
Python | 爬虫框架 feapder 初体验
嘿,大家好,我是咸鱼,之前,我们写爬虫,用的最多的框架莫过于scrapy啦,今天我们用最近新出的爬虫框架feapder来开发爬虫,看下是怎样的体验。
目标网站:aHR0cHM6Ly93d3cubGFnb3UuY29tLw==
需求:采集职位列表与职位详情,详情需每7天更新一次
为了演示,以下只搜索与爬虫相关的职位
1. 调研
1.1 列表页面
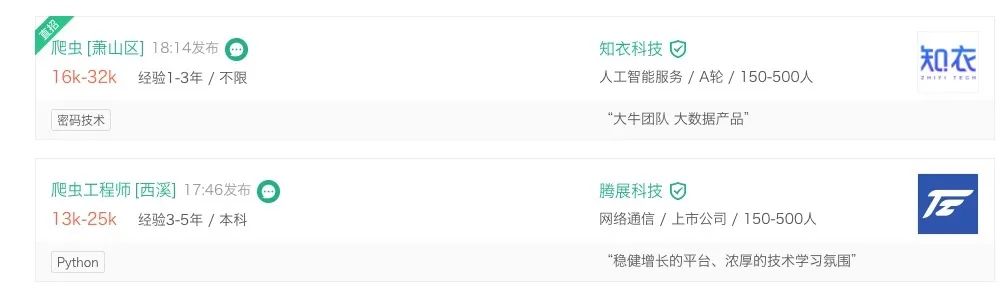
首先我们需要看下页面是否为动态渲染的,接口是否有反爬。
看是否为动态渲染的可以右键,显示网页源代码,然后搜索网页上的内容源码里是否存在,比如搜索列表的第一条知衣科技,匹配了0条,则初步判断是动态渲染的

或者可以用feapder命令,下载网页源码,查看。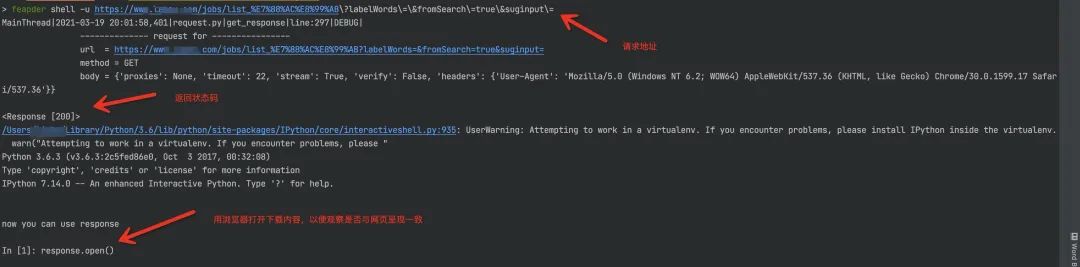
打开后的页面为加载中
调用response.open()命令会在工作目录下生产一个temp.html文件,内容为当前请求返回的源码,我们点击查看,是一段js,有安全验证。因此可以推断出该网站有反爬,难度升级预警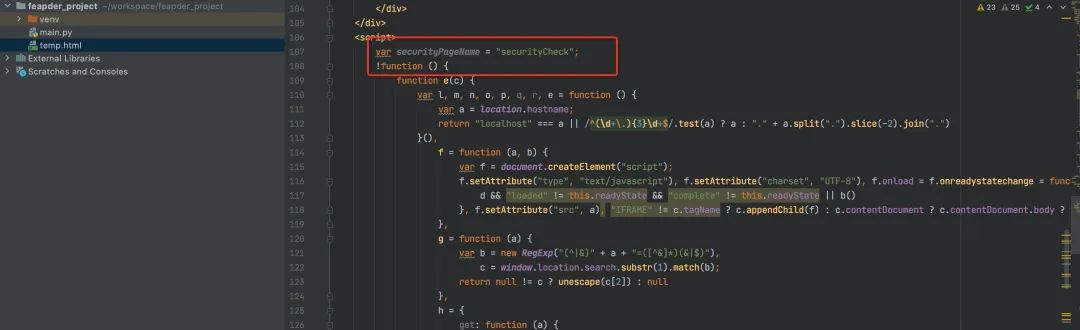
feapder还支持使用curl命令请求,方式如下:
按F12,或者右键检查,打开调试窗口,刷新页面,点击当前页的请求,复制为curl,返回命令行窗口,输入 feapder shell --然后粘贴刚刚复制的内容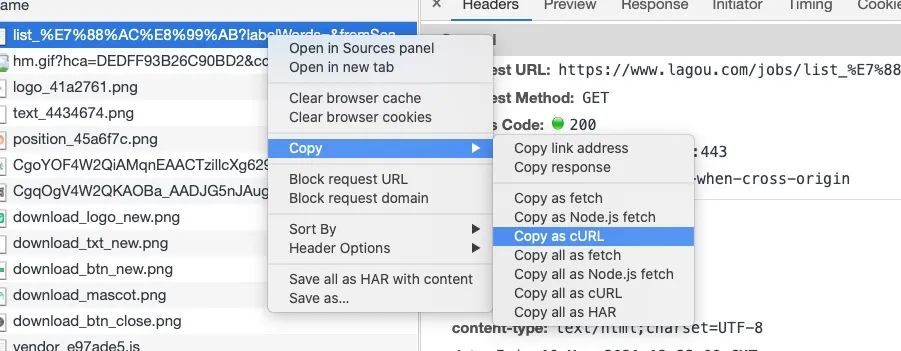
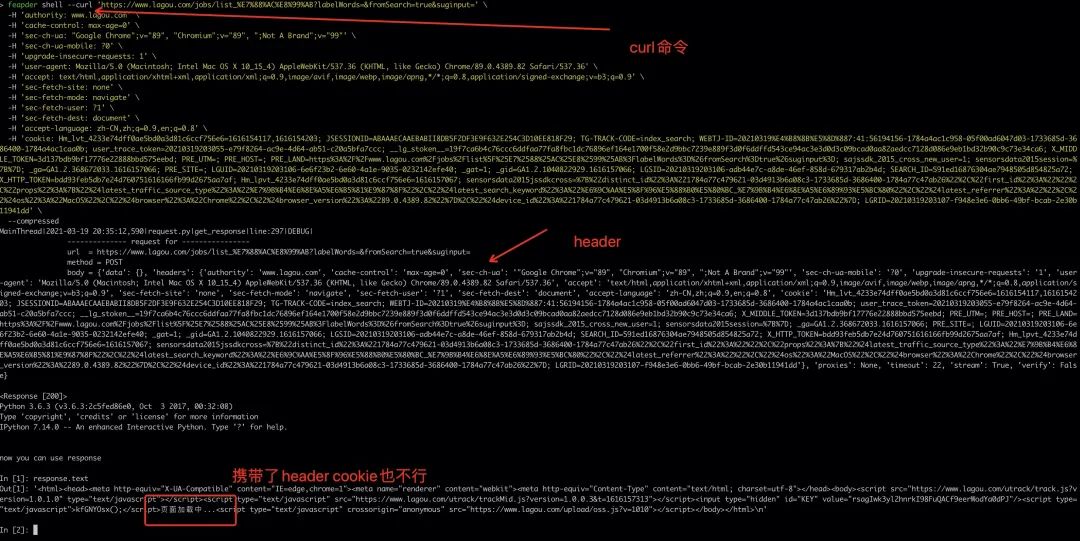
发现携带header,cookie也不行,可能是某些参数只能用一次吧。
调研结论:列表页有反爬,页面动态渲染
ps: 正常大神还会继续调研,列表接口是什么,如何破解反爬,但因为我是小白,就先不纠结了
1.2 详情页面
与列表页调研类似,结论是有反爬,但页面不是动态渲染的
2. 创建项目
打开命令行工具,输入:
> feapder create -p lagou-spider
lagou-spider 项目生成成功
生成项目如下:
我用的pycharm,先右键,将这个项目加入到工作区间。
(右键项目名,Mark Directory as -> Sources Root)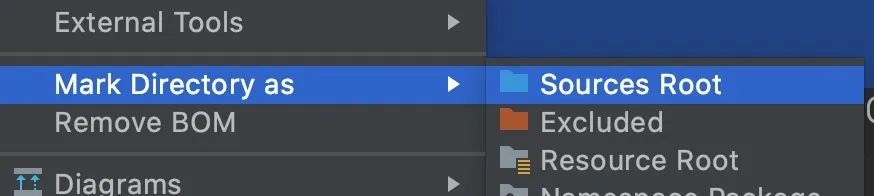
3. 写列表页爬虫
3.1 创建爬虫
> cd lagou-spider/spiders
> feapder create -s list_spider
ListSpider 生成成功
生成代码如下:
import feapder
class ListSpider(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
ListSpider().start()
这是请求百度的例子,可直接运行
3.2 写爬虫
下发任务:
def start_requests(self):
yield feapder.Request("https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput=", render=True)
注意到,我们在请求里携带了render参数,表示是否用浏览器渲染,因为这个列表页是动态渲染的,又有反爬,我比较怂,所以采用了渲染模式,以避免掉头发
编写解析函数
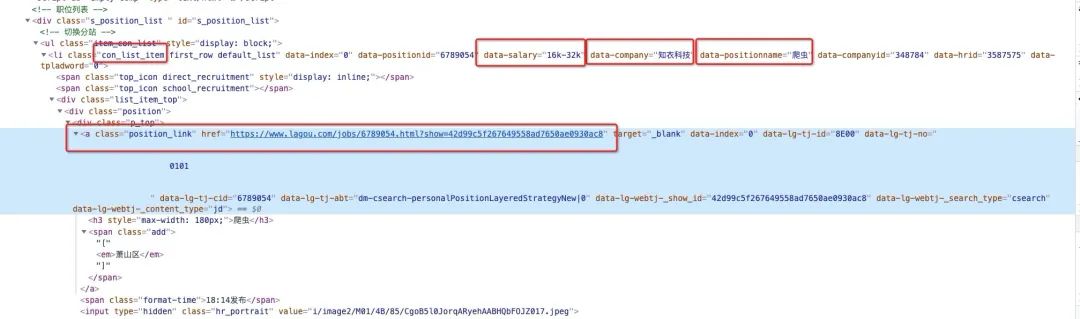
