来自:JAVA高级程序员
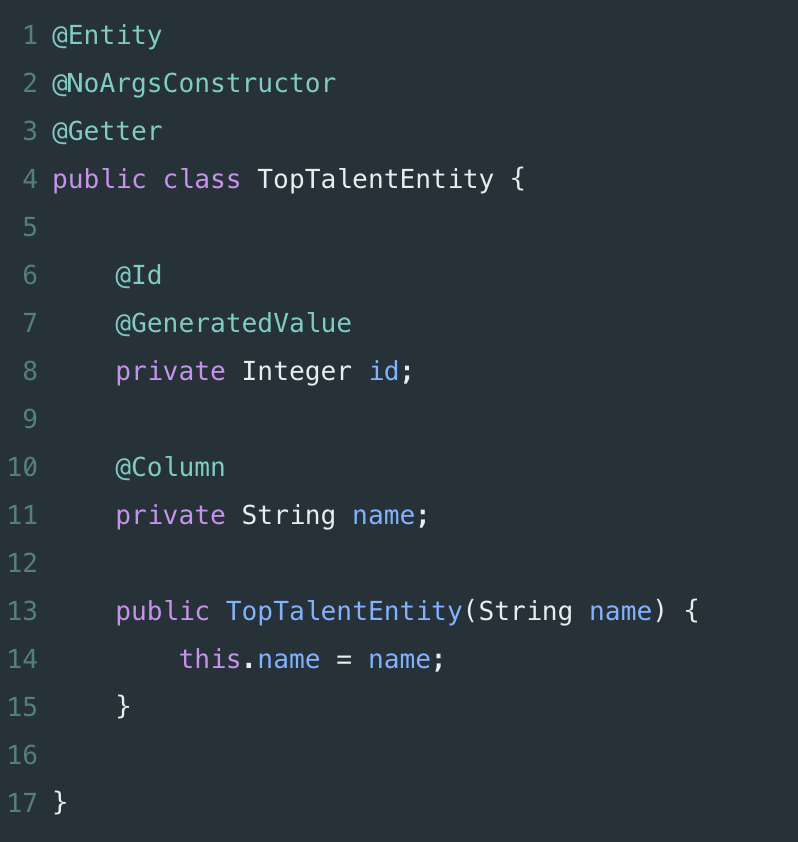
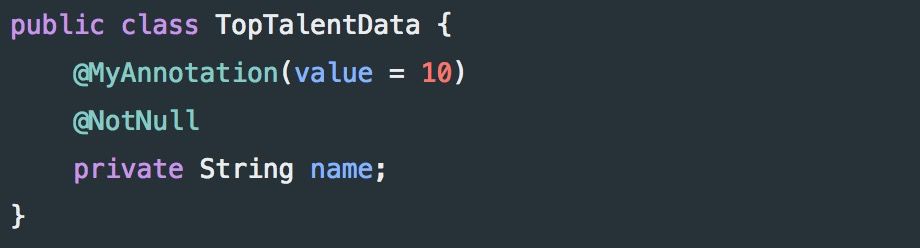
我们正在解决这个常见错误,是因为 “非我所创” 综合症在软件开发领域很是常见。症状包括经常重写一些常见的代码,很多开发人员都有这种症状。虽然理解特定库的内部结构及其实现,在很大程度上是好的并且很有必要的(也可以是一个很好的学习过程),但作为软件工程师,不断地处理相同的底层实现细节对个人的开发生涯是有害的。像 Spring 这种抽象框架的存在是有原因的,它将你从重复地手工劳作中解放出来,并允许你专注于更高层次的细节 —— 领域对象和业务逻辑。因此,接受抽象。下次面对特定问题时,首先进行快速搜索,确定解决该问题的库是否已被集成到 Spring 中;现在,你可能找到一个合适的现成解决方案。比如,一个很有用的库,在本文的其他部分,我将在示例中使用 Project Lombok 注解。Lombok 被用作样板代码生成器,希望懒惰的开发人员在熟悉这个库时不会遇到问题。举个例子,看看使用 Lombok 的 “标准 Java Bean” 是什么样子的:但是,请注意,如果你打算在 IDE 中使用 Lombok,很可能需要安装一个插件,可在 此处 找到 Intellij IDEA 版本的插件。公开你的内部结构,从来都不是一个好主意,因为它在服务设计中造成了不灵活性,从而促进了不好的编码实践。“泄露” 的内部机制表现为使数据库结构可以从某些 API 端点访问。例如,下面的 POJO(“Plain Old Java Object”)类表示数据库中的一个表:假设,存在一个端点,他需要访问 TopTalentEntity 数据。