
HDFS 实践 | 京东 HDFS EC 应用解密

Tech
导读
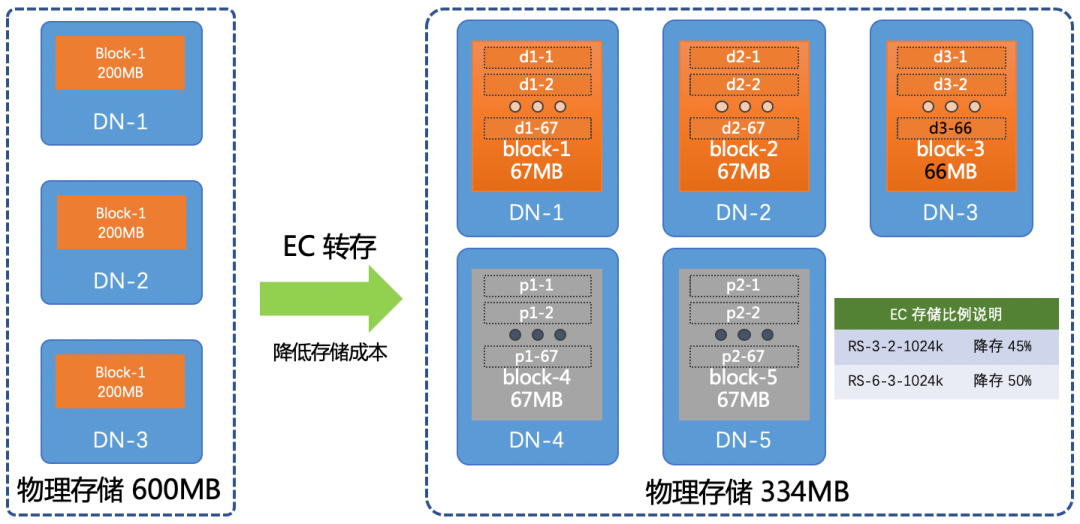
为了实现降本增效,京东HDFS 团队在 EC 功能的移植、测试与上线过程中,基于自身现状采取的一些措施并最终实现平滑上线。同时自研了一套数据生命周期管理系统,对热温冷数据进行自动化管理。在研发落地过程中还构建了三维一体的数据校验机制,为 EC 数据的正确性提供了强有力的技术保障。
本文详细介绍在研发一个复杂系统时,如何基于实际情况进行取舍,并确立行动准则。在功能上线过程中,要保持对线上系统的敬畏,确保上线与回滚不会导致元数据损坏。此外,要深刻认识系统的核心职责,对于存储系统务必加强技术保障,确保数据的安全与可靠,不能丢不能错。
01
升级 or 移植
按功能模块移植代码。 移植过程中,尽可能的保持社区代码原有样式,以便于后续apply patch。 对移植过程没有任何帮助的代码,不移植。 对于接口,优先移植,而且与社区保持一致。 测试用例必须移植并跑通。 对于目前不移植或者为了简化移植工作而去掉的代码,一定不能影响现有场景的功能,并用TODO标识未来会修改。