观察页面结构,写出如下解析函数
def parse(self, request, response):
job_list = response.xpath("//li[contains(@class, 'con_list_item')]")
for job in job_list:
job_name = job.xpath("./@data-positionname").extract_first()
company = job.xpath("./@data-company").extract_first()
salary = job.xpath("./@data-salary").extract_first()
job_url = job.xpath(".//a[@class='position_link']/@href").extract_first()
print(job_name, company, salary, job_url)
我们解析了职位名称、公司、薪资、以及职位详情地址,正常逻辑应该将详情地址作为任务下发,获取详情
def parse(self, request, response):
job_list = response.xpath("//li[contains(@class, 'con_list_item')]")
for job in job_list:
job_name = job.xpath("./@data-positionname").extract_first()
company = job.xpath("./@data-company").extract_first()
salary = job.xpath("./@data-salary").extract_first()
job_url = job.xpath(".//a[@class='position_link']/@href").extract_first()
print(job_name, company, salary, job_url)
yield feapder.Request(
job_url, callback=self.parse_detail, cookies=response.cookies.get_dict()
) # 携带列表页返回的cookie,回调函数指向详情解析函数
def parse_detail(self, request, response):
print(response.text)
# TODO 解析详情
但需求是详情每7天更新一次,列表没说要更新,因此为了优化,将详情单独写个爬虫,本爬虫只负责列表的数据和生产详情的任务就好了
3.3 数据入库
创建表
职位列表数据表 lagou_job_list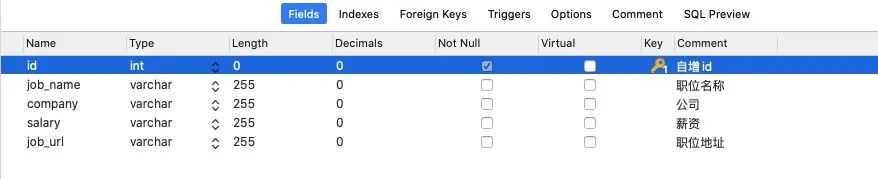
CREATE TABLE `lagou_job_list` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增id',
`job_name` varchar(255) DEFAULT NULL COMMENT '职位名称',
`company` varchar(255) DEFAULT NULL COMMENT '公司',
`salary` varchar(255) DEFAULT NULL COMMENT '薪资',
`job_url` varchar(255) DEFAULT NULL COMMENT '职位地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
