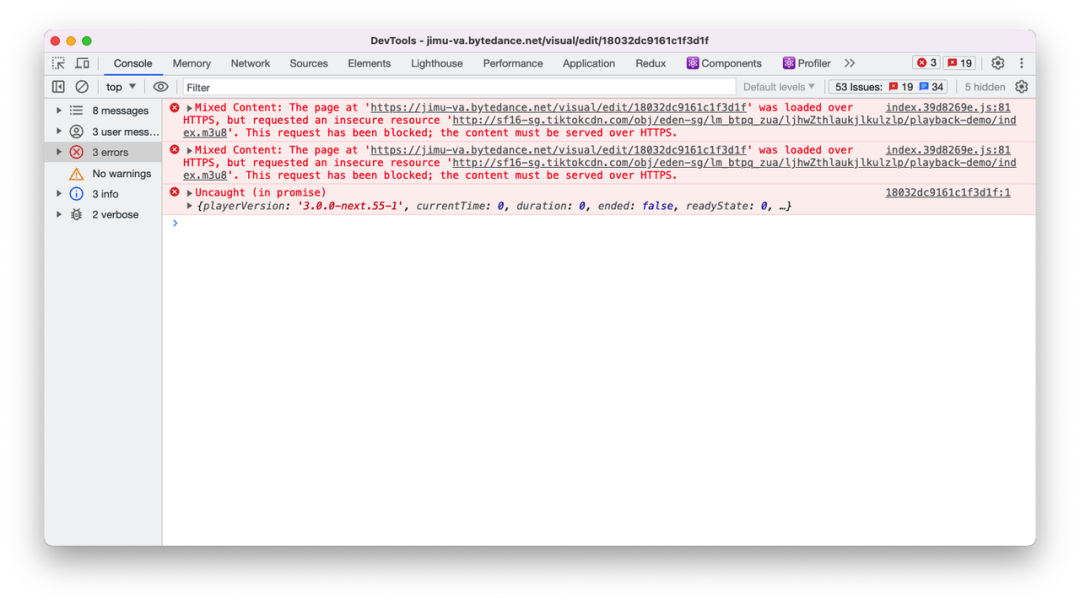
d) XMLHttpRequest 加载 HTTP 资源
系统安全
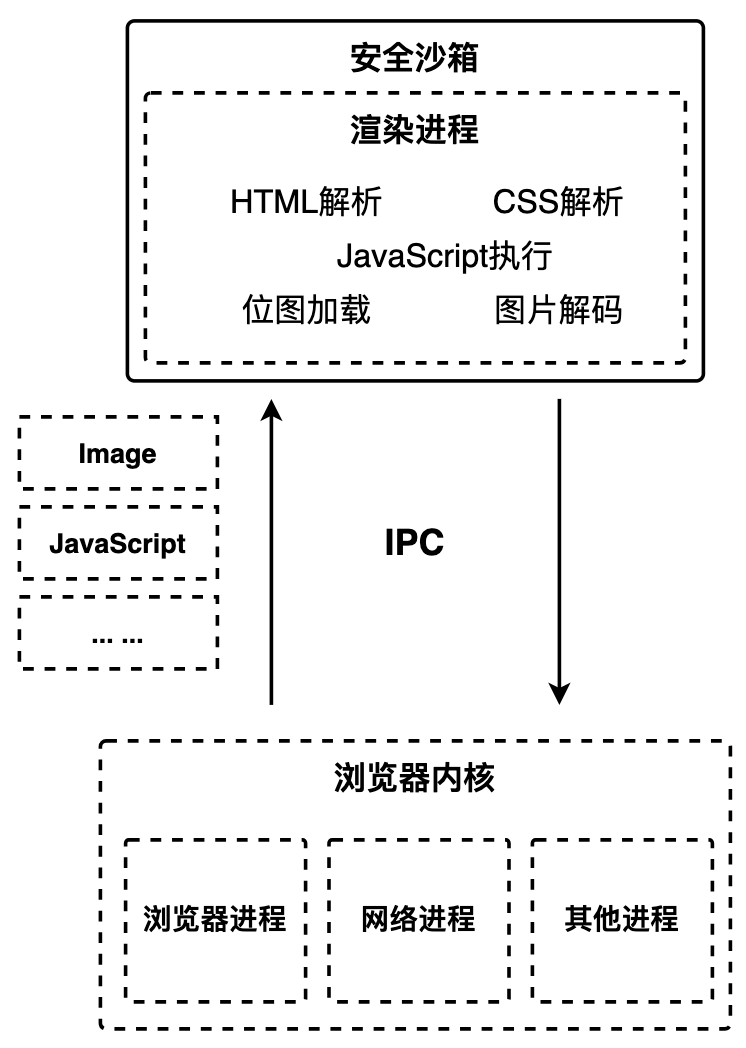
浏览器可划分为浏览器内核和渲染内核两个核心模块,浏览器内核由网络进程、浏览器主进程和 GPU 进程组成;渲染内核即渲染进程。
所有网络资源都通过浏览器内核下载,之后通过 IPC 传递给渲染进程。渲染进程接收到数据后对这些资源进行解析和绘制,之后由浏览器内核将位图写入内存,最终显示到屏幕上。
-
为什么一定要通过浏览器内核去请求资源,再将数据转发给渲染进程?
