
懂你,更懂Rust系列之ownership
我祈祷拥有一颗透明的心灵
和会流泪的眼睛
给我再去相信的勇气
oh~越过谎言去拥抱你
每当我找不到存在的意义
每当我迷失在黑夜里
oh~夜空中最亮的星
请指引我靠近你
夜空中最亮的星
在了解这个ownership之前,先需要认识下两种计算机内存结构
Heap《堆》和Stack《栈》
Heap和Stack都是内存的一部分,在程序运行的时候,Heap和Stack中保存有系统运行的相关数据或变量,Heap和Stack的结构方式不同,其中Stack是一个先进后出的队列结构,如下图:
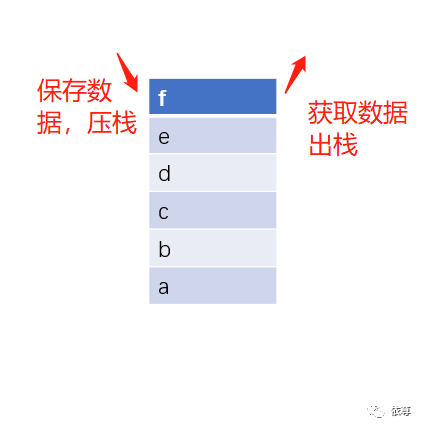
如上图所示,Stack中保存了abcde五个数据,其中按照abcde的顺序保存,获取数据的时候,只能按照edcba的顺序出栈。
具体可以参照有一篇关于JVM虚拟机描述的Java虚拟机栈中操作数栈的描述的那样
在Rust语言中,所有存储在Stack上的数据必须有一个已知的固定的大小,Rust编译的时候,那些未知大小的数据,或者大小可能发生改变的数据,将会被保存在Heap中,Heap的组织性较差,当保存数据在Heap中的时候,需要确定的空间大小,内存分配器《memory allocator》在Heap中会找到一个足够大小的空间存储数据,同时返回一个指针,即表明该数据所在Heap中的位置。这个过程即为堆上分配。
这里可以看出,在Stack中分配数据的效率远远比在Heap中分配数据的效率要高很多,因为Stack中,只需要将数据压入栈顶即可,而Heap中则需要去寻找一个足够大的地方,同时获取这个地方的指针索引,同样的,获取数据,Stack只需要弹出栈顶元素即可,而Heap中则需要根据索引指针找到数据所在位置,然后才能获取数据。
通常情况下,当代码调用一个函数的时候,传递到函数中的值(可能包含指向Heap中的指针对象)和函数局部变量将被压入Stack中,当函数调用结束,这些值将会被弹出Stack
ownership则是解决如何跟踪代码中哪部分使用了Heap中的数据,最小化堆中数据重复量,以及及时清理未使用的堆中数据。
所有权规则<ownership Rule> :
Each value in Rust has a variable that’s called its owner.
There can only be one owner at a time.
When the owner goes out of scope, the value will be dropped.
大致意思就是:
Rust语言中每一个变量值都有一个属于自己的所有权
一次只能拥有一个所有权
当所有权超出作用域时,该值将被删除
