
盘一盘2021全球流量最高的网站~
世界上流量最大的网站有哪些,也许我们都能脱口而出,比如 Google,YouTube,Facebook 还有 PxxnHub 等等,今天我们就通过多个维度来看看,那些叱咤全球的流量网站!

数据获取
首先我们还是先抓取数据,目标网站是如下地址
https://www.visualcapitalist.com/the-50-most-visited-websites-in-the-world/
该页面有如下一个表格,里面罗列的全球流量前50的网站,我们就抓取这个数据
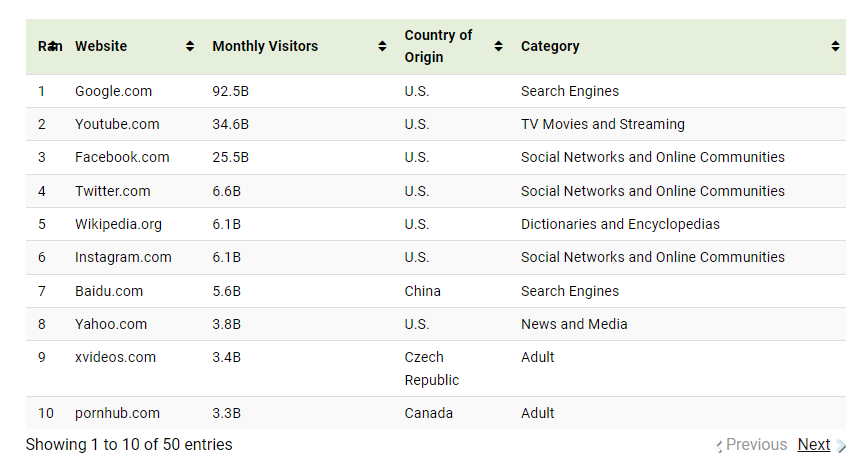
下面进行编码,使用 requests 访问页面,通过 BeautifulSoup 解析网页
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
res = requests.get("https://www.visualcapitalist.com/the-50-most-visited-websites-in-the-world/", headers=headers)
soup = BeautifulSoup(res.text)
tbody = soup.find("table").find("tbody")
tr_list = tbody.find_all("tr")
data_list = []
for tr in tr_list:
tds = tr.find_all("td")
tmp = []
for td in tds:
tmp.append(td.text)
data_list.append(tmp)
print(data_list)
Output:
[['1', 'Google.com', '92.5B', 'U.S.', 'Search Engines'],
['2', 'Youtube.com', '34.6B', 'U.S.', 'TV Movies and Streaming'],
['3',
'Facebook.com',
'25.5B',
'U.S.',
'Social Networks and Online Communities'],
['4',
'Twitter.com',
'6.6B',
'U.S.',
'Social Networks and Online Communities'],
['5', 'Wikipedia.org', '6.1B', 'U.S.', 'Dictionaries and Encyclopedias'],
['6',
'Instagram.com',
'6.1B',
'U.S.',
'Social Networks and Online Communities'],
....
拿到上述数据之后,我们整理成 DataFrame 形式
df = pd.DataFrame(data_list)
df.rename(columns={0:'Rank',1:'WebSite',2:'Traffic', 3:'Country', 4:'Type'},inplace=True)
df['new_Traffic'] = df['Traffic'].apply(lambda x: x.split("B")[0] if "B" in x else float(x.split("M")[0])/1000)
print(df)
Output:
Rank WebSite Traffic Country Type new_Traffic
0 1 Google.com 92.5B U.S. Search Engines 92.5
1 2 Youtube.com 34.6B U.S. TV Movies and Streaming 34.6
2 3 Facebook.com 25.5B U.S. Social Networks and Online Communities 25.5
3 4 Twitter.com 6.6B U.S. Social Networks and Online Communities 6.6
4 5 Wikipedia.org 6.1B U.S. Dictionaries and Encyclopedias 6.1
5 6 Instagram.com 6.1B U.S. Social Networks and Online Communities 6.1
6 7 Baidu.com 5.6B China Search Engines 5.6
7 8 Yahoo.com 3.8B U.S. News and Media 3.8
8 9 xvideos.com 3.4B Czech Republic Adult 3.4
9 10 pornhub.com 3.3B Canada Adult 3.3
10 11 Yandex.ru 3.2B Russia Search Engines 3.2
11 12 Whatsapp.com 3.1B U.S. Social Networks and Online Communities 3.1
12 13 Amazon.com 2.9B U.S. Marketplace 2.9
...
