
如何写出令人惊叹的Python类
我身边有搞机器学习的,也有数据科学家,Python 是他们的首选语言。然而,他们并非每个都是经验丰富的 Python 开发人员,他们也不太可能掌握 Python 提供的所有优秀功能。这当然是可以理解的,但同时也是不幸的。为什么?因为了解语言的细节需要编写代码......
这就是为什么我想为提升 Python 技能的人提供一些帮助,这样你就可以编写更多出色的代码,也许会给您的伙伴或同事留下深刻印象,并从中获得更多乐趣!具体来说,在这篇文章中,我想谈谈如何使用 Python 中的魔术方法,写出令人惊叹的 class,让我们开始吧。
什么是魔术方法
魔术方法首先是方法,是属于类的函数。它们既可以是实例方法,也可以是类方法。你可以轻松识别它们,因为它们都以双下划线开头和结尾,即它们都看起来像 __actual_name__。
重要的是,魔术方法不可以直接调用!当然,你可以这样做并写一些类似 YourClass().__actual_name__() 的东西,但请不要直接调用。
那么魔术方法是如何调用的呢?它们会在适当的时候被调用,比如,调用 str(YourClass()) 将调用魔术方法 __str__ 或 YourClass() + YourClass() 将调用 __add__,如果你已经实现了这两个魔术方法。
那么,魔法方法有什么用?它让我们能够编写可与 python 内置方法一起使用的类,这样写出的代码更易读和更少的冗余。
为了强调魔术方法的有用性,并了解在进行机器学习或数据科学时如何从使用它们中受益,让我们举一个具体的例子。
实例:自定义范围的 datetime 类
下面的代码展示了如何使用魔术方法编写类似于内置 range 函数的 DateTimeRange 类,代码如下:
from datetime import datetime, timedelta
from typing import Iterable
from math import ceil
class DateTimeRange:
def __init__(self, start: datetime, end_:datetime, step:timedelta = timedelta(seconds=1)):
self._start = start
self._end = end_
self._step = step
def __iter__(self) -> Iterable[datetime]:
point = self._start
while point < self._end:
yield point
point += self._step
def __len__(self) -> int:
return ceil((self._end - self._start) / self._step)
def __contains__(self, item: datetime) -> bool:
mod = divmod(item - self._start, self._step) # divmod return the tuple (x//y, x%y). Invariant: div*y + mod == x.
return item >= self._start and item < self._end and mod[1] == timedelta(0)
def __getitem__(self, item: int) -> datetime:
n_steps = item if item >= 0 else len(self) + item
return_value = self._start + n_steps * self._step
if return_value not in self:
raise IndexError()
return return_value
def __str__(self):