一、Variable Scope
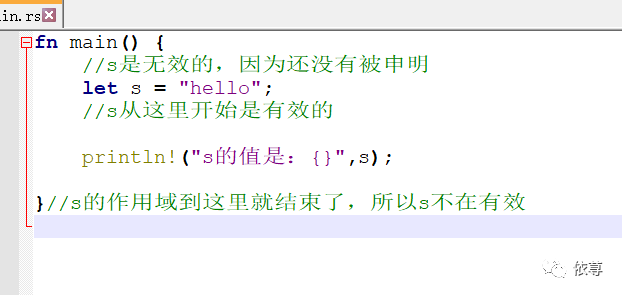
看上面这段代码,在main方法里申明了一个变量s,然后打印输出,在s还没有被申明的时候,s是无效的,当退出main方法的时候,s离开作用域,同时也变无效
即:
当s进入作用域时,它是有效的,
然后它一直有效,直到超出作用域
这里需要指出的是,在前面说到的Rust语言基本类型<懂你,更懂Rust系列之数据类型>(除开数组和元祖)的数据,都是存储在Stack中的,并且在它们的作用域结束时,弹出Stack。
所以,基于基本类型保存在Stack中的数据,不需要过多的去探讨,重点需要关注的是那些保存在Heap中的数据,上面这个小例子,过于简化,因为这里申明了一个定长的string类型的数据,即这里是将string类型的s硬编码到程序中,所以其执行效率是很高的。那么对于那些未知大小的数据情况呢?
比如下面代码:
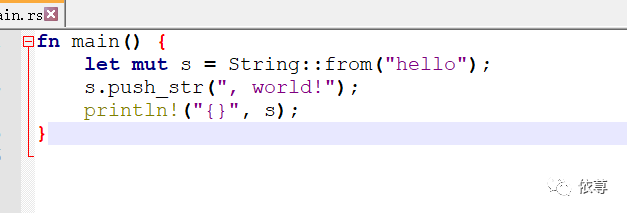
这里的双冒号(::)是一个操作符号,String::from是指从字符串文本中创建字符串,s.push_str是指将变量s追加字符串
这里可以看到,这是一个可变、不定长的字符串类型,不能通过硬编码的方式在程序中引入二进制的内存块来保存数据了。
所以,对于这种类型的string,需要在Heap中分配一定数量的内存,同时,这需要程序或者程序员做以下事:
1、必须在程序运行的时候,从内存分配器中请求内存
2、当用完这个字符串的时候,把这个内存返回给分配器
第一件事,在调用String::from的时候,程序给我们完成了,这个在很多编程语言中都是比较相似的,
第二件事,在不同的编程语言中,是有很大区别的,在有GC收集器的语言(比如Java、Python等),GC收集器会跟踪并识别这些区域,然后将其清理掉。在没有GC收集器时,需要我们识别出内存什么时候不再被使用,并显示调用代码,返回内存
做到第二点其实是比较难的,如果忘记了,则浪费内存,容易引起内存泄漏,如果太早的调用代码清除返回内存,则可能使定义的变量是个无效的变量。如果做了2次,那也是个BUG,我们就必须将分配的一个内存和释放的一个内存精确的配对。
Rust语言提供了不同的路径解决这个内存回收的问题,一旦拥有内存的变量超出作用域,则内存就自动释放并返回。
针对上面的代码做些说明:
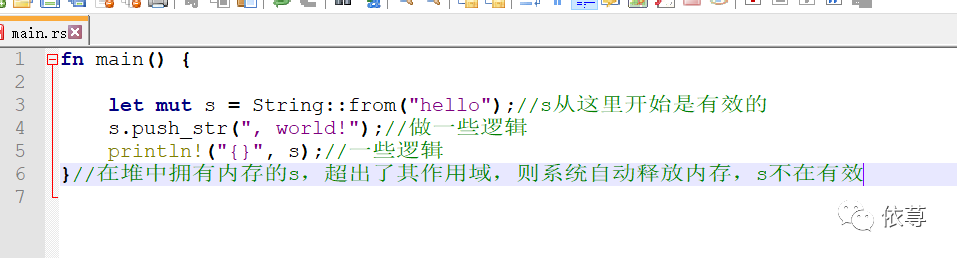
类似在C++语言中,在项目生命周期结束时,重新分配资源的模式被称为RAII,这里可以类比的理解
二、Ways Variables and Data Interact: Move