02
项目质量保障
移植工作不能改变原有接口和命令行语义,甚至接口和命令行的返回信息也要确保与 2.7.1 版本一致。 一般的集群运维操作能够正常进行,比如 DN 节点上下线,NN 升级与回退。 在破坏性测试中,集群的健壮性不受影响,比如磁盘故障,网络异常,数据损坏。 验证集群兼容性,NN/DN/JN 逐步升级和回退不能影响集群的服务能力。 校验数据正确性,在测试过程中要保证 EC 数据没有被损坏,丢块后重建的数据是正确的。 性能对比测试,引入 EC 功能后,通过压测对比,确保集群,特别是 NN,性能不受影响。
03
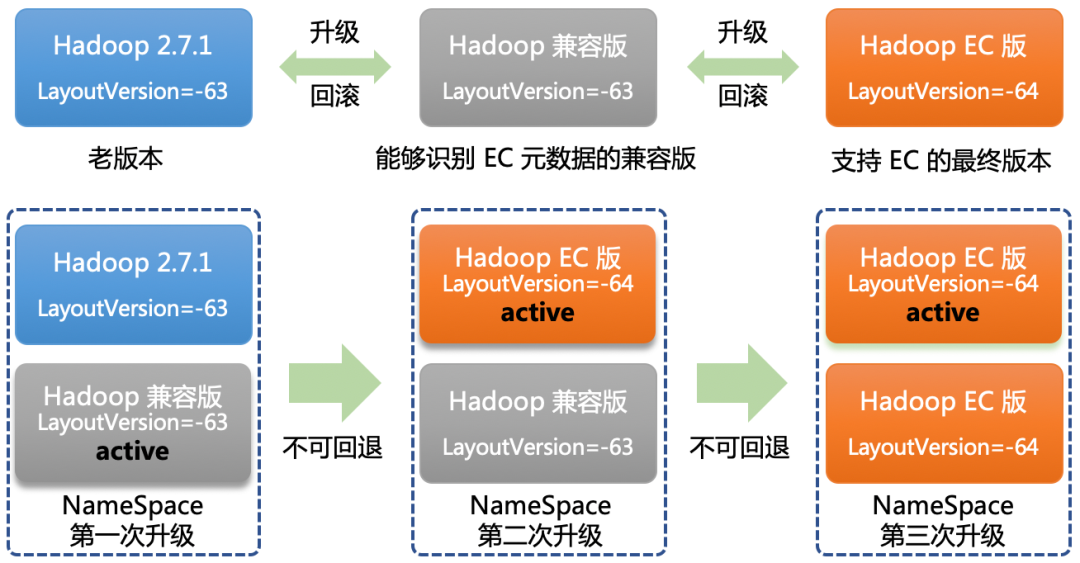
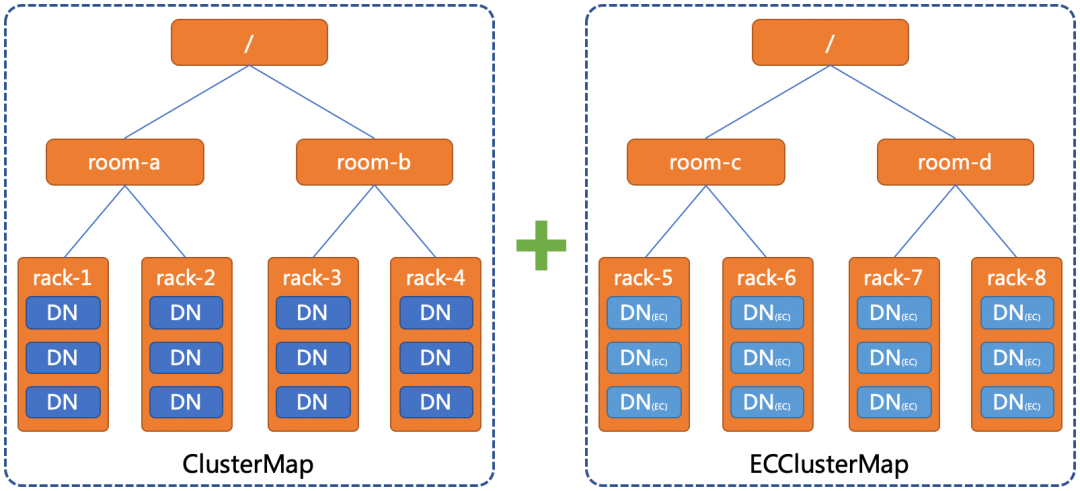
升级与回滚
04
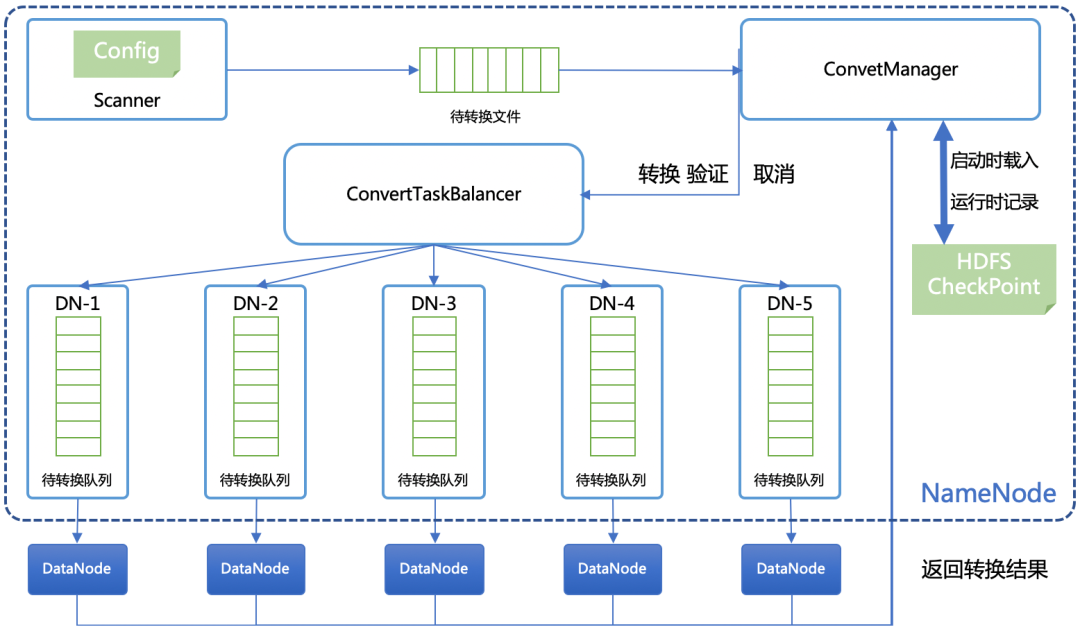
数据生命周期管理
