
springboot第58集:Dubbo万字挑战,一文让你走出微服务迷雾架构周刊
单点登录(Single Sign-On,SSO)是一种身份验证机制,允许用户在多个应用程序或系统中使用单一的登录凭证(例如用户名和密码)进行身份验证,并且在成功登录后,可以访问所有已经授权的应用程序,而无需重新进行身份验证。
原理:
- 用户访问应用程序A并进行登录。
- 应用程序A将用户的登录凭证发送到认证中心进行验证。
- 认证中心验证用户的身份,并生成一个令牌(Token)。
- 应用程序A将令牌返回给用户。
- 用户访问其他应用程序B,并在请求中携带之前获得的令牌。
- 应用程序B将令牌发送到认证中心进行验证。
- 认证中心验证令牌的有效性,并返回用户信息给应用程序B。
- 应用程序B根据认证中心返回的用户信息,完成用户的登录过程。
实现方式:
- Cookie-Based SSO:利用浏览器的 Cookie 实现跨域共享用户登录状态。当用户登录成功后,认证中心在用户的浏览器中设置一个包含用户身份信息的 Cookie,其他应用程序在同一域名下可以读取该 Cookie,从而实现单点登录。
- Token-Based SSO:采用令牌机制,认证中心颁发一个令牌给用户,其他应用程序在需要验证用户身份时,向认证中心发送令牌进行验证。常见的实现方式包括 JWT(JSON Web Token)和 OAuth2.0 等。
同域名下的单点登录: 在同一域名下实现单点登录较为简单,可以直接通过 Cookie 或者 Session 实现。当用户登录成功后,认证中心在用户浏览器中设置一个 Cookie,其他应用程序可以通过读取该 Cookie 来验证用户的身份。
不同域名下的单点登录: 在不同域名下实现单点登录需要采用跨域认证技术,常见的方式包括:
- 跨域设置 Cookie:在主域名下设置 Cookie,并通过设置子域名共享 Cookie。例如,将 Cookie 的域名设置为主域名,子域名下的应用程序可以共享该 Cookie,从而实现跨域的单点登录。
- 使用 Token:采用 Token-Based SSO 的方式,通过认证中心颁发的令牌来实现跨域的单点登录,各个子域名下的应用程序共享同一个认证中心。
- 使用代理方式:将所有的应用程序都通过一个代理服务器进行访问,代理服务器在用户登录成功后,负责将用户信息传递给其他应用程序。
设计一个秒杀系统需要考虑多个方面,包括前端设计、后端设计、数据库设计、缓存设计、限流与熔断、消息队列等。下面是一个针对双11秒杀场景的秒杀系统的整体解决方案:
-
前端设计方案:
- 采用前端页面静态化技术,尽量减少页面的动态请求。
- 使用 CDN 加速,减轻服务器压力。
- 前端页面实现简单、快速响应,减少页面元素加载时间,提高用户体验。
后端设计方案:
- 使用分布式架构,将负载分散到多个服务器上,提高系统的并发处理能力。
- 使用微服务架构,将不同的业务模块拆分成独立的服务,提高系统的灵活性和可维护性。
- 使用缓存技术,将热门数据缓存到内存中,减少数据库的访问压力。
- 使用限流与熔断机制,限制用户的请求频率,避免系统过载崩溃。
- 使用消息队列,将请求异步化处理,降低系统的响应时间。
数据库层解决方案:
- 使用高性能的数据库,如 MySQL、Redis 等。
- 使用数据库集群和读写分离技术,提高数据库的读写性能和扩展能力。
- 使用数据库连接池,避免频繁地创建和关闭数据库连接,提高数据库的并发处理能力。
- 使用分库分表技术,将数据水平切分到多个数据库或表中,提高数据库的读写性能。
整体解决方案:
- 提前做好系统的容量规划和压力测试,确保系统能够承受大规模并发访问。
- 针对核心业务流程进行优化,如减少锁粒度、减少数据库查询次数、合并数据库操作等。
- 使用分布式缓存来缓存热门数据,减少数据库的访问压力。
- 使用分布式锁来控制对共享资源的访问,避免出现超卖和重复购买的情况。
- 使用异步处理技术,将秒杀请求异步化处理,提高系统的并发处理能力。
Apache RocketMQ 是一个开源的分布式消息中间件,具有高性能、高可靠性、高吞吐量、低延迟等特点。其核心组件、架构设计、特性以及应用场景如下:
-
核心组件:
- NameServer:用于管理整个 RocketMQ 集群的路由信息,负责提供 Topic 的路由查询服务。
- Broker:消息存储和消息服务的核心组件,负责消息的存储、传输和服务端的处理。
- Producer:消息生产者,负责将消息发送到 Broker。
- Consumer:消息消费者,负责从 Broker 拉取消息并进行处理。
- Topic:消息的逻辑分类,消息按照 Topic 进行存储和订阅。
架构设计:
- RocketMQ 的架构设计采用了分布式的 Broker 集群架构,Producer 和 Consumer 通过 NameServer 发现 Broker,实现了消息的发布与订阅。
