
大厂 6年踩过的 kafka 的坑,请避让!

点击“ 程序员内点事 ”关注,选择“ 设置星标 ”
坚持学习,好文每日送达!
kafka消息给我们系统,系统读取消息后,做业务逻辑处理,持久化订单和菜品数据,然后展示到划菜客户端。这样厨师就知道哪个订单要做哪些菜,有些菜做好了,就可以通过该系统出菜。系统自动通知服务员上菜,如果服务员上完菜,修改菜品上菜状态,用户就知道哪些菜已经上了,哪些还没有上。这个系统可以大大提高后厨到用户的效率。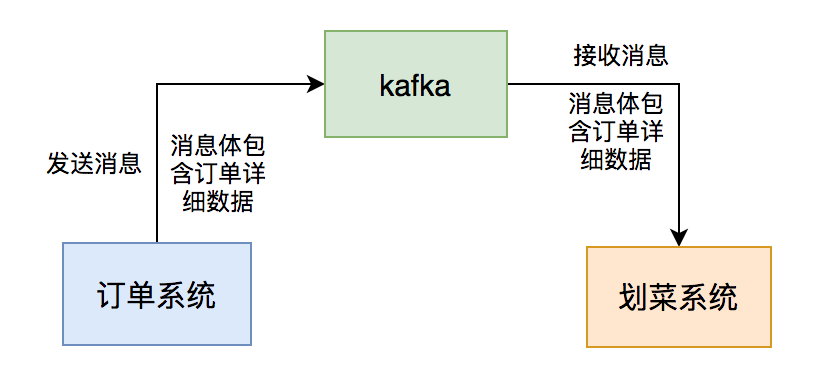
kafka,如果它有问题,将会直接影响到后厨显示系统的功能。kafka两年时间踩过哪些坑?kafka通信,订单系统发消息时将订单详细数据放在消息体,我们后厨显示系统只要订阅topic,就能获取相关消息数据,然后处理自己的业务即可。下单的消息都没读取到,就先读取支付或撤销的消息吧,如果真的这样,数据不是会产生错乱?2.如何保证消息顺序?
kafka的topic是无序的,但是一个topic包含多个partition,每个partition内部是有序的。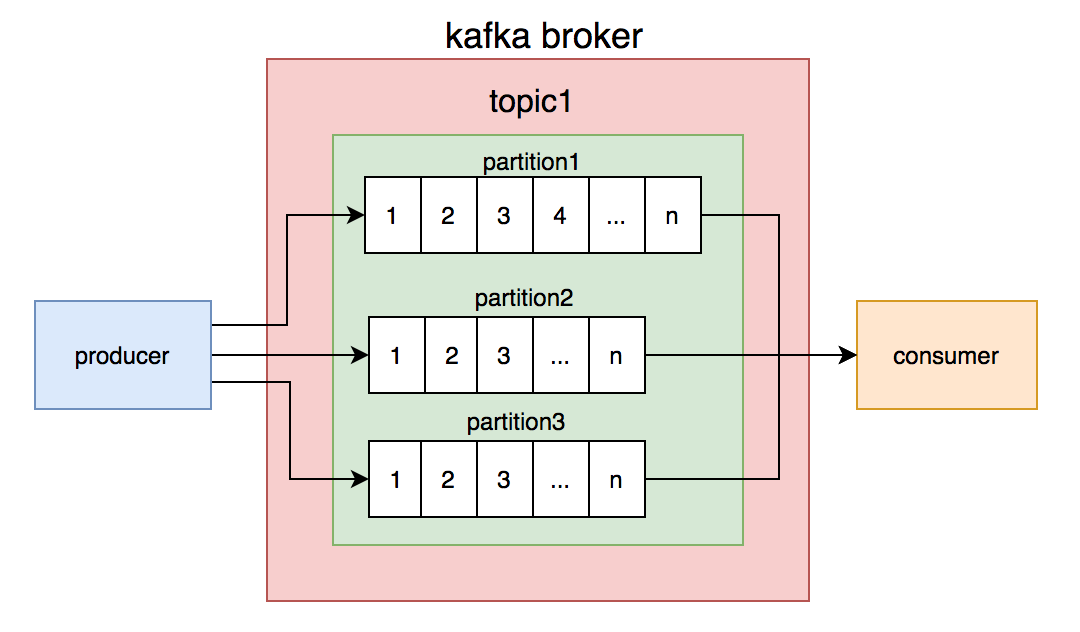
partition,不同的消费者读不同的partition的消息,就能保证生产和消费者消息的顺序。商户编号的消息写到同一个partition,topic中创建了4个partition,然后部署了4个消费者节点,构成消费者组,一个partition对应一个消费者节点。从理论上说,这套方案是能够保证消息顺序的。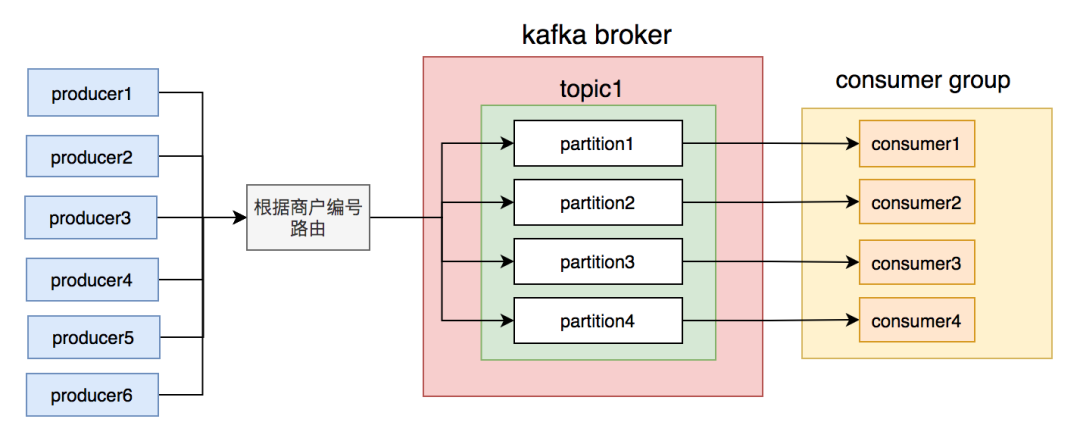
3.出现意外
顺序消息的打击,可以说是毁灭性的。
失败重试机制,使得这个问题被放大了。问题变成:一旦”下单“消息的数据入库失败,用户就永远看不到这个订单和菜品了。4.解决过程
同步重试机制在出现异常的情况,会严重影响消息消费者的消费速度,降低它的吞吐量。异步重试机制了。重试表下来。”支付“消息前面只有”下单“消息,这种情况比较简单。但如果某种类型的消息,前面有N多种消息,需要判断多少次呀,这种判断跟订单系统的耦合性太强了,相当于要把他们系统的逻辑搬一部分到我们系统。 影响消费者的消费速度