详情任务表 lagou_job_detail_task
CREATE TABLE `lagou_job_detail_task` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`url` varchar(255) DEFAULT NULL,
`state` int(11) DEFAULT '0' COMMENT '任务状态(0未做,1完成,2正在做,-1失败)',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
数据入库方式
数据入库有很多方式,直接导入pymysql然后拼接sql语句入库,或者使用框架自带的MysqlDB。不过feapder有一种更方便的入库方式,自动入库
自动入库AirSpider是不支持的,因为他比较轻量嘛,作者为了保持轻量的特性,暂时没支持自动入库。不过分布式爬虫Spider是支持的,我们直接将继承类改为Spider即可
class ListSpider(feapder.AirSpider):
改为
class ListSpider(feapder.Spider):
生成item
item是与表一一对应的,与数据入库机制有关,可用feapder命令生成。
首先配置下数据库连接信息,在setting中配置的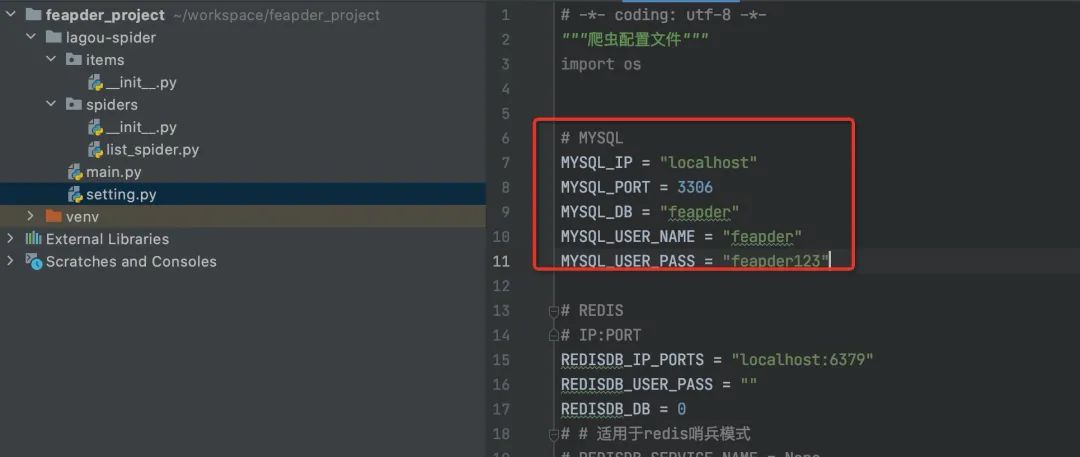
生成item:
> cd items
> feapder create -i lagou_job_list
> feapder create -i lagou_job_detail_task

数据入库
def parse(self, request, response):
job_list = response.xpath("//li[contains(@class, 'con_list_item')]")
for job in job_list:
job_name = job.xpath("./@data-positionname").extract_first()
company = job.xpath("./@data-company").extract_first()
salary = job.xpath("./@data-salary").extract_first()
job_url = job.xpath(".//a[@class='position_link']/@href").extract_first()
# 列表数据
list_item = lagou_job_list_item.LagouJobListItem()
list_item.job_name = job_name
list_item.company = company
list_item.salary = salary
list_item.job_url = job_url
yield list_item # 直接返回,框架实现批量入库
# 详情任务
detail_task_item = lagou_job_detail_task_item.LagouJobDetailTaskItem()
detail_task_item.url = job_url
yield detail_task_item # 直接返回,框架实现批量入库
以yield item的方式将数据返回给框架,框架自动批量入库
3.4 整体代码
import feapder
from items import *
class ListSpider(feapder.Spider):
