
用雪花 id 和 uuid 做 MySQL 主键,被领导怼了
点击关注公众号:互联网架构师,后台回复 2T获取2TB学习资源!
上一篇:2T架构师学习资料干货分享
MySQL和程序实例
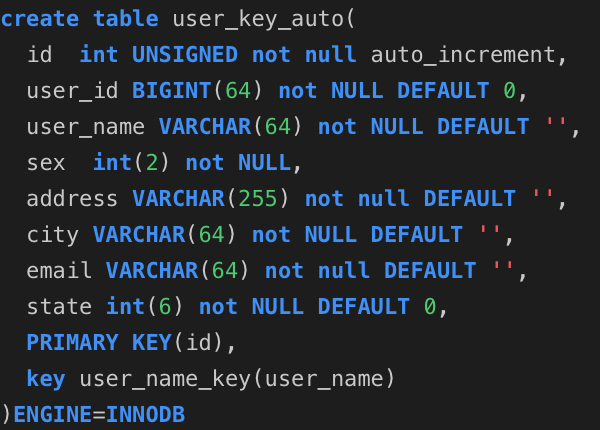
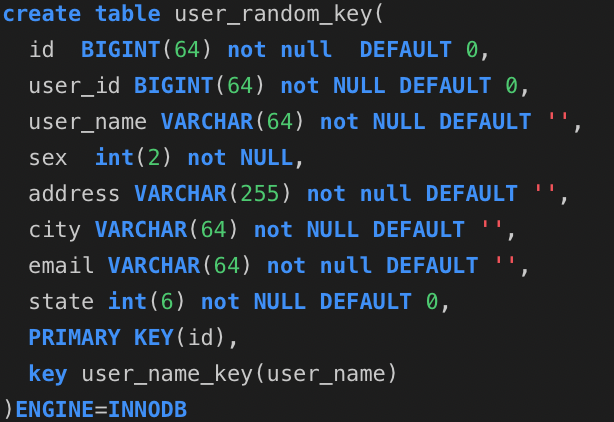
1、要说明这个问题,我们首先来建立三张表

2、光有理论不行,直接上程序,使用spring的jdbcTemplate来实现增查测试
技术框架:
springboot+jdbcTemplate+junit+hutool,
程序的原理就是连接自己的测试数据库,然后在相同的环境下写入同等数量的数据,来分析一下insert插入的时间来进行综合其效率,为了做到最真实的效果,所有的数据采用随机生成,比如名字、邮箱、地址都是随机生成,程序已上传自gitee,地址链接在文底。
package com.wyq.mysqldemo;import cn.hutool.core.collection.CollectionUtil;import com.wyq.mysqldemo.databaseobject.UserKeyAuto;import com.wyq.mysqldemo.databaseobject.UserKeyRandom;import com.wyq.mysqldemo.databaseobject.UserKeyUUID;import com.wyq.mysqldemo.diffkeytest.AutoKeyTableService;import com.wyq.mysqldemo.diffkeytest.RandomKeyTableService;import com.wyq.mysqldemo.diffkeytest.UUIDKeyTableService;import com.wyq.mysqldemo.util.JdbcTemplateService;import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.util.StopWatch;import java.util.List;@SpringBootTestclass MysqlDemoApplicationTests {@Autowiredprivate JdbcTemplateService jdbcTemplateService;@Autowiredprivate AutoKeyTableService autoKeyTableService;@Autowiredprivate UUIDKeyTableService uuidKeyTableService;@Autowiredprivate RandomKeyTableService randomKeyTableService;@Testvoid testDBTime() {StopWatch stopwatch = new StopWatch("执行sql时间消耗");/*** auto_increment