
系统总出故障怎么办,或许你该学学稳定性建设!

说到系统稳定性,不知道大家会想起什么?我想大多数人会觉得这个词挺虚的,不知道系统稳定性指的是什么。
一年前的我看到这个词,也是类似于这样的感受,大概只知道要消除单点、做好监控报警,但却并没有一个体系化的方法论。
经过一段时间的摸索,我对系统稳定性有了较为体系化的认识,于是迫不及待地希望和大家一起分享。所以今天,就让我跟大家简单聊聊系统稳定性建设这个话题吧!
何谓稳定性?
系统稳定性,从字面上来看,就是让系统尽可能稳定,不要出问题。但业务是变化的,系统肯定也是一直变化的,有可能新加了个功能就把系统搞挂了,也有可能突然业务流量暴增把系统搞挂了。所以,要保障系统稳定性可谓非常之难。但即使再难,也还是得去做,但到底怎么做呢?
我们要保障系统稳定性,那就需要知道哪些因素可能会造成系统不稳定。我自己来了一个头脑风暴,把所有可能造成系统不稳定的因素整理一下,下面是我梳理的会造成系统不稳定的部分因素:
未测试需求直接上线 上线的需求产品不知道 上线的新需求有 bug 频繁发布需求 发布紧急需求 上线后没有线上验证 系统设计方案存在缺陷 系统代码实现存在缺陷 漏测了某个功能 上线时操作失误 下游服务挂了 网络中断导致调用失败 上游调用流量突增,冲垮服务 应用服务器内存溢出 OOM 应用服务器 CPU 100% 数据库主从延迟了 数据库主库挂了 Kafka 消息挤压了 Redis 响应缓慢 第三方服务商挂了 潜在的黑客攻击 潜在的系统漏洞
是不是感觉特别多,看起来有点晕了?别怕,其实我们可以将所有的不稳定因素根据时间维度,将其分为三大类:上线前、上线时、上线后。
上线前的不稳定因素。这块指的是需求上线前的所有内容,包括需求评审、技术方案设计、代码编写、功能测试等等。 上线时的不稳定因素。 这块指的是上线时可能的不稳定因素,包括操作失误、某个功能有问题导致线上出问题等等。 上线后的不稳定因素。这块指的是需求上线后,有可能出现的各种各样的问题,例如中间件挂了、网络挂了等等。
我们现在已经知道哪个环节可能会出什么问题,那么接下来就是针对每个环境做一些特定的动作,从而提高系统稳定性了!
上线前
很多时候我们都以为系统稳定只是线上运行稳定就好了,但事实上需求研发流程是否规范,也会极大地影响到系统的稳定性。
试想一下,如果谁都可以随便提需求、做的功能没有做方案设计、谁都可以直接操作线上服务器,那么这样的系统服务能够稳定得了吗?所以说,需求上线前的过程也是影响系统稳定性的重大因素。
在我看来,在上线前这个阶段,主要有三大块非常重要的稳定性建设内容,分别是:
开发流程规范 发布流程规范 高可用设计

