
darknet框架权威解读系列一:框架构成
AI编辑:我是小将
本文作者:陈训教
本文已由原作者授权,不得擅自二次转载
前 言
本系列文章旨在通过解读darknet整体框架,一方面可以探究深度学习原理的底层实现机制,另一方面,提升C语言能力。截止目前,在github上解读darknet的两个好的项目(https://github.com/hgpvision/darknet和https://github.com/BBuf/Darknet),其中hgpvision主要针对pjreddie项目解读,而BBuf主要是针对AB大神的darknet项目解读。这里特别感谢两位前辈给出的精彩解读。
本系列文章按照由整体到部分,原理(框架)解读+代码解析的思路进行解读,首先给出整个darknet的框架构成,然后详细解读每一部分。详细的darknet项目解读地址:https://github.com/ChenCVer/darknet。
框架总览
darknet项目工程代码结构如下图所示:
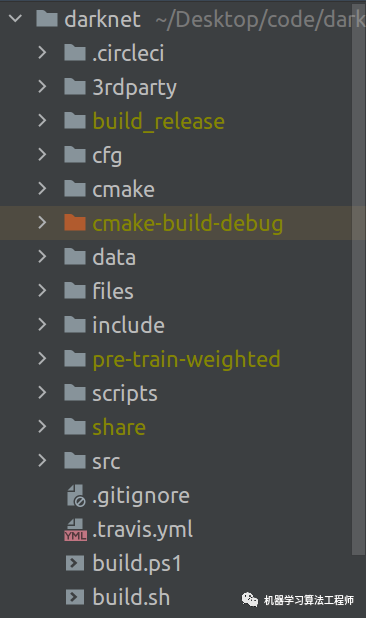
各文件夹的作用大致如下:
3rdparty:存放第三方库;
cfg:存放各种配置文件,比如网络配置文件(例如:yolov4.cfg)和data配置文件(比如voc.data)等;
data:类似于标准C工程代码中的resource文件夹,用来存放data,比如你的voc数据集等;
files:这个文件夹是我自己加的,主要存放对于darknet某些具体细节代码的详细说明;
include:存放darknet头文件,主要用于win系统;
pre-train-weighted:用于存放预训练权重文件(我自己加的);
scripts:从来存放一些脚本文件等;
src:用来存放所有源代码(诸如:各种类型的网络层结构,重要的工具函数等),这个文件夹最重要。
darknet总体框架如下图所示(几乎所有的框架都是这个流程):
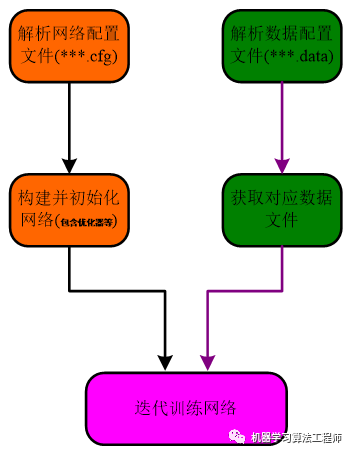
框架最简代码可以写成下述形式(注意,代码只是整体框架的逻辑思路):
int main(int argc, char** argv){
// step1: 网络构建及初始化
// 解析net.cfg配置文件
list *sections = read_cfg(filename);
// 为网络分配内存空间
network* net = (network*)xcalloc(1, sizeof(network));
// 为网络中的指针变量内存空间
*net = make_network(sections->size - 1);
// 解析xxx.cfg网络配置文件,同时初始化网络
parse_net_options(options, &net);
// step2:解析datacfg文件
// 解析data配置文件, 存入list双头链表中
list *options = read_data_cfg(datacfg);
// 多线程加载数据, 其中args包含一系列与loaddata相关的参数, 比如数据增强等
pthread_t load_thread = load_data(args);
// step3: 训练网络
while (get_current_iteration(net) < net.max_batches){
pthread_join(load_thread, 0); // 数据一次性load完毕
// for循环中会形成累计梯度
for(i = 0; i < n; ++i){
forward_network(net); // 前向传播
backward_network(net); // 反向传播
}
update_network(net); // 一次性更新参数
}
return 0;
}
从上面的代码中需要注意一个问题,相信大家在用darknet的时候都会看到网络配置文件中的batch和subdivisions这两个参数,darknet框架是将batch拆分成subdivisions份,也就是说,在进行数据加载的时候,darknet是遵循一次性加载batch个数据,但是在进行前向传播和反向传播的时候,每次只利用batch/subdivisions个数据。这里可知上述代码中的n=batch/subdivisions。这样做的目的是,缓解GPU显存压力,同时可以获得相似的大batch更新效果。其实这样做还是与一次性前向和反向batch数据有区别的,最主要的区别在于BN层的计算。
代码解读
darknet框架的所有功能入口在src/darknet.c文件中的main函数里面,其主函数如下所示(由于代码太长,会有删减)
