
MySQL表删除数据,索引文件会不会变小?
本文公众号来源:微观技术
作者:Tom哥
“大家好,我是3y。今天给大家分享下MySQL的一些小知识。
“以前在公司的时候提交申请修改表结构工单执行DDL(比如增加一个列),DBA都会问下表现在的数据量有多少,会不会影响到业务。
原来这跟DDL的原理有关阿(关键字:Online DDL)。
如果我要新增一个列:那需要新增一张表,然后将主表的数据导到新表中,等完成后再rename...如果数据量大,还需要考虑主从延迟的问题。
这篇文章又让我了解到:原来删除数据,表的空间是不会释放的...
一张千万级的数据表,删除了一半的数据,你觉得B+树索引文件会不会变小?
我们先来做个实验,看看表的大小是如何变化的??
做个实验,让数据说话
1、首先,在mysql中创建一张用户表,表结构如下:
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用户名',
`age` int(11) NOT NULL COMMENT '年龄',
`address` varchar(128) COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
2、造数据。用户表中批量插入1000W条数据
@GetMapping("/insert_batch")
public Object insertBatch(@RequestParam("batch") int batch) {
// 设置批次batch=100000,共插入 1000W 条数据
for (int j = 1; j <= batch; j++) {
List<User> userList = new ArrayList<>();
for (int i = 1; i <= 100; i++) {
User user = User.builder().userName("Tom哥-" + ((j - 1) * 100 + i)).age(29).address("上海").build();
userList.add(user);
}
userMapper.insertBatch(userList);
}
return "success";
}
批量插入,每个批次100条记录,100000个批次,共1000W条数据

3、查看表文件大小

索引文件大小约 595 M,最后修改时间 02:17
说明:
MySQL 8.0 版本以前,表结构是存在以 .frm为后缀的文件里独享表空间存储方式使用 .ibd文件来存放数据和索引,且每个表一个.ibd文件
表数据既可以存在共享表空间,也可以是单独文件。通过innodb_file_per_table参数控制。MySQL 5.6.6 版本之后,默认是ON,这样,每个 InnoDB 表数据存储在一个以 .ibd为后缀的文件中。
4、删除 约500W条数据
@GetMapping("/delete_batch")
public Object deleteBatch(@RequestParam("batch") int batch) {
for (int j = 1; j <= batch; j++) {
List<Long> idList = new ArrayList<>();
for (int i = 1; i <= 100; i += 2) {
idList.add((long) ((j - 1) * 100 + i));
}
userMapper.deleteUser(idList);
}
return "success";
}
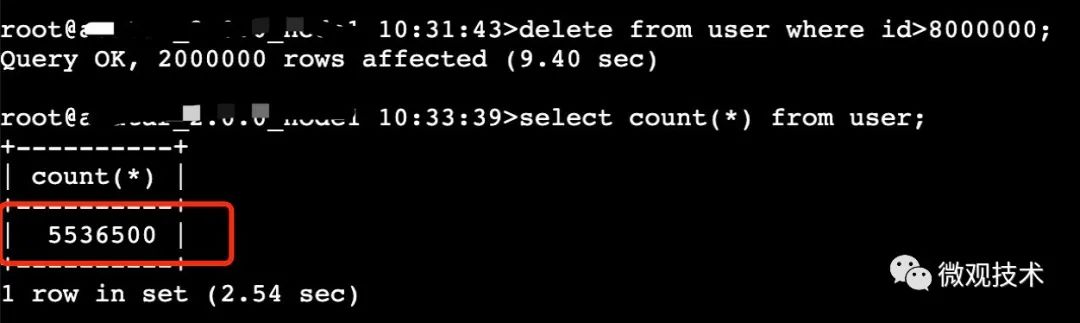
开始时user表有1000W条数据,删除若干后,目前剩余约 550W 条
5、在删除约500W条记录后,再次查看表文件大小

索引文件大小约 595 M,最后修改时间 10:34
实验结论:
对于千万级的表数据存储,删除大量记录后,表文件大小并没有随之变小。好奇怪,是什么原因导致的?不要着急,接下来,我们来深入剖析其中原因

