邻近模糊匹配?你可能不知道的pandas骚操作,确实很好用!
↑↑↑关注后"星标"简说Python
人人都可以简单入门Python、爬虫、数据分析 简说Python推荐 来源:可以叫我才哥 作者:才哥
大家好,最近在处理数据的时候pd.merge()操作使用场景很多,但是它有个前提是必须有关键值key能精确对应上,而我们实际场景中可能会遇到需要类似模糊匹配的情况,那么可以怎么处理呢?今天,我们就来了解一下!!
先看一个实际案例:
现在我们有两份数据,一份记录着每天不同玩家购买某道具的时候实际支付的购买金额,另外一份记录着该道具调整售价的日期及对应售价。
需求如下:将这两张表合并,形成一张总表记录每天玩家购买某道具实际支付的购买金额以及此时该商店的售价,以此我们可以进一步算折扣以及不同折扣下的销量等等。
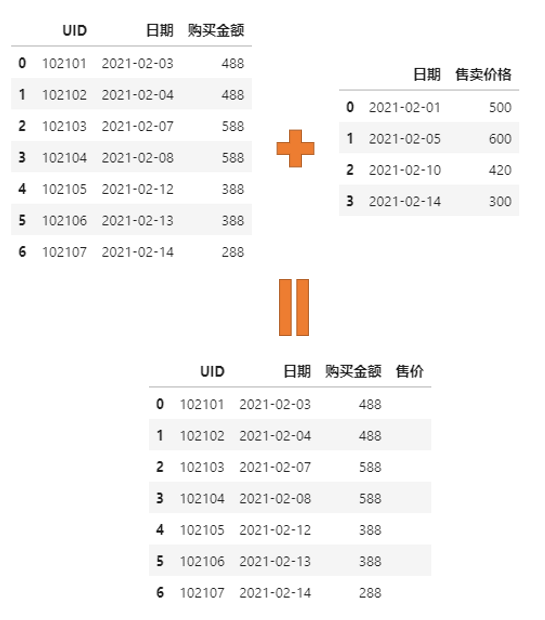
面对这样的需求,可能大家首先可能会想到pd.merge函数方法,然后一番操作。
>>> pd.merge(df['实际购买价格'],df['售价'])
UID 日期 购买金额 售卖价格
0 102107 2021-02-14 288 300
>>> pd.merge(df['实际购买价格'],df['售价'],how='outer')
UID 日期 购买金额 售卖价格
0 102101.0 2021-02-03 488.0 NaN
1 102102.0 2021-02-04 488.0 NaN
2 102103.0 2021-02-07 588.0 NaN
3 102104.0 2021-02-08 588.0 NaN
4 102105.0 2021-02-12 388.0 NaN
5 102106.0 2021-02-13 388.0 NaN
6 102107.0 2021-02-14 288.0 300.0
7 NaN 2021-02-01 NaN 500.0
8 NaN 2021-02-05 NaN 600.0
9 NaN 2021-02-10 NaN 420.0
不过,好像直接这样并不能得到我们需要的结果,那么可以这么操作呢?那么,就来看看吧!
1. 常规方案
其实,我们通过pd.merge方法的outer外连接,能够获得可以拼凑需求里的全部数据(有多余的以及缺失的),基于这样的情况,再进行以下操作即可获得完成最终需求。
思路如下:
在 pd.merge(df['实际购买价格'],df['售价'],how='outer')基础上按照日期进行排序,默认升序即可;然后对售卖价格进行缺失值填充,采用 method="ffill"方式;最后对其余含有缺失值的行进行删除即可,也就是 dropna()。
看效果:
# 按照日期进行排序
>>> pd.merge(df['实际购买价格'],df['售价'],how='outer').sort_values(by='日期')
UID 日期 购买金额 售卖价格
7 NaN 2021-02-01 NaN 500.0
0 102101.0 2021-02-03 488.0 NaN
1 102102.0 2021-02-04 488.0 NaN
8 NaN 2021-02-05 NaN 600.0
2 102103.0 2021-02-07 588.0 NaN
3 102104.0 2021-02-08 588.0 NaN
9 NaN 2021-02-10 NaN 420.0
4 102105.0 2021-02-12 388.0 NaN
5 102106.0 2021-02-13 388.0 NaN
6 102107.0 2021-02-14 288.0 300.0
# 售卖价格列进行缺失值ffill填充,再删除含有缺失值的行
>>> _.assign(售卖价格 = _['售卖价格'].ffill()).dropna()
UID 日期 购买金额 售卖价格
0 102101.0 2021-02-03 488.0 500.0
1 102102.0 2021-02-04 488.0 500.0
2 102103.0 2021-02-07 588.0 600.0
3 102104.0 2021-02-08 588.0 600.0
4 102105.0 2021-02-12 388.0 420.0
5 102106.0 2021-02-13 388.0 420.0
6 102107.0 2021-02-14 288.0 300.0
2. 邻近模糊匹配方法pd.merge_asof()
由于本文案例的情况使用场景较多,所以pandas官方也是想到了要提供这么样一个快速处理的方法,也就是今天我们要重点介绍的pd.merge_asof()。
pandas.merge_asof(left, right, on=None, left_on=None, right_on=None, left_index=False, right_index=False, by=None, left_by=None, right_by=None, suffixes=('_x', '_y'), tolerance=None, allow_exact_matches=True, direction='backward')
>This is similar to a left-join except that we match on nearest key rather than equal keys. Both DataFrames must be sorted by the key.
