
虚拟邓丽君,歌声合成真的可以如此逼真吗?数字人技术系列

 虚拟邓丽君 - 数字王国
虚拟邓丽君 - 数字王国
opus
虚拟邓丽君的歌声是配音??

Sean
Zhao
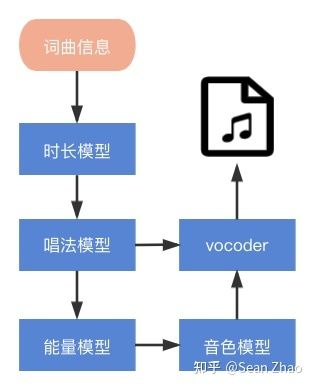
想要数字人自己可以唱歌的话,就不得不说一下歌声合成技术了
# 拼接合成
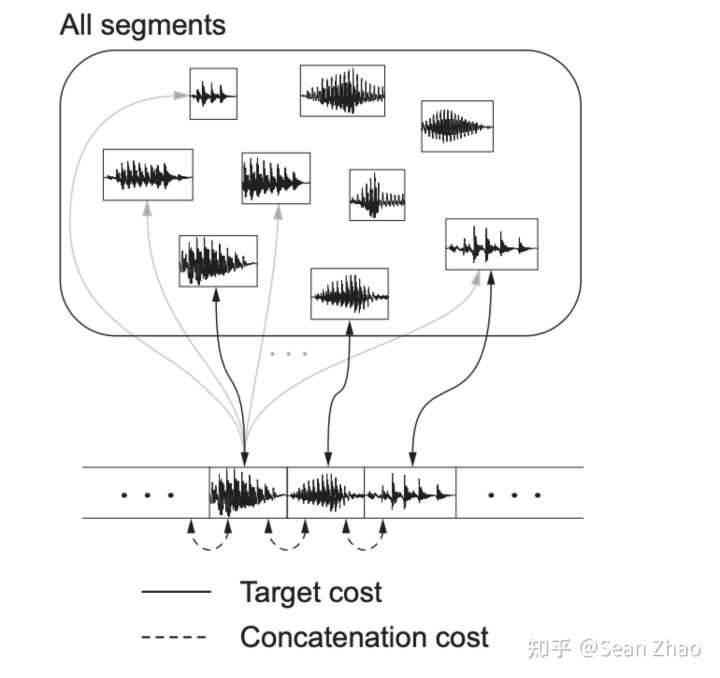
- 采样的处理:
合成时,要对采样进行一些处理,比如最常见的变调,拉伸等,还有一些更细致的调教参数,如气息度等。
- 声库的设计:
如何设计声库,可以使用尽量少的数据应对合成过程中的各种复杂组合,还要保持很高的自然度。
- 拼接的处理:
采样拼接时,如何处理可以最大化的做到平滑无缝感

# 参数合成
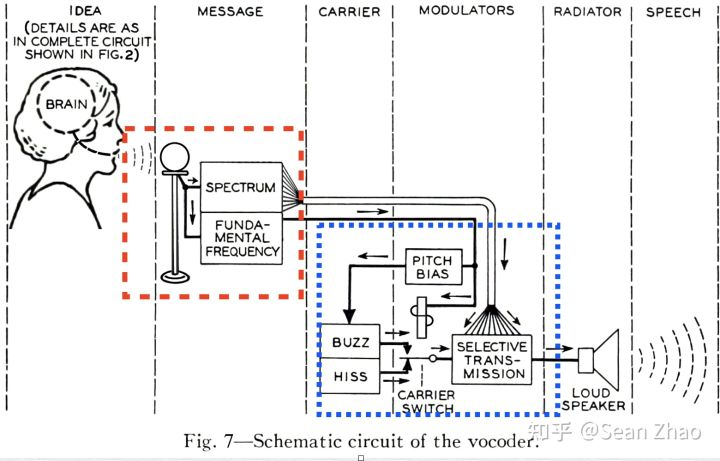
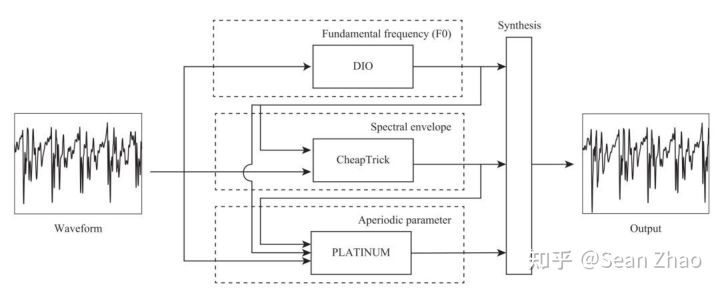
# 深度神经网络
专栏作者
Sean Zhao
AI算法工程师/游戏开发工程师/全栈
知乎:www.zhihu.com/people/sean-zhao-11

opus
学到了!欢迎大家加入我们的社群#算法作曲,探索AI音乐方向。
评论