接下来我们再转换下格式,保存成csv文件,留着后面使用
web_name = df['WebSite'].values.tolist()
newdf = pd.DataFrame(np.repeat(df.values,24,axis=0))
newdf.columns = df.columns
newdf['date'] = ''
for i, r in newdf.iterrows():
print(r['WebSite'])
tag = 0
ni = 0
for j in web_name[::-1]:
if r['WebSite'] == j:
print(tag)
print(ni)
r['date'] = d_list[tag:]
ni += 1
tag += 1
newdf=newdf[['WebSite','Type','new_Traffic', 'date']]
newnew = newdf.rename(columns={'WebSite':'name','Type': 'type', 'new_Traffic':'value'})
newnew.to_csv('newdf.csv', index=0)
可视化分析
首先导入需要的库
from pyecharts.charts import Bar,Map,Line,Page,Scatter,Pie,Polar
from pyecharts import options as opts
from pyecharts.globals import SymbolType,ThemeType
from pyecharts.charts import Grid, Liquid
from pyecharts.commons.utils import JsCode
排名前十榜单
根据流量的大小,获取排名前十的榜单
x_data = df['WebSite'].values.tolist()[:10]
y_data = df['new_Traffic'].values.tolist()[:10]
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
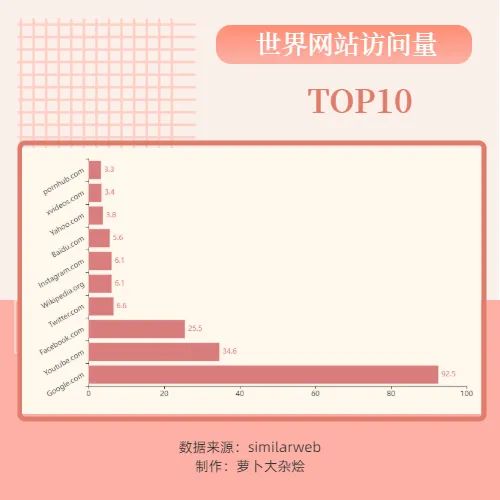
可以看出 Google.com 一骑绝尘,是巨无霸的存在,紧随其后的就是全球最大的视频分享网站油管,而我们都熟悉的,呸,是你们都熟悉的P站排在第十,也是个不错的排名哦
排名前二十榜单
再来看看前二十的情况
x_data = df['WebSite'].values.tolist()[10:20]
y_data = df['new_Traffic'].values.tolist()[10:20]
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()

前二十相对差距就没有那么大了,Zoom,亚马逊等知名网站都在这个区间
国家排名
下面我们根据网站所属国家进行排名
country_group = df.groupby("Country").count().sort_values(by=["Rank"], ascending=False)
x_data = country_group.index.tolist()[:7]
y_data = country_group["Rank"].values.tolist()[:7]
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='top'))
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
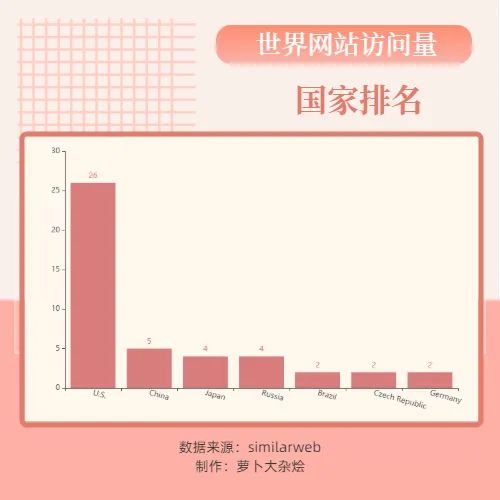
漂亮国遥遥领先,作为当今世界第一强国,其领先优势是全方位的,排名2-4位的分别为中国,日本和俄罗斯
散点图视角
c = (
Scatter()
.add_xaxis(x_data)