那我们还是先看这个方法的骚操作吧:
>>> pd.merge_asof(df['实际购买价格'],df['售价'])
UID 日期 购买金额 售卖价格
0 102101 2021-02-03 488 500
1 102102 2021-02-04 488 500
2 102103 2021-02-07 588 600
3 102104 2021-02-08 588 600
4 102105 2021-02-12 388 420
5 102106 2021-02-13 388 420
6 102107 2021-02-14 288 300
什么?一行代码就搞定了!!?
当然,因为这个操作的前提是必须按照key值排序过的数据哈,如果输入数据没有排序过就先进行一次排序操作即可。
当然了,这里我们再深入介绍下这个函数更多的用法哈
案例数据:
>>> left = pd.DataFrame({"a": [1, 5, 10], "left_val": ["a", "b", "c"]})
>>> left
a left_val
0 1 a
1 5 b
2 10 c
>>> right = pd.DataFrame({"a": [1, 2, 3, 6, 7], "right_val": [1, 2, 3, 6, 7]})
>>> right
a right_val
0 1 1
1 2 2
2 3 3
3 6 6
4 7 7
默认情况下
会匹配key值相同的那个,如果我们不想匹配key值相同的可以设置参数allow_exact_matches=False取消邻近匹配的是左key之前的那个右key对应的值,比如下面案例中,左侧的5匹配的是右侧的3对应的值3,左侧的10匹配的是右侧的7对应的值7
# 默认情况下,两边key都有1,精确匹配的值也在
>>> pd.merge_asof(left, right, on="a")
a left_val right_val
0 1 a 1
1 5 b 3
2 10 c 7
# 如果对于精确匹配的值不想要,则修改参数即可,精确匹配的时会变成NaN缺失
>>> pd.merge_asof(left, right, on="a", allow_exact_matches=False)
a left_val right_val
0 1 a NaN
1 5 b 3.0
2 10 c 7.0
同样,可以设置参数direction来决定匹配前后还是邻近模糊值
# 比如 匹配key之后的
>>> pd.merge_asof(left, right, on="a", direction="forward")
a left_val right_val
0 1 a 1.0
1 5 b 6.0
2 10 c NaN
# 比如 匹配两个key最接近的
>>> pd.merge_asof(left, right, on="a", direction="nearest")
a left_val right_val
0 1 a 1
1 5 b 6
2 10 c 7
更复杂的案例:
>>> quotes = pd.DataFrame(
... {
... "time": [
... pd.Timestamp("2016-05-25 13:30:00.023"),
... pd.Timestamp("2016-05-25 13:30:00.023"),
... pd.Timestamp("2016-05-25 13:30:00.030"),
... pd.Timestamp("2016-05-25 13:30:00.041"),
... pd.Timestamp("2016-05-25 13:30:00.048"),
... pd.Timestamp("2016-05-25 13:30:00.049"),
... pd.Timestamp("2016-05-25 13:30:00.072"),
... pd.Timestamp("2016-05-25 13:30:00.075")
... ],
... "ticker": [
... "GOOG",
... "MSFT",
... "MSFT",
... "MSFT",
... "GOOG",
... "AAPL",
... "GOOG",
... "MSFT"
... ],
... "bid": [720.50, 51.95, 51.97, 51.99, 720.50, 97.99, 720.50, 52.01],
... "ask": [720.93, 51.96, 51.98, 52.00, 720.93, 98.01, 720.88, 52.03]
... }
... )
>>> quotes
time ticker bid ask
0 2016-05-25 13:30:00.023 GOOG 720.50 720.93
1 2016-05-25 13:30:00.023 MSFT 51.95 51.96
2 2016-05-25 13:30:00.030 MSFT 51.97 51.98
3 2016-05-25 13:30:00.041 MSFT 51.99 52.00
4 2016-05-25 13:30:00.048 GOOG 720.50 720.93
5 2016-05-25 13:30:00.049 AAPL 97.99 98.01
6 2016-05-25 13:30:00.072 GOOG 720.50 720.88
7 2016-05-25 13:30:00.075 MSFT 52.01 52.03
>>> trades = pd.DataFrame(
... {
... "time": [
... pd.Timestamp("2016-05-25 13:30:00.023"),
