在今年的音乐科技顶会 ISMIR 2021(International Society for Music Information Retrieval)上,字节跳动海外技术团队有 7 篇论文入选,涵盖了音乐分类、音乐标签、音源分离、音乐结构分析等多个技术方向。
如今抖音已经成为音乐宣发的一个重要渠道。一支支音乐先在抖音上以短视频 BGM 火起来,再扩散到各大音乐平台上。抖音神曲甚至成了很多音乐平台的一个重要分类。
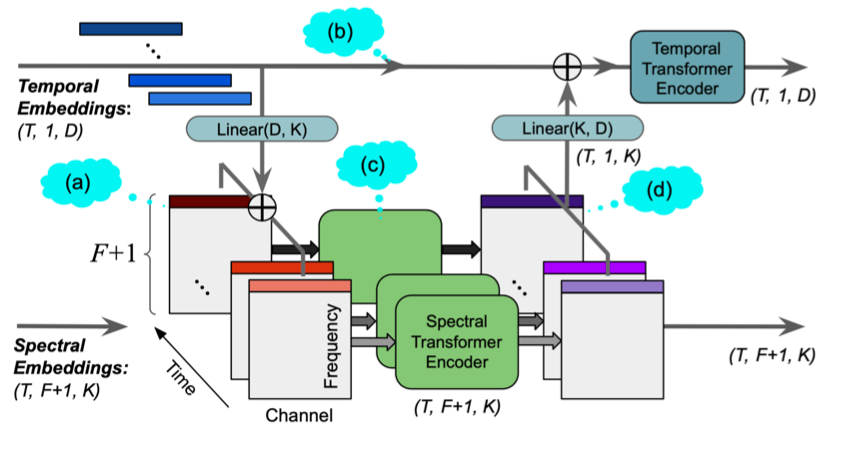
有人说神曲能火是因为歌词和旋律简单,听得多了就印在脑子里。但是对一个有着海量用户、复杂多样内容场景的短视频平台来说,如何让音乐更好地和短视频创作及互动融合在一起,绝不是一件简单的事。包括抖音在内,字节跳动旗下的众多短视频 / 音乐类应用已有存量亿级的曲库,音乐片段更高达数十亿量级。让海量音乐和海量用户更懂对方的,是一整套语音、音频和音乐的智能创作能力,即 SAMI (Speech, Audio and Music Intelligence)。就在今年的音乐科技顶会ISMIR 2021(International Society for Music Information Retrieval)上,字节跳动海外技术团队有 7 篇论文入选,涵盖了音乐分类、音乐标签、音源分离、音乐结构分析等多个技术方向。该团队成员分布在美国、英国等国家和地区,支持了字节系产品音乐的搜索、推荐、内容创作等场景,这些技术恰恰揭示了一首首神曲是如何炼成的。千万播放量的变装视频,原来人人都可以拍。音乐与视觉效果的联动,不断激发创作者发挥自己的无限想象。甚至只需上传照片,不需要任何的裁剪编辑,就可以变成属于自己的“视觉大片”。