.add_yaxis("", y_data)
.set_global_opts(
title_opts=opts.TitleOpts(),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(type_="size", max_=30, min_=1),
)
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(c, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
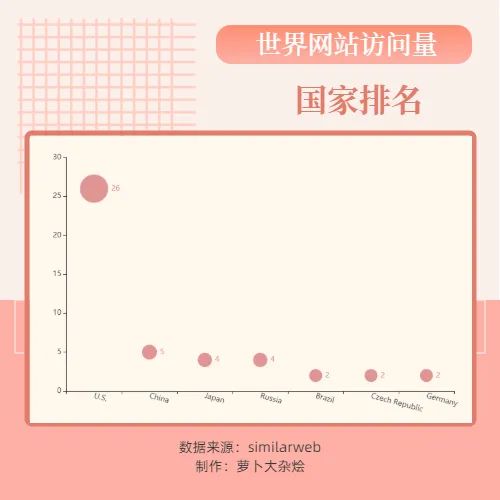
网站类型
下面我们来看下不同网站类型的分布情况
type_group = df.groupby("Type").count().sort_values(by=["Rank"], ascending=False)
x_type = type_group.index.tolist()
y_type = type_group["Rank"].values.tolist()
test = ['Social Networks and Online Communities',
'Marketplace',
'News and Media',
'Search Engines',
'Adult',
'Programming and Developer Software',
'Email']
c = (
Polar()
.add_schema(angleaxis_opts=opts.AngleAxisOpts(data=x_type[:9], type_="category"))
.add("", y_type[:9], type_="bar", stack="stack0")
.set_global_opts(title_opts=opts.TitleOpts(title=""))