在不修改 NN的前提下,任务调度系统无法实时转换新增数据。 如果在数据拷贝过程中发生错误,只能重头开始转换。 如果要对数据进行过滤,只支持对文件路径的过滤。 如果把转换后的数据移到源目录时,没法进行原子交换,用户程序会在此间隙抛出找不到文件的异常。 此外,HDFS 为目录和文件设置了用户组权限以及时间戳,对所有数据进行拷贝时,需要给拷贝程序赋超级权限,会引入一定的安全风险,现有方案也不能保证转换后的文件和原始文件属性保持一致。
05
全方位的数据完整性保障
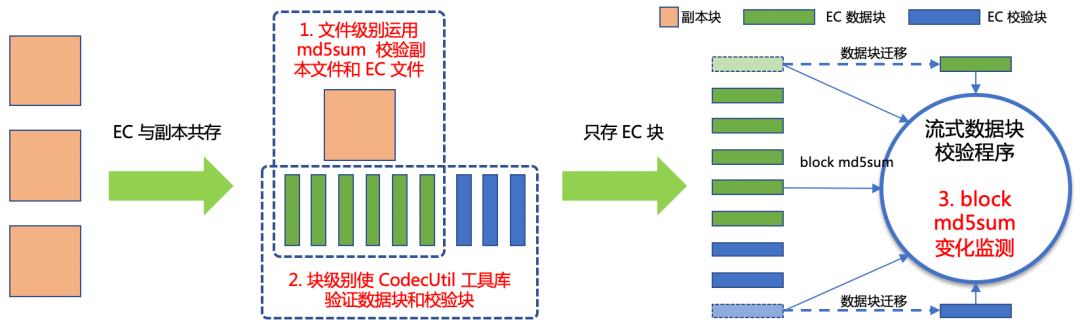
06
总结与展望
HDFS-14171,影响 NN 启动速度。 HDFS-14353, 修复 xmitsInProgress 指标异常。 HDFS-14523, 去除 NetworkTopology 多余锁。 HDFS-14849, DN 下线导致 EC 块无限复制。 HDFS-15240, 修复脏缓存导致数据重建错误。
京东零售-黄涛

揭秘| 大数据计算引擎性能及稳定性提升神器!
"多模态数字内容生成"的技术探索与应用实践
AI新生:破解人机共存密码 | 每月一书(福利送书)
一图看懂未来科技趋势

评论