- Broker 集群中的每个 Broker 都会存储一部分消息数据,并且消息数据会进行主从同步以及多个 Slave 副本备份,以保证数据的可靠性和高可用性。
特性:
- 高可靠性:RocketMQ 支持主从同步和多副本备份机制,保证消息数据的可靠性和高可用性。
- 高吞吐量:RocketMQ 使用了优化的消息存储和传输机制,实现了高性能的消息存储和传输,支持大规模消息的并发处理。
- 低延迟:RocketMQ 的消息存储和传输机制经过优化,实现了低延迟的消息处理,适用于对延迟要求较高的场景。
- 水平扩展:RocketMQ 支持水平扩展,可以通过增加 Broker 节点来实现集群的扩展,以支持更大规模的消息处理。
应用场景:
- 日志收集与存储:RocketMQ 可以作为日志收集和存储的中间件,用于收集分布式系统产生的日志数据,并将数据持久化存储到 Broker 中。
- 异步消息处理:RocketMQ 支持异步消息处理模式,可以用于解耦复杂系统中的不同模块,提高系统的可伸缩性和性能。
- 实时数据分析:RocketMQ 支持高吞吐量和低延迟的消息传输,适用于实时数据分析和流式计算场景。
- 事务消息:RocketMQ 提供了事务消息的支持,可以保证消息的可靠投递和事务的一致性,适用于分布式事务处理场景。
综上所述,RocketMQ 是一个功能丰富、性能优异的分布式消息中间件,适用于多种不同的应用场景,包括日志收集、异步消息处理、实时数据分析以及事务消息处理等。
Kafka 是一个分布式流处理平台,它具有高吞吐量、持久性、水平可扩展性以及容错性等特点。Kafka 在设计和实现上采用了多种技术来提高性能和可靠性,包括页缓存技术、磁盘顺序写、零拷贝、分区分段、索引等。
-
页缓存技术:
- Kafka 使用操作系统的页缓存来缓存消息数据,以加快消息的读写速度。通过将热点数据保留在内存中,可以减少磁盘 IO 操作,提高消息的读写性能。
磁盘顺序写:
- Kafka 通过将消息追加写入到日志文件(Log Segment)中,并利用磁盘的顺序写入特性,以实现高效的持久化存储。顺序写可以降低磁盘的寻址时间和旋转延迟,提高写入性能。
零拷贝:
- Kafka 使用零拷贝技术来提高消息的传输效率。在 Kafka 的生产者和消费者之间,消息可以直接在内核态和用户态之间进行传输,而无需在中间进行额外的数据拷贝,减少了 CPU 和内存的消耗,提高了数据传输的效率。
分区分段:
- Kafka 中的每个主题(Topic)可以分成多个分区(Partition),每个分区可以看作是一个有序且不可变的消息队列。每个分区又可以细分为多个 Log Segment,用于存储消息数据。这种分区分段的设计可以提高消息的并发处理能力,减少竞争,并且支持更大的数据量和更高的吞吐量。
索引:
- 在每个 Log Segment 中,Kafka 会维护一个索引文件(Index File),用于快速定位消息的位置。通过索引文件,Kafka 可以在读取消息时快速定位到指定消息的偏移量,而无需遍历整个日志文件,大大提高了消息的读取速度。
这些技术的结合,使得 Kafka 能够实现高性能、高可靠性的分布式消息系统,广泛应用于日志收集、事件处理、流式计算等场景中。
RocketMQ的架构是参考kafka来实现的,在互联网领域特别是金融,用的很多。
负载均衡(Load Balancing)是指将请求分发到多个服务器上,以达到平衡服务器负载、提高系统性能、增加系统可用性的目的。下面是几种常见的负载均衡算法及其原理机制:
-
轮询(Round Robin) :
- 原理:轮询算法会按照请求的顺序将请求依次分配给后端的服务器,每个请求都按照顺序选取下一个服务器。
- 特点:简单、均匀地分发请求,适用于后端服务器性能相近的情况。
加权轮询(Weighted Round Robin) :
- 原理:加权轮询算法在轮询算法的基础上引入了权重的概念,根据服务器的权重来决定分配请求的比例。
- 特点:可以根据服务器的性能或者负载情况动态地分配请求,提高整体系统的性能。
源地址散列(Source IP Hash) :
- 原理:源地址散列算法会根据请求的源IP地址计算哈希值,然后将哈希值映射到后端服务器。
- 特点:相同的源IP地址会被分配到同一个后端服务器上,可以保证相同客户端的请求都会被分发到同一台服务器上,适用于有状态的会话保持场景。
最小连接数(Least Connections) :
- 原理:最小连接数算法会统计后端服务器当前的连接数,每次选择连接数最少的服务器来处理请求。
- 特点:根据服务器的负载情况动态地分配请求,使得连接数相对均衡,适用于长连接的场景。
随机(Random) :
- 原理:随机算法会随机选择一个后端服务器来处理请求。
- 特点:简单快速,适用于后端服务器性能相近的情况,但不适用于有状态的会话保持场景。
这些负载均衡算法各有特点,可以根据实际业务场景和需求选择合适的算法。在实际应用中,也可以根据实际情况进行算法的定制和优化,以满足特定的需求。
