
翻车了,被读者找出 BUG
大家好呀,我是小楼。
本文是上篇文章《使用增强版 singleflight 合并事件推送,效果炸裂!》的续集,没看过前文必须要先看完才能看本文,实在不想看,拉到文章末尾,给我点个赞再退出吧~Doge
上篇文章发出后,有一位读者朋友给我发私信,写了一大段话:
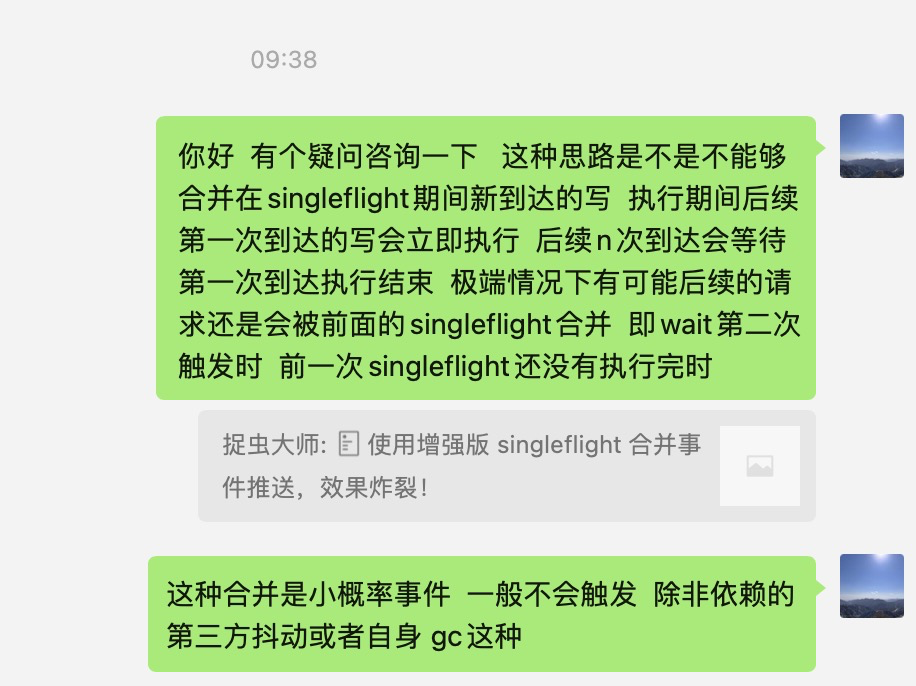
一开始,没太看懂,于是就细问了一下
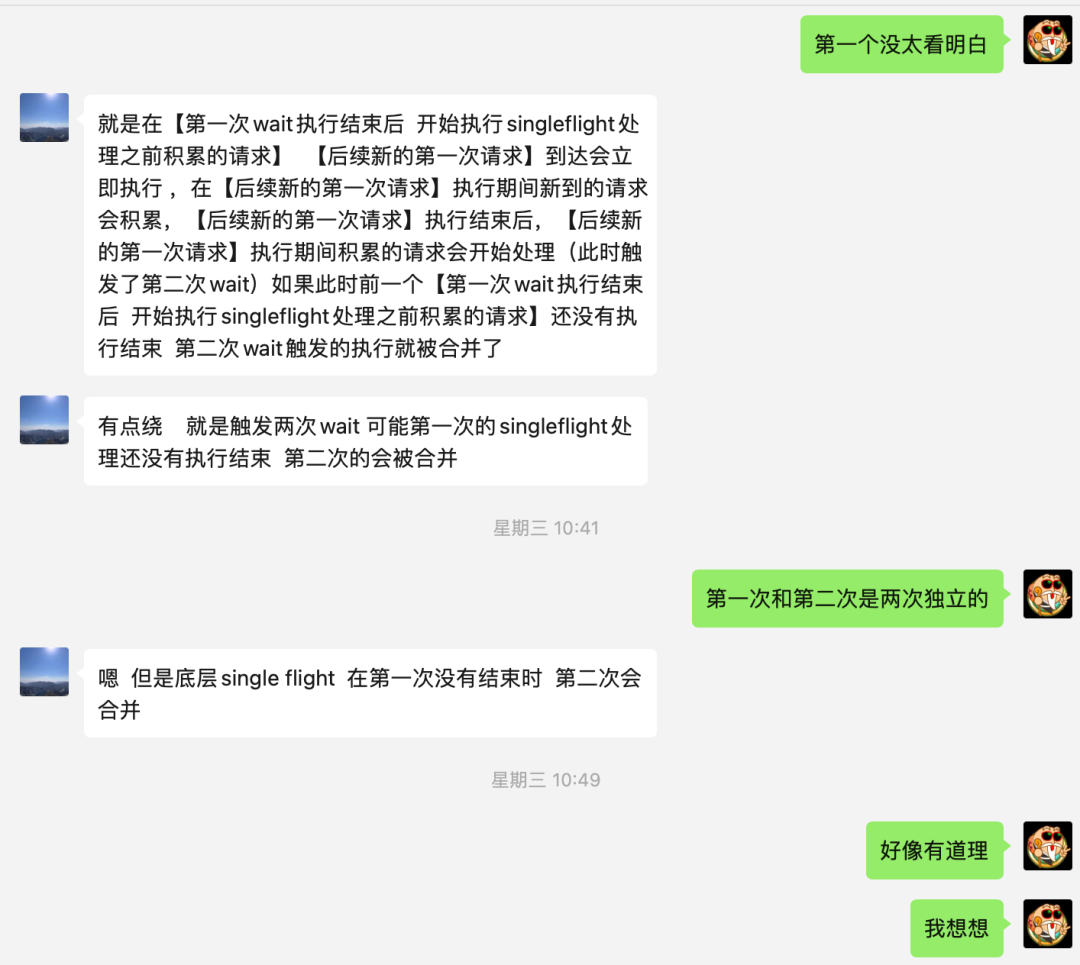
在看了解释之后,感觉好像有点懂了,再三思考后,确认了,这里面有 BUG。
理想状态
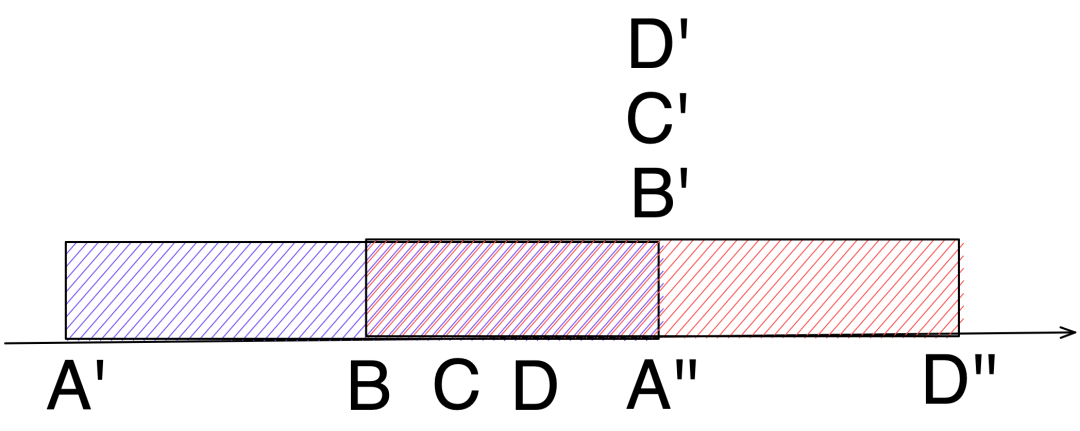