这个操作起来很简单的功能,逐渐成为了抖音素人用户的创作神器,极大程度上降低了视频拍摄门槛,让用户的创意充分展现出来。这些视频创作效果,是基于抖音音频算法技术对音频内容的深度分析,结合视觉等算法技术形成的。SpectTNT 就是一种新型的、专为音乐频谱提取设计的深度学习模型。这项技术可被用于视频编辑中的声乐旋律提取和音乐结构分析,达到更好的音频和画面匹配效果。随着技术的不断提升,该技术还将用在音乐标记、和弦识别和节拍跟踪中,不断衍生出多种多样的视频玩法。ISMIR 2021 论文:SpecTNT: a Time-Frequency Transformer for Music AudioSpectTNT 模型的原理是将音频信号经过短时傅立叶变换,得到频谱图。然后,频谱图经过时间和频域的转换模型提取高层次特征。模型本身包含残差结构,使得底层信息能够充分流入到高层中。
当我们面对着海量音乐库,哪首歌曲才能唤醒此刻的心情?算法技术,可以对音乐这一抽象的 “听觉艺术” 进行客观的分析及展示,大大提升用户发现音乐的效率。用户想给视频找个合适的配乐,往往通过标签分类进行查询,例如曲风就是最常见的分类。目前字节提出了一种半监督式的 Transformer音乐模型来实现音乐的标签化,实现海量音乐数据的曲风、相似性的归类。音乐标签化已广泛服务于Resso、抖音、剪映等产品的音乐推荐系统中。
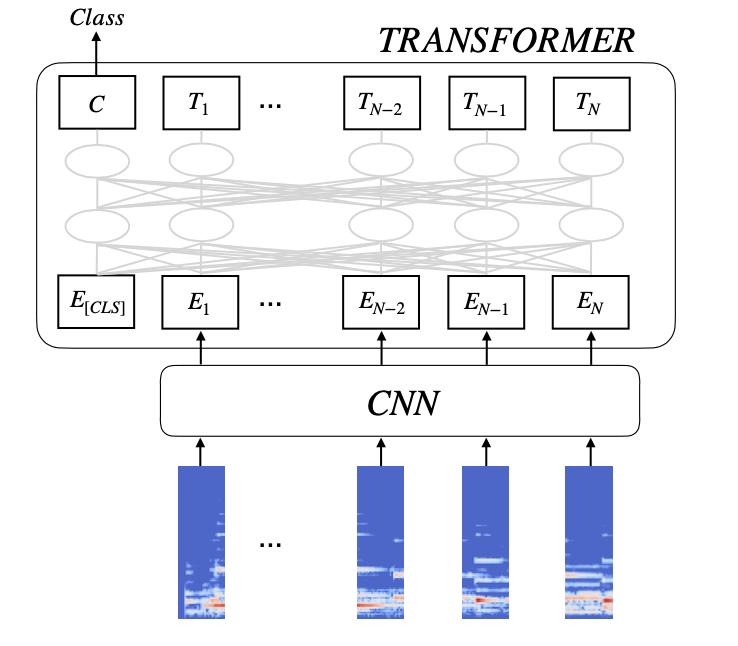
ISMIR 2021 论文:< Semi-supervised Music Tagging Transformer >论文提出的半监督式 Transformer 音乐模型,能够突破传统卷积神经网络的一些表现,进一步提出了基于噪声学习和半监督学习的方法,充分利用有标记数据和无标注数据,大幅减少人工数据标注的工作量。该模型已经超越了现在大规模使用的深度残差网络表现。
