
“一学就会”微服务的架构模式:一个服务一个数据库模式(上)
不管你喜不喜欢微服务,现在微服务无疑已经是程序员们绕不过去的话题了。无论你是想把目前的架构改成微服务,还是你要出去面试高级一点的岗位,需要深入理解微服务。
提起微服务,很多程序员对它是又爱又恨,想学微服务不知道如何开始,学了一点之后,又找不到地方去实践。总之就是感觉微服务遥不可及,又很难驾驭。
首先要明白的是微服务是有套路的,而这些套路基本上解决了微服务结构面临的几乎所有重要问题。
这些套路就是微服务自己的架构模式
如果我们能深入了解这些模式的其来龙去脉,就可以理解了微服务绝大部分内容。学习快速,实用价值也极大。
1. 微服务最基本的模式
这篇文章先来讲第一个最基本的模式,这个模式我估计需要三篇文章才能讲透,这是上篇。打算中篇写实践,下篇写问题。
希望大家能学的轻松。
微服务最基本的模式就是:
一个服务一个数据库
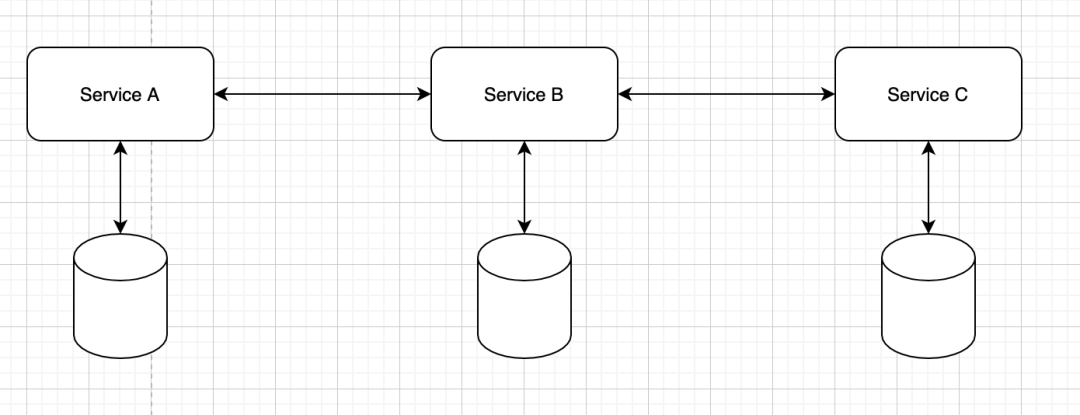
上图就是一个最简单的微服务模式了。
一个服务一个数据库这种模式,是微服务体系结构中的最基础也是最核心的模式。看着简单,但是,这个模式蕴含着微服务的最基本的思想。
要弄清楚一个服务一个数据库这种模式,首先我们就需要问一下,为什么我们要搞微服务。
2. 传统系统的问题
在谈及微服务的时候,和微服务对应的概念叫做单体系统( Monolithic application )。简单说,微服务是为了解决单体系统的问题才衍生出来的。单体系统结构如下图:
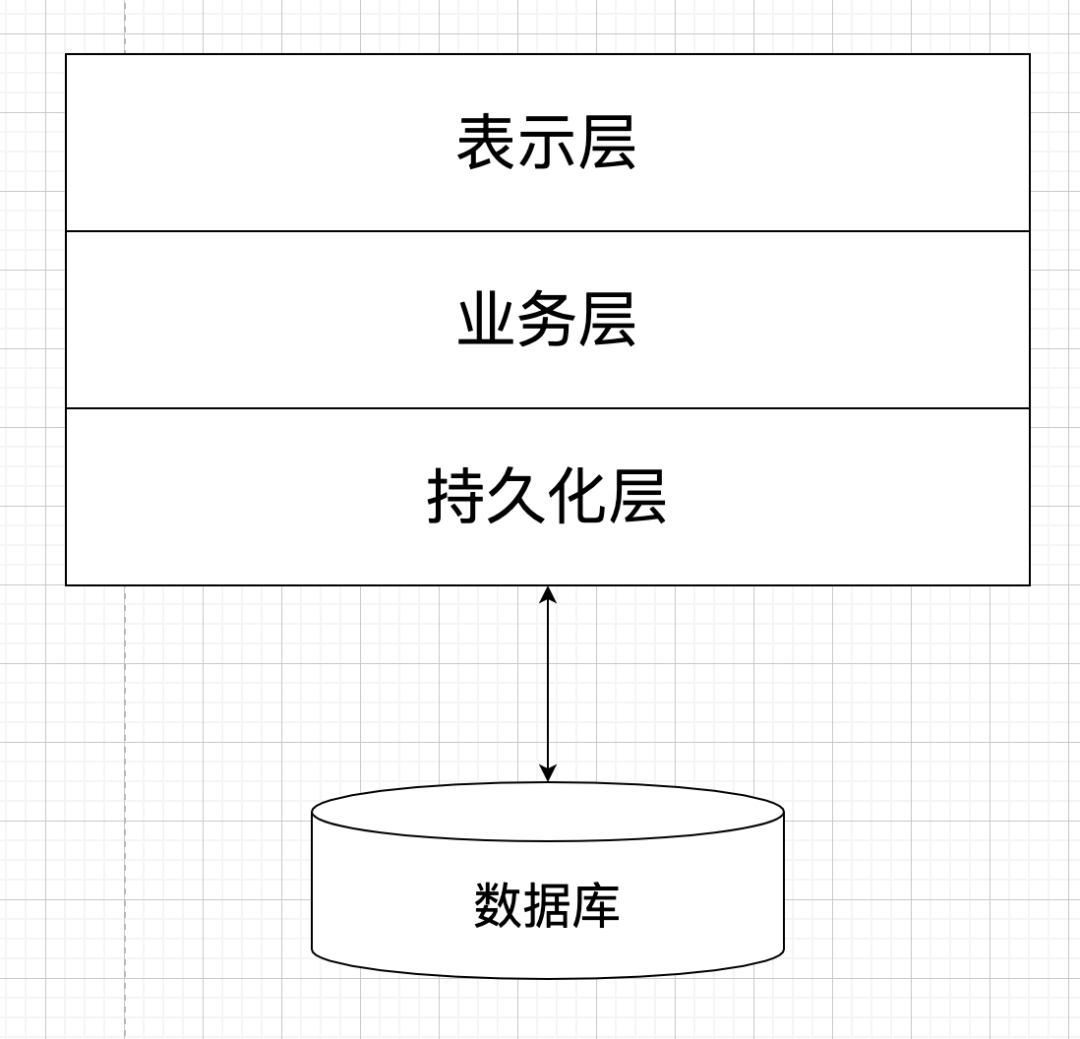
那么这种单体结构出现了什么问题,导致现在大家必须开口闭口微服务了呢?