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(c, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
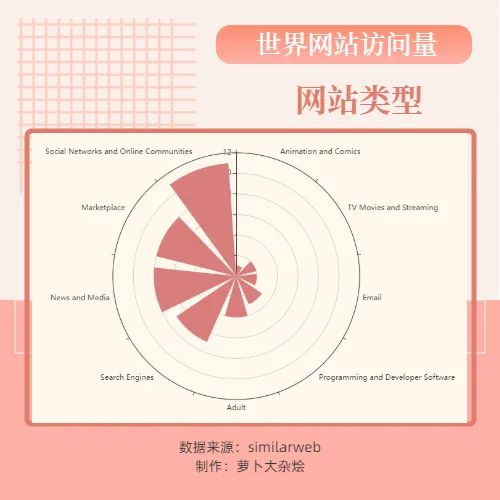
可以看到,网站类型最多的就是社交&在线交流类型的网站,比如Facebook,Twitter等,然后以Amazon为首的购物网站也占据了很大一部分
各类型网站所占比例
l1 = (
Liquid()
.add("", [y_type[2]/sum(y_type)], center=["35%", "75%"])
.set_global_opts(title_opts=opts.TitleOpts(title=""))
)
l2 = Liquid().add(
"lq",
[y_type[0]/sum(y_type)],
center=["25%", "26%"],
label_opts=opts.LabelOpts(
font_size=50,
formatter=JsCode(
"""function (param) {
return (Math.floor(param.value * 10000) / 100) + '%';
}"""
),
position="inside",
),
)
l3 = (
Liquid()
.add("", [y_type[1]/sum(y_type)], center=["75%", "26%"])
.set_global_opts(title_opts=opts.TitleOpts(title=""))
)
l4 = Liquid().add(
"",
[y_type[3]/sum(y_type)],
center=["65%", "75%"],
label_opts=opts.LabelOpts(
font_size=50,
formatter=JsCode(