int main(int argc, char **argv)
{
if (0 == strcmp(argv[1], "detector")){
run_detector(argc, argv); // 检测算法入口(<==分析入口)
}else if (0 == strcmp(argv[1], "yolo")){
run_yolo(argc, argv); // YOLO系列算法入口
}else if (0 == strcmp(argv[1], "rnn")){
run_char_rnn(argc, argv); // rnn算法入口
}else if (0 == strcmp(argv[1], "classifier")){
run_classifier(argc, argv); // 分类算法入口
}else {
fprintf(stderr, "Not an option: %s\n", argv[1]);
}
return 0;
}
由main函数可知,darknet不仅支持目标检测系列算法,还支持RNN和分类算法,这里还需要注意的是,run_yolo()和run_detector()其实是一回事,后续调用的函数是同一个,这里应该是AB大神为了兼容老版darknet框架。另外,对于darknet来说,他的精髓其实是在yolo算法,如果你非要用darknet来做分类任务,也不是不行,就是其数据增强操作太少,我尝试将opencv嵌入到darknet中,作为数据增强库,结果发现十分难搞(主要是由于本人太菜)。darknet自身所带的数据增强操作不如python第三方库那么丰富。本人也尝试用darknet进行分类网络的训练,结果也不太理想,loss迟迟下不去。所以推荐对于图像分类,图像分割(darknet不支持做分割任务,需要自己写代码实现,网上有人实现过)更倾向于用pytorch框架实现。鉴于此情况,本系列解读也只是针对检测算法,不过检测算法中所有代码均已包含分类代码,由于本人没有研究过RNN,所以,相关代码没有做注释(这里十分抱歉啦)。为了让读者对darknet函数相互之间有清晰的全局认识,下面给出了函数之间相互调用流程图,如下所示:
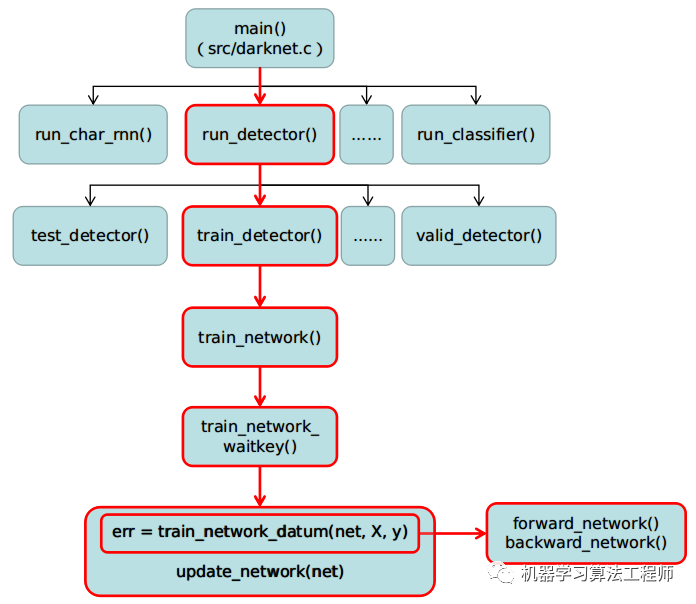
上图中的红色部分就是darknet训练目标检测任务过程的整个函数调用关系流程,其他诸如图像分类,RNN其过程也很类似,就没有列出来。run_detector()函数在位于src/detector.c中,可以看到,run_detecor()函数提供train、valid和test等几乎你能想得到的功能:
void run_detector(int argc, char **argv)
{
if (0 == strcmp(argv[2], "test")) test_detector(datacfg, cfg, weights,...);
else if (0 == strcmp(argv[2], "train")) train_detector(datacfg, cfg, weights, gpus,...);
else if (0 == strcmp(argv[2], "valid")) validate_detector(datacfg, cfg, weights, outfile,...);
else if (0 == strcmp(argv[2], "recall")) validate_detector_recall(datacfg, cfg, weights,...);
else if (0 == strcmp(argv[2], "map")) validate_detector_map(datacfg, cfg, weights, thresh, iou_thresh,...);
else if (0 == strcmp(argv[2], "calc_anchors")) calc_anchors(datacfg, num_of_clusters, width, height, show,...);
else printf(" There isn't such command: %s", argv[2]);
}
由于train相比于test和valid较复杂,涉及backword过程,这里我们的目的是要对darknet有一个全方位的把控,所以,我这里还是选择分析整个train过程,我们跟进train_detector()函数:
void train_detector(char *datacfg, char *cfgfile, char *weightfile,...)