... pd.Timestamp("2016-05-25 13:30:00.038"),
... pd.Timestamp("2016-05-25 13:30:00.048"),
... pd.Timestamp("2016-05-25 13:30:00.048"),
... pd.Timestamp("2016-05-25 13:30:00.048")
... ],
... "ticker": ["MSFT", "MSFT", "GOOG", "GOOG", "AAPL"],
... "price": [51.95, 51.95, 720.77, 720.92, 98.0],
... "quantity": [75, 155, 100, 100, 100]
... }
... )
>>> trades
time ticker price quantity
0 2016-05-25 13:30:00.023 MSFT 51.95 75
1 2016-05-25 13:30:00.038 MSFT 51.95 155
2 2016-05-25 13:30:00.048 GOOG 720.77 100
3 2016-05-25 13:30:00.048 GOOG 720.92 100
4 2016-05-25 13:30:00.048 AAPL 98.00 100
案例中,除了日期time之前,还有ticker字段需要用于匹配,如果直接匹配上pd.merge_asof()结果如下:
>>> pd.merge_asof(trades, quotes, on="time")
time ticker_x price quantity ticker_y bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 MSFT 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 MSFT 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 GOOG 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 GOOG 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 GOOG 720.50 720.93
我们可以看到,第4行数据中 2016-05-25 13:30:00.048时间下,trades只有APPL没有GooG,理论上匹配过来的值应该为NaN,由于on参数只能有一个值,所以提供了by参数用于分组,操作如下:
>>> pd.merge_asof(trades, quotes, on="time", by="ticker")
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
有时间邻近匹配我们需要设置匹配的范围区间,则可以设置参数tolerance的值(必须是int或Timedelta),下面案例展示的是只匹配 时间差在2ms以内的:
>>> pd.merge_asof(trades, quotes, on="time", by="ticker", tolerance=pd.Timedelta("2ms"))
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 51.95 51.96
1 2016-05-25 13:30:00.038 MSFT 51.95 155 NaN NaN
2 2016-05-25 13:30:00.048 GOOG 720.77 100 720.50 720.93
3 2016-05-25 13:30:00.048 GOOG 720.92 100 720.50 720.93
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
回到我们之前提到了 allow_exact_matches参数,我们还可进行匹配 10ms以内且key值不同的:
>>> pd.merge_asof(
... trades,
... quotes,
... on="time",
... by="ticker",
... tolerance=pd.Timedelta("10ms"),
... allow_exact_matches=False
... )
time ticker price quantity bid ask
0 2016-05-25 13:30:00.023 MSFT 51.95 75 NaN NaN
1 2016-05-25 13:30:00.038 MSFT 51.95 155 51.97 51.98
2 2016-05-25 13:30:00.048 GOOG 720.77 100 NaN NaN
3 2016-05-25 13:30:00.048 GOOG 720.92 100 NaN NaN
4 2016-05-25 13:30:00.048 AAPL 98.00 100 NaN NaN
好了,以上就是本次的全部内容,大家可以调整参数多多练习下,相信这个操作用途还是不错的。
扫下方二维码添加我的私人微信,可以在我的朋友圈获取最新的Python学习资料,以及近期推文中的源码或者其他资源,另外不定期开放学习交流群,以及朋友圈福利(送书、红包、学习资源等)。
扫码查看我朋友圈
获取最新学习资源
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了
“点赞”传统美德不能丢