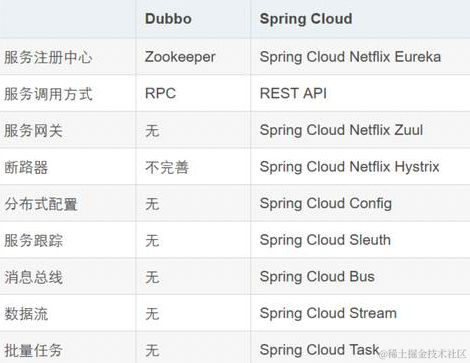 image.png
image.pngDubbo集群提供了哪些负载均衡策略?
Random LoadBalance: 随机选取提供者策略,有利于动态调整提供者权重。
RoundRobin LoadBalance:轮询选取提供者策略,平均分布,但是存在请求累积的问题。
LeastActive LoadBalance:最少活跃调用策略,解决慢提供者接收更少的请求;
ConstantHash LoadBalance:一致性Hash策略,使相同参数请求总是发到同一提供者,一台机器宕机,可以基于虚拟节点,分摊至其他提供者,避免引起提供者的剧烈变动;
缺省时为Random随机调用
Dubbo使用的是什么通信框架?默认使用NIO Netty框架
Dubbo与Spring的关系?Dubbo采用全Spring配置方式,透明化接入应用,对应用没有任何API侵入,只需用Spring加载Dubbo的配置即可,Dubbo基于Spring的Schema扩展进行加载
Dubbo的注册中心集群挂掉,发布者和订阅者之间还能通信么?可以的,启动dubbo时,消费者会从zookeeper拉取注册的生产者的地址接口等数据,缓存在本地。每次调用时,按照本地存储的地址进行调用。
Dubbo的架构设计:
- Service
- Config
- Proxy
- Registry
- Cluster
- Monitor
- Protocol
- Exchange
- Transport
- Serialize
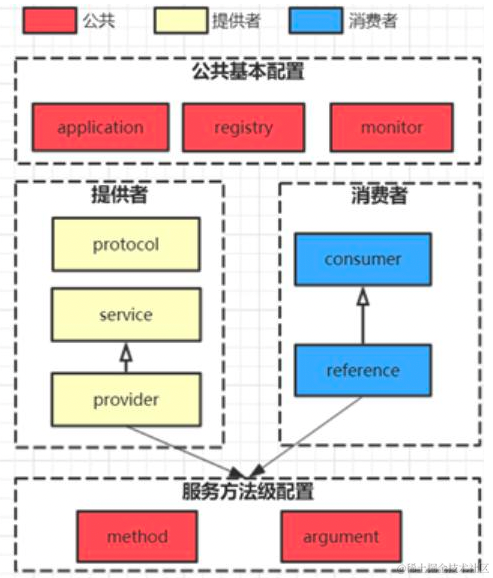 image.png
image.pngDubbo的核心组件:
Provider:暴露服务的服务提供方
Consumer:调用远程服务的服务消费方
Registry:服务注册与发现的注册中心
Monitor:统计服务的调用次调和调用时间的监控中心
Container:服务运行容器
Dubbo的场景:透明化的远程方法调用,就像调用本地方法一样调用远程方法,只需简单配置,没有任何API侵入。软负载均衡以及容错机制,可在内网替代F5等硬件负载均衡器,降低成本,减少单点。
Dubbo的由来:
单一应用架构:单体应用框架,将所有功能都部署在一起即可。
垂直应用架构:当访问量逐渐增加,单一应用按照有业务线拆成多个应用,提高效率。
分布式服务架构:分布式服务框架(RPC)
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需要增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
资源调度和治理中心
Dubbo 是一个高性能的分布式服务框架,它主要解决了分布式系统中服务之间的远程调用问题。下面是 Dubbo 的一些优化内容和简要原理介绍:
- 通信协议优化: Dubbo 支持多种通信协议,如 Dubbo 协议、HTTP 协议、Hessian 协议等。不同的协议适用于不同的场景,比如 Dubbo 协议是 Dubbo 的默认协议,提供了较高的性能和可靠性,适合在高性能要求的内部服务调用中使用;而 HTTP 协议则更适用于跨语言、跨平台的服务调用。
- 序列化优化: Dubbo 支持多种序列化方式,如 Hessian、JSON、Protobuf 等。序列化是将对象转换为字节流的过程,在 Dubbo 中使用高效的序列化方式可以减少数据传输的大小,提高性能。
- 负载均衡优化: Dubbo 提供了多种负载均衡策略,如随机、轮询、一致性哈希等。负载均衡策略决定了请求会被分发到哪个服务节点上,合理选择负载均衡策略可以避免服务节点的负载不均衡,提高系统的整体性能和稳定性。
- 集群容错优化: Dubbo 提供了多种集群容错机制,如失败自动切换、失败快速失败、失败安全等。集群容错机制用于处理服务调用过程中可能出现的异常情况,保证服务调用的可靠性和稳定性。
- 服务治理优化: Dubbo 提供了丰富的服务治理功能,如服务注册与发现、动态路由、服务降级、熔断限流等。这些功能可以帮助开发者更好地管理和监控分布式系统中的各个服务,保证系统的健壮性和可靠性。
示例原理介绍:
假设有一个电商系统,其中包含了商品服务和订单服务两个模块,商品服务提供了查询商品信息的接口,订单服务需要调用商品服务来获取商品信息。这时可以使用 Dubbo 来实现商品服务和订单服务之间的远程调用。
-
服务提供者(商品服务) :
- 商品服务提供者通过 Dubbo 暴露出查询商品信息的接口。
- Dubbo 会将该服务注册到注册中心(如 ZooKeeper)中,供其他服务消费。
服务消费者(订单服务) :
- 订单服务通过 Dubbo 引用商品服务提供的接口。
- Dubbo 会从注册中心中获取商品服务的地址列表,并根据负载均衡策略选择一个服务提供者。