-
为什么渲染进程只负责生成页面图片,还需要通过浏览器内核才能展示到屏幕上?
渲染进程需要执行 DOM 解析、CSS 解析、网络图片解码等操作,如果执行代码里存在系统级别的漏洞,那么就有可能让恶意的站点通过渲染进程获取到控制权限,进而又获取操作系统的控制权限,这是非常危险的。因为网络资源的内容存在着各种可能性,所以浏览器会默认所有的网络资源都是不可信和不安全的。
假设下载了一个恶意程序,只要没有执行它,那么恶意程序是不会生效的。同理,浏览器之于网络内容也是如此,浏览器可以安全地下载各种网络资源,但是如果要执行这些网络资源里携带的代码时,就需要非常谨慎,因为黑客会利用这些操作对含有漏洞的浏览器发起攻击。
基于以上原因,我们需要在渲染进程和操作系统之间建一道墙,即便渲染进程由于存在漏洞被黑客攻击,但由于这道墙,黑客就获取不到渲染进程之外的任何操作权限。将渲染进程和操作系统隔离的这道墙就是安全沙箱。浏览器中的安全沙箱是利用操作系统提供的安全技术,让渲染进程在执行过程中无法访问或者修改操作系统中的数据,在渲染进程需要访问系统资源的时候,需要通过浏览器内核来实现,然后将访问的结果通过 IPC 转发给渲染进程。安全沙箱最小的保护单位是进程。
| 渲染进程 | 浏览器 内核 |
|---|---|
| HTML 解析 | Cookie |
| CSS 解析 | Cache |
| 图片解码 | 网络请求 |
| JavaScript 执行 | 文件读取 |
| 布局 | 下载管理 |
| 绘制 | SSL/TSL |
| XML 解析 | 浏览器窗口管理 |
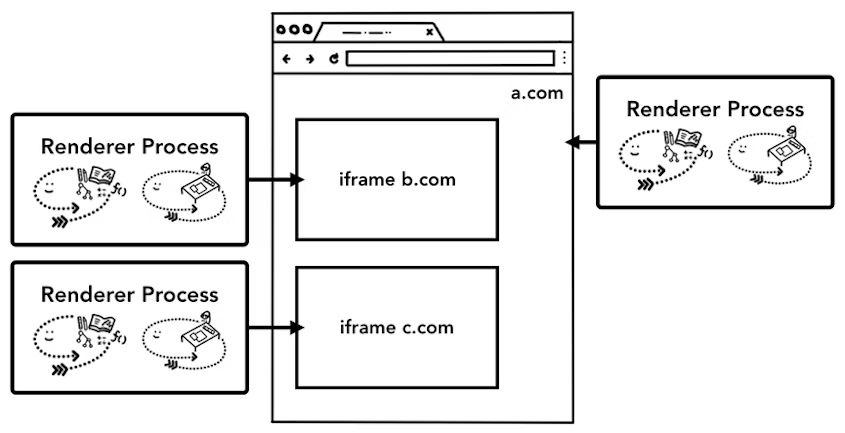
站点隔离是指将同一站点(相同根域名和协议)的页面放到同一渲染进程中执行。
Chrome 最初是以标签页为单位进行渲染进程划分的。但是,按照标签页划分渲染进程存在一些问题,原因就是一个标签页中可能包含了多个 iframe,而这些 iframe 又有可能来自于不同的站点,这就导致了多个不同站点中的内容通过 iframe 同时运行在同一个渲染进程中。
处理器架构存在“硬件之殇”——熔毁(Meltdown)和幽灵(Spectre),“熔毁”影响着英特尔芯片,而“幽灵”则会影响多家厂商的芯片,包括英特尔、AMD 和 ARM。黑客通过这两个漏洞可以直接入侵到进程的内部。在一些数据敏感的站点(如银行、社交)里如果包含恶意 iframe,则会入侵渲染进程,恶意程序就能读取站点渲染进程的所有内容。
因此 Chrome 重构代码将标签级的渲染进程重构为站点级的渲染进程,严格按照同一站点的策略来分配渲染进程。
网络安全
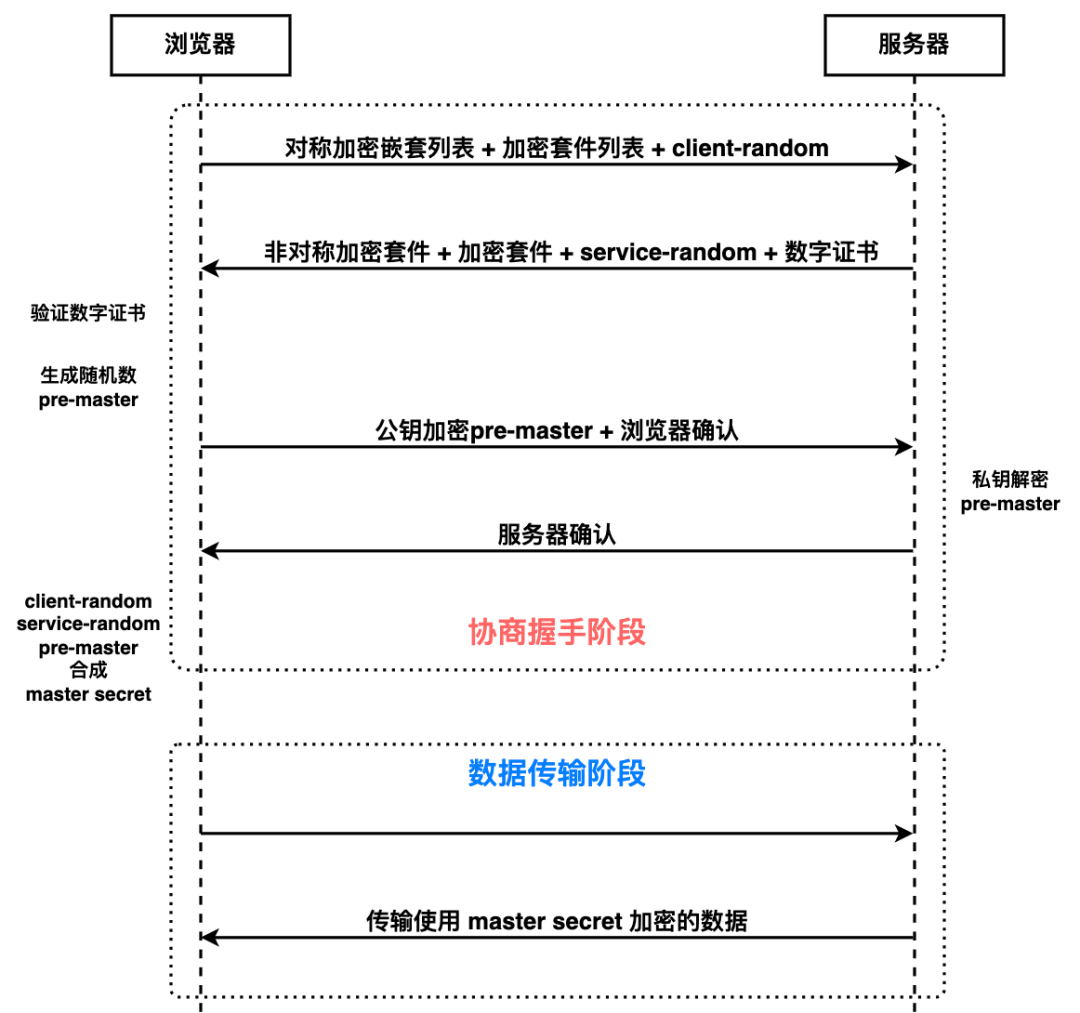
注:加密套件指加密算法,加密套件列表指浏览器能支持多少种加密算法的列表。
-
对称加密算法,加密和解密都使用相同的密钥。
-
不安全,随机数合成密钥算法是公开的,协商加密套件和随机数都是明文,数据容易被破解。
-
非对称加密算法,服务器将公钥以明文的形式发送给浏览器,用不公开的私钥将浏览器传输的密文解密。
-
