来源:新智元
【导读】今天,ECCV 2022放榜了!今年论文总投稿数爆增到8000多篇,共有1629篇论文中选,录用率还不到20%。
知乎上已经有大佬们,热烈的讨论。不知道大家中了没?有位大佬投了两年,GitHub开源项目 攒了 2500 star,今年才终于中了,不容易呀https://www.zhihu.com/question/516128811
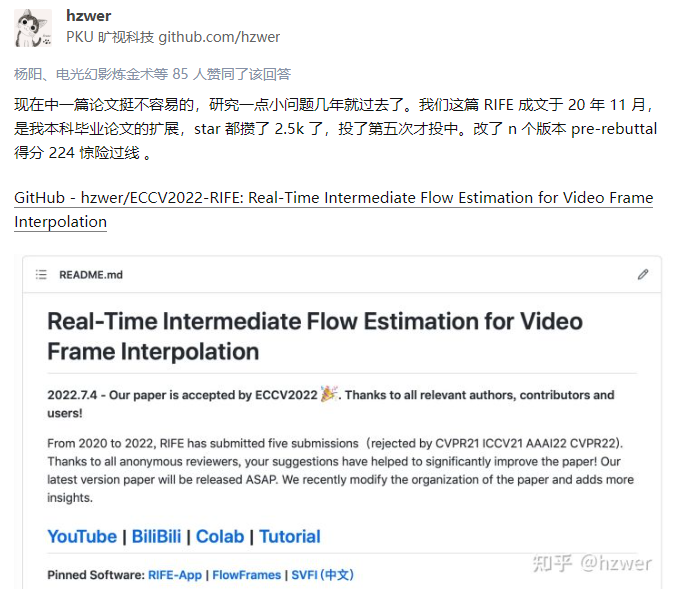
根据最新公开的论文录用列表,今年ECCV共接收了1629篇。今年的投稿理论上至少有8170篇(最后一个中稿ID),由此预估,录用率还不到20%。2020年ECCV共收到有效投稿5025篇,接收论文1361篇,接收率为27%。2018年共有2439篇投稿,接收776篇,录用率为31.8%。通过对比发现,ECCV 2022论文接收投稿数直接拉满,比2020年还要多大约3000多篇。而录用的论文这次比ECCV 20仅多出300多篇,很显然,中稿率下降也是情理之中。除了我们熟知的CVPR、ICCV,ECCV(欧洲计算机视觉国际会议)也是计算机视觉三大国际顶级会议之一,每两年召开一次。ECCV 2022 将在10月23日-27日的以色列特拉维夫(Tel-Aviv)举行。和刚刚过去的CVPR同样,这个会议也将采取线下和线上混合形式召开。ECCV 22论文录取列表刚刚公布不久,网友们早就迫不及待地晒出了自己成绩单。自己的1篇、2篇、3篇论文......都被ECCV接收了。自己的论文「RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation」终于被ECCV接收了。这篇论文曾被CVPR 2021、ICCV 2021、AAAI 2022,以及CVPR 2022连拒了4次,可见被顶会录用过程极其艰难。还有网友晒出,自己喜提reject,还将自己称为CV Reject的收割者。第一篇由罗切斯特理工学院(RIT)教授Dongfang Liu和普渡大学(Purdue)教授Xiangyu Zhang共同指导,普渡大学博士学生Zhiyuan Cheng为第一作者。这篇题为「Physical Attack on Monocular Depth Estimation in Autonomous Driving with Optimal Adversarial Patches」的论文,最为突出的一点在于,这是针对自动驾驶深度估计攻击的第一个工作。
论文地址:https://drive.google.com/file/d/1p6HX9G0SM5MugeOXoHQpvK0HtHFhoNW8/view?usp=sharing
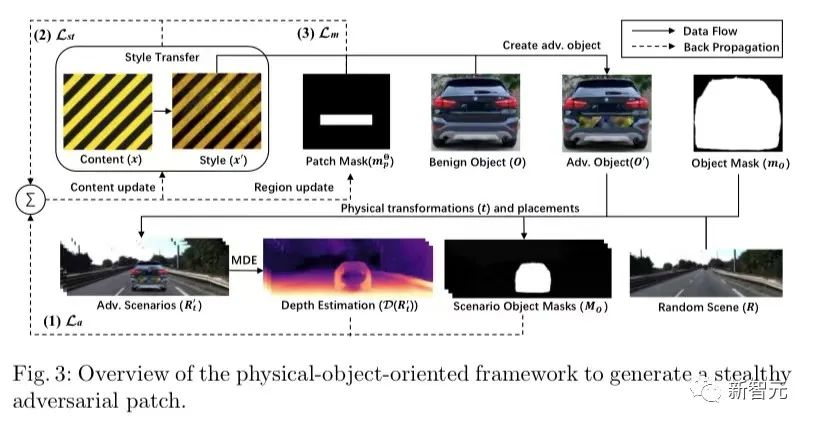