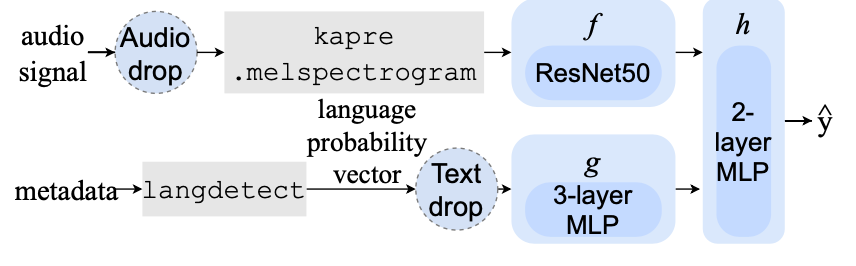
除了曲风、相似度等标签之外,在全球化环境下的音乐类应用,语种类型的识别也非常重要。字节的音乐语种识别系统,可快速分别一首歌中的中文、英语、印地语等几十种类别组成及占比。这项技术正在为 Resso 的曲库提供语言识别服务。准确地向用户推送合适语种的音乐,已经被证实能有效提高多地区、多样化语种用户的留存率。ISMIR 2021 论文:<Listen, Read, and Identify: Multimodal Singing Language Identification of Music>字节提出的音乐语种识别,支持多模态作为系统的输入。基于音频的对数梅尔谱图,经过 50 层的深度残差网络提取嵌入特征,并且支持使用音乐的一些结构化文本数据,例如专辑名等作为输入。经过一个语言识别模型输出嵌入特征。最后通过结合音频和元数据的多模态特征,经过全连接层输出预测的语言结果。
除了最常见的 “标签化” 理解模式,字节的音乐理解算法,还注重对于音乐本身的内容结构分析,也是其音频算法的一大“法宝”。这一技术,让产品更懂音乐也更会用音乐。对海量音乐 MIDI 的和弦的分析,不断发现好音乐背后的编曲奥秘,进而输出快速、大规模、高质量的和弦片段。这一技术也为 AI 自动作曲系统提供了前置条件,帮助 AI 音乐创作出更符合大多数人喜爱的音乐片段。AI 创作的音乐已经在 TikTok、抖音等产品中被广泛运用。