看下面代码:
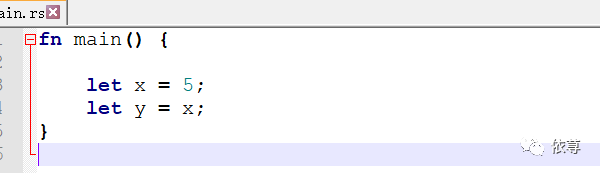
这里不难理解,首先定义一个变量x,将5赋值给这个变量,然后再次复制一个x的值5绑定到y中,此时我们拥有了2个变量值,都等于5,此时两个5均被压入Stack中:

因为基本类型都是定长大小的,是保存在Stack中的,那么如果是Heap中的String呢?
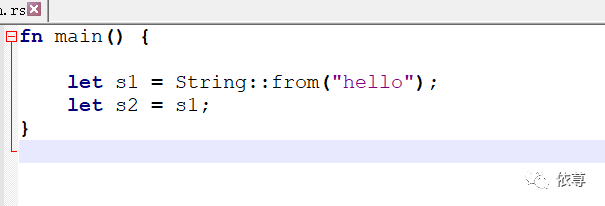
这里和上一段代码是很类似的,但是其内存实现方式是有很大区别的:
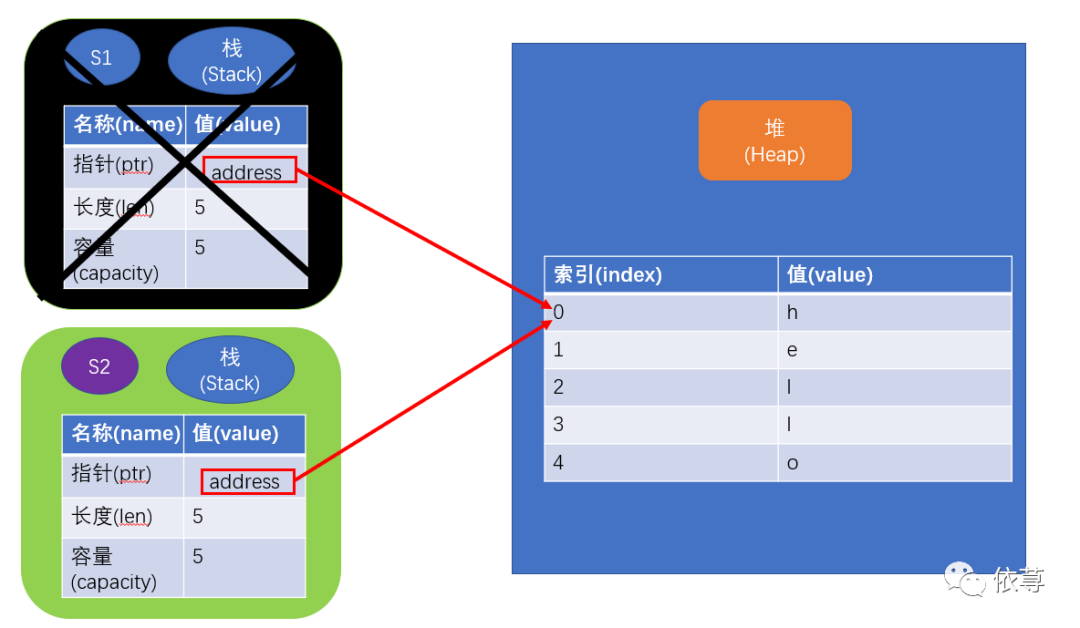
首先我们来看下s1在内存中的保存方式:
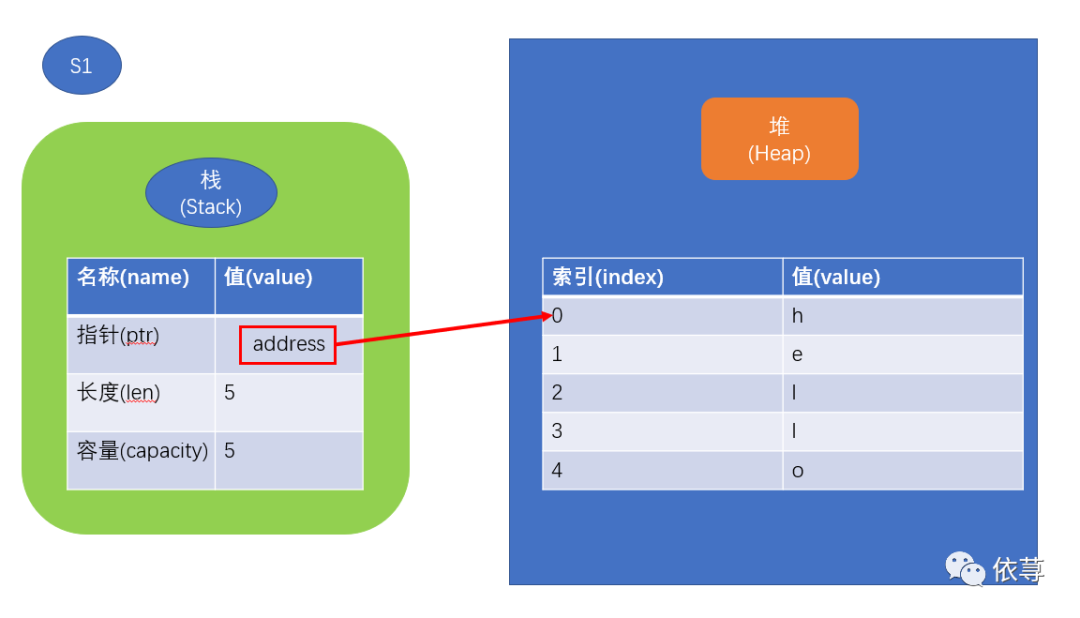
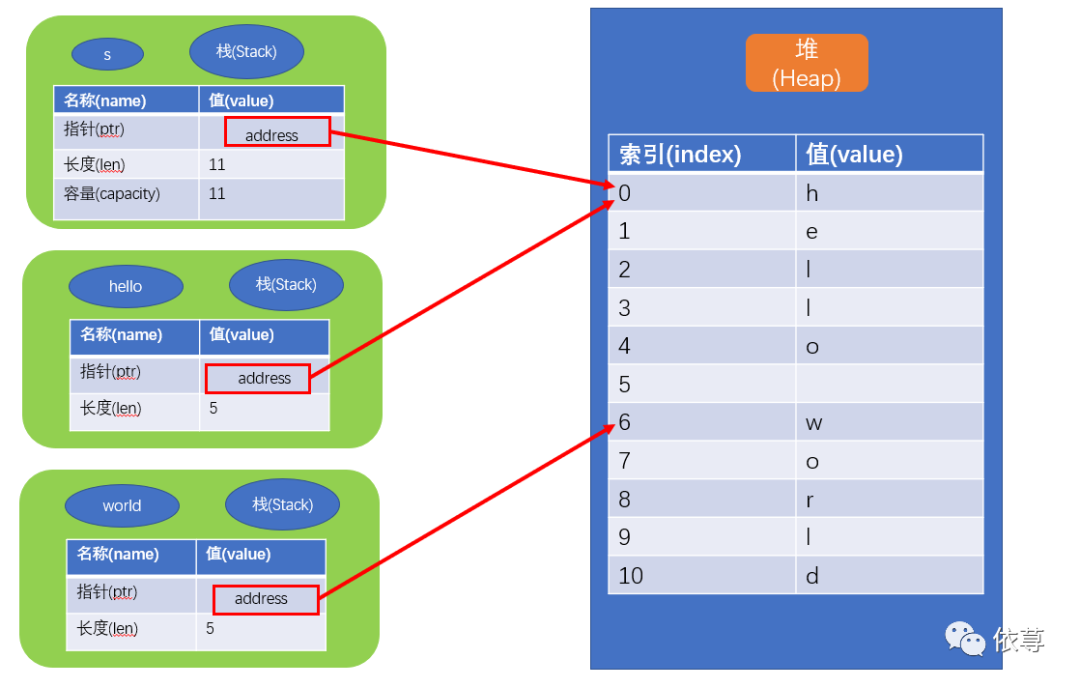
首先,字符串类型由3部分组成,如上图左边所示:指向保存字符串内容的内存指针地址、字符串长度、字符串容量,这些数据是保存在Stack中的,而这个内存指针指向堆中字符串内容。
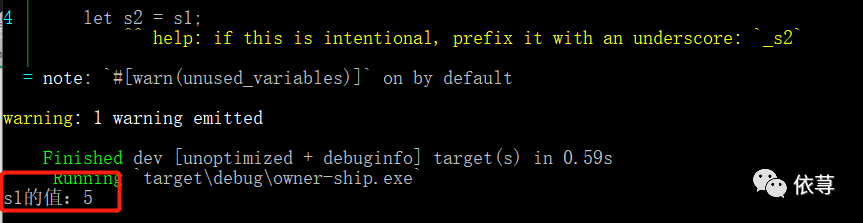
那么当执行let s2 = s1的时候,发生了什么呢?
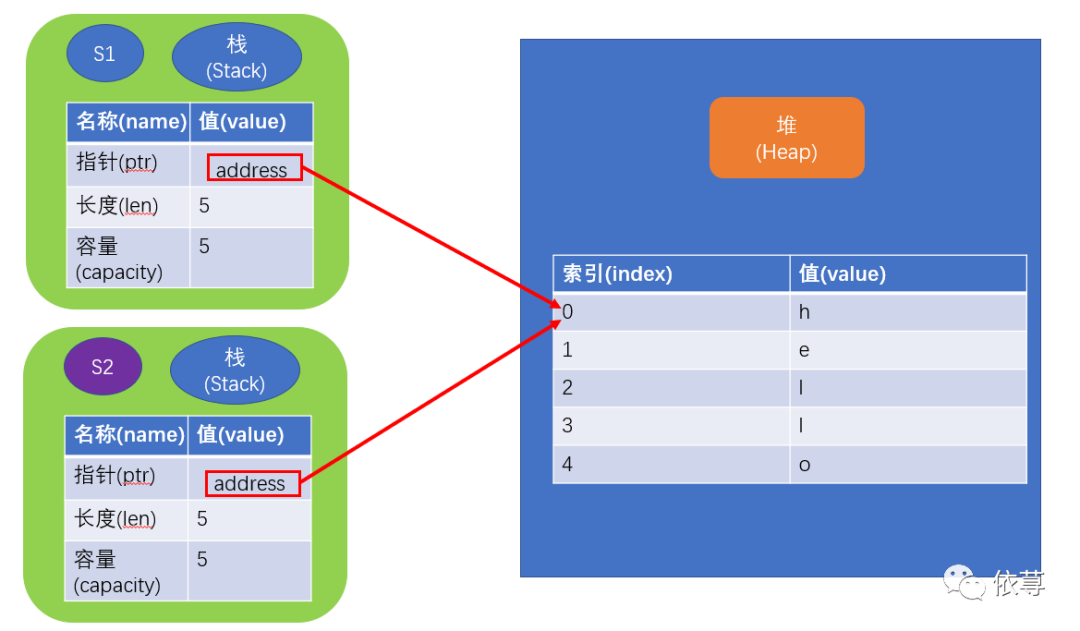
如上图所示,当执行let s2 = s1时,程序会复制Stack中的内容,即s2的内存地址指针指向了原本s1指向的地址,Heap中的内容并没有跟随堆的复制而复制。
前面我们说过,当变量超出作用域时,会自动释放内存(rust调用drop实现),但这里,两个变量同时指向了相同的堆内存地址,即当s1和s2超出作用域的时候,将释放2次相同的内存,这就是double free error,属于一个内存安全漏洞,两次释放可能导致内存损坏。
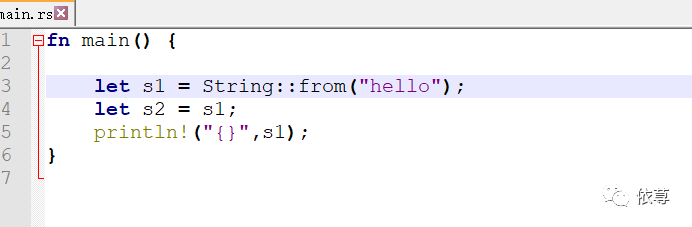
为了解决这个问题,Rust认为,当s2创建完成后,s1不再有效。即:
比如代码尝试使用s1:
编译报错:
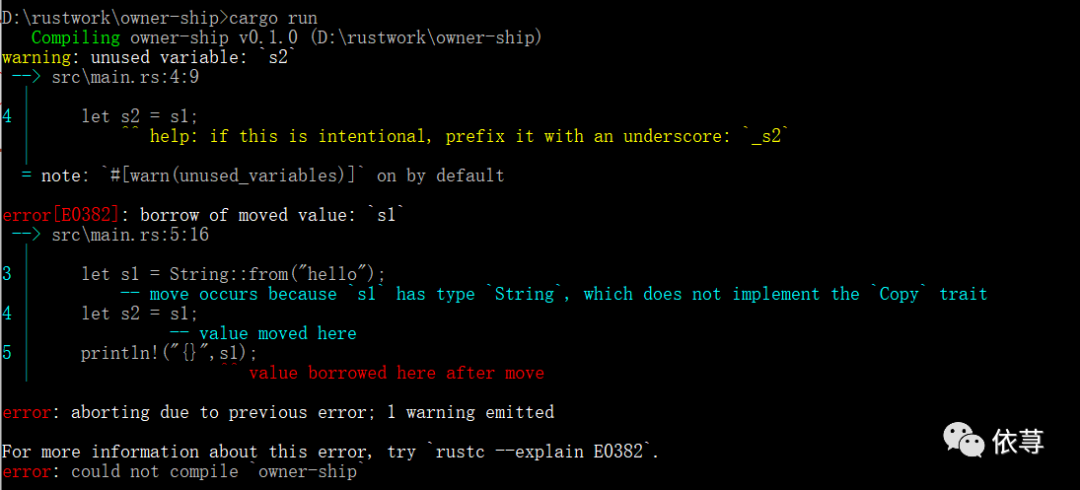
这里既是数据之间的移动,即移动之后,原本的对象无效了。
这种移动仅仅限于在堆上分配内存保存的数据,基本类型由于是在栈上存储,则是可以的,比如前面的代码是可以运行的:
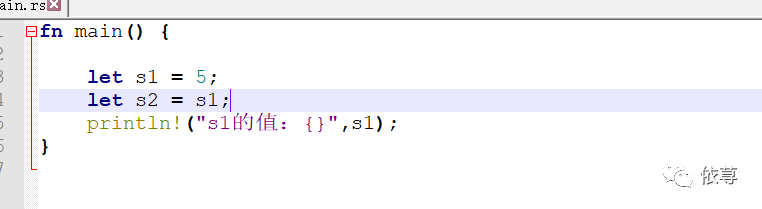
编译运行:
三、Ways Variables and Data Interact: Clone
那么针对上面移动的字符串例子,如果我们确实需要复制一个呢?这里有一种克隆方法:
编译运行:
此时内存发生的变化则是这样了:
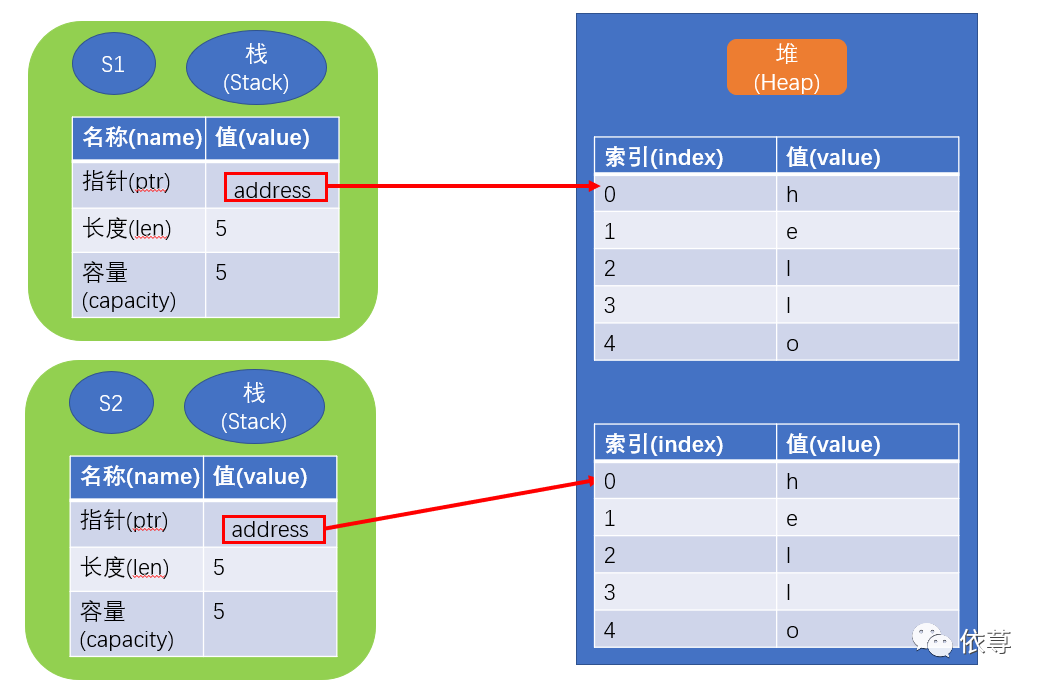
即Heap中的内存也得到了复制,不过这是一个很昂贵的代价,系统需要花费比较大的消耗去完成这件事。
克隆结果的两个对象,其==比较结果是为true的
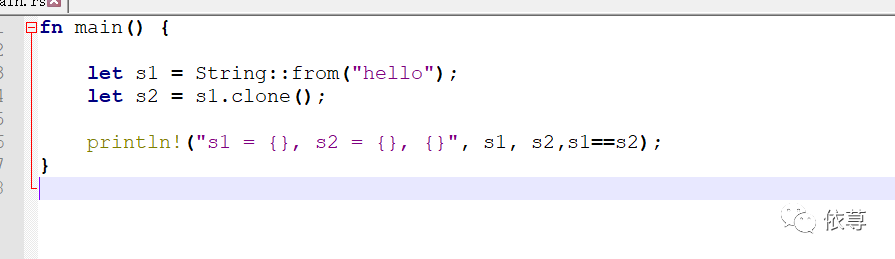
编译运行:

四、Stack-Only Data: Copy
这里就是针对前面介绍的基本类型的栈上分配数据是不会产生移动的,不在过多赘述:
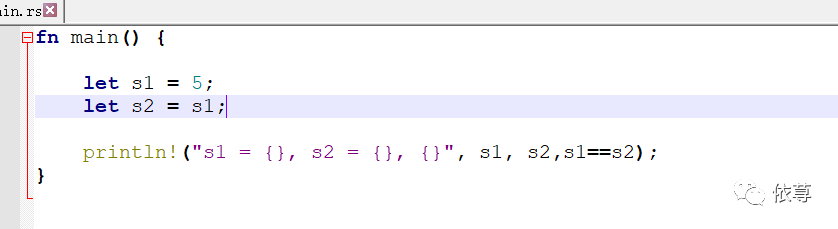
编译运行:

五、Ownership and Functions
看如下代码:
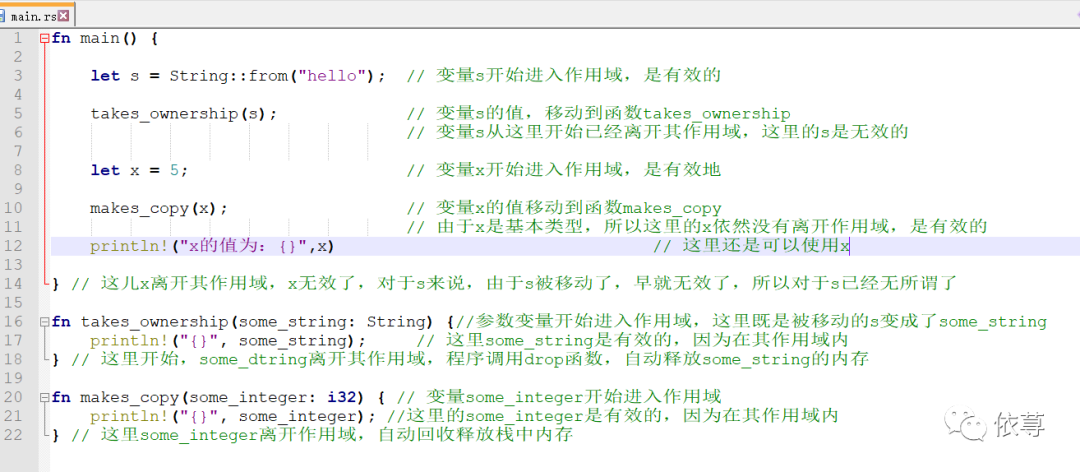
需要指出的是,当非基本类型变量进入函数体时,变量产生移动,原始变量不在有效。这是区别于其他很多高级语言的。
编译运行:
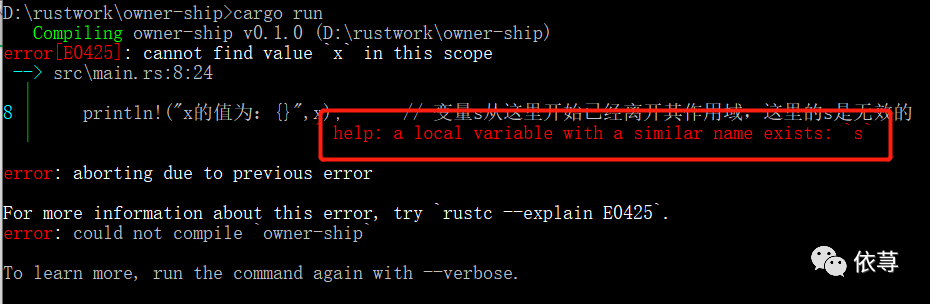
但是如果我们试图在main函数内,takes_ownership函数之后,调用s,编译就会报错,比如:
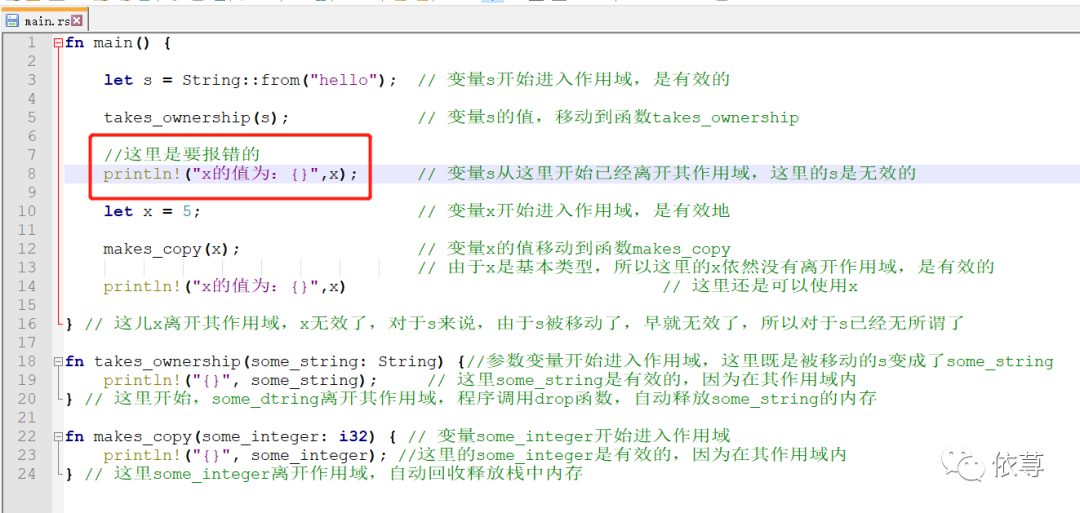
编译报错:
六、Return Values and Scope
函数返回值,也是具有移动的,看下面代码:
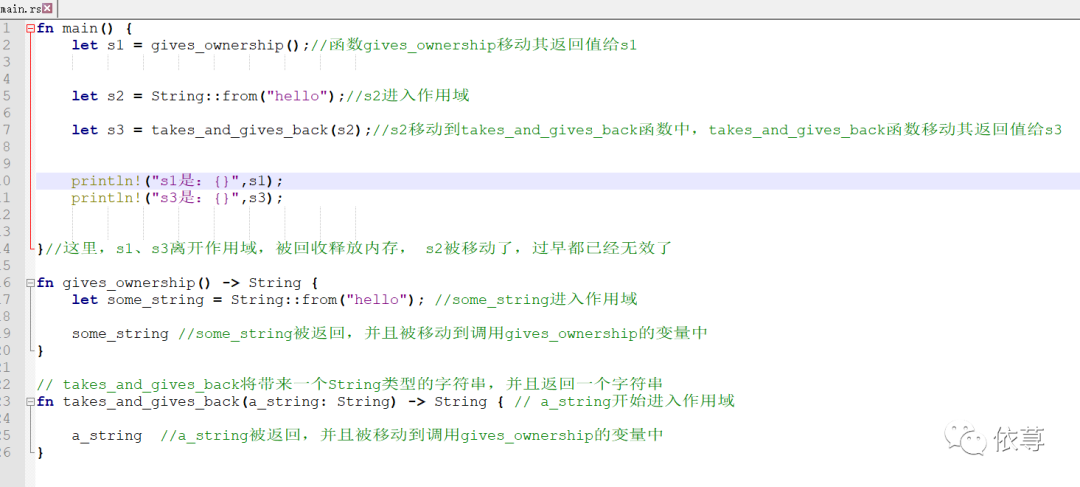
拥有返回值的函数,在被调用之后,其返回值将移动到调用者
所以,在调用takes_and_gives_back函数之后,试图拿到s2也是会编译报错的,这里就不做试验了。
可以简单做个小结:
变量的所有权,在每次给另外一个变量赋值时,将会移动该变量,当变量超出作用域时,变量被回收,释放内存。
函数会获取参数的所有权,被调用者调用,又将返回所有权给调用者,那么有时候,需要让函数只是使用某个值,并不让其产生变量移动效果,怎么解决这个问题呢?一般来说,可以使用函数返回值是元组的方式来完成这个操作。
即:
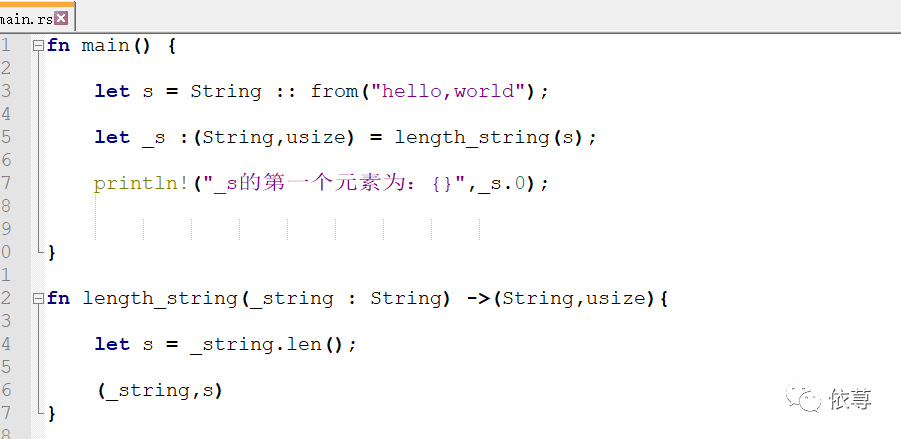
编译运行:

这里,length_string函数返回了元祖数据,将参数返回了,还可以继续用。
这里的代码稍微做改变:
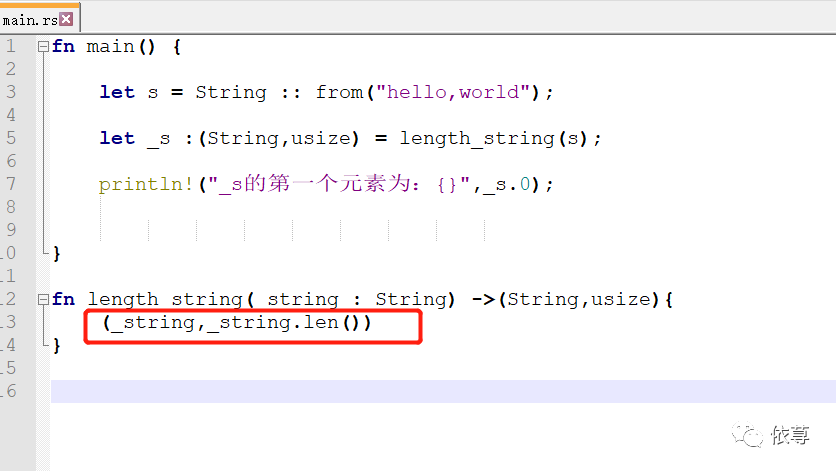
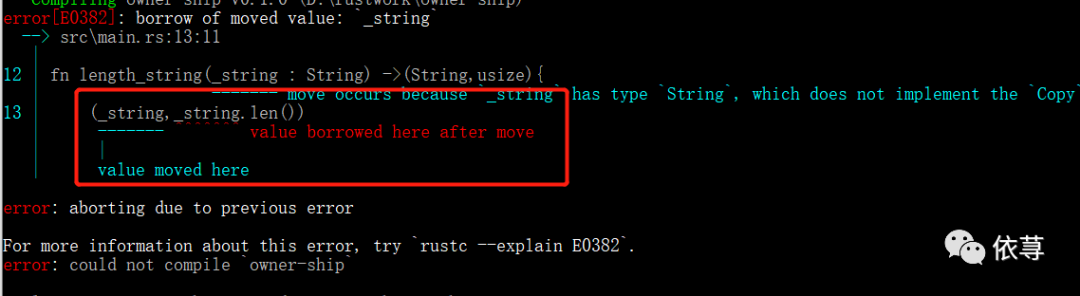
这里是会编译报错的,
当执行返回值构造方法后,其第一个元素为_string,所以参数_string已经发生了移动,不在有效,当调用_string.len()方法时,_string已经无效了。