深度学习极大的提升了单目深度估计的性能,这是完全基于视觉的自动驾驶系统(如特斯拉)中的关键模块。在这项工作中,作者开发了一种针对基于学习的单目深度识别模型的攻击。具体地,作者使用一种基于优化的方法,系统地生成了隐蔽的、面向物理世界真实物体的对抗性补丁,以干扰对物体距离的估计。

作者通过面向物体的对抗性设计、对敏感区域的定位和自然风格伪装来平衡作者攻击的隐蔽性和有效性。利用真实世界的驾驶场景,作者评估了本工作针对最前沿的单目深度估计模型和自动驾驶中的代表性下游任务(3D物体检测)的攻击效果。
实验结果表明,本方法可以为不同的目标物体和模型生成隐蔽、有效和稳健的对抗性补丁,并在物体检测中实现了超过6米的平均深度估计误差和超过93%的攻击成功率,补丁面积仅为车辆后部面积的1/9。在三条不同的驾驶路线上用真实车辆进行的现场测试表明,作者造成了超过6米的平均深度估计误差,并将下游任务中连续视频帧的物体检测率从90.70%降低到了5.16%。第二篇题为,「A Cloud 3D Dataset and Application-Specific Learned Image Compression in Cloud 3D」来自德州大学圣安东尼奥分校,作者分别是Tianyi Liu,Sen He,Vinodh Kumaran Jayakumar和Wei Wang。在Cloud 3D系统中,例如Cloud Gaming和Cloud Virtual Reality(VR),3D应用的画面在云端数据中心渲染,然后压缩后发送到客户端供用户和游戏玩家查看和交互。为了同时实现低延迟和高图像质量,快速、高压缩率和高质量的图像压缩技术备受青睐。由于基于深度学习的神经网络图像压缩,在图像压缩中逐渐表现了出色效果。本文主要探讨如何加速基于神经网络的图像压缩方法,以使其更适合云端图形渲染系统。作者采用了低复杂度和应用专用的AI模型来减少计算时间,同时保证图像质量。(1)由于 3D 应用程序渲染的图像是高度同质化的,与通用训练数据集相比,application-specific数据集可以提高模型的rate-distortion性能;(2) 3D 应用程序的图像画面往往没有自然照片那么复杂,这也使得使用不太复杂的模型进行更快的压缩变得可行;(3)随着深度学习模型的简化,我们可以动态提高压缩任务的分片大小,从而充分利用GPU算力资源,提高并行度。通过在六个游戏图像数据集上进行评估,我们的方法具有与SOTA压缩算法相似的率失真性能,同时获得约 5 到 9 倍的加速并将压缩时间减少到小于 1 秒(0.74 秒)。从而将深度学习图像压缩技术在Cloud 3D系统中的应用,又向前推动了一小步。
参考资料:
https://eccv2022.ecva.net/submission/list-of-accepted-papers-ids/