ISMIR 2021 论文:< A deep learning method for enforcing coherence in Automatic Chord Recognition>该技术提出了一种能够识别音乐和弦的方法,可识别非常丰富的和弦种类,是一种基于神经网络的自回归蒸馏估计方法 NADE。经过详实的数据实测,该方案在一些经典的数据集上的和弦识别效果优于很多同类研究。
除音乐和弦理解外,其他音乐结构分析的能力也必不可少。字节对音乐结构的理解更大程度上提高了音乐在 UGC 及 PUGC 视频场景中的使用效率,也促使着抖音成为“神曲创造机”。先理解音乐是如何 “表达” 的,才能对音乐进行更好地 “结构化” 分析,可以大幅降低音乐内容理解的门槛。字节提出的一种新型的音乐表征模型 CLMR,只需极少的数据标注,而且通用性很强。该模型已被应用到庞大的音乐数据集中,作为音乐标签、节奏提取等的重要前置,极大地降低了成本。ISMIR 2021 论文:< Contrastive Learning of Musical Representations >CLMR 只需极少的数据标注,避免了监督学习中需要大量标签的情况,大幅降低了数据成本。通过对音频数据做出多种增强处理,并使用对比学习的方法,训练出音乐的通用表征。在多个音频分类的迁移学习任务上,CLMR 表征均取得了非常好的效果。
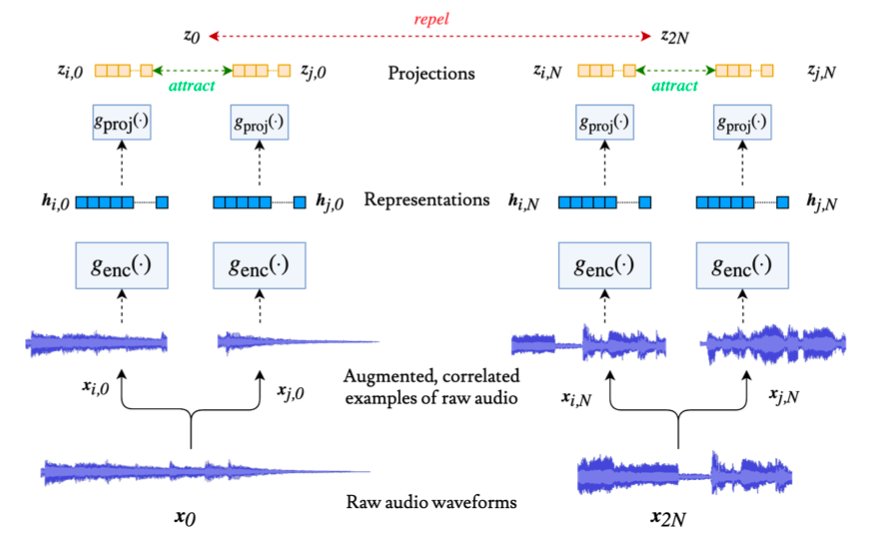
人可以轻易地分辨出音乐中的高潮片段,并且可以自我发挥把一首 3 分钟的歌自然地哼到五六分钟,那么机器可以做到这么自然地过渡吗?西瓜的音频编辑场景中,已经用到了这项技术,通过使用音乐结构分析算法,批量识别音乐中的高光、循环片段,能使得智能延长的效果更加自然,帮助用户随意延长或缩短音乐的长度,方便创作者发挥。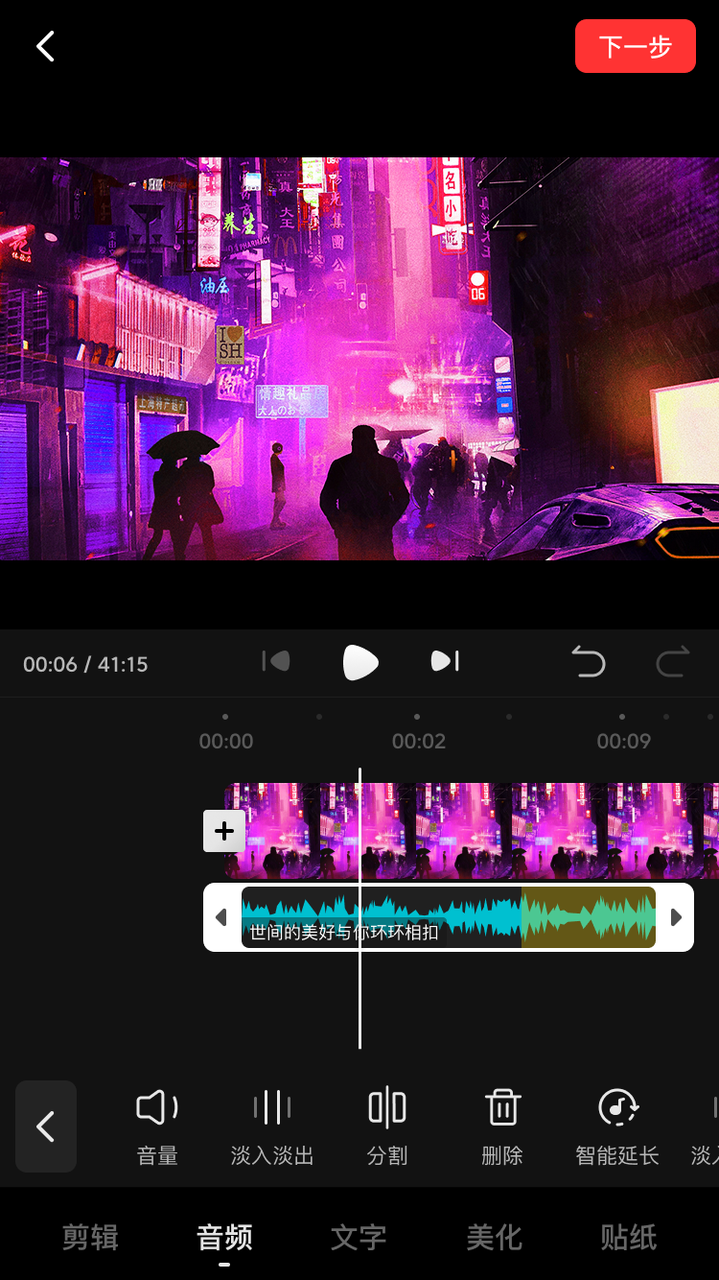