"""function (param) {
return (Math.floor(param.value * 10000) / 100) + '%';
}"""
),
position="inside",is_show=True
),
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE)).add(l1, grid_opts=opts.GridOpts()).add(l2, grid_opts=opts.GridOpts()).add(l3, grid_opts=opts.GridOpts()).add(l4, grid_opts=opts.GridOpts())
grid.render_notebook()
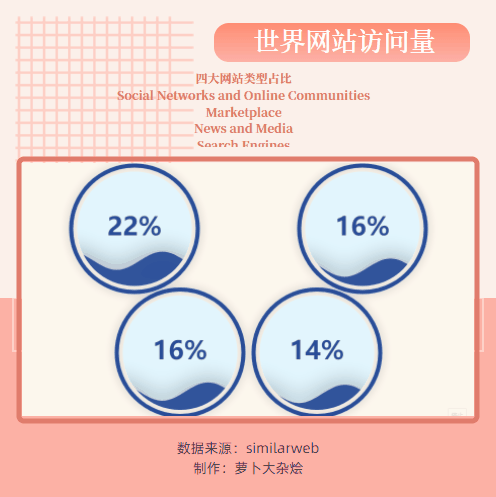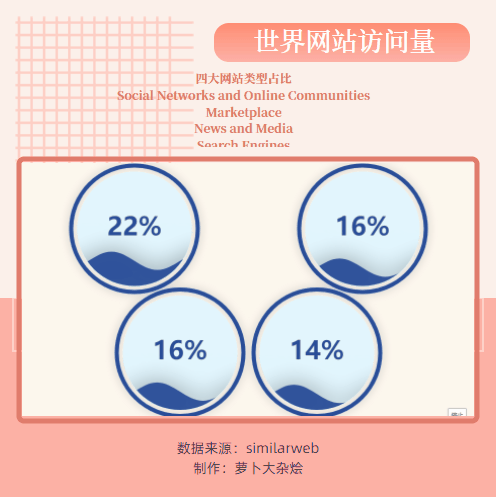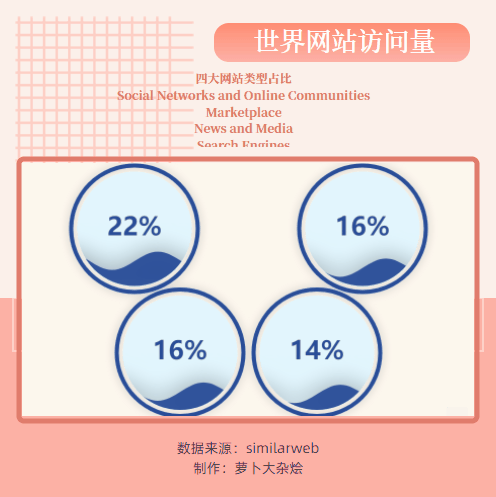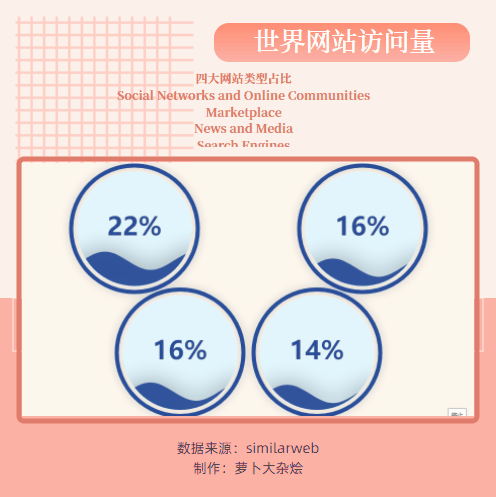
动态排行展示
下面我们通过一个小视频来更加直观看下全球top网站的排名情况
最后再来一张神图,非常惊艳
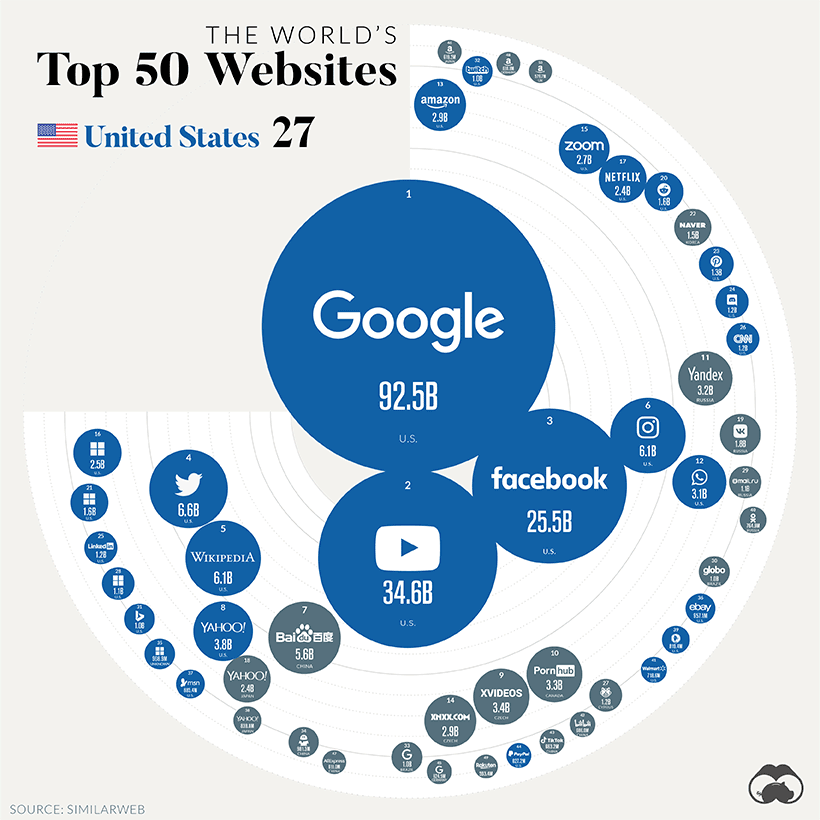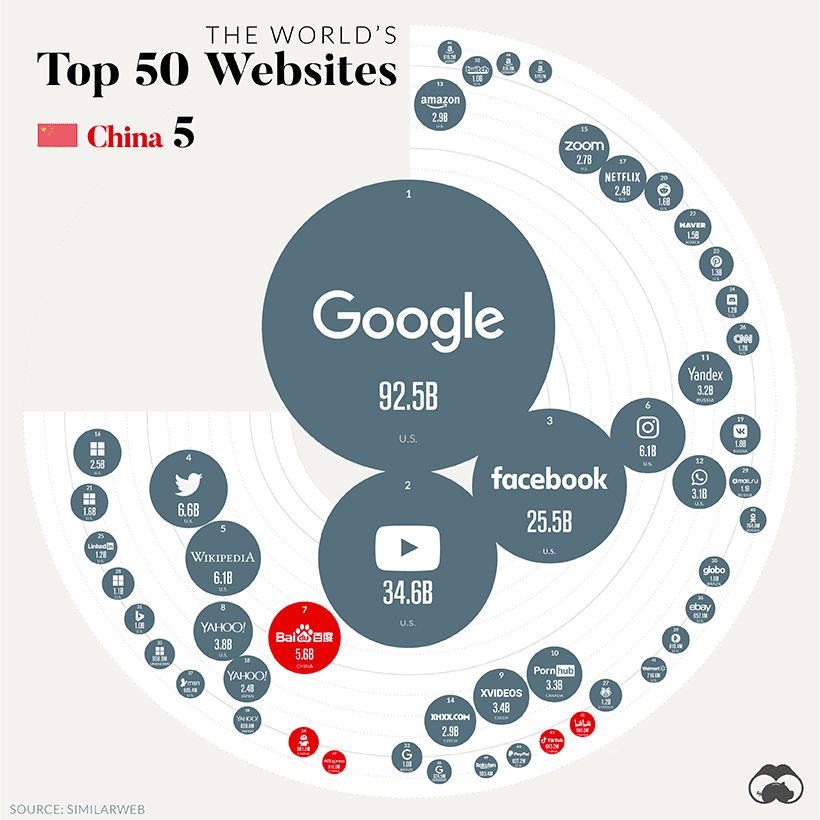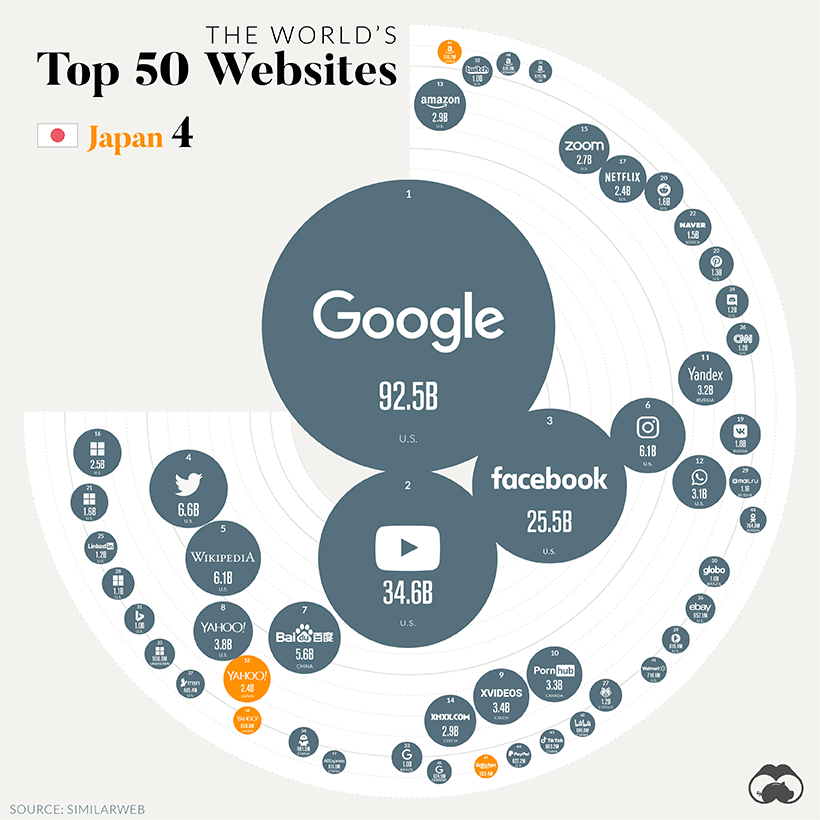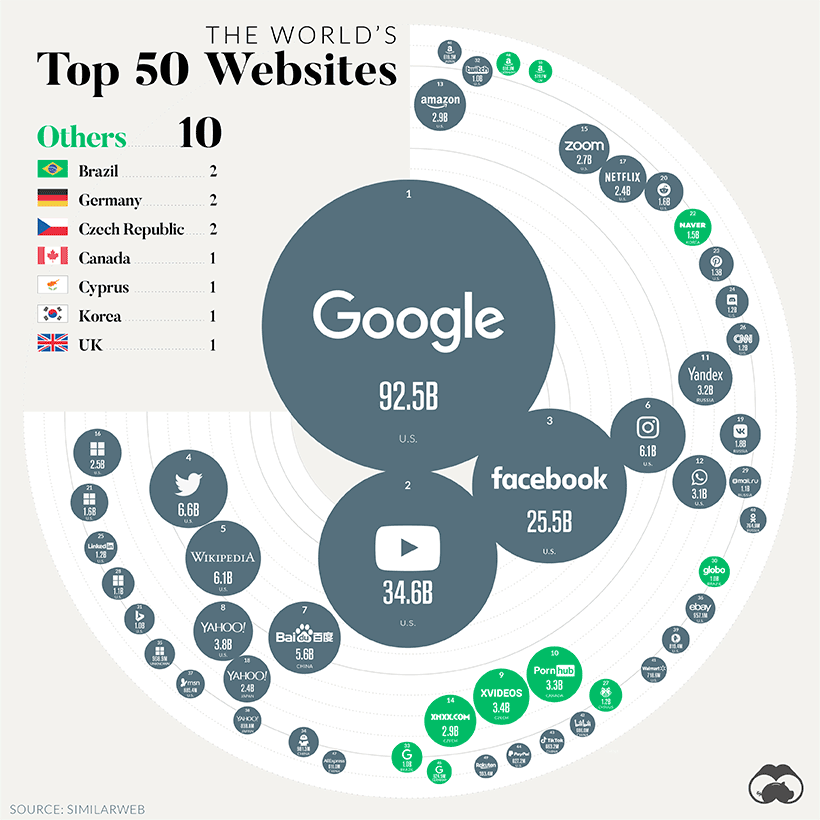
这张图目测通过 Matplotlib 应该可以实现,大家帮忙给文章点赞和在看,如果数量够多,咱们就找时间复现一下~
好了,以上就是今天分享的所有内容,如果对你有帮助,帮忙点赞和在看支持哦~
各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)

推荐阅读