编译报错
如果在实际项目中,需要调用函数的时候,还可以返回参数,通过这种方式固然可以实现,但是有点太过于麻烦了,这时候,Rust提出了另外一个概念,引用-->References
七、References & Borrowing
这里还是为了解决上面那个问题,看下面代码:
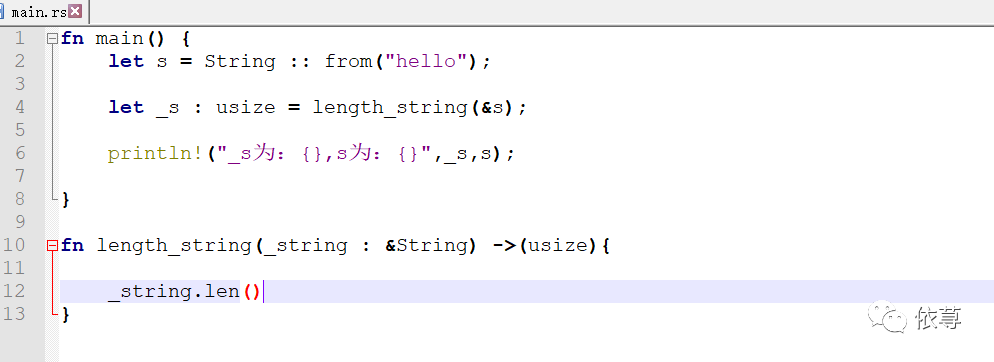
编译运行:
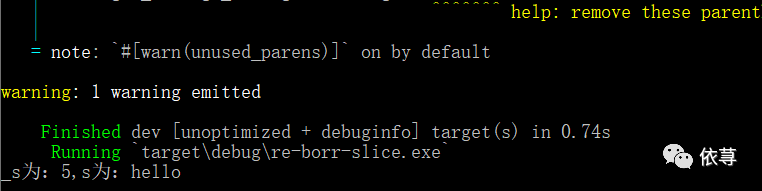
这里可以看到,s作为参数传入函数length_string中后,并没有发生移动。在函数length_string中,_string变量其实只是引用了s,并没有将s的所有权移动到_string中,所以当_string超出作用域后,其指向的值,并不会被删除。
其内存指针如下图:
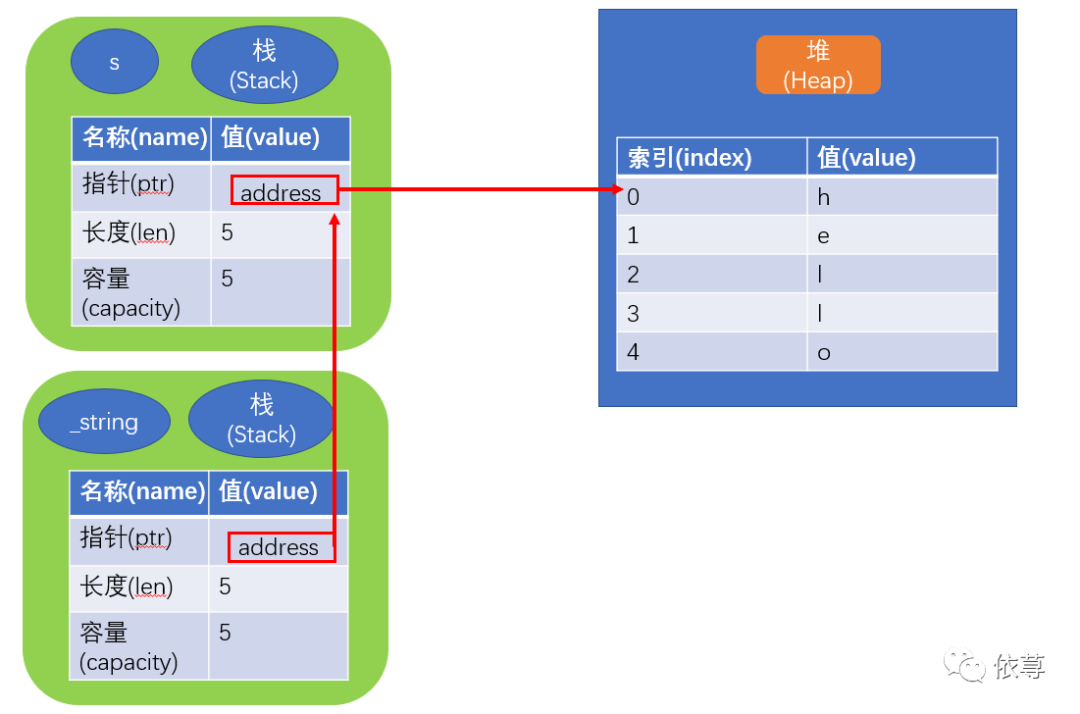
给上面代码加些注释:
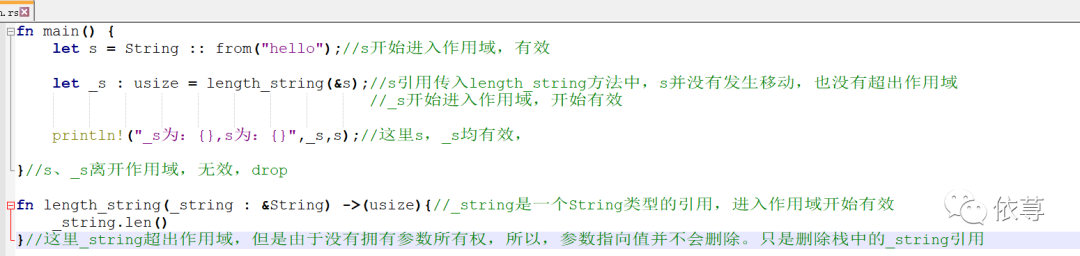
我们把&s称为s的引用<references>
把这种引用称为函数的参数租借<borrowing>
一般来说,在调用函数的时候,需要进行参数值的一些改变,这里由于没有得到参数所有权,所以是会编译报错的
这里举个简单的例子,引用好比现在去租了一个房子,但是并没有拥有房子的所有权,就只能简单的住在这里,所以,如果在没有经过房东的同意,假设我修改了房子的结构,那肯定是会发生状况的。
比如:
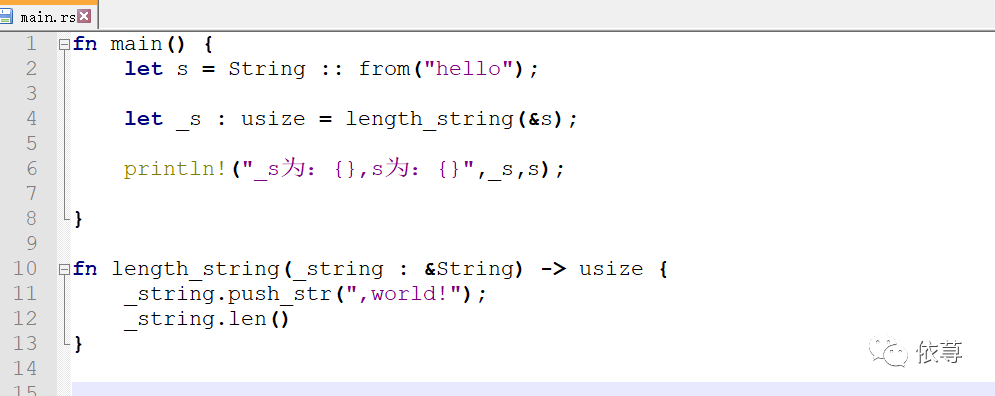
这里在调用函数的时候,对参数进行了拼接,编译报错:
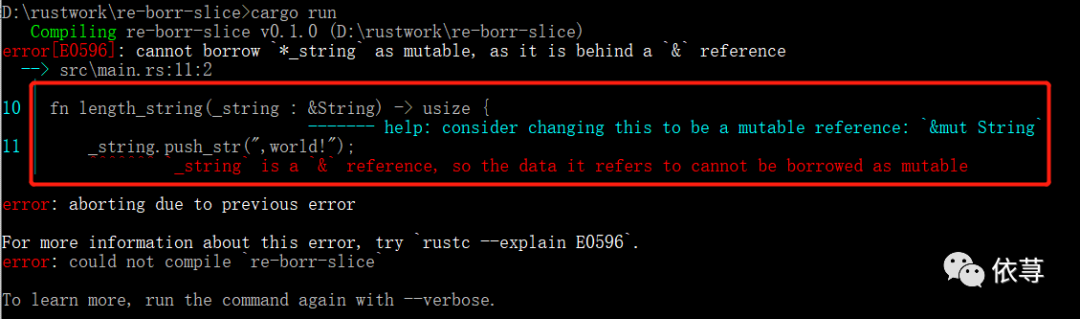
`_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
这个报错信息给与了我们一个解决方案:
即,它告诉我们,这个引用必须是可变的
于是,改进代码:
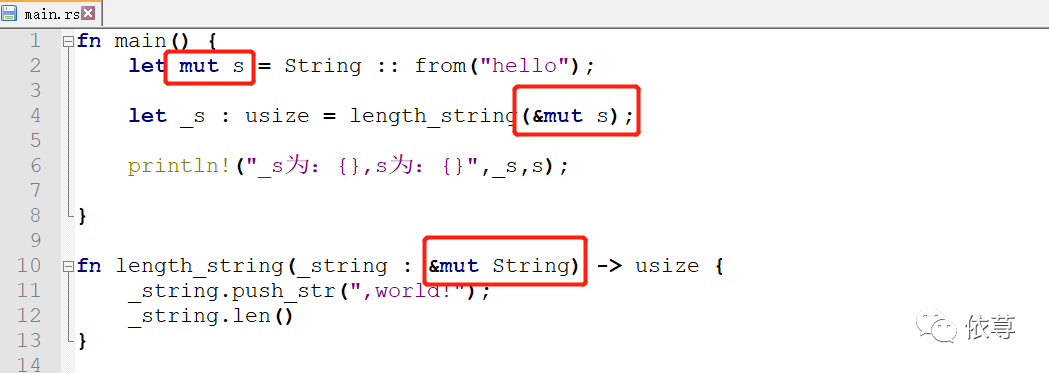
编译运行:

这里有一个需要记住的地方,可变引用在特定范围内,只能有一个对特定数据块的可变引用,比如下面代码:
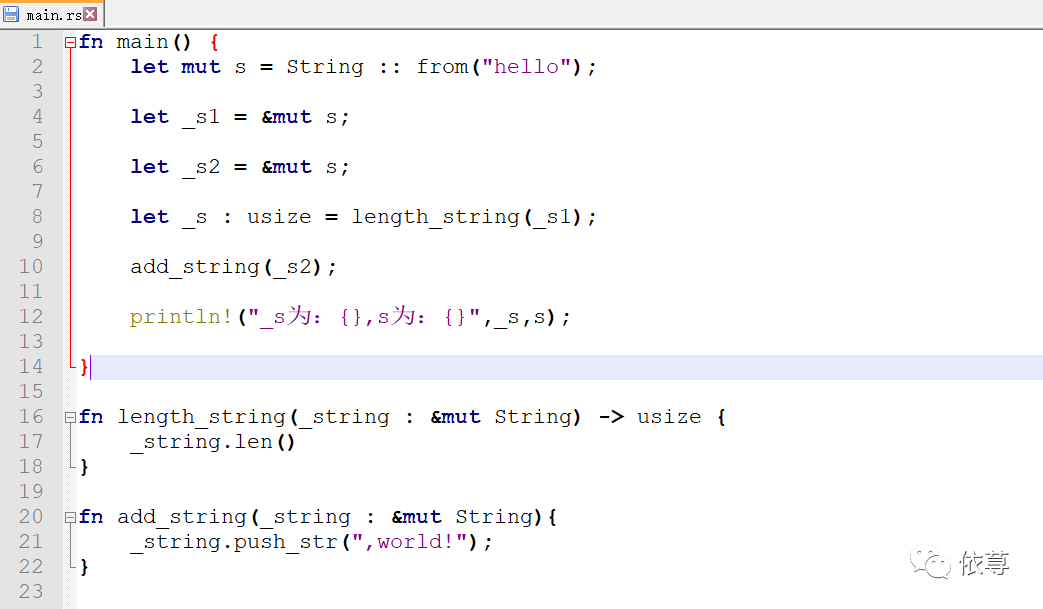
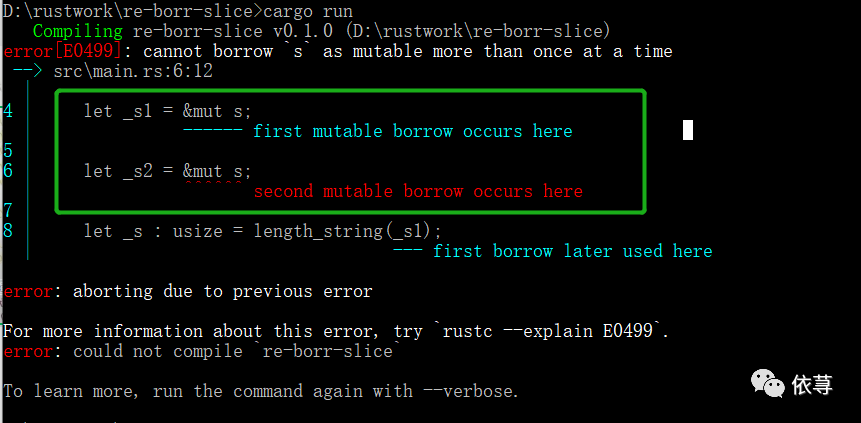
编译报错:
移动下位置:
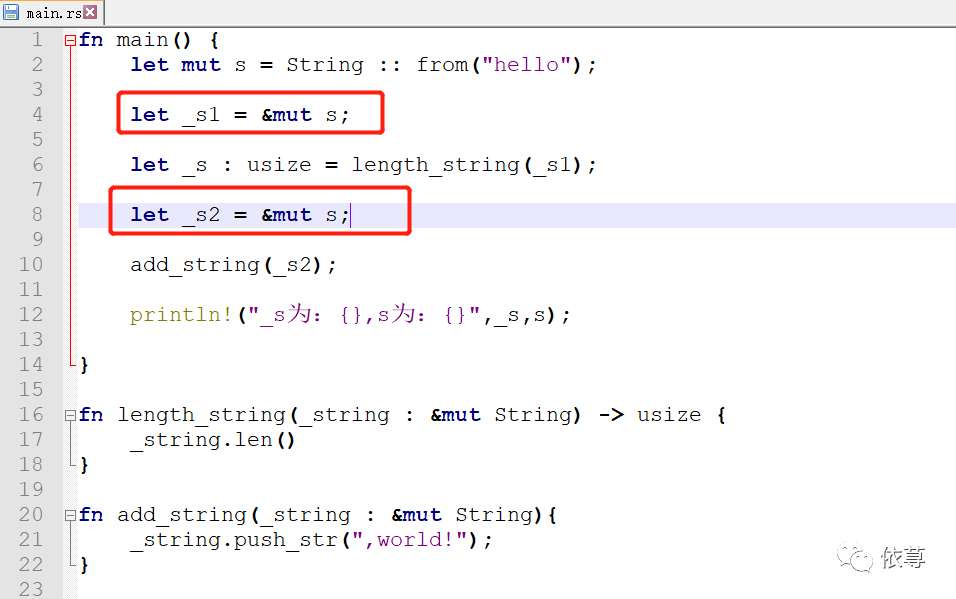
这个时候,编译运行:

这个时候为什么就是可以的?可以想一下,看看前面的内容是不是忘了?