key任务*/final String insertSql = "INSERT INTO user_key_auto(user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?)";List<UserKeyAuto> insertData = autoKeyTableService.getInsertData();stopwatch.start("自动生成key表任务开始");long start1 = System.currentTimeMillis();if (CollectionUtil.isNotEmpty(insertData)) {boolean insertResult = jdbcTemplateService.insert(insertSql, insertData, false);System.out.println(insertResult);}long end1 = System.currentTimeMillis();System.out.println("auto key消耗的时间:" + (end1 - start1));stopwatch.stop();/*** uudID的key*/final String insertSql2 = "INSERT INTO user_uuid(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";List<UserKeyUUID> insertData2 = uuidKeyTableService.getInsertData();stopwatch.start("UUID的key表任务开始");long begin = System.currentTimeMillis();if (CollectionUtil.isNotEmpty(insertData)) {boolean insertResult = jdbcTemplateService.insert(insertSql2, insertData2, true);System.out.println(insertResult);}long over = System.currentTimeMillis();System.out.println("UUID key消耗的时间:" + (over - begin));stopwatch.stop();/*** 随机的long值key*/final String insertSql3 = "INSERT INTO user_random_key(id,user_id,user_name,sex,address,city,email,state) VALUES(?,?,?,?,?,?,?,?)";List<UserKeyRandom> insertData3 = randomKeyTableService.getInsertData();stopwatch.start("随机的long值key表任务开始");Long start = System.currentTimeMillis();if (CollectionUtil.isNotEmpty(insertData)) {boolean insertResult = jdbcTemplateService.insert(insertSql3, insertData3, true);System.out.println(insertResult);}Long end = System.currentTimeMillis();System.out.println("随机key任务消耗时间:" + (end - start));stopwatch.stop();String result = stopwatch.prettyPrint();System.out.println(result);}}
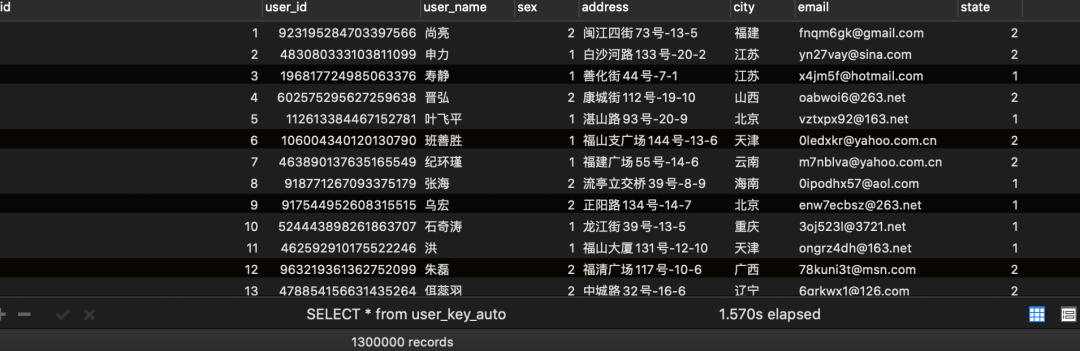
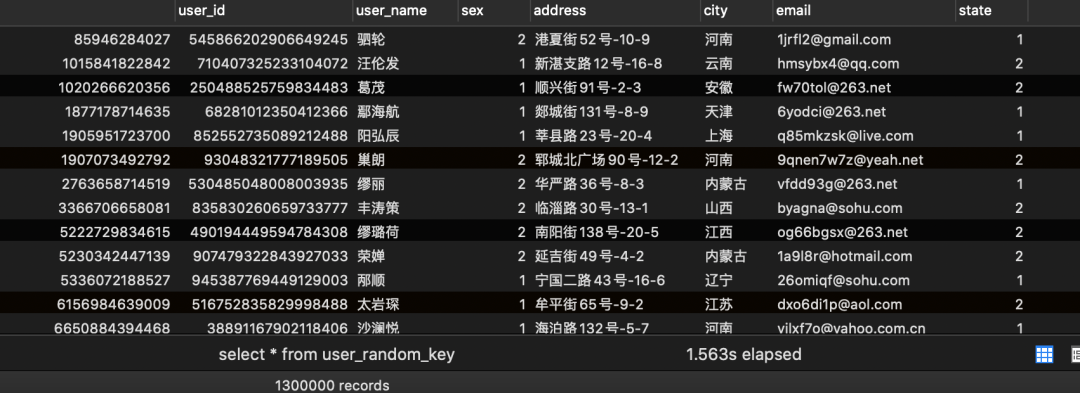
3、程序写入结果
4、效率测试结果
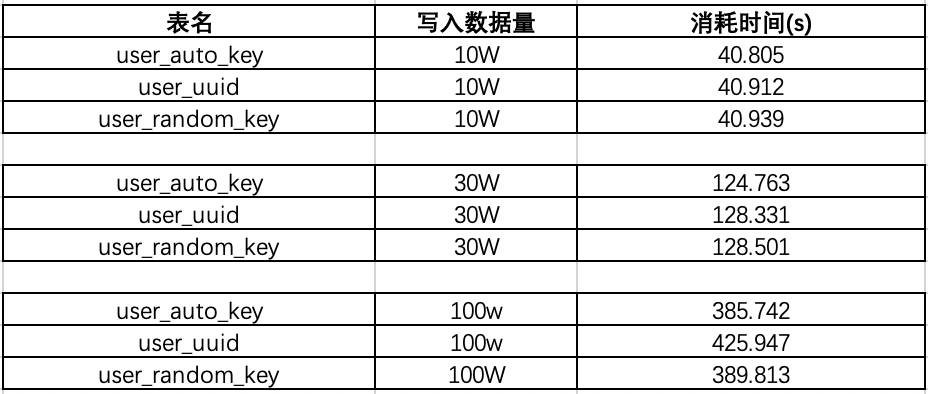
在已有数据量为130W的时候:我们再来测试一下插入10w数据,看看会有什么结果:

使用uuid和自增id的索引结构对比
1、使用自增id的内部结构
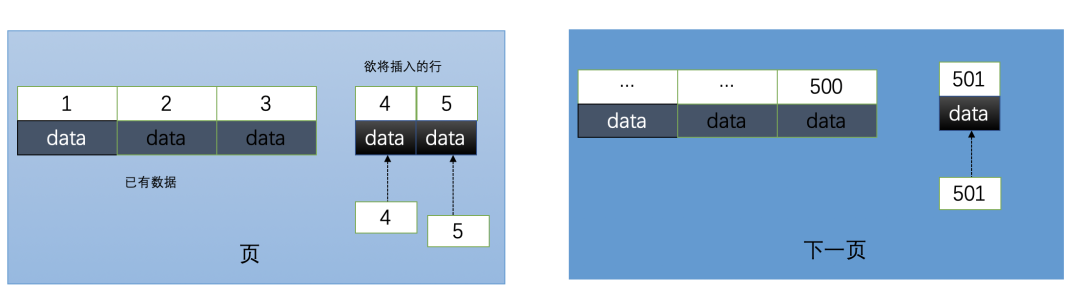
自增的主键的值是顺序的,所以Innodb把每一条记录都存储在一条记录的后面。当达到页面的最大填充因子时候(innodb默认的最大填充因子是页大小的15/16,会留出1/16的空间留作以后的 修改):
2、使用uuid的索引内部结构
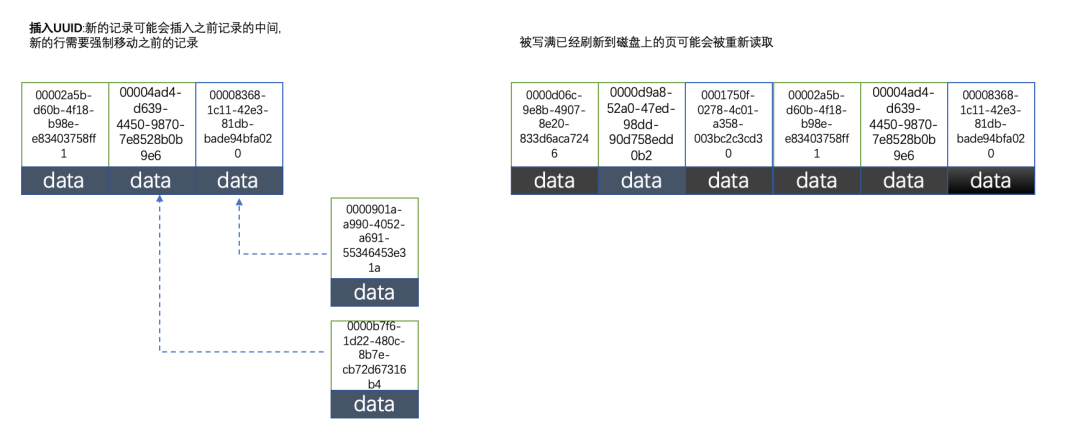
因为uuid相对顺序的自增id来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以innodb无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
结论:使用innodb应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行
3、使用自增id的缺点
那么使用自增的id就完全没有坏处了吗?并不是,自增id也会存在以下几点问题:
①别人一旦爬取你的数据库,就可以根据数据库的自增id获取到你的业务增长信息,很容易分析出你的经营情况
②对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
③Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失
附:
Auto_increment的锁争抢问题,如果要改善需要调优innodb_autoinc_lock_mode的配置
总结
正文结束
推荐阅读 ↓↓↓
1.JetBrains 如何看待自己的软件在中国被频繁破解?

正文结束
1.JetBrains 如何看待自己的软件在中国被频繁破解?