为了描述简单,这里我用字母本身表示事件发生,如
A
,用字母加一撇表示事件开始执行,如
A'
,用字母加两撇表示事件执行结束后的状态,如
D''
。
如下表示我们之前思考的理想状态:A 事件到来便执行,在执行结束前又先后来了 B、C、D 三个事件,先 Hold 住,待 A 执行完成后,B、C、D 同时进入 sigleflight group 中抢执行,最终结果是 D'',感觉非常完美。
对应到代码上是这样:
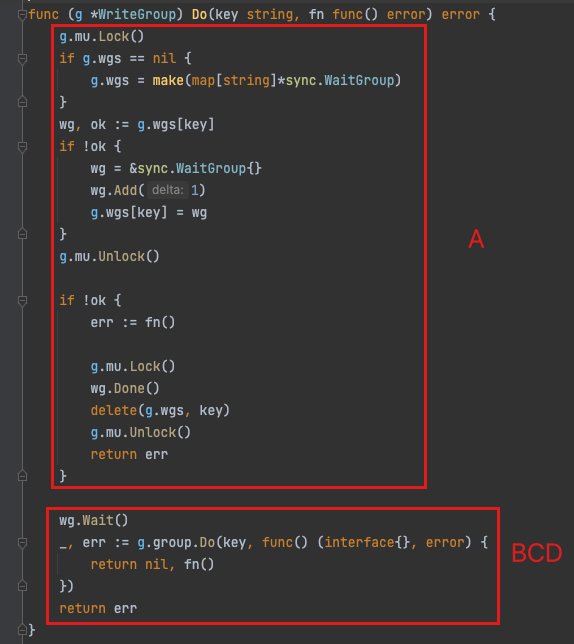
case 1
但这位读者提出了一个疑问,如果在 B、C、D 执行的时候又来一个 E 事件,那这个 E 事件将会重走 A 事件的路,如果这个 E 事件执行的比较快,先于 B、C、D 事件完成,那不就有问题了?