tips:_s1变量在调用length_string函数的时候,传入的是_s1,_s1发生了移动,_s1不在有效。
在特定范围内,保证只有一个可变引用,可以防止多个指针指向相同对象时,发生对指针指向对象改变值所导致的数据竞争,这种情况在其他多数语言中都可能发生,但Rust在编译阶段就防止这种情况。
看下面这种情况:
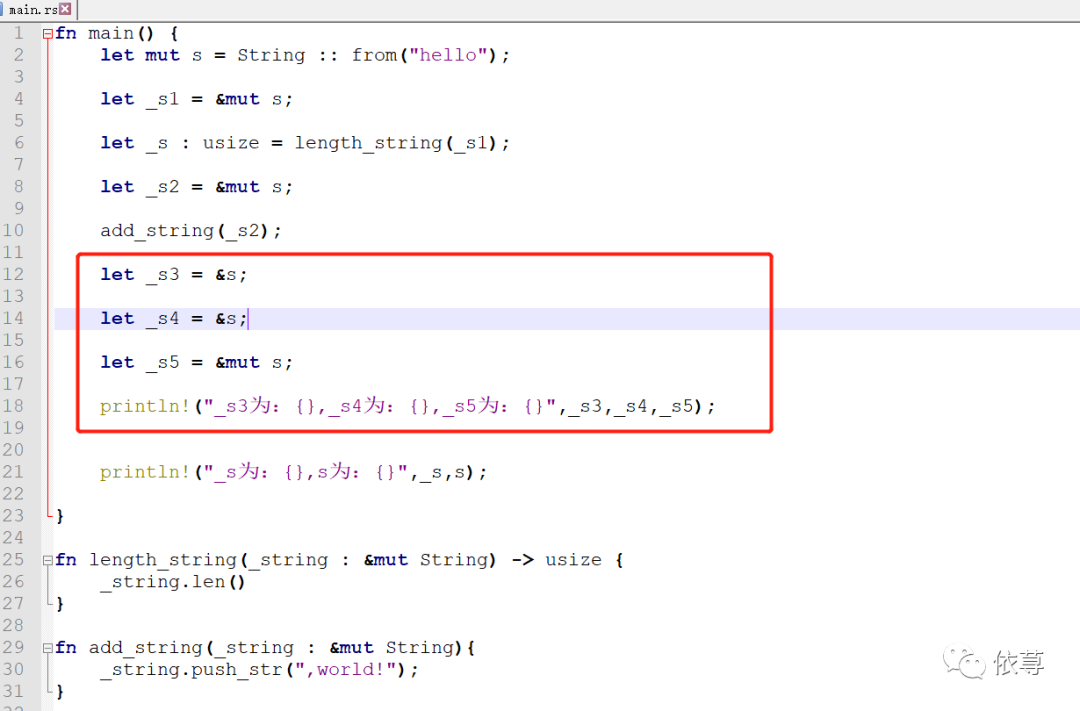
这里12行,定义_s3为可变变量s的不可变引用,_s4为可变变量s的不可变引用,这两个变量的定义,都没有问题,只是后面定义了一个_s5为可变变量s的可变引用,
编译报错:
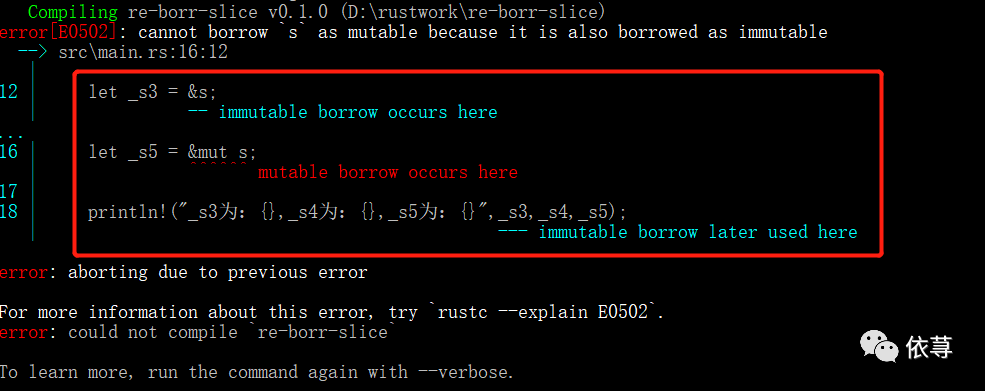
报错信息告诉我们,当变量不可变引用存在租借的情况,在变量不可变引用没有超过作用域的时候不能定义变量为可变引用。
修改下代码:
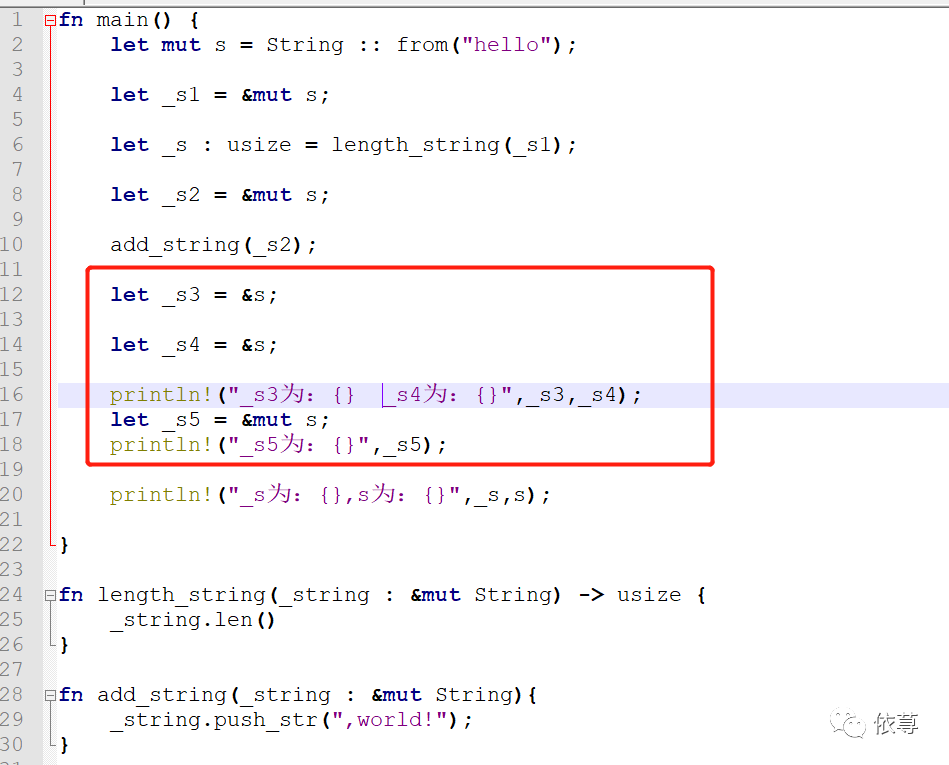
编译运行:
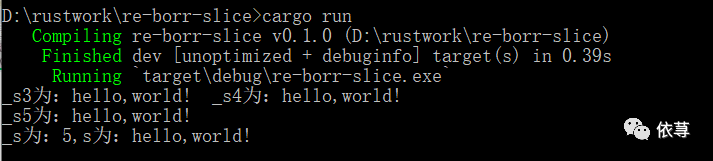
因为当调用println方法后,_s3和_s4发生了移动,不在有效,所以可以再次定义变量可变引用。
通常情况下,在有指针存在的语言中,可能出现指针存在,但是指针指向的内存已经被释放的情况,即dangling pointer,在Rust中,这种情况,编译阶段就会出现错误:
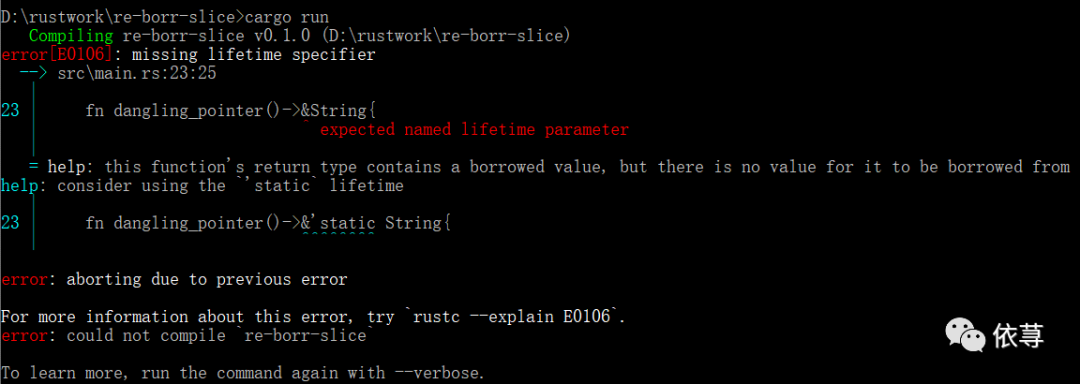
比如:

这里,定义一个String类型,然后返回这个变量_k的引用,当_k超出dangling_pointer函数的时候,程序会调用drop,清理掉_k的内存,但是返回了_k的栈引用,
这其实是个错误示范
编译报错:
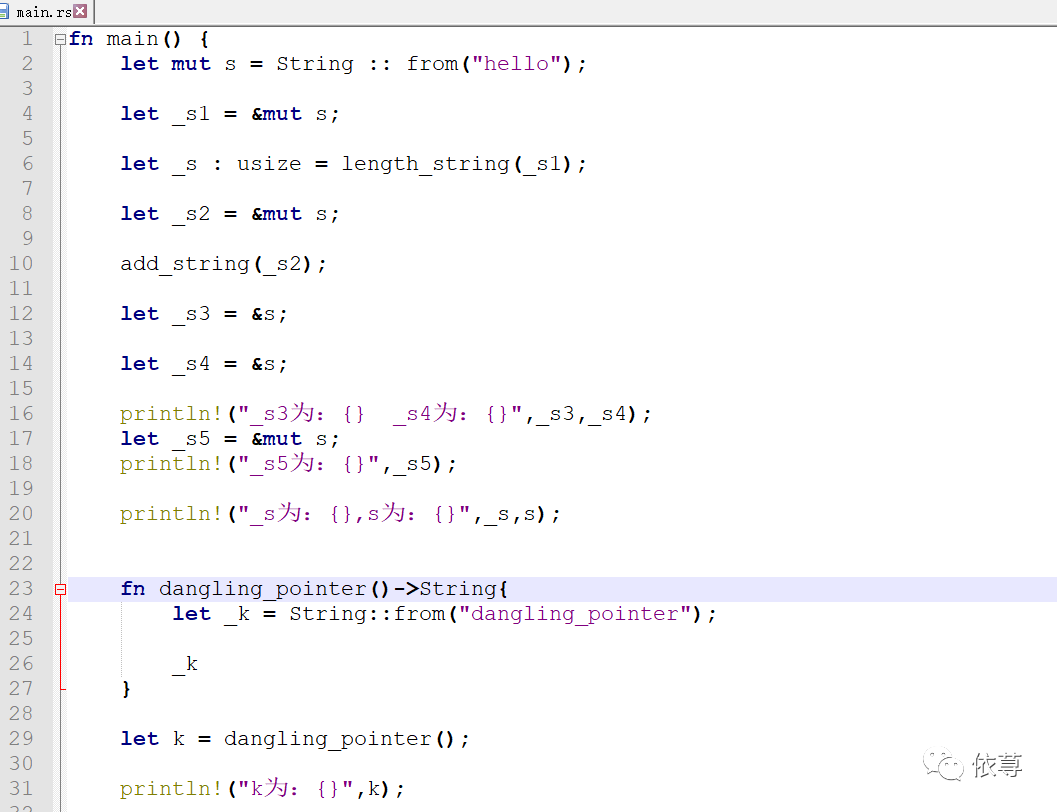
但是可以这样:
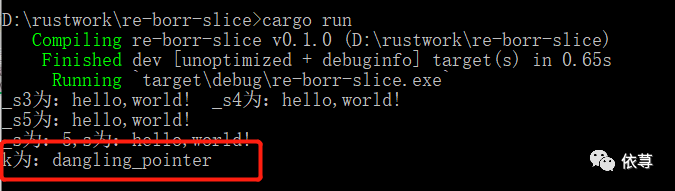
编译运行
八、The Slice Type
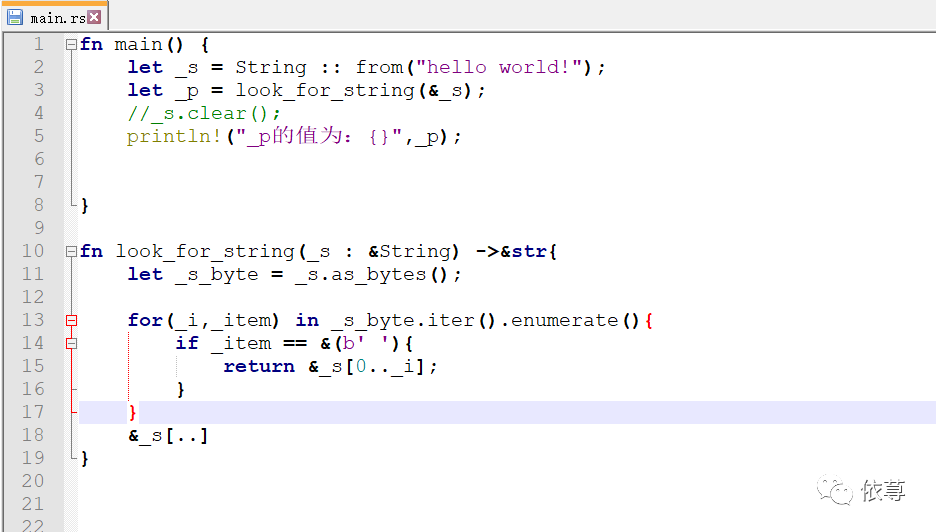
下面实现这么一个功能,从字符串中找到某个字符在字符串中所在的位置,
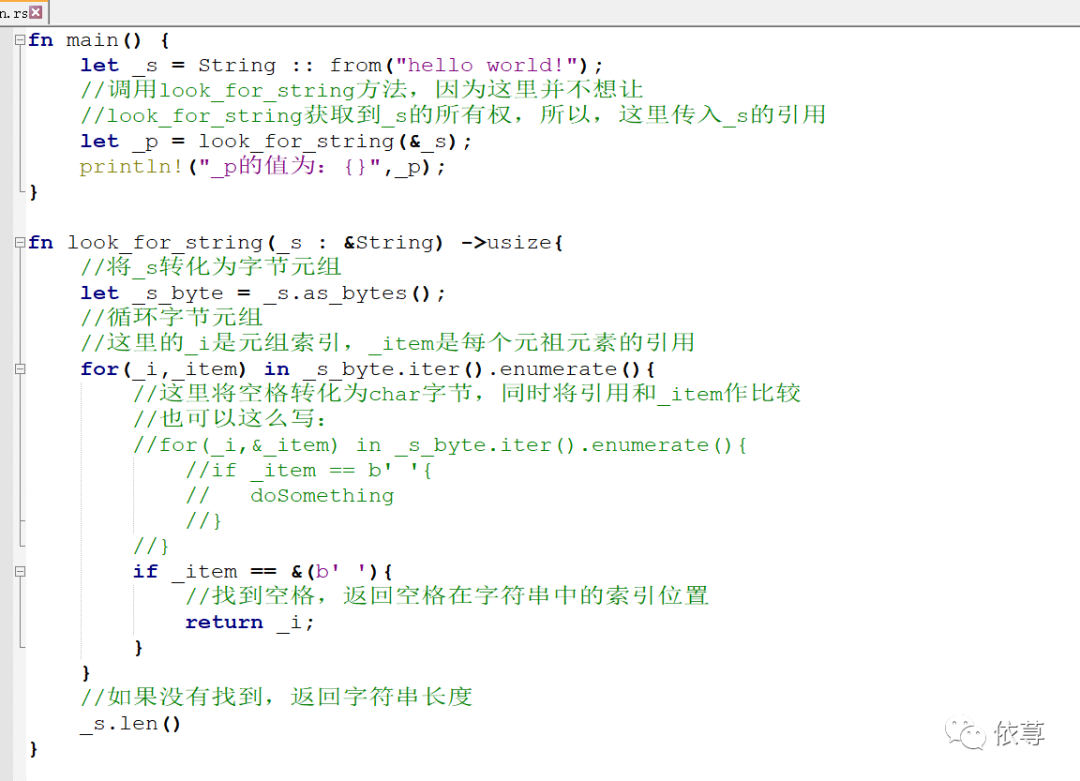
程序编译运行肯定是没有什么问题的,
也可以很容易的拿到_p的值是5

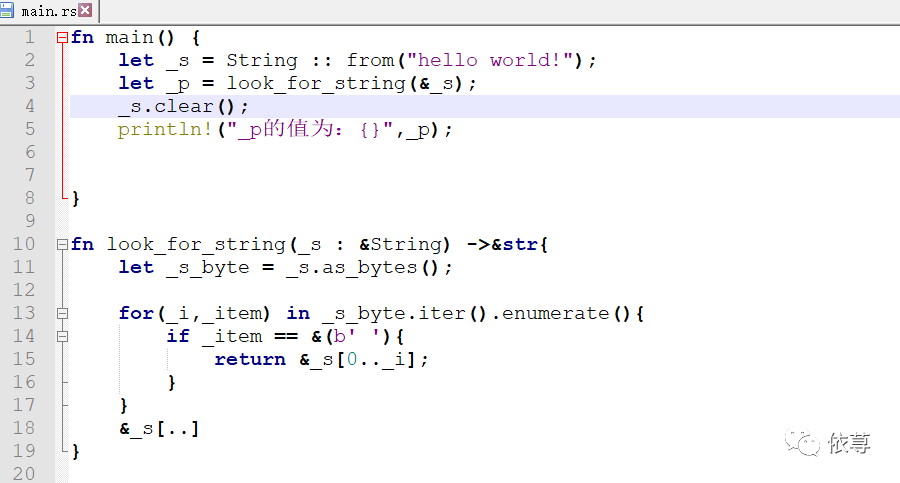
那么,接下来,拿到这个5,一般来说,是需要有所作用的,比如根据这个5,获取_s中指定部分数据,就上面代码示例来看,也是可以调用截取,根据_s和_p做一些操作,那如果,我们清空_s呢?