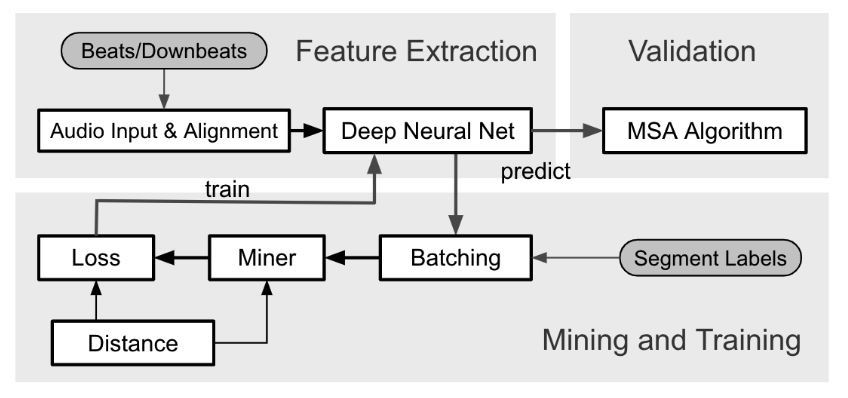
ISMIR 2021 论文:<Supervised Metric Learning for Music Structure Features>字节的音乐高光检测等技术利用一种较为前沿的音乐结构分析方法,音频经过深度神经网络提出特征,提取的特征会送到一个数据挖掘模块中继续分析。本文提出的方法已用在 HarmonixSet, SALAMI, RWC 等多个数据集上。
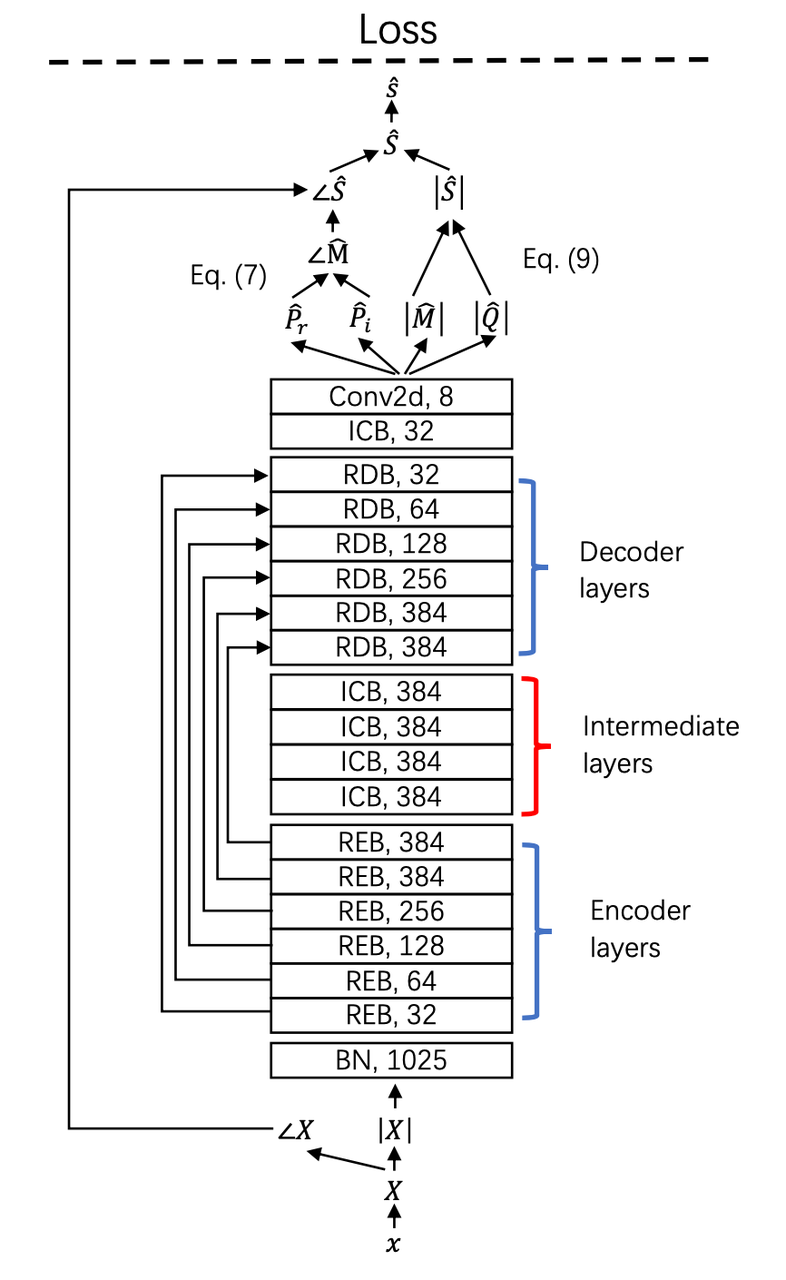
除上述音乐理解技术外,技术团队还提供着音乐物料制作的能力支持,提升音乐在多样业务场景中的灵活性。例如音源分离技术,能够把一首乐曲分离成人声及伴奏。在音视频编辑场景中,支持创作者给人声换个更优质的背景乐,或是提取背景音乐,换成更优质的人声。音源分离是音乐信号处理里的关键技术,该新模型效果超越大多数声音分离系统,并已在 TikTok 等场景中使用。ISMIR 2021 论文:< Decoupling Magnitude and Phase Estimation with Deep ResUNet for Music Source Separation>这项技术的创新之处在于,作者们提出了一种同时估计幅度谱和相位谱的方法,提升了理想掩模方法的上限,进一步提出了一个 143 层的深度残差网络。实验表明,该系统在人声分离中取得了 8.98 dB 的值。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