研发流程规范
研发流程规范,指的是一个需求从提出到完成的整个过程应该是怎样流转的。一般的需求研发流程包括:产品提出需求、技术预研、需求评审、技术方案设计、测试用例评审、技术方案评审、测试用例评审、需求开发、CodeReview、需求测试。不同公司根据情况会有所调整,但大差不差。
在这个流程中,与研发相关的几个比较重要的节点是:技术方案设计及评审、测试用例评审及评审、需求开发、代码测试覆盖率、CodeReview。我们上面提到的几个影响稳定性的因素,就是因为没有做好这几个节点的工作导致的,包括:
未测试需求直接上线 上线的需求产品不知道 上线的新需求有 bug 上线后没有线上验证 系统设计方案存在缺陷 系统代码实现存在缺陷
如果能够处理好上述几个节点,那么就能够极大地降低研发流程导致的问题。这里每个节点都有很深的学问,这里就不展开讲了,我们主要说个思路。
发布流程规范
发布流程规范主要是为了控制发布权限以及频率的问题。
在项目初始,为了快速响应业务,一般权限控制都很松,很多人都可以进行线上服务的发布。但随着业务越来越多、流量越来越大,相对应的故障也越来越多,到了某个时候就需要对权限做管控,并且需要对需求的发布频率做控制。
对于需求发布流程来说,一般有几种发布方式,分别是:Release Train 方式、零散发布方式。Release Train 意思是固定时间窗口发布,例如每周四发布一次。如果无法赶上这次发布时间,那么就需要等到下次发布窗口。
零散发布方式,指的是有需要就发布,不做发布时间控制。但这种方式一般只在项目初期发挥作用,后期一般都会收紧。
除此之外,发布流程中都会设有紧急发布流程,即如果某个需求特别重要,或者有紧急漏洞需要修复,那么可以通过该流程来紧急修复,从而避免因未到时间窗口而对业务产生影响。
但一般来说,紧急发布流程都比较麻烦,除非迫不得已不然不要审批通过,不然 Release Train 方式可能会退化成零散发布方式。
高可用设计
高可用设计指的是为了让系统在各种异常情况下都能正常工作,从而使得系统更加稳定。其实这块应该是属于研发流程规范中的技术方案设计的,但研发流程规范更加注重于规范,高可用设计更加注重高可用。
另外,也由于高可用设计是非常重要,因此独立拿出来作为一块来说说。对于高可用设计来说,一般可分为两大块,分别是:服务治理和容灾设计。
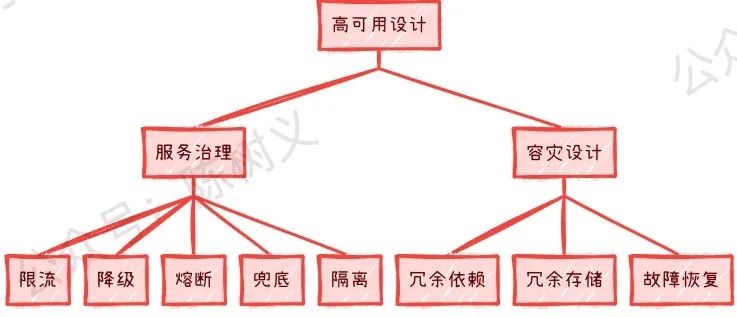
服务治理就包括了限流、降级、熔断、兜底、隔离等,这一些考虑点都是为了让系统在某些特殊情况下,都能稳定工作。例如限流是为了在上游请求量太大的时候,系统不至于被巨大的流量击垮,还可以正常提供服务。
容灾设计应该说是更加高端点的设计了,指的是当下游系、第三方、中间件挂了,如何保证系统还能正常运行?可以说容灾设计比起服务治理,其面临的情况更加糟糕。
例如支付系统最终是通过 A 服务商进行支付的,如果 A 服务商突然挂了,那我们的支付系统是不是就挂了?那有什么办法可以在这种情况(灾难)发生的时候,让我们的系统还能够正常提供服务呢?这就是容灾设计需要做的事情了。
上线时
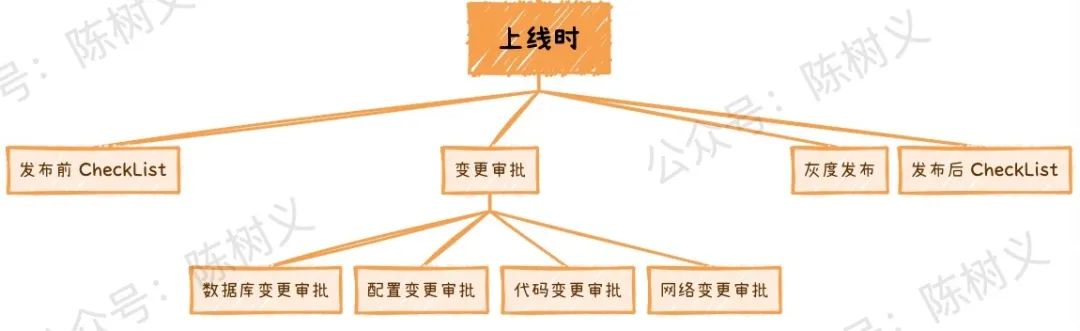
上线时这个阶段,主要是确保功能按照原先设计的方案进行部署,这个阶段主要是确保规范操作,避免失误,因此可以制定相关的 CheckList 以及变更审批。
其次,为了避免还可能存在未发现的功能缺陷,有时候还可以使用灰度发布降低风险。在这个阶段能做的一些稳定性建设如下图所示。
上线后
当系统成功上线后,很多小伙伴以为工作就结束了,但实际上我们还有不少工作可以做。根据我的经验,在上线后我们能做的稳定性建设包括:
监控报警 故障管理 紧急处理预案 容灾演练 案例学习 全链路压测

监控报警,指的是我们需要对应用做好运行数据的收集,监控好系统的运行状态。当系统状态异常时,我们需要及时地发现并报警,从而让研发人员快速地解决问题。
一般来说,监控报警分为系统级别的监控报警和业务级别的监控报警。系统级别的监控报警包括 CPU、内存、磁盘等服务器资源的监控,而业务级别的报警则需要根据业务情况自行定义。
故障管理,就是当发生故障时,我们需要遵循的整套处理规范。团队小的时候可能无所谓,但是当团队大了的时候,我们就需要统一大家的故障处理流程,从而可以更快速地解决故障。此外,在故障解决完成之后还需要进行复盘,产出对应的故障报告。
Case Study 机制指的是定期学习其他团队的高可用或者线上故障进行学习,从而提高团队的系统设计能力,避免踩坑。
容灾演练,其实就是模拟某些中间件或者服务故障,然后看看系统是否能按照之前设计的高可用方案实施。
容灾演练是提升系统稳定性的一把利器,很多时候即使我们设计得很完美,但实际上却没发挥作用,究其根本就是没有实践过。是驴是马,得拉出来溜溜才知道。
紧急处理预案,简单就是要想到各种可能发现的情况,然后做好预案。之后结合容灾演练不断进行优化,从而形成一套很好的处理预案。这样当线上发生类似故障时,就可以轻松应对了。
全链路压测,指的是对整个链路进行压测。不同公司可能会采用不同的方案,有些会直接在线上进行压测,然后用流量标记的方式识别测试流量。
有些则是进行流量录制,之后重新搭建一套与线上非常类似的系统进行压测。一般来说,第一种效果肯定会更好,成本也更低,但是对研发人员要求也更高,风险也更大。
总结
今天我们简单地从上线前、上线时、上线后去探讨了如何做稳定性建设,其中每一块都可以展开来讲很多内容。
例如监控报警这块,那我们应该监控系统的哪些指标?其实这些都是有一些成熟的方案了,例如要监控 TP90、响应延迟、调用延时、消息处理延时等。
但出于篇幅原因,我们今天只是蜻蜓点水,点到为止,后续继续再慢慢不断完善,纯当抛砖引玉吧。最后,丢一个思维导图,作为今天文章的结尾。

好了,这就是今天分享的全部内容了。
往 期 推 荐
4、为什么国外JetBrains做 IDE 就可以养活自己,国内不行?区别在哪?
点分享
点收藏
点点赞
点在看