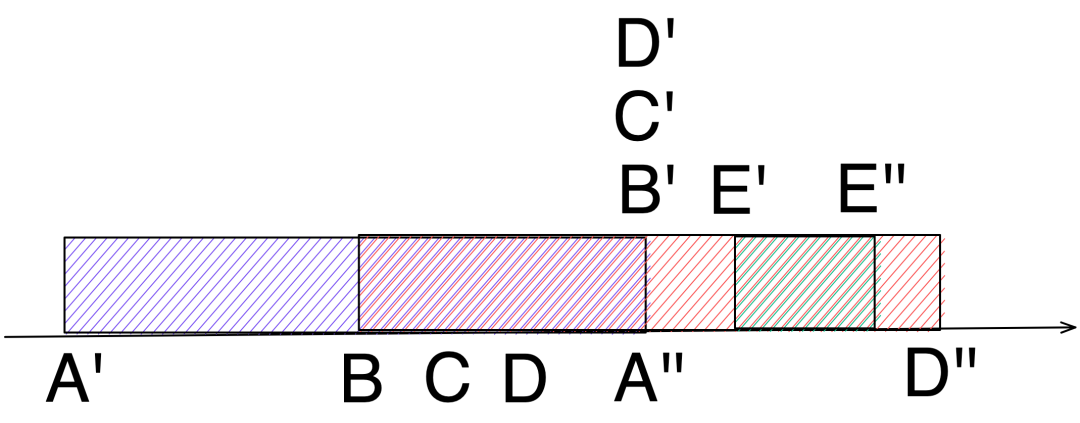
E 事件最后到,我们期望的结果应该是 E'',但按这个推理,最终结果是 D'',显然不符合预期。
case 2
同理,如果在 E 事件执行期间累积了 F、G 事件,且 F、G 也比较争气,在 B、C、D 完成之前完成了:
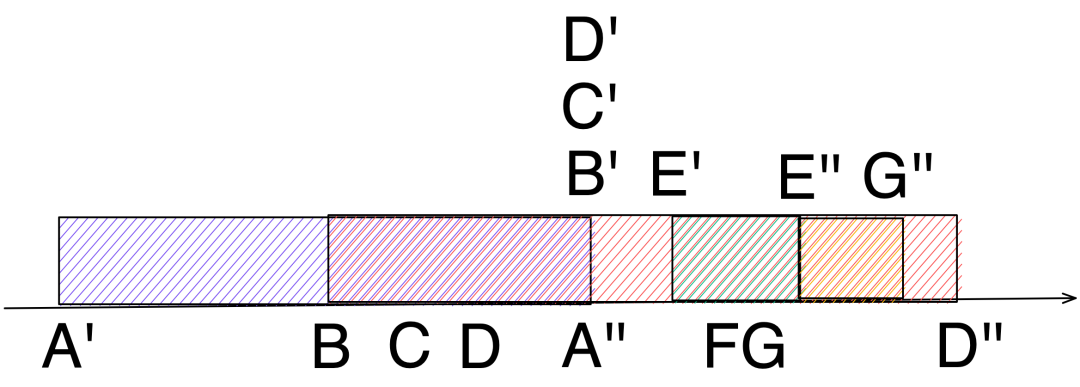
期望的是 G'',但最终结果是 D''。
线上有问题吗?
这两个场景确实很难测试到,如果不幸遇到,还是有风险的。我们复盘了自己的系统,发现我们的系统是可以解这个问题的。
我们的系统会针对推送下去不一致的数据进行定期补偿,具体怎么做的呢?
在推送之前,针对同一种推送,也就是相同的 key 生成(存在则更新)同一条记录,该记录包含两个时间 t1、t2,推送的开始时间 tn(精确到纳秒)记录到 t1,推送完成后将 tn 记录到 t2,这两次记录在一个方法中,伪代码是这样:
tn := time.Now().UnixNano()
markT1(key, tn)
push(key)
markT2(key, tn)
如果 t1 = t2 则说明推送没有问题,如果 t1 != t2 则说明这条推送需要补偿,每 10s 扫描一次需要补偿的事件进行重新下发推送
我们以 case 1 为例,按照时间顺序
A 执行完成时,t1= ta,t2 = ta
D 开始执行,t1 = td
E 开始执行,t1 = te,E 执行结束 t2 = te
D 执行结束,t1 = te,t2 = td
10 s 后发现 t1 != t2,于是触发重新下发逻辑,重新推送最新数据为 E''
最后
还好我们线上系统有一层保护机制,否则可能要出事。如果在 singleflight 层面去解决这个问题,暂时我还没有想到很好的办法,如果读者朋友们有好的方法,欢迎私信我。
不得不说读者朋友们当中还是有不少读了我的文章,而且认真思考了的,在此表示感谢,也欢迎大家指出文章中的错误。
最后感谢能抽空看到这里,如果你能点赞、在看、分享,我会更加感激不尽~
搜索关注微信公众号"捉虫大师",后端技术分享,架构设计、性能优化、源码阅读、问题排查、踩坑实践
进技术交流群加微信 MrRoshi