加密效率低,严重影响用户打开页面的速度。
-
无法保证服务端发送给浏览器的数据安全,发送给浏览器的数据采用私钥加密公钥解密,而公钥是公开的。
-
混合加密算法,数据使用对称加密算法,密钥传递采用非对称加密算法。
-
DNS 劫持 IP 地址,黑客通过修改 DNS 内的服务器 IP 映射表,将恶意 IP 伪装为服务器 IP。
浏览器向服务器发送对称加密套件列表、非对称加密套件列表和随机数 client-random;服务器保存随机数 client-random,选择对称加密和非对称加密的套件,然后生成随机数 service-random,向浏览器发送选择的加密套件、service-random 和公钥;浏览器保存公钥,并生成随机数 pre-master,然后利用公钥对 pre-master 加密,并向服务器发送加密后的数据;最后服务器拿出自己的私钥,解密出 pre-master 数据,并返回确认消息。这样就保证了数据传输过程的安全性。
而 DNS 劫持 IP 地址的问题,只能通过数字证书的方式进行鉴权,由权威机构 CA 给服务器 IP 颁发的数字证书有两个重要作用:1.通过数字证书向浏览器证明服务器的身份;2.数字证书里包含服务器公钥。
参考资料
IEEE 754 标准: https://en.wikipedia.org/wiki/Double-precision_floating-point_format
[2]https://262.ecma-international.org/11.0/#sec-ordinary-object-internal-methods-and-internal-slots-ownpropertykeys
[3]https://tc39.es/ecma262/#sec-object.keys
[4]Ignition: https://v8.dev/docs/ignition
[5]TurboFan: https://v8.dev/docs/turbofan
[6]Maglev: https://blog.chromium.org/2023/06/how-chrome-achieved-high-scores-on.html
[7]jsvu: https://github.com/GoogleChromeLabs/jsvu
[8]字节码: https://github.com/v8/v8/blob/master/src/interpreter/bytecodes.h
[9]任务类型: https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/public/platform/task_type.h
[10]WHATWG 规范: https://html.spec.whatwg.org/multipage/webappapis.html#event-loop-processing-model
[11]https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/renderer/modules/scheduler/dom_timer.cc