{
// 读取data配置文件信息
list *options = read_data_cfg(datacfg);
// 构建网络, 为网络分配空间: 用多少块GPU, 就会构建多少个相同的网络(不使用GPU时, ngpus=1)
network* nets = (network*)xcalloc(ngpus, sizeof(network));
for (k = 0; k < ngpus; ++k) {
// 解析net.cfg文件, 构建并初始化网络
nets[k] = parse_network_cfg(cfgfile);
// 学习率和gpus关系, gpu数目越多, leraning_rate越大.
nets[k].learning_rate *= ngpus;
}
// 第一块显卡上的网络
network net = nets[0];
// 为什么要把网络参数存储到args参数列表里面, 这就和Darknet加载数据的机制有关.
load_args args = { 0 };
args.w = net.w; // 网络输入宽
args.h = net.h; // 网络输入高
args.c = net.c; // 网络输入通道
args.paths = paths; // 图片路径列表
args.n = imgs; // batchsize
args.m = plist->size; // 数据集总量
args.classes = classes; // 数据集类别数(不含背景)
args.flip = net.flip;
args.jitter = l.jitter; // 图像扰动值
args.resize = l.resize;
args.num_boxes = l.max_boxes; // 一张图片中的最大gt数
// 图片中每个gt标签长度(xywhc), 这里是6, 但实际上应该是5,
args.truth_size = l.truth_size;
net.num_boxes = args.num_boxes;
// train_images_num即为训练集的size
net.train_images_num = train_images_num;
args.d = &buffer; // 这个buffer用来不断获取data数据信息
args.type = DETECTION_DATA;
args.threads = 0; // 16 or 64, 调试时用单线程分析
// 数组增强相关
args.angle = net.angle;
args.gaussian_noise = net.gaussian_noise;
args.blur = net.blur;
args.mixup = net.mixup;
args.exposure = net.exposure;
args.saturation = net.saturation;
args.hue = net.hue;
args.letter_box = net.letter_box;
args.mosaic_bound = net.mosaic_bound;
args.contrastive_jit_flip = net.contrastive_jit_flip;
pthread_t load_thread = load_data(args); // 数据加载
while (get_current_iteration(net) < net.max_batches) {
// 阻塞, 主函数等待线程load_thread函数执行完毕, 再往下继续执行
pthread_join(load_thread, 0);
train = buffer; // 数据加载完毕放在buffer中.
// 为下一轮训练加载数据.
load_thread = load_data(args);
// train即为用于网络训练的数据, 这一段是核心
loss = train_network(net, train); // (核心代码<==)
}
}
从上面整个train过程可以看出,包含:解析data配置文件和网络配置文件,构建并初始化网络,加载数据,网络训练几个主要过程,在后续的代码分析中都会对这些过程进行详细解析。这里为了完整分析完网络的训练过程,我们跟进train_network(net, train)这句代码, 查看train_network()函数(位于src/network.c)中:
float train_network(network net, data d){
return train_network_waitkey(net, d, 0);}
float train_network_waitkey(network net, data d, int wait_key)
{
// 事实上对于图像检测而言,d.X.rows/net.batch=net.subdivision,因此恒有d.X.rows % net.batch
// == 0, 且下面的n就等于net.subdivision,(可以参看detector.c中的train_detector()),因此对于图像
// 检测而言, 下面三句略有冗余,但对于其他种情况(比如其他应用,非图像检测甚至非视觉情况),不知道是不是这
// 样。
assert(d.X.rows % net.batch == 0);
// 注意: 这里net.batch=cfg.batch(也即配置中写的batch)/net.subdivisions
// 因为在parse_network_cfg(cfgfile)时,有net.batch /= net.subvisions.
int batch = net.batch;
int n = d.X.rows / batch; // n = net.subvisions
float* X = (float*)xcalloc(batch * d.X.cols, sizeof(float)); // d.X.cols = h*w*c
float* y = (float*)xcalloc(batch * d.y.cols, sizeof(float));
int i;
float sum = 0;
for(i = 0; i < n; ++i){
// 从d中读取batch张图片到net.input中,进行训练:
// 第一个参数d包含了net.batch*net.subdivision张图片的数据,第二个参数batch即为每次循环
// 读入到net.input也即参与train_network_datum(),训练的图片张数,第三个参数为在d中的偏移量,
// 第四个参数为网络的输入数据,第五个参数为输入数据net.input对应的标签数据(gt).
get_next_batch(d, batch, i*batch, X, y);
net.current_subdivision = i;
// 训练网络: 本次训练的数据共有net.batch张图片, 这个batch = 配置文件中的batch/subdivisions
// 训练包括一次前向过程: 计算每一层网络的输出.