- 订单服务调用选中的商品服务提供者,进行远程调用获取商品信息。
调用过程:
- 订单服务将查询商品信息的请求通过 Dubbo 进行序列化,并通过网络发送给选中的商品服务提供者。
- 商品服务提供者接收到请求后,通过 Dubbo 进行反序列化,并调用商品服务中对应的方法来处理请求。
- 商品服务提供者将处理结果通过 Dubbo 进行序列化,并通过网络发送给订单服务消费者。
- 订单服务消费者接收到响应后,通过 Dubbo 进行反序列化,并得到最终的查询结果。
通过 Dubbo,服务提供者和服务消费者之间的远程调用过程变得简单透明,开发者无需关心底层的通信细节,只需要关注业务逻辑的实现即可。Dubbo 的优化内容和灵活的配置使得它成为构建高性能、可靠的分布式系统的理想选择。
 image.png
image.pngSpringBoot使用validator校验
@NotEmpty(message="用户名不能为空")
@Length(min=6,max = 12,message="用户名长度必须位于6到12之间")
@NotEmpty(message="密码不能为空")
@Length(min=6,message="密码长度不能小于6位")
@Email(message="请输入正确的邮箱")
@Pattern(regexp = "^(\\d{18,18}|\\d{15,15}|(\\d{17,17}[x|X]))$", message = "身份证格式错误")
使用 Docker 部署一个 Cassandra 的集群环境。
version: '3'
services:
cassandra-1:
image: cassandra:3.11.7
container_name: cassandra-1
volumes:
- /opt/module/docker-compose/cassandra.yaml:/opt/cassandra/conf/cassandra.yaml
- /data/cassandra-cluster/cassandra-1/cassandra:/var/lib/cassandra
environment:
- CASSANDRA_BROADCAST_ADDRESS=cassandra-1
ports:
- "7000:7000"
- "9042:9042"
restart: always
cassandra-2:
image: cassandra:3.11.7
container_name: cassandra-2
volumes:
- /opt/module/docker-compose/cassandra.yaml:/opt/cassandra/conf/cassandra.yaml
- /data/cassandra-cluster/cassandra-2/cassandra:/var/lib/cassandra
environment:
- CASSANDRA_BROADCAST_ADDRESS=cassandra-2
- CASSANDRA_SEEDS=cassandra-1
ports:
- "7001:7000"
- "9043:9042"
depends_on:
- cassandra-1
restart: always
cassandra-3:
image: cassandra:3.11.7
container_name: cassandra-3
volumes:
- /opt/module/docker-compose/cassandra.yaml:/opt/cassandra/conf/cassandra.yaml
- /data/cassandra-cluster/cassandra-3/cassandra:/var/lib/cassandra
environment:
- CASSANDRA_BROADCAST_ADDRESS=cassandra-3
- CASSANDRA_SEEDS=cassandra-1
ports:
- "7002:7000"
- "9044:9042"
depends_on:
- cassandra-2
restart: always
Matching Java Virtual Machines (6):
17.0.2 (x86_64) "Oracle Corporation" - "OpenJDK 17.0.2" /Users/jeskson/Library/Java/JavaVirtualMachines/openjdk-17.0.2/Contents/Home
11.0.18 (arm64) "Amazon.com Inc." - "Amazon Corretto 11" /Users/jeskson/Library/Java/JavaVirtualMachines/corretto-11.0.18/Contents/Home