def start_requests(self):
yield feapder.Request(
"https://www.lagou.com/jobs/list_%E7%88%AC%E8%99%AB?labelWords=&fromSearch=true&suginput=",
render=True,
)
def parse(self, request, response):
job_list = response.xpath("//li[contains(@class, 'con_list_item')]")
for job in job_list:
job_name = job.xpath("./@data-positionname").extract_first()
company = job.xpath("./@data-company").extract_first()
salary = job.xpath("./@data-salary").extract_first()
job_url = job.xpath(".//a[@class='position_link']/@href").extract_first()
# 列表数据
list_item = lagou_job_list_item.LagouJobListItem()
list_item.job_name = job_name
list_item.company = company
list_item.salary = salary
list_item.job_url = job_url
yield list_item # 直接返回,框架实现批量入库
# 详情任务
detail_task_item = lagou_job_detail_task_item.LagouJobDetailTaskItem()
detail_task_item.url = job_url
yield detail_task_item # 直接返回,框架实现批量入库
if __name__ == "__main__":
spider = ListSpider(redis_key="feapder:lagou_list")
spider.start()
redis_key为任务队列在redis中存放的位置。
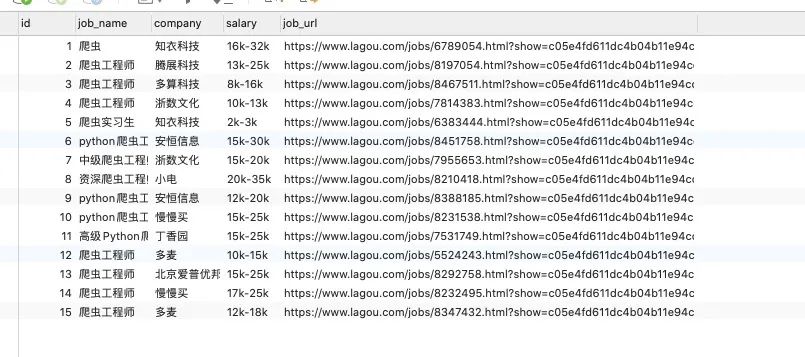
直接运行,观察到数据已经自动入库了
4. 写详情爬虫
与列表页爬虫不同,详情数据需要每7天更新一次。
为了做时序数据展示,我们每7天采集一次数据,数据需携带批次信息,将数据按照7天维度划分
在没接触feapder框架前,我们需要考虑将任务从详情任务表中分批拿出发给爬虫,还需要维护任务的状态,以及上面提及的批次信息。并且为了保证数据的时效性,需要对采集进度进行监控,写个爬虫十分繁琐。
那么feapder如何做呢?为了节省篇幅,直接给出完整代码:
import feapder
from items import *
class DetailSpider(feapder.BatchSpider):
def start_requests(self, task):
task_id, url = task
yield feapder.Request(url, task_id=task_id, render=True)
def parse(self, request, response):
job_name = response.xpath('//div[@class="job-name"]/@title').extract_first().strip()