// 一次反向过程: 计算误差项(敏感度delta), 梯度(误差项与激活函数导数之积)、∂L/∂w、∂L/∂b等;
// X中仍然是包含batch(这个batch是被除net.subvisions的)张图片
float err = train_network_datum(net, X, y);
sum += err;
if(wait_key) wait_key_cv(5);
}
// 每跑一个batch大小的数据, cur_iteration都会+1, net->seen则为: net-
// >cur_iteration*batch*subdivs
(*net.cur_iteration) += 1;
update_network(net); // 更新参数
free(X);
free(y);
return (float)sum/(n*batch);
}
可以发现,train_network_waitkey()函数主要就是循环获取数据和网络训练(运行train_network_datum函数),最后进行一次性参数更新( 代码:update_network(net))。这里我们进一步跟进train_network_datum()函数(位于src/network.c),如下:
float train_network_datum(network net, float *x, float *y)
{
// 用network_state结构体记录网络训练过程中forward()和backbard()需要的信息.
network_state state={0};
*net.seen += net.batch; // 更新目前已经处理的图片数量: 每次处理一个batch, 故直接添加l.batch
state.index = 0; // 用于记录网络层编号
state.net = net; // 记录下当前的网络状态
state.input = x; // x中仍然包含batch张图片: batch * h * w * c
state.delta = 0; // 用于保存反向传播的梯度
state.truth = y; // ground_truth
state.train = 1; // 标记处于训练阶段
forward_network(net, state); // 前向传播
backward_network(net, state); // 反向传播
float error = get_network_cost(net); // 计算损失
return error;
}
可以发现,整个train_network_datum()函数,就是进行forward()和backward()过程,其中forward()函数如下所示(具体的注释已经写在代码中):
void forward_network(network net, network_state state)
{
// 网络的工作空间, 指的是所有层中占用运算空间最大的那个层的workspace_size,
// 因为实际上在GPU或CPU中某个时刻只有一个层在做前向或反向运算
state.workspace = net.workspace;
int i;
// 遍历所有层,从第一层到最后一层,逐层进行前向传播,网络共有net.n层
for(i = 0; i < net.n; ++i){
// 当前正在进行第i层的处理
state.index = i;
// 获取当前层
layer l = net.layers[i];
// 如果当前层的l.delta已经动态分配了内存, 则调用fill_cpu()函数将其所有元素初始化为0
if(l.delta && state.train){ // l.delta不为NULL, 且为训练状态.
// 第一个参数为l.delta的元素个数, 第二个参数为初始化值, 为0
scal_cpu(l.outputs * l.batch, 0, l.delta, 1); // l.delta[i*1] *= 0.
}
// double time = get_time_point();
// 前向传播: 完成当前层前向推理
l.forward(l, state); // 函数指针, 实现多态.
// 完成某一层的推理时, 置网络的输入为当前层的输出(这将成为下一层网络的输入), 注意此处更改的是
// state, 而非原始的net
// printf("%d - Predicted in %lf milli-seconds.\n", i, ((double)get_time_point()
// - time) / 1000);
state.input = l.output;// l.output记录网络某一层的输出结果, 网络某一层的输出即为下一层的输入
}
}
其backward()函数如下所示:
void backward_network(network net, network_state state)
{
int i;
// 在进行反向传播之前先保存一下原来的net信息
float *original_input = state.input;
float *original_delta = state.delta;
state.workspace = net.workspace;
for(i = net.n-1; i >= 0; --i){
state.index = i; // 标志参数, 当前网络的活跃层
if(i == 0){
state.input = original_input;
state.delta = original_delta;
}
else{
// 获取net.layers[i]的上一层net.layer[i-1].
layer prev = net.layers[i-1];
// prev.output也即a_l-1, 上一层的输出值a_l-1作为当前层的输入, 下面l.backward()会用到
state.input = prev.output;
// 上一层的敏感度图δ_l-1, 敏感度也即误差项.
state.delta = prev.delta;
}
// 置网络当前活跃层为当前层, 即第i层
layer l = net.layers[i];
if (l.stopbackward) break;
if (l.onlyforward) continue;
// 反向计算第i层的敏感度图、权重及偏置更新值,并更新权重、偏置(同时会计算上一层(i-1)的敏感度图,
// 存储在net.delta中,这里一定要记住还差一个环节: 乘上上一层输出对加权输入的导数,也即上一层激活函
// 数对加权输入的导数)。
l.backward(l, state);
}
}
关于CNN的前向传播和反向传播,这里推荐一个写的非常好的博客,会对理解darknet代码有很好的帮助。darknet的实现也是来自于博客中提及到的理论:https://www.zybuluo.com/hanbingtao/note/485480
本次解读分析就先到这里了,下一个解读主要分析darknet是如果解析网络配置文件并初始化网络的。
由于本人水平有限,若有错误之处,麻烦联系我及时指正!谢谢!微信:13521560705,加我请备注:darknet。
推荐阅读
mmdetection最小复刻版(六):FCOS深入可视化分析
mmdetection最小复刻版(五):yolov5转化内幕
机器学习算法工程师
一个用心的公众号