3. 单体系统太大了
最首要的一个原因就是应用系统太大。而由于应用系统的过于庞大,如果仅是单体系统的话,就引发了各种各样的问题,体现在以下三个方面:
3.1. 系统本身业务复杂,模块众多
系统随着时间的发展,业务需求越来越多。而为了满足这些需求,就导致整个系统的模块越来越多。而系统模块越来越多,就导致能理解整套系统的人变得越来越少,直到最后没有人可以理解整套系统。
3.2. 系统的代码库非常庞大
代码量也会随着系统的增大而增大,代码量的庞大影响了整个开发流程,会导致整个开发成本变得很高。
首先,代码量大,依赖关系复杂,所以对新接手的开发人员来说,配置开发环境非常耗费精力。 其次,代码量大,加载这些代码和对应的依赖需要的内存就多,所以就会导致开发人员的 IDE 运行非常缓慢,导致编辑代码都很麻烦。 再次,代码量大,如果要把整个代码编译打包,需要的内存也很多,所以也会导致功能开发完成后,对系统的构建会非常缓慢,导致整个构建的时间非常漫长。 再有,代码量大,几乎没人能对整体代码有比较深入的了解,哪怕可能其中一个要改动的功能,都会因为过于复杂导致开发人员理解不深入。而这些不深入的理解又会让开发人员不能使用最佳的方式去做功能开发,从而导致隐藏的 bug。
3.3. 技术团队变得非常庞大
由于功能模块越来越多,这就需要越来越多的开发人员去开发和维护这套系统。但是,这些开发人员都是面对的同一套代码库,虽然可以搞分支,大家各搞各的。可是一旦需要合代码,发布上线,就是场噩梦。
各种代码冲突,代码丢失,都可能在上线的时候发生。
不仅如此,由于顾虑代码丢失和冲突,就需要在上线前,进行足量的测试,而这些测试又需要投入巨大的时间成本。
但是,现在都讲敏捷开发,很可能在还没上线的时候,后续的业务需求又接踵而至,简直要命。
4. 业务需求的个性化
搞微服务,还有一个很重要的原因是业务需求的个性化和颗粒化。
随着业务的发展,不管是由于市场竞争还是本身发展的需要,势必需要对本身业务模型的深度挖掘以及提高用户使用系统的各种体验。而基于此类种种,就势必要把系统的各个功能模块做深做透。
这又会引发几个新的问题:
4.1. 系统功能模块可能变得更多更杂
系统功能模块可能被不断拆分成了更细碎的模块,以致可能碎成了颗粒。而由于功能变得更碎更颗粒了,就会让产品经理们更容易的提出一些非常细致的业务需求。
这些非常细致的需求,很可能会造成频繁的功能修改和上线要求。而这些无穷尽的快速需求相对整体庞大的系统上线和开发人员的疲于奔命形成了最激烈的冲突。
4.2. 功能模块对系统的技术要求出现了冲突
比如,不同的功能模块,订单模块和支付模块。订单模块就希望系统能尽可能的能同时处理大量的订单,甚至可以有一定的容错性,出问题了砍单就可以了。
但是支付模块则不一样,支付模块希望系统能尽量的稳定,并且必须对准确度要求极高,几乎没有容错的空间。
同样的,在同样的支付模块中(根据系统模块划分而定),可能同时存在本地账户转账和三方渠道支付,本地账户转账可能需要即时,要求极高的响应时间。但是对于第三方支付,则可以有一定的响应时间容忍度。
如果系统本身是个单体系统,就势必要求开发人员对整套系统做一定的妥协,对冲突的技术需求做出一定的权衡。而这种权衡很可能影响的就是系统整体的体验度。
4.3. 系统模块对服务器的要求出现了冲突
由于功能的深耕细作,则势必会出现性能上的不同需求。
比如,系统的订单模块,个人下单可能会被频频访问,此时,就需要系统的集群多一些,去处理这些大规模的访问。但是,同样的功能模块里,可能还存在一些企业团购需求,他们没有那么大的访问量,就不需要那么多的服务器集群。
又比如,用户评论截图,可能需要大量的数据存储。但是,同样的,针对用户的个性化推荐就可能需要大规模的密集运算。
除了上面说的,系统庞大引发的问题带来的一些附属问题:
4.4. 故障的连锁反应问题
单体系统从技术上,各个模块是耦合在一起的。在实际运行里,很可能就会出现一处故障导致整个系统崩盘的现象。
比如,不常用的一个 XX 功能出现了内存泄露,导致整个系统全部不可用了。
4.5. 系统的技术锁死问题
坦白来说,你得承认在编程里,没有一种语言是完美的,也没有一个数据库是万能的。
比如,Java 做科学计算就没有 Python 那么方便高效。比如,我们需要存储很复杂的对象关系的时候,MySQL、Oracle 就不如任何一种图形数据库。
所以,系统越复杂,需要不同技术的概率就越高。但是又由于系统的复杂,引入新技术的风险也就越大。所以,新技术的使用非常困难。
同时,系统庞大后,如果一些组件,甚至语言 SDK 本身的问题如果需要升级,也是一件既繁琐,又充满风险的事情,所以,技术版本升级也非常困难。
综上,对于传统的单体应用来讲,系统庞大引发的技术问题,业务发展引发的需求冲突问题……都是无法单凭单体系统的架构思想就可以解决的。
那为什么 SOA 也不能解决这些问题呢?
