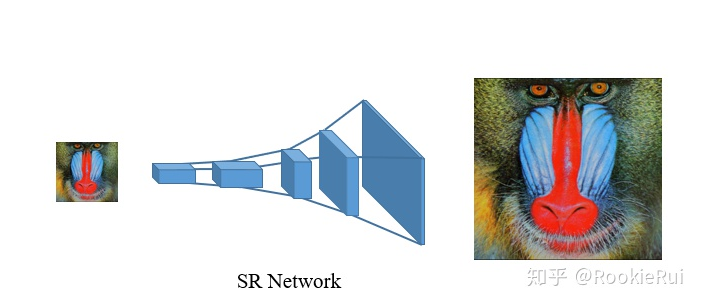
MMEditing:多任务图像视频编辑工具箱极市平台关注共 3735字,需浏览 8分钟 ·2020-08-12 16:47 点击蓝字 关注我们作者丨RookieRui@知乎来源丨https://zhuanlan.zhihu.com/p/178867385我们近期在 OpenMMLab 项目中开源了MMEditing。这是一个图像和视频编辑的工具箱,它目前包含了常见的编辑任务,比如图像修复,图像抠图,超分辨率和生成模型。在编辑图像或者视频的时候,我们往往是需要组合使用以上任务的,因此我们将它们整理到一个统一的框架下,方便大家使用。目前 MMEditing 的 repo 已经上线,欢迎大家点赞提issue:open-mmlab/mmeditinggithub.com在具体介绍每一个子任务前,让我们先来看一下 MMEditing 的优势吧!1. 统一的框架:我们设计了先进的框架来统一最常见的图像修复,图像抠图,超分辨率和生成模型这几个任务。用户可以在一个框架中方便地调用不同的算法和模型。2. 灵活的模块化设计:用户能够基于这套框架灵活地增加新的功能和算法。3. 丰富的模型和文档:下图中展示了我们支持的算法数目,要知道其中有不少算法是首次有完整的复现哦~我们也完善了文档(文档覆盖率高达90%以上)和入门材料,方便用户上手。4. 高效的实现:MMEditing所有的训练包括 GAN 的对抗训练都是基于高效的分布式训练框架部署的,对于一些基础的操作单元,我们也相应地进行了优化。强调一下,现在的 MMEditing 不仅仅是研究导向的框架,还是一个可以用于入门和教学的框架,在这里你可以看到 low-level vision 中常用的模型和基础的任务,每个模型也都被很好地拆解,方便大家上手探索其中的奥秘。下面让我们一起来走进 MMEditing,进一步了解一下不同的任务。Super-Resolution 超分辨率超分辨率(简称超分),是将低分辨率图像放大到高分辨率图像,如下图,一只小狒狒经过 SR网络后,可以得到放大,变成一只“大”狒狒。随着深度学习的兴起,早在2014年,香港中文大学多媒体实验室就提出了首个使用卷积神经网络解决超分辨率的模型——SRCNN。作为图像超分辨率工作,SRCNN 对后续计算机视觉的底层算法研究产生了重要影响。后续,各种各样的网络结构如雨后春笋般地冒了出来,比如VDSR,EDSR,SRResNet 等等; 还有追求视觉效果的 SRGAN, ESRGAN。MMEditing把一些基本的超分算法,比如 SRCNN,EDSR,SResNet,SRGAN还有视频的 EDVR 算法都包括进去。之前 OpenMMLab 中的 MMSR 也有类似的功能,相比之下,MMEditing 使用了更好的框架设计,用上了 MMCV 和 MMDetection 在发展过程中的经验积淀。整个 MM 系列都采用了类似的框架,只要掌握了一种,就能够轻而易举地掌握其他任务的代码库。Inpainting修复Inpainting(图像修复)是图像编辑领域里面一项基础的任务,其主要目标是修复图像中的受损(污染)区域。如下图中,左边是原图,中间是受损区域示意图,你可以去除图像中的不想要的人物,或者是图像中杂乱的不规则的受损区域。然后经过 Inpainting 修复算法就得到最右边的图啦。Inpainting 作为一项基础任务,现如今已经被广泛的应用到各种各样的场景,比如面部修复,背景填充以及视频编辑中。之前传统的 Patch-Matching 算法可以通过图中已知区域的纹理来快速填补当前受损区域。随着深度学习的发展,越来越多的工作利用深度神经网络实现更好的图像修复效果。深度图像修复领域中,有许多经典的开创性的工作像 Global&Local、Partial Conv 以及 DeepFill 系列,他们作为深度图像修复的经典模型被广泛地应用到后来的研究工作当中。可是这些方法都没有官方的 PyTorch 实现,为了方便大家更好的研究和深入了解这些模型,我们在 MMEditing 中集成了这些算法的训练和测试功能。同时,我们对其中一些重要的模块进行了代码上的优化,以使其更加符合 PyTorch 的风格,甚至是更快的 GPU 计算,从而能够有更好的训练速度。Matting抠像抠像(Matting)问题是一个在计算机视觉研究领域有重要价值的研究课题,其在工业界也有非常重要的应用。抠像是将前景从图片或者视频中与背景分离开来的问题,比如下图中,输入是左图,一位超级可爱的小姐姐在秀丽的风景前中,我们希望得到右边的小姐姐的抠像结果(b)。它和 segmentation分割的不同之处在于,matting 需要得到更精准的边缘(如头发)以及与背景的组合系数。为了降低求解的难度,一种最常见的方式是引入用户输入的 trimap(如下图),来对图片进行简单的三分类。其中,图中的黑色为背景,白色为前景,灰色为未知区域。给定 trimap 后,我们只需要求解未知区域的抠图结果,这大大降低了求解的难度。在 MMEditing 中,我们首次完整复现了 DIM(Deep Image Matting)在原论文中的性能。除此之外,MMEditing 还包含当前开源 Matting 模型中性能最好的 GCA Matting 模型,以及速度最快的 IndexNet Matting。Generation生成模型Generation,中文含义为“生成”。所谓生成,不同于其他图像编辑的任务,旨在创造新的图像。