detail = response.xpath('string(//div[@class="job-detail"])').extract_first().strip()
item = lagou_job_detail_item.LagouJobDetailItem()
item.title = job_name
item.detail = detail
item.batch_date = self.batch_date # 获取批次信息,批次信息框架自己维护
yield item # 自动批量入库
yield self.update_task_batch(request.task_id, 1) # 更新任务状态
if __name__ == "__main__":
spider = DetailSpider(
redis_key="feapder:lagou_detail", # redis中存放任务等信息的根key
task_table="lagou_job_detail_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="lagou_detail_batch_record", # mysql中的批次记录表
batch_name="详情爬虫(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
# 下面两个启动函数 相当于 master、worker。需要分开运行
# spider.start_monitor_task() # 下发及监控任务
spider.start() # 采集
我们分别运行spider.start_monitor_task()与spider.start(),待爬虫结束后,观察数据库
任务表:lagou_job_detail_task

任务均已完成了,框架有任务丢失重发机制,直到所有任务均已做完
数据表:lagou_job_detail:
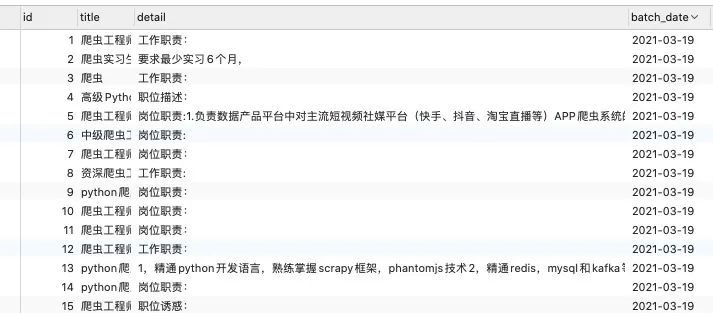
数据里携带了批次时间信息,我们可以根据这个时间来对数据进行划分。当前批次为3月19号,若7天一批次,则下一批次为3月26号。
在本批次期间重复启动爬虫,若无新任务,爬虫不会抓取spider.start_monitor_task()
spider.start()
批次表:lagou_detail_batch_record

批次表为启动参数中指定的,自动生成。批次表里详细记录了每个批次的抓取状态,如任务总量、已做量、失败量、是否已完成等信息
5. 整合
目前列表爬虫与详情爬虫都写完了,运行入口分布在两个文件里,管理起来比较乱,feapder建议写到统一写到main.py里
from feapder import ArgumentParser
from spiders import *
def crawl_list():
"""
列表爬虫
"""
spider = list_spider.ListSpider(redis_key="feapder:lagou_list")
spider.start()
def crawl_detail(args):
"""
详情爬虫
@param args: 1 / 2 / init
"""
spider = detail_spider.DetailSpider(
redis_key="feapder:lagou_detail", # redis中存放任务等信息的根key