return f"Datetime Range [{self._start}, {self._end}) with step {self._step}"
def main():
my_range = DateTimeRange(datetime(2021,1,1), datetime(2021,12,1), timedelta(days=12))
print(my_range)
print(f"{len(my_range) == len(list(my_range)) = }")
print(f"{my_range[-2] in my_range = }")
print(f"{my_range[2] + timedelta(seconds=12) in my_range = }")
for r in my_range:
print(r)
#do_something(r)
if __name__ == '__main__':
main()
先看下运行结果:
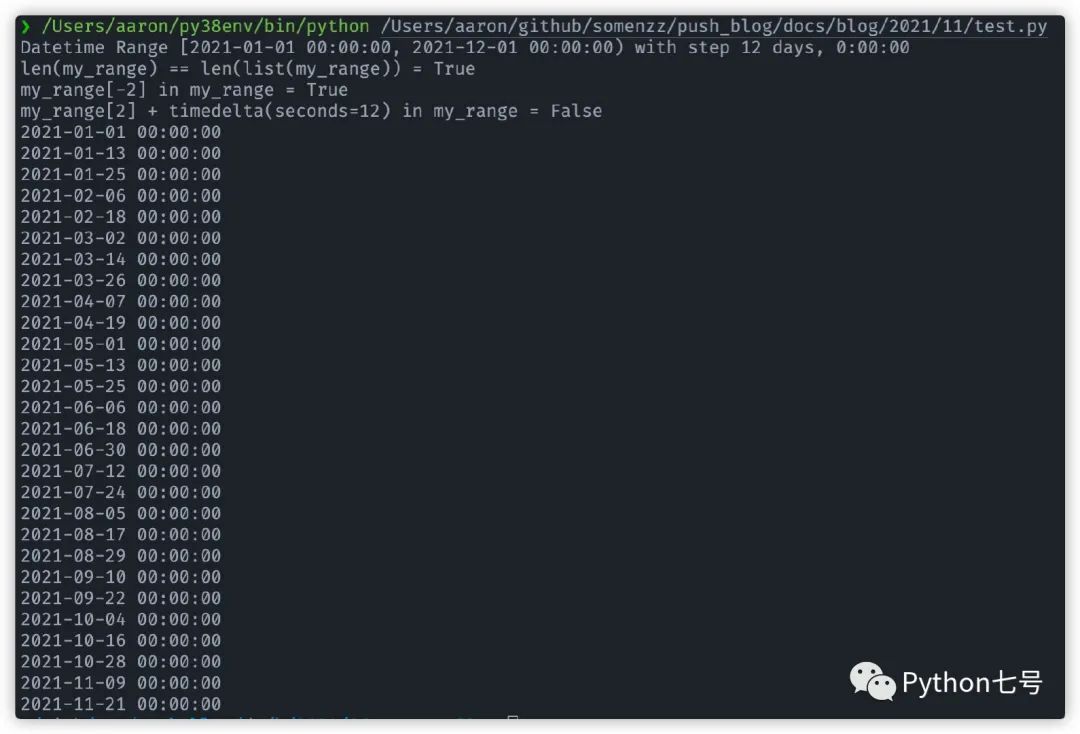
看到运行结果,你也许可以更快的理解类 DateTimeRange 的作用,代码有点多,不过别担心,我会解释。
总的来说,上述代码实现了六种不同的魔法方法:
1、__init__ 方法。你肯定知道,此方法主要用于初始化您的类的实例属性。在这里,我们将范围类的开始和结束与步长一起传给 DateTimeRange。
2、__iter__ 方法。for 循环或 list(DateTimeRange()) 时会调用。这可能是最重要的一个,因为它生成了我们日期时间范围内的所有元素。这个函数是一个所谓的生成器函数,它一次创建一个元素,将它交给调用者,并允许调用者处理它。它会这样做,直到到达范围的末尾。在查看 yield 关键字时,您可以轻松识别生成器函数。此语句暂停函数保存其所有状态,然后在连续调用时从那里继续。这允许您一次使用一个元素并使用它,而无需您将每个元素都放在内存中。
当范围比较大时,将所有内容都放在内存中会变得非常占用内存。例如,执行 list(DateTimeRange(datetime(1900,1,1), datetime(2000,1,1)) 时会将 3184617600 个日期时间放入内存。太大了,然而 ,使用生成器您可以轻松地一一处理这些元素。
3、现在你已经看到它不是列表或元组。然而,为了处理这个 DateTimeRange 类,就像它是一个列表或元组一样,我添加了另外三个神奇的方法,即 __len__ 、 __contains__ 和 __getitem__ 。
使用 __len__ ,您可以通过调用 len(my_range) 找出属于您的范围的元素数量。例如,当迭代所有元素并想知道已经从所有可用元素中处理了多少元素时,这会变得非常有用。它也可能告诉你,嘿,我要处理很多数据,请喝杯咖啡。
使用 __contains__,您可以使用 my_range 中的内置语法元素检查某个元素是否属于您的范围。给定实现的好处在于,这是使用纯数学完成的,无需将给定元素与范围内的所有元素进行比较。这意味着检查元素是否在您的范围内是一个恒定时间操作,不依赖于实际范围实例的大小。同样,这对于我们在处理数据时经常看到的大范围会变得很方便。
使用 __getitem__ 您可以使用索引语法从对象中检索条目。因此,可以通过 my_range[-1] 获取我们范围的最后一个元素。一般来说,使用 __getitem__ 可以编写非常干净和可读的界面。
4、__str__ 方法的作用是将类的实例转换为字符串。将实例转换为字符串时自动调用该方法,例如调用 print(my_range) 或 str(my_range) 时就会调用__str__。
最后的话
本文分享了如何通过魔法方法编写一个非常优雅的类,魔术方法可在 Python 内置的函数或操作中自动调用,可以让我们编写出可读性、易用性更好的类,就像本文中的 DateTimeRange。
如果觉得有帮助,还请点赞、转发、在看,感谢你的支持。