5. SOA 的问题
咱们先来看看SOA的结构
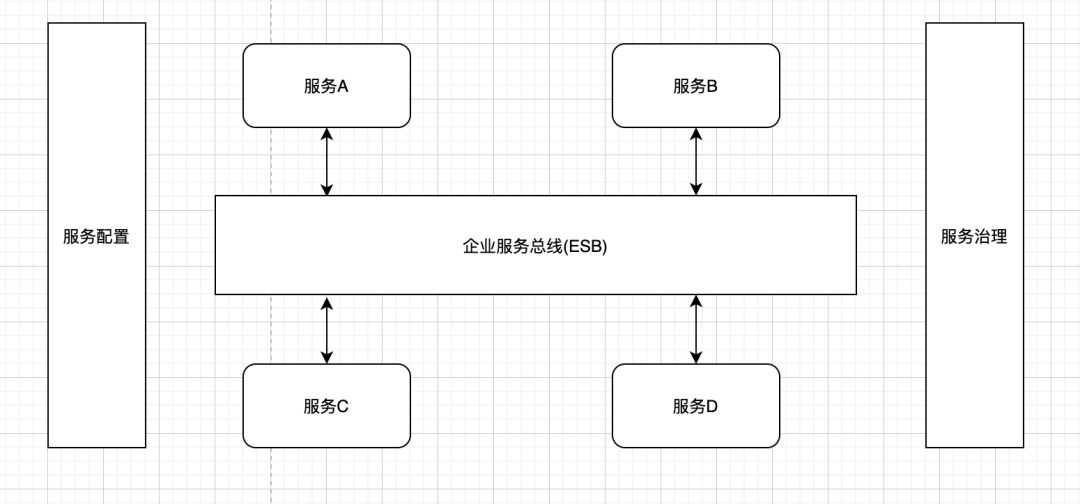
可以看到 SOA 架构中有个 ESB(企业服务总线)。这个 ESB 就是专门用于 SOA 的服务和服务之间的互动,是 SOA 必备的基础技术设施。
正因为 SOA 有了服务总线的思想,就注定 SOA 切分的服务不可能太细,因为服务出现的越多,这个服务总线就最终会变成一个整体系统的瓶颈。
SOA 的服务切分规模本身就受到了限制,这个限制就会带来以下的问题:
切分不够细——我们说过,我们的主要问题根源是系统过于庞大,并且还堆在了一起。如果我们切分不够细,那么可能的结果就会变为,从一个很大的系统被切分为了寥寥几个也很大的系统,最终没有解决问题不说,还可能因为系统变成了不同的分布式服务,又引入了新的分布式系统本身所带来的问题。
ESB 本身就可能成为一个庞大无比的系统怪兽——ESB 作为 SOA 的基础设施,它本身就已经足够复杂,很可能由于业务的发展,它自己也变成了一个恐怖的系统怪物。从而让开发人员不仅需要维护原来的系统,很可能还需要为如何维护和修改ESB本身而伤透脑筋。
所以,可以看出来,SOA这种思维方式和架构实现本身不足以解决庞大单体系统带来的问题。
6. 为什么需要服务
回到我们的微服务的话题。我们知道了问题的根源,我们就需要着手解决这些问题。
首先,既然问题是由于系统的庞大复杂引起的,那么我们就可以参考软件里很普遍的解决思想:分而克之。
无论一个系统有多大,如果我们将其拆的足够小,就可以把一个复杂的大系统拆分成许多个小系统,再让这分解出来的小系统通过对外提供服务的手段,将他们再聚合成一套大的完整体系,从结果上,就等价为了原来的复杂的大系统了。而这,就是微服务的最朴实的思想。
所以,微服务思想核心有两个:
把系统拆分成不同的部分 这些部分要足够小
微服务这样做带来了几个好处:
无论多大多复杂的系统,我只要能拆,会拆,就能把问题简化,从而不用惧怕系统变得复杂。
拆分出来的服务只要足够小,那么无论开发、部署、运维上,都能得到无数原来因为系统庞大而无法获得的好处:修改代码可能变得简单了,测试和运行也变得容易了……
拆分出来的服务能各自独立发展,不会互相制约。原来系统是单体系统的时候,模块之间由于技术上的耦合,导致无法自由自在的选用最适合当前功能模块的技术,也不能随心所欲的根据当前功能模块的负载情况去弹性的安排服务器。