订单号在重试表有没有数据,如果有则直接把当前消息保存到重试表。如果没有,则进行业务处理,如果出现异常,把该消息保存到重试表。elastic-job建立了失败重试机制,如果重试了7次后还是失败,则将该消息的状态标记为失败,发邮件通知开发人员。服务器节点就能解决问题,但是按照公司为了省钱的惯例,要先做系统优化,所以我们开始了消息积压问题解决之旅。1. 消息体过大
kafka号称支持百万级的TPS,但从producer发送消息到broker需要一次网络IO,broker写数据到磁盘需要一次磁盘IO(写操作),consumer从broker获取消息先经过一次磁盘IO(读操作),再经过一次网络IO。
2次网络IO和2次磁盘IO。如果消息体过大,势必会增加IO的耗时,进而影响kafka生产和消费的速度。消费者速度太慢的结果,就会出现消息积压情况。消息体过大,还会浪费服务器的磁盘空间,稍不注意,可能会出现磁盘空间不足的情况。中间状态,只需知道一个最终状态就可以了。订单系统发送的消息体只用包含:id和状态等关键信息。 后厨显示系统消费消息后,通过id调用订单系统的订单详情查询接口获取数据。 后厨显示系统判断数据库中是否有该订单的数据,如果没有则入库,有则更新。
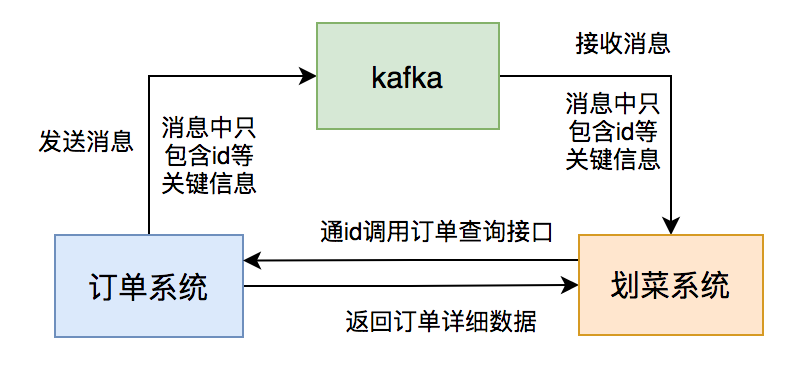
2. 路由规则不合理
partition上的消息都有积压,而是只有一个。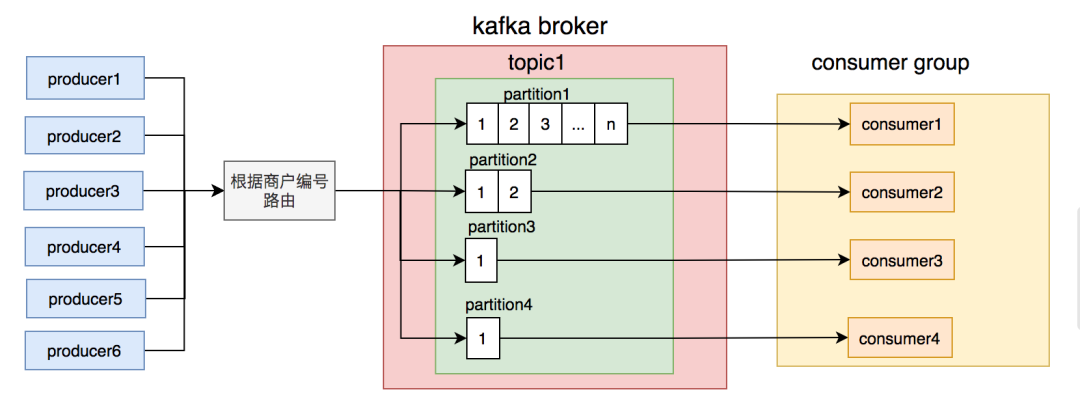
partition消息的节点出了什么问题导致的。但是经过排查,没有发现任何异常。partition,使得该partition的消息量比其他partition要多很多。商户编号路由partition的规则不合理,可能会导致有些partition消息太多,消费者处理不过来,而有些partition却因为消息太少,消费者出现空闲的情况。订单号路由到不同的partition,同一个订单号的消息,每次到发到同一个partition。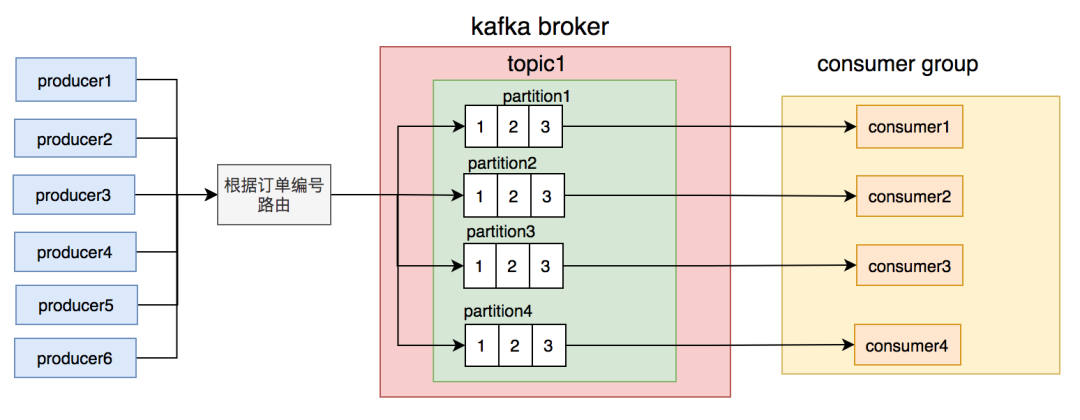
3. 批量操作引起的连锁反应