我们试图通过深度学习的方式,让神经网络成为创造者,产生新的信息。生成任务一般分为两种,非条件(unconditional)和条件(conditional)的生成。所谓非条件生成,主要是从潜在空间(latent space)中的噪声(noise)往图像域(image domain)进行转换,并试图近似相关边缘概率分布,产生逼真的图像。所谓条件生成,主要是从一个图像域映射到潜在空间,并进一步转换到另一个图像域。目前的MMEditing主要支持后者,即从一个图像域映射到另一个图像域,如分割的mask转换到真实图像、马转换到斑马等。后者的条件生成也更加符合目前图像编辑的主题。而目前 MMEditing 支持的条件图像生成,又可以分为两种不同的设定。其中一种生成模型的训练数据中,包含成对的训练数据,被称为“成对图像到图像转换(paired image-to-image translation)”。这种设定一般生成任务的难度比较低,但对数据本身的要求比较高,生成效果一般比较良好。最经典的成对图像到图像转换的方法,名为 pix2pix。它也是图像到图像转换领域开山鼻祖的文章,因此我们在这个版本中首先考虑对它进行实现,获得了与作者官方实现一致的结果。另一种生成模型的训练数据中,仅包含非成对的训练数据,被称为“非成对图像到图像转换(unpaired image-to-image translation)”。这种设定一般对数据要求较低,很容易构建两个明确的图像域,但生成难度较大,生成效果会略微降低。提出非成对图像到图像转换问题,并首先给出解决方案(cycle-consistency)的方法,名为 CycleGAN。CycleGAN 作为最经典的非成对图像到图像转换的生成方法,我们在这个版本中同样首先考虑对它进行实现和效果对齐。生成(Generation)任务通常比较困难,但向人们展示出了惊人的效果和广阔的研究前景。在未来 MMEditing 代码库的版本中,我们会考虑加入更多不同的生成设定,以及多种生成方法,让我们的代码库更加全面、丰富、强大。结语MMEditing 作为 OpenMMLab 的一员,后面会逐渐地完善,不断修改 bugs,持续添加新功能。欢迎大家一起来完善 MMEditing,共同贡献 OpenMMLab! 下面是 OpenMMLab 中的其他成员的介绍,后续会有更多重磅的 project 出现,希望大家持续关注我们的OpenMMLab 计划,并且参与其中哈。推荐阅读超详细!使用OpenCV深度学习模块在图像分类下的应用实践Matplotlib优雅作图笔记21张让你代码能力突飞猛进的速查表(神经网络、线性代数、可视化等)添加极市小助手微信(ID : cv-mart),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR等技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~△长按添加极市小助手△长按关注极市平台,获取最新CV干货觉得有用麻烦给个在看啦~ 浏览 63点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 VideoCrafter视频生成和编辑工具箱VideoCrafter是一个用于制作视频内容的开源视频生成和编辑工具箱。目前包括以下三种型号:BaseT2V:通用文本到视频生成提供基于潜在视频扩散模型(LVDM)的基本文本到视频(T2V)生成模型VideoCrafter视频生成和编辑工具箱VideoCrafter 是一个用于制作视频内容的开源视频生成和编辑工具箱。目前包括以下三种型号:BPotatofieldImageToolkit图像工具箱洋芋田图像工具箱,一个适用于摄影从业者/爱好者、设计师等创意行业从业者的图像工具箱。软件目前有如下工具:图片加水印工具长图拼接工具富文本制图工具尺寸调整工具图片裁剪工具EXIF读取工具字体管理工具色彩PiTiVi视频编辑软件PiTiVi 是一个使用 Python 所写并基于 GStreamer 和 GTK+ 的开源视频编辑PiTiVi视频编辑软件PiTiVi是一个使用Python所写并基于GStreamer和GTK+的开源视频编辑软件。无论是编辑视频的新手,还是专业人员,皆可通过PiTiVi找到自己的需要。PiTiVi提供一个时间轴,以便对视Shotcut视频编辑软件Shotcut是一款自由、开源、跨平台的视频编辑软件。使用Qt开发。依赖:MLT:multimediaauthoringframeworkQt5:applicationandUIframeworkFFCinelerra非线性视频编辑软件Cinelerra,是非线性视讯编辑系统,为GNU\Linux操作系统而设计,也可以成功安装在OSXLightworks非线性视频编辑系统Lightworks 是一套非线性视频编辑系统,能处理高清媒体、DPX和RED文件,可以与FinalCinelerra非线性视频编辑软件Cinelerra,是非线性视讯编辑系统,为GNU\Linux操作系统而设计,也可以成功安装在OSX上,目前没有Windows的版本。制作公司是HeroineVirtual。它也拥有后制合成引擎,功能LiVES视频编辑、播放软件LiVES 是一个简单易用但功能强大的视频效果,编辑,转换和播放软件。它使用现有普通工具(MPlay点赞 评论 收藏 分享 手机扫一扫分享分享 举报








 下载APP
下载APP