[12]https://developer.mozilla.org/zh-CN/docs/Web/CSS/CSS_positioned_layout/Understanding_z-index/Stacking_context
[13]Draw Quad 命令: https://juejin.cn/post/7147706156968837150
[14]Chromium Viz: https://zhuanlan.zhihu.com/p/61416139
[15]RTT: https://blog.csdn.net/weixin_44446626/article/details/124576767?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3-124576767-blog-104130496.235%5Ev38%5Epc_relevant_anti_vip&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3-124576767-blog-104130496.235%5Ev38%5Epc_relevant_anti_vip&utm_relevant_index=4
[16]Inside look at modern web browser: https://developer.chrome.com/blog/inside-browser-part1/
[17]从 Number.MAX_VALUE 探秘 JavaScript 世界的神秘数字: https://juejin.cn/post/7008069852082470919
[18]JavaScript 对象遍历方法及其遍历顺序的总结: https://blog.csdn.net/weixin_50290666/article/details/124219626
[19]V8 内存管理: https://zhuanlan.zhihu.com/p/550025142
[20]Getters for spaces: https://source.chromium.org/chromium/chromium/src/+/refs/heads/main:v8/src/heap/heap.h
[21]Google CTF 2022 d8: From V8 Bytecode to Code Execution: https://mem2019.github.io/jekyll/update/2022/07/03/Google-CTF.html
[22]内存回收机制: https://juejin.cn/post/6844904182512615432
[23]事件循环和任务调度: https://juejin.cn/post/7215145804033818682
[24]Chrome DevTools 面板全攻略: https://juejin.cn/post/6854573212412575757