故障天然被隔离开了。我们把系统切分成了服务,每个服务都有自己的进程或者服务器,这样故障从物理层面就被隔离开了,从而避免了一处不重要的功能故障导致整个系统崩盘。我们只需要把核心的功能弄的足够健壮,即使非核心功能有了问题,也不会造成太大的损失。
所以,一套巨大的系统,由于本身的臃肿和复杂,就可能会要对其自身进行拆分。而这些拆分,根据一些指导原则,将其拆解的够小,够简单,那么,拆解后带来的效益是很可观的。
7. 为什么需要拆库
服务已经拆了,已经获得那么大的好处了。
“但是为什么数据库也必须要拆?”——这其实是很多使用微服务的同学最疑惑的问题了。
数据库拆分不拆分本质上其实就是数据共享的问题。而一个服务一个库本身的观念,其实就是尽最大程度的避免数据的共享。
数据共享会带来如下几个问题:
7.1. 技术实现依然可能耦合
因为没有拆分数据库,所以,很可能一个本来应该独立出来的服务模块,必须依赖于另外的服务模块,而这和我们拆分服务的初衷出现了冲突。
比如,订单服务和个性化推荐服务,很可能都需要访问订单相关数据。此时,如果不拆数据库,则很可能由于订单业务需求导致的订单表结构的修改,倒逼个性化推荐服务也要跟着修改。
7.2. 底层数据的过度暴露
还是上面订单服务和个性化推荐服务的例子,个性化推荐很可能只是需要一些用户 id、订单类别之类的东西,但是由于数据库是共享的,很可能开放的就是订单表的全部数据,而这些数据有很多算是敏感数据,应该被隐藏的,现在则被暴露出去了。
7.3. 无必要的数据访问竞争
因为是同一个数据库,这势必会造成对共享数据的竞争性访问,而这些竞争性访问则会大大影响业务模块的弹性部署。比如,订单模块很可能由于个性化推荐的一些定时批量查询,被影响了其能承载的并发数据量。
所以,看出来了吧,分库是必须要考虑进微服务整个体系结构的。
8. 最后留个尾巴
每一个服务对应一个数据库这种模式,是微服务中的最核心最基本的模式,它体现了微服务最核心的思想:
拆分与解耦
一般来说,微服务大部分时候,都会尽量采用一个服务一个数据库的模式。
这里只说了为什么要使用一个服务一个数据库,而如何去分服务,如何去分数据库,它们是否还存在一些实践上的妥协,这会在下一篇文章里仔细解析。
为了下篇文章能早日出炉,希望老铁能来个三连支持,给我点动力~
你好,我是四猿外。
一家上市公司的技术总监,管理的技术团队一百余人。
我从一名非计算机专业的毕业生,转行到程序员,一路打拼,一路成长。
我会通过公众号,
把自己的成长故事写成文章,
把枯燥的技术文章写成故事。
我建了一个读者交流群,里面大部分是程序员,一起聊技术、工作、八卦。欢迎加我微信,拉你入群。
推荐阅读