kafka的topic的数据,果然上面消息有积压,但这次每个partition都积压了十几万的消息没有消费,比以往加压的消息数量增加了几百倍。这次消息积压得极不寻常。十几万的消息该如何处理呢?partition数量是不行的,历史消息已经存储到4个固定的partition,只有新增的消息才会到新的partition。我们重点需要处理的是已有的partition。kafka允许同组的多个partition被一个consumer消费,但不允许一个partition被同组的多个consumer消费,可能会造成资源浪费。线程池处理消息,核心线程和最大线程数都配置成了50。zookeeper动态调整的,我把核心线程数调成了8个,核心线程数改成了10个。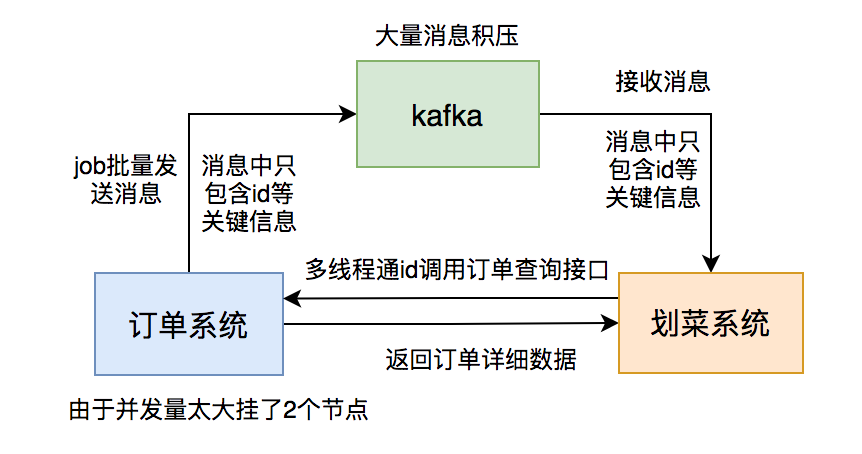
订单系统的批量操作一定提前通知下游系统团队。 下游系统团队多线程调用订单查询接口一定要做压测。 这次给订单查询服务敲响了警钟,它作为公司的核心服务,应对高并发场景做的不够好,需要做优化。 对消息积压情况加监控。
4. 表过大
2秒。以前是500毫秒,现在怎么会变成2秒呢?几千万,其他的划菜表也是一样,现在单表保存的数据太多了。3天的即可。多余的数据,不如把表中多余的数据归档。于是,DBA帮我们把数据做了归档,只保留最近7天的数据。 Duplicate entry '6' for key 'PRIMARY',说主键冲突。加锁。加分布式锁也可能会影响消费者的消息处理速度。 消费者依赖于redis,如果redis出现网络超时,我们的服务就悲剧了。
INSERT INTO ...ON DUPLICATE KEY UPDATE语法:INSERT INTO table (column_list)
VALUES (value_list)
ON DUPLICATE KEY UPDATE
c1 = v1,
c2 = v2,
...;
insert语句改造之后,就没再出现过主键冲突问题。kafka的topic中消息有没有积压,但这次并没有积压。DBA。果然,DBA发现数据库的主库同步数据到从库,由于网络原因偶尔有延迟,有时延迟有3秒。3秒,调用订单详情查询接口时,可能会查不到数据,或者查到的不是最新的数据。重试机制。调用接口查询数据时,如果返回数据为空,或者只返回了订单没有菜品,则加入重试表。重复消费