比如:
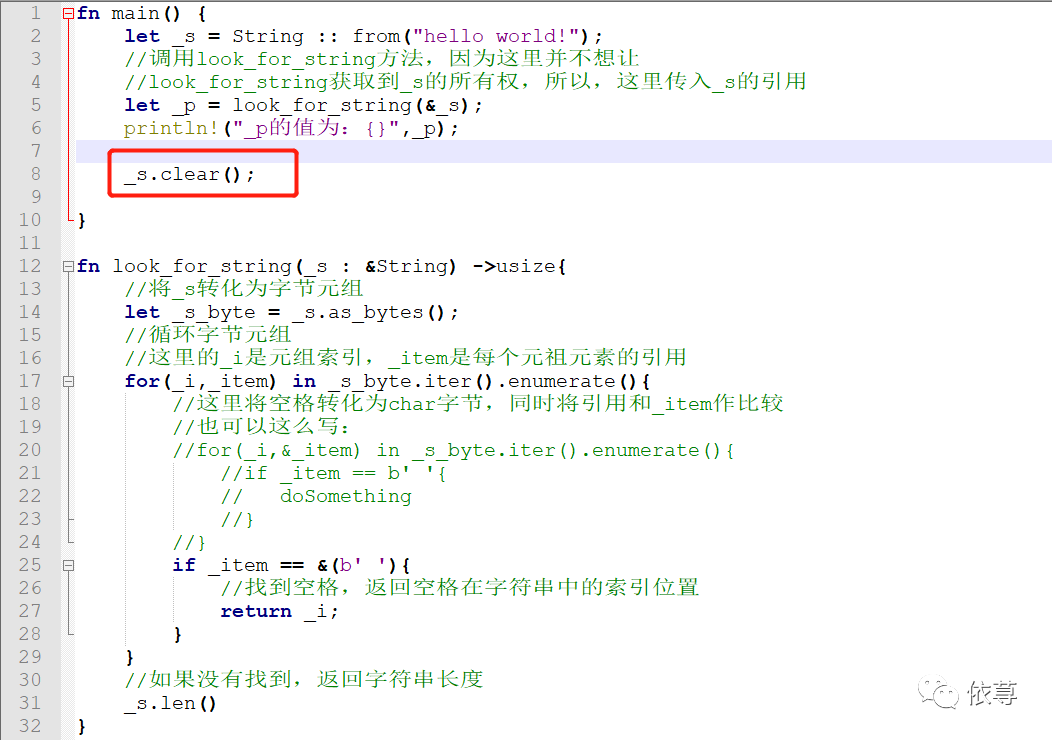
在调用_s.clear(),之后,仿佛这个_p的意义就不大了<这里仅仅是为了接下来的内容引入,不接受类似‘不调用_s.clear()就好了’之类的反驳。(#^.^#)>,因为没有办法截取了,_s已经空了!
Rust语言提供了一种类型,帮助我们解决这个问题,即,可以获取字符串指定部分内容,同时将截取的部分内容称为:片(slice)
看下面代码:

编译输出:

这里就是简单的slice类型的定义,
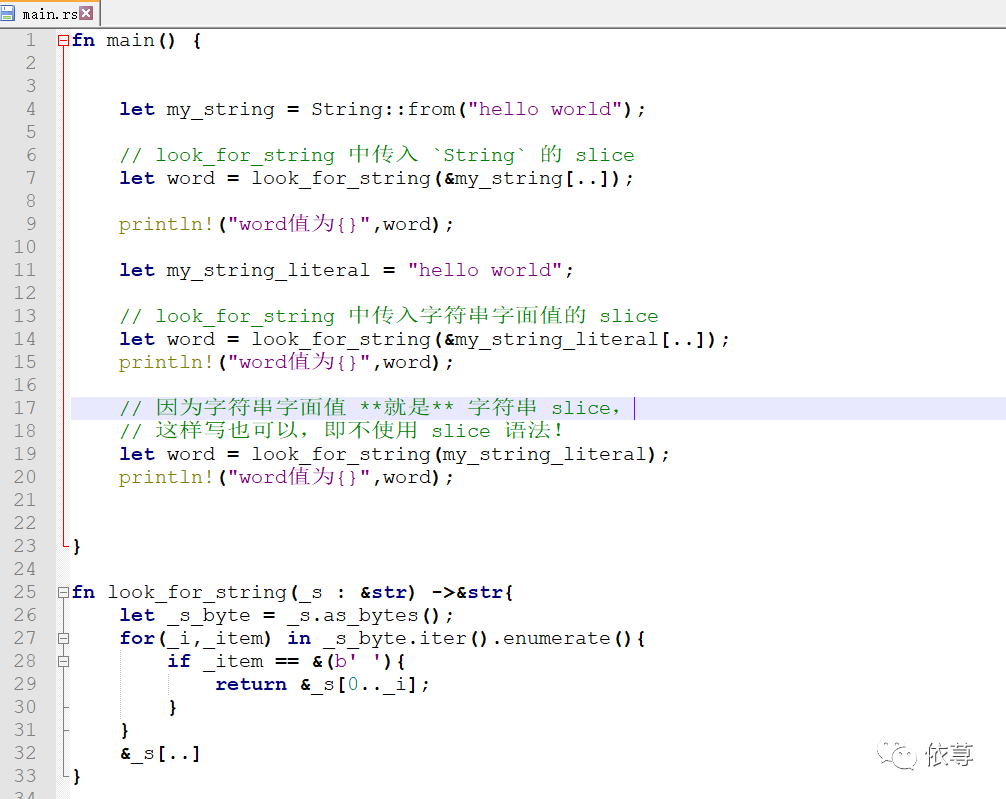
细心一点,可以发现一个问题:这里定义的时候,用的&s,即使用了s的引用,那么可以直接使用s的截取部分么?即:
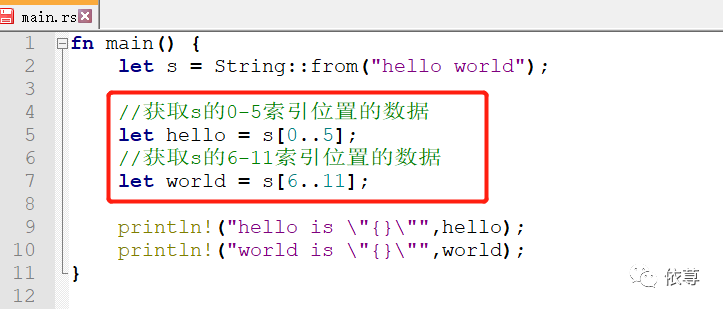
这里编译是会报错的:
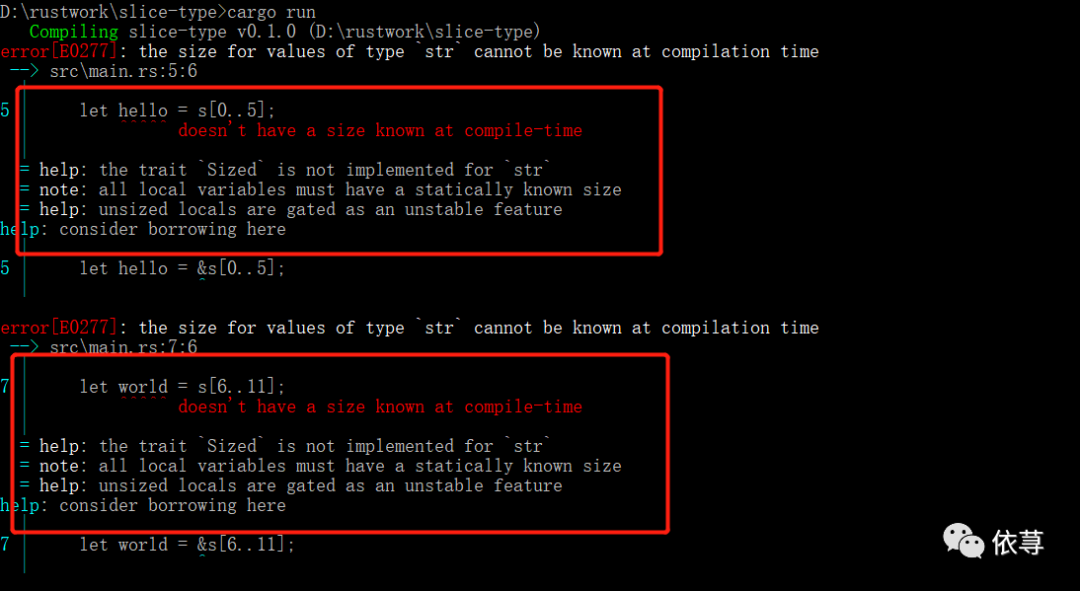
编译器说,在编译阶段,无法知道str类型的固定的长度
这里仿佛又获得一个新的东西,str
在Rust中,String类型具体分为两种,一个是未知长度的字符串类型String,一种是已知长度大小的str
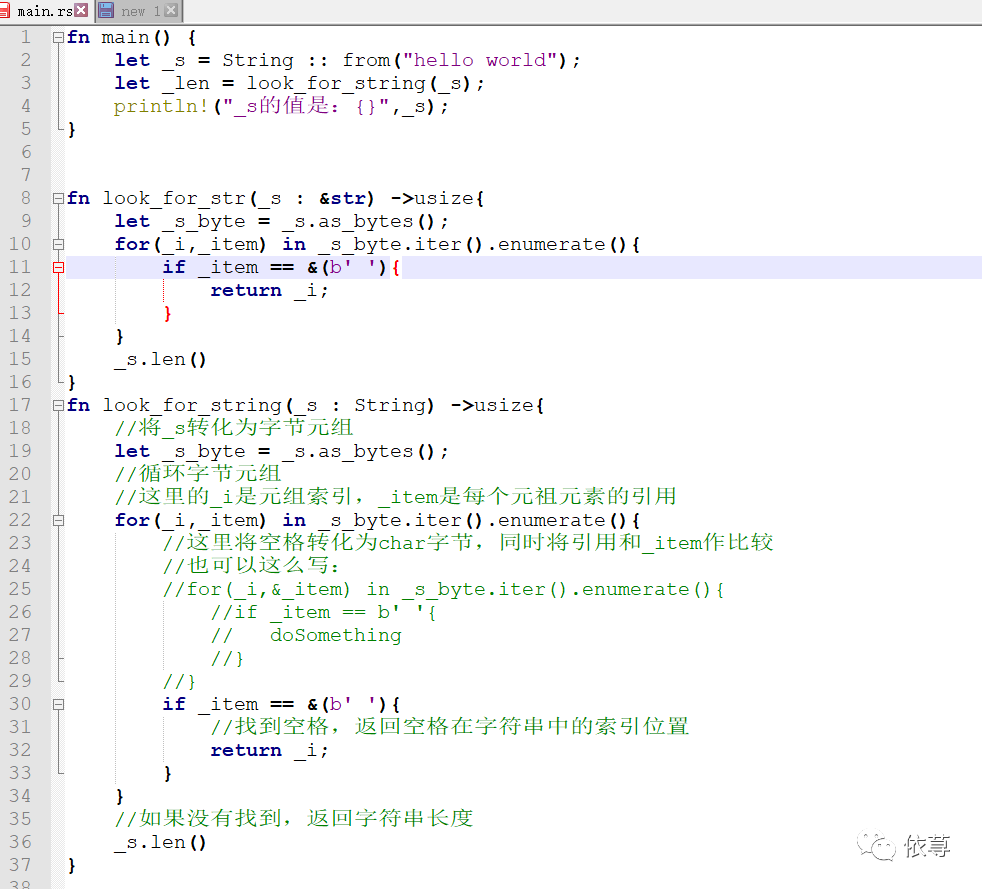
已知长度大小的字符串,其内存分配的时候,是在栈中保存的,所以不会存在移动,比如下面代码:
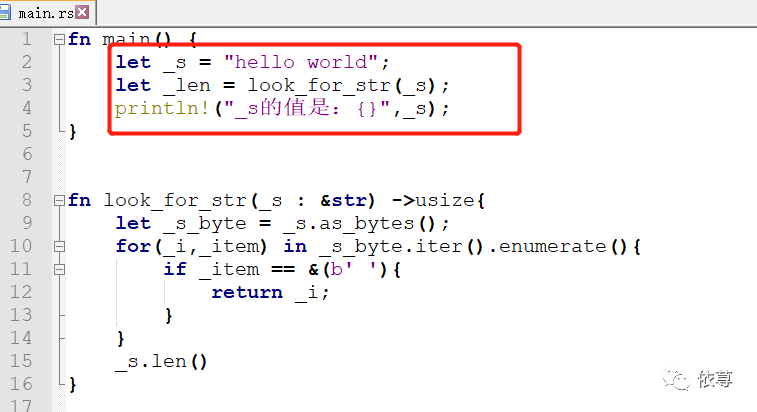
这里如果_是String类型的,在调用look_for_str函数之后,肯定会发生移动,所以,后面打印输出的时候,是一定会报错的,但是这里由于是栈中内存,可以视为和Rust基本类型一样,不会发生移动,而打印输出的时,并没有超出_s的作用域,所以,是没有问题的
编译运行:

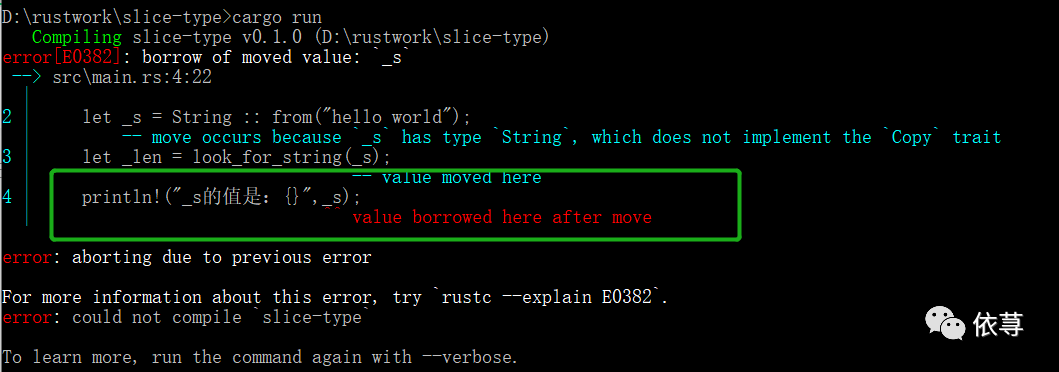
而这样是肯定会发生错误的:
编译报错:
所以,这里就比较容易的理解,刚刚定义slice类型时,为啥要使用引用?