1.8.0_392 (arm64) "Amazon" - "Amazon Corretto 8" /Users/jeskson/Library/Java/JavaVirtualMachines/corretto-1.8.0_392/Contents/Home
1.8.0_382 (arm64) "Amazon" - "Amazon Corretto 8" /Users/jeskson/Library/Java/JavaVirtualMachines/corretto-1.8.0_382/Contents/Home
1.8.0_372 (arm64) "Amazon" - "Amazon Corretto 8" /Users/jeskson/Library/Java/JavaVirtualMachines/corretto-1.8.0_372/Contents/Home
1.8.0_362 (arm64) "Amazon" - "Amazon Corretto 8" /Users/jeskson/Library/Java/JavaVirtualMachines/corretto-1.8.0_362/Contents/Home
/Users/jeskson/Library/Java/JavaVirtualMachines/openjdk-17.0.2/Contents/Home
./cqlsh
create keyspace devjavasource with replication={'class':'SimpleStrategy','replication_factor':1};
cqlsh> use devjavasource;
cqlsh> create table User(
id int primary key,
address text,
name text);
cqlsh> DESCRIBE KEYSPACES;
system system_distributed system_traces system_virtual_schema
system_auth system_schema system_views
cqlsh> CREATE KEYSPACE simple_crud
... WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
cqlsh> DESCRIBE KEYSPACES;
simple_crud system_auth system_schema system_views
system system_distributed system_traces system_virtual_schema
cqlsh>
docker run --name my-cassandra-container -d cassandra:latest
docker run --name my-cassandra-container -d -p 9042:9042 cassandra:latest
docker run --name my-cassandra-container -d -p 9042:9042 -v /path/to/local/dir:/var/lib/cassandra cassandra:latest
docker exec -it my-cassandra-container cqlsh
docker ps
Connected to **Test Cluster** at 127.0.0.1:9042
[cqlsh 6.1.0 | Cassandra 4.1.4 | CQL spec 3.4.6 | Native protocol v5]
Use HELP for help.
cqlsh> DESCRIBE KEYSPACES;
system system_distributed system_traces system_virtual_schema
system_auth system_schema system_views
 image.png
image.png image.png
image.png
isNaN(123); // false,数字
isNaN('123'); // false,字符串 '123' 可以转换为数字
isNaN('abc'); // true,字符串 'abc' 不能转换为数字
isNaN(true); // false,true 被转换为数字 1
isNaN(false); // false,false 被转换为数字 0
isNaN(null); // false,null 被转换为数字 0
isNaN(undefined); // true,undefined 不能转换为数字
加群联系作者vx:xiaoda0423
仓库地址:https://github.com/webVueBlog/JavaGuideInterview