task_table="lagou_job_detail_task", # mysql中的任务表
task_keys=["id", "url"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="lagou_detail_batch_record", # mysql中的批次记录表
batch_name="详情爬虫(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
if args == 1:
spider.start_monitor_task()
elif args == 2:
spider.start()
if __name__ == "__main__":
parser = ArgumentParser(description="xxx爬虫")
parser.add_argument(
"--crawl_list", action="store_true", help="列表爬虫", function=crawl_list
)
parser.add_argument(
"--crawl_detail", type=int, nargs=1, help="详情爬虫(1|2)", function=crawl_detail
)
parser.start()
查看启动命令:
> python3 main.py --help
usage: main.py [-h] [--crawl_list] [--crawl_detail CRAWL_DETAIL]
xxx爬虫
optional arguments:
-h, --help show this help message and exit
--crawl_list 列表爬虫
--crawl_detail CRAWL_DETAIL
详情爬虫(1|2)
启动列表爬虫:
python3 main.py --crawl_list
启动详情爬虫master
python3 main.py --crawl_detail 1
启动详情爬虫worker
python3 main.py --crawl_detail 2
总结
本文拿某招聘网站举例,介绍了使用feapder采集数据整个过程。其中涉及到AirSpider、Spider、BatchSpider三种爬虫的使用。
AirSpider爬虫比较轻量,学习成本低。面对一些数据量较少,无需断点续爬,无需分布式采集的需求,可采用此爬虫。
Spider是一款基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能
BatchSpider是一款分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。
feapder除了支持浏览器渲染下载外,还支持pipeline,用户可自定义,方便对接其他数据库
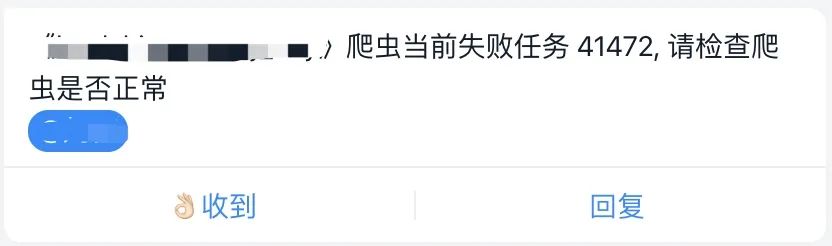
框架内置丰富的报警,爬虫有问题时及时通知到我们,以保证数据的时效性
实时计算爬虫抓取速度,估算剩余时间,在指定的抓取周期内预判是否会超时

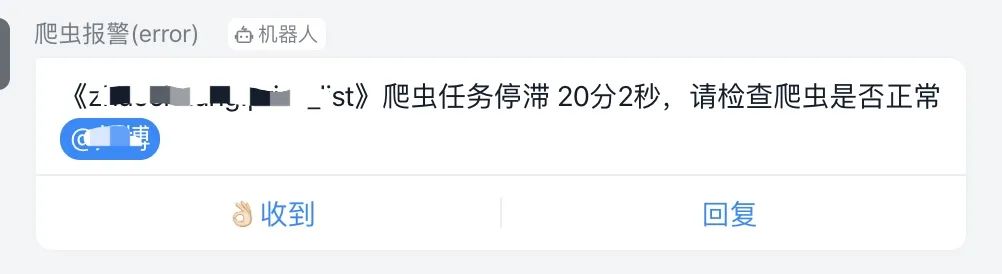
爬虫卡死报警
爬虫任务失败数过多报警,可能是由于网站模板改动或封堵导致
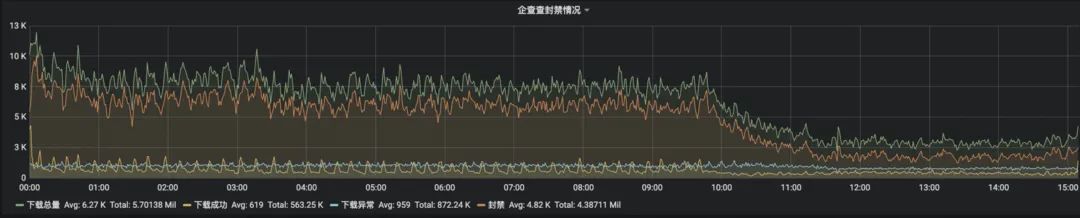
下载情况监控
关于feapder使用说明,详见官方文档:https://boris.org.cn/feapder/#/
本文项目地址可在后台回复【feapder】获取