
人脸识别,现在连动漫角色都不放过
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
看过的动漫太多,以至于认角色时有点脸盲?
又或者,只想给自己的二次元老婆剪个出场合辑,却不得不在各大搜索引擎搜索关于她的照片?
试试爱奇艺推出的这个卡通人脸识别基准数据集iCartoonFace,用它训练AI帮你找动漫素材,效率分分钟翻倍。

对于脸型相近、但角色不同的二次元人物,能准确识别出来(脸盲福音):

如果人物视角出现变化,也能准确识别:

不仅如此,在人脸被大面积遮挡时,也能准确地识别出来:

至于阴影和光照也不在话下,哪怕站在树荫里,也能被AI“侦测”:

效果完全不输现有的真实人脸识别。
那么,这样的技术是怎么做出来的呢?
结合真人数据,训练卡通人脸识别
团队提出了一种卡通和真人的多人物训练框架,主要包括分类损失函数、未知身份拒绝损失函数和域迁移损失函数三部分,如下图所示。
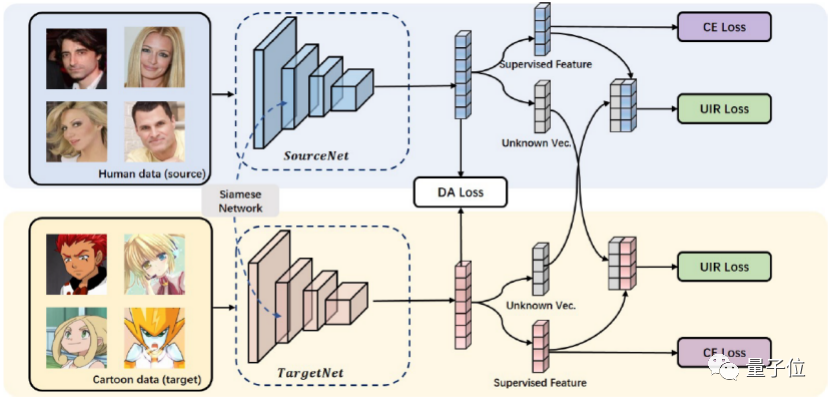
其中,分类损失函数主要用来对卡通脸和真人脸进行分类。
而未知身份拒绝损失函数,则是为了在不同域之间进行无监督正则化投影。
至于域迁移损失函数,目的是降低卡通和真人域之间的差异性,对他们的相关性进行约束。
针对这个框架,研究者们探讨了三个问题:哪种算法最好?人脸识别是否有助于卡通识别?上下文信息对卡通识别是否有用?
从实验结果来看,ArcFace+FL的效果最佳,所以此次团队选用了这个算法。
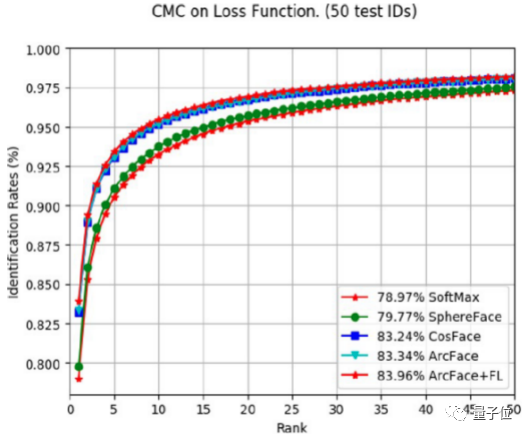
至于后两个问题的答案,也是肯定的。
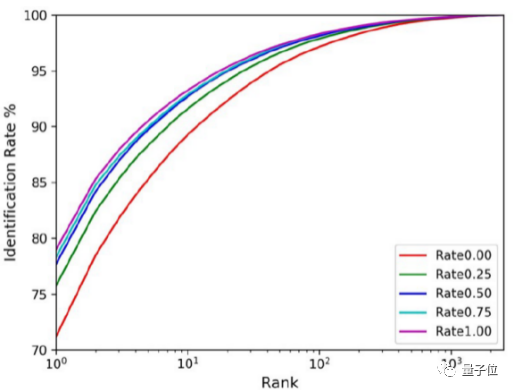
从下图的蓝线来看,加上真人人脸识别的信息后,对于卡通检测的识别同样有帮助。

至于上下文信息,团队也做了实验,下图是算法在卡通人脸基础上扩充不同比例下的性能识别。实验证明,上下文信息越丰富,人脸识别的效果也会更好。
事实上,动物角色训练出来的特征样本,相比于人脸来说,还是有点诡异。
下图中分别是原图和对应的特征样本,相比于动漫男生和女生,虹猫的特征显得有点……不可捉摸。

不过这也说明,一个标准、大型的动漫人脸数据集是有必要的。
标注数据,只需要一步
为了减少人工标注的工作量,研究者们设计了一种半自动数据集构建框架,用于构建iCartoonFace数据集。
如下图,这个框架可以分为三个阶段:

首先,对数据进行分层收集。先获取卡通图片信息,包括专辑和人物名称,再获取卡通人物图片,使得数据集结构非常清晰。
其次,对数据进行过滤。利用卡通人脸检测、特征提取器和特征聚类等,对图片数据进行噪声过滤。
其中,特征提取器的性能会发生变化:随着标注数据的增多,性能不断增强。
最后,标注人员只需要做一个步骤:根据特征聚类的结果,回答两张图片是否是同一个人物。

目前最大的卡通人物标注数据集
事实上,目前已有大量针对真人的人脸识别的技术和算法。
然而,针对二次元人脸识别的数据集依旧少之又少,大多数数据集存在着噪音比例大、数据量小的问题。
但这样的需求的确存在,不局限于对视频的结构化分析,还能应用于图片搜索、广告识别等场景。
例如,给创作者提供智能剪辑、或者是对恶搞的讽刺漫画、卡通风格人物进行审核辨识。
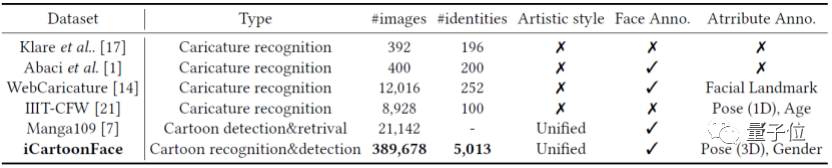
针对这个现象,爱奇艺开放了目前全球最大的手工标注卡通人物检测数据集与识别数据集iCartoonFace,包含超过5000个卡通人物、40万张以上的高质量实景图片。
下图是iCartoonFace与其他已有动漫数据集的对比,基于这个数据集设计框架,可以有效地提高卡通人物识别性能。
说不定,真能让广大观众对动漫角色“不再脸盲”。
论文链接:
https://arxiv.org/pdf/1907.13394.pdf
数据集(在竞赛数据集一栏):
https://iqiyi.cn/icartoonface
如果你对CV感兴趣 打算转行CV,或者你已经有一定基础想要挑战高薪,可以看下七月在线【CV就业小班 第六期】课程,可以保证就业!
此课程在教学模式、实战项目、讲师团队、就业服务,在国内都是非常领先的,还专门为学员提供一年的GPU云平台使用。


六大实战项目


专家级讲师阵容

往期学员就业薪资

(篇幅有限,只节选部分)
扫码查看课程详情,同时大家也可以去看看之前学员的面试经验分享。
戳↓↓“阅读原文”和老师申请优惠!