因为如果不使用引用,那么定义的string类型是str的,str是需要固定大小的,然而本身_s并不是str,而是string类型,所以截取出来的_s部分也是一个string引用,并不是str
那么接下来,继续前面的内容,slice定义语法是
[starting_index..ending_index]
这里的starting_index是起始下标,
ending_index是结束下标,
两者是可以省略的,
[..ending_index]
等价于[0..ending_index]
[starting_index..]
等价于[starting_index..string.len()]
[..]
等价于[0..string.len()]
定义的slice是变量的引用对象的部分指向,内存并没有生成多余的空间来保存这个数据,比如前面的定义代码:
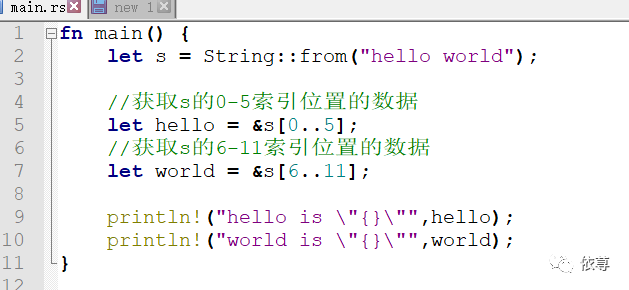
内存结构为:
注意,这里的索引截取,必须位于有效的UTF-8字符边界内,如果是从一个多字节字符的中间位置截取,这里是不允许的,比如:
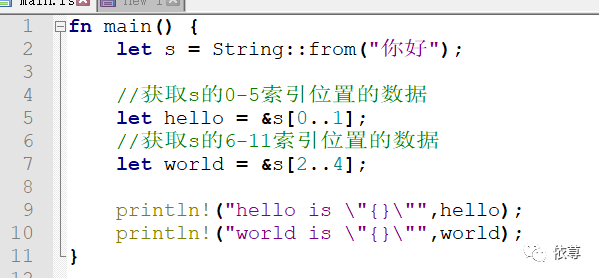
编译报错:

这个时候,只能这样:
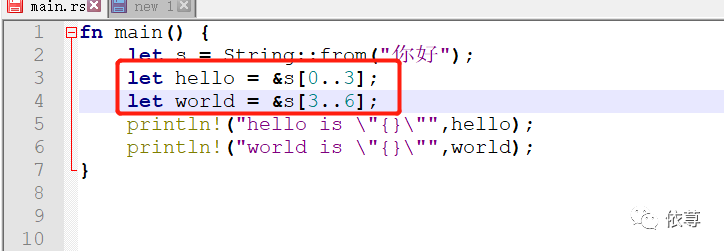
编译运行:
在有了这些基本语法之后,再来看看前面那个截取字符串的功能:
这里合理的截取到了需要的部分:

此时,如果在调用打印输出前,将_s清空,则编译报错,此时,可以有效的帮助我们发现,如果这样做,那么_p将变得毫无意义:
即:
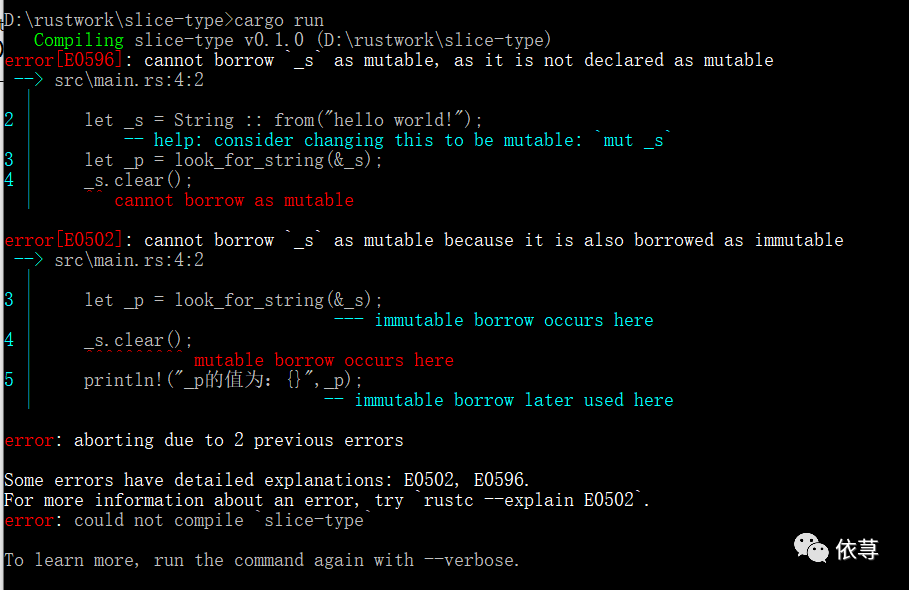
编译报错:
此外,还可以将slice当做参数传入函数中:
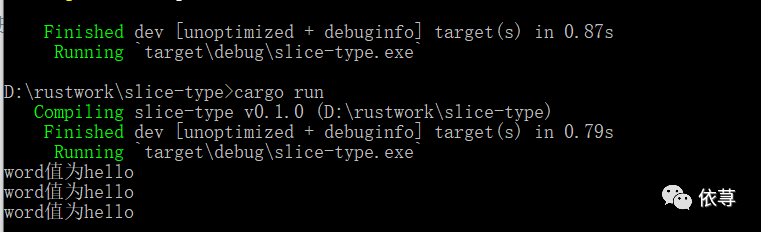
编译运行:
关于Rust语言的一些特性,就先到这儿了,主要需要多多自己写代码,然后去理解下。后续将分享实体结构相关
喜欢的欢迎关注转发,谢谢
点个再看和赞咯,(#^.^#)