数据表操作有新增、删除、修改、查询,其中查询属于读操作,并不会修改文件内容。修改文件内容的是写操作,具体分为有删除、新增、修改三种类型。
接下来,我们开始逐一分析
删除数据
InnoDB 中的数据采用B+树来组织结构。如果对B+树存储结构不清楚的话,可以先看下我之前写的一篇文章,巩固下基础知识。
假如表中已经插入若干条记录,构造的B+树结构如下图所示:

删除id=7这条记录,InnoDB引擎只是把id=7这条记录标记为删除,但是空间保留。如果后面有id位于(6,19)区间内的数据插入时,可以重复使用这个空间。
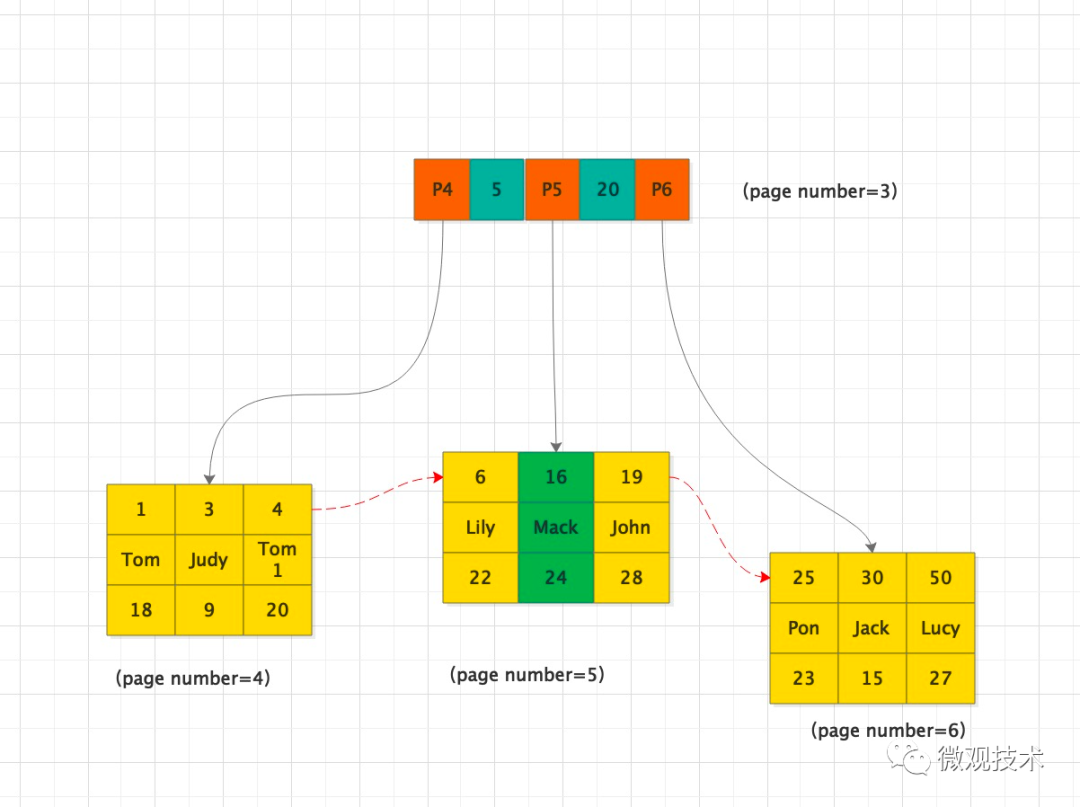
上图,表示新插入一条id=16的记录。
除了记录可以复用外,数据页也可以复用。当整个页从B+树摘掉后,可以复用到任何位置。
比如,将page number=5页上的所有记录删除以后,该page标记为可复用。此时如果插入一条id=100的记录需要使用新页,此时page number=5便可以被复用了。
如果相邻两个page的利用率都很低,数据库会将两个页的数据合并到其中一个page上,另一个page被标记为可复用。
当然,如果是像上面我们做的实验那样,将整个表的数据全部delete掉呢?所有的数据页都会被标记为可复用,但空间并没有释放,所以表文件大小依然没有改变。
总结:delete命令只是把数据页或记录位置标记为可复用,表空间并没有被回收,该现象我们称之为”空洞“
新增数据
如果是插入的数据是随机的非主键有序,可能会造成数据页分裂。
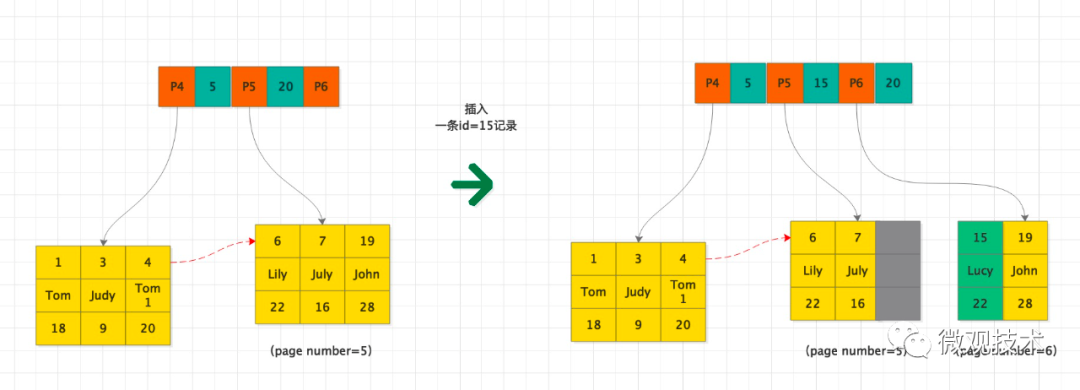
上图可以看到,假如page number=5的数据页已经满了,此时插入id=15的记录,需要申请一个新的页page number=6来保存数据。待页分裂完成后,page number=5的最后位置就会留下一个可复用的空洞。
相反,如果数据是按照索引递增顺序插入的,那么索引是紧凑的,不会出现数据页分裂。
修改数据
如果修改的是非索引值,那么并不会影响B+树的结构