kafka消费消息时支持三种模式:at most once模式
最多一次。保证每一条消息commit成功之后,再进行消费处理。消息可能会丢失,但不会重复。at least once模式
至少一次。保证每一条消息处理成功之后,再进行commit。消息不会丢失,但可能会重复。exactly once模式
精确传递一次。将offset作为唯一id与消息同时处理,并且保证处理的原子性。消息只会处理一次,不丢失也不会重复。但这种方式很难做到。
kafka默认的模式是at least once,但这种模式可能会产生重复消费的问题,所以我们的业务逻辑必须做幂等设计。INSERT INTO ...ON DUPLICATE KEY UPDATE语法,不存在时插入,存在时更新,是天然支持幂等性的。多环境消费问题
pre(预发布环境) 和 prod(生产环境),两个环境共用同一个数据库,并且共用同一个kafka集群。kafka的topic的时候,要加前缀用于区分不同环境。pre环境的以pre_开头,比如:pre_order,生产环境以prod_开头,比如:prod_order,防止消息在不同环境中串了。pre环境切换节点,配置topic的时候,配错了,配成了prod的topic。刚好那天,我们有新功能上pre环境。结果悲剧了,prod的有些消息被pre环境的consumer消费了,而由于消息体做了调整,导致pre环境的consumer处理消息一直失败。offset,重新读取了那一部分消息解决了问题,没有造成太大损失。kafka的consumer使用自动确认机制,导致cpu使用率100%。kafka集群中的一个broker节点挂了,重启后又一直挂。
kafka的经历,虽说遇到过挺多问题,踩了很多坑,走了很多弯路,但是实打实的让我积累了很多宝贵的经验,快速成长了。kafka是一个非常优秀的消息中间件,我所遇到的绝大多数问题,都并非kafka自身的问题(除了cpu使用率100%是它的一个bug导致的之外)。
在看、点赞、转发,是对我最大的鼓励。
公众号内回复:面试、代码神器、开发手册、时间管理有超赞的粉丝福利,另外回复:加群,可以跟很多BAT大厂的前辈交流和学习。

评论