比如,更新id=7的其它字段值,主键id保持不变。整个B+树并没有发生结构调整。
但是,如果修改的内容包含了索引,那么操作步骤是先删除一个旧的值,然后再插入一个新值。可能会造成空洞。
分析发现,新增、修改、删除数据,都可能造成表空洞,那么有没有什么办法压缩表空间??

客官,请继续往下看
新建表
我们可以新建一个影子表B与原表A的结构一致,然后按主键id由小到大,把数据从表A迁移到表B。由于表B是新表,并不会有空洞,数据页的利用率更高。
待表A的数据全部迁移完成后,再用表B替换表A。
MySQL 5.5 版本之前,提供了一键命令,快捷式完成整个流程,转存数据、交换表名、删除旧表。
alter table 表名 engine=InnoDB
但是,该方案有个致命缺点,表重构过程中,如果有新的数据写入表A时,不会被迁移,会造成数据丢失。
Online DDL
为了解决上面问题,MySQL 5.6 版本开始引入 Online DDL,对流程做了优化。
执行步骤:
新建一个临时文件 扫描表A主键的所有数据页,生成B+ 树,存储到临时文件中 在生成临时文件过程中,如果有对表A做写操作,操作会记录到一个日志文件中 当临时文件生成后,再重放日志文件,将操作应用到临时文件 用临时文件替换表A的数据文件 删除旧的表A数据文件
与新建表的最大区别,增加了日志文件记录和重放功能。迁移过程中,允许对表A做增删改操作。
“我是3y,我们下期再见吧。
卷王之卷的《对线面试官》系列目前已经连载24篇啦!每周更新两篇,首发公众号【面试造火箭】,欢迎持续关注:
【对线面试官】Java注解 【对线面试官】Java泛型 【对线面试官】 Java NIO 【对线面试官】Java反射 && 动态代理 【对线面试官】多线程基础 【对线面试官】 CAS 【对线面试官】synchronized 【对线面试官】AQS&&ReentrantLock 【对线面试官】线程池 【对线面试官】ThreadLocal 【对线面试官】CountDownLatch和CyclicBarrier 【对线面试官】List 【对线面试官】Map 【对线面试官】SpringMVC 【对线面试官】Spring基础 【对线面试官】SpringBean生命周期 【对线面试官】Redis基础 【对线面试官】Redis持久化 【对线面试官】Kafka基础 【对线面试官】使用Kafka会考虑什么问题? 【对线面试官】MySQL索引 【对线面试官】MySQL 事务&&锁机制&&MVCC