返回 TopTalentEntity 实例可能很诱人,但更灵活的解决方案是创建一个新的类来表示 API 端点上的 TopTalentEntity 数据。这样,对数据库后端进行更改将不需要在服务层进行任何额外的更改。考虑下,在TopTalentEntity 中添加一个 “password” 字段来存储数据库中用户密码的 Hash 值 —— 如果没有 TopTalentData 之类的连接器,忘记更改服务前端,将会意外地暴露一些不必要的秘密信息。
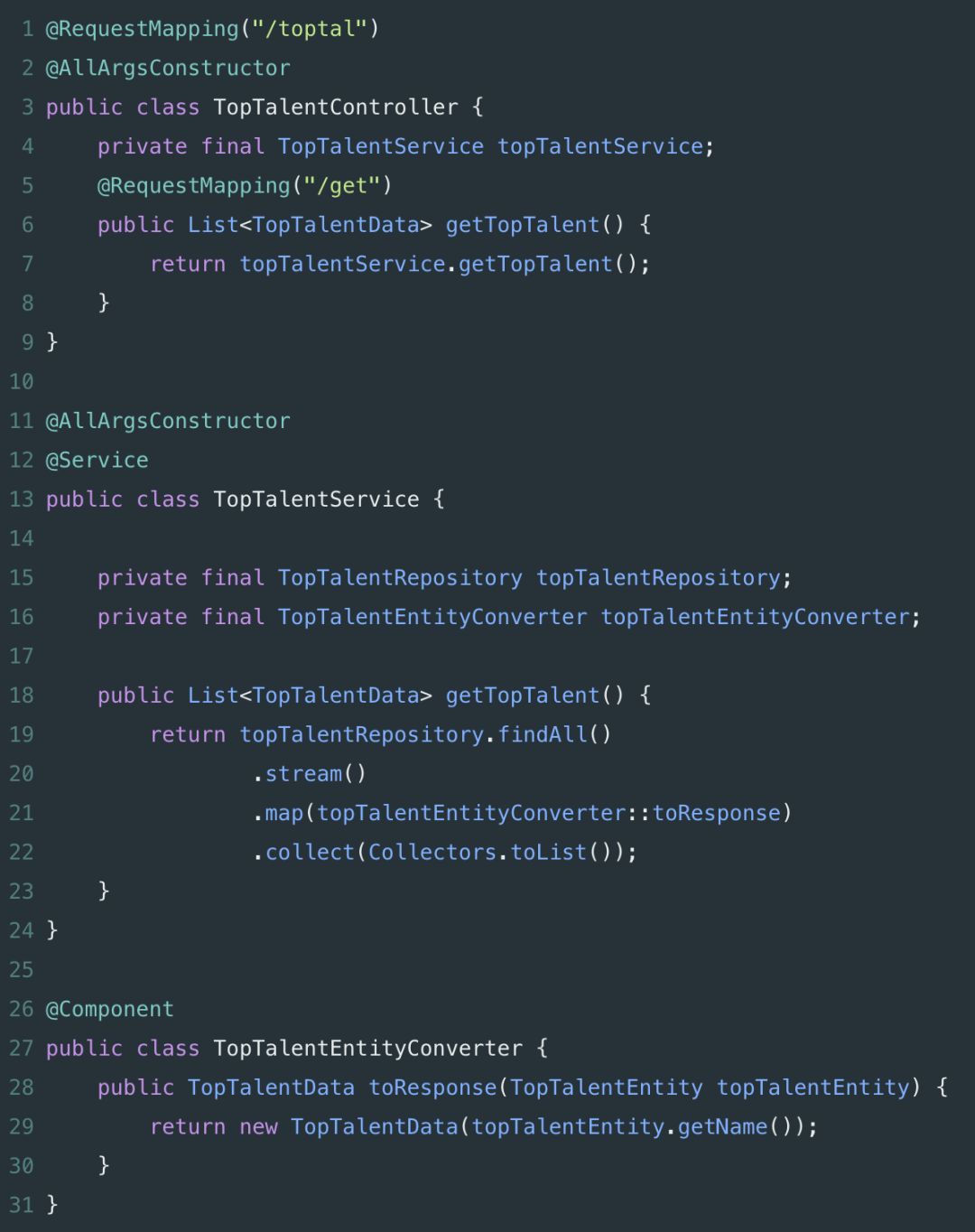
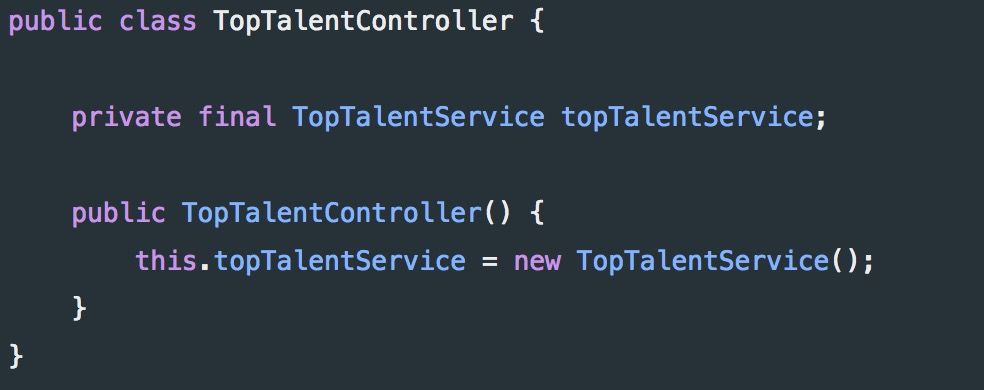
随着程序规模的增长,逐渐地,代码组织成为一个越来越重要的问题。讽刺的是,大多数好的软件工程原则开始在规模上崩溃 —— 特别是在没有太多考虑程序体系结构设计的情况下。开发人员最常犯的一个错误就是混淆代码关注点,这很容易做到!通常,打破 关注点分离 的是将新功能简单地 “倒” 在现有类中。当然,这是一个很好的短期解决方案(对于初学者来说,它需要更少的输入),但它也不可避免地会在将来成为一个问题,无论是在测试期间、维护期间还是介于两者之间。考虑下下面的控制器,它将从数据库返回 TopTalentData。起初,这段代码似乎没什么特别的问题;它提供了一个从 TopTalentEntity 实例检索出来的TopTalentData 的 List。然而,仔细观察下,我们可以看到 TopTalentController 实际上在此做了些事情;也就是说,它将请求映射到特定端点,从数据库检索数据,并将从 TopTalentRepository 接收的实体转换为另一种格式。一个“更干净” 的解决方案是将这些关注点分离到他们自己的类中。这种层次结构的另一个优点是,它允许我们通过检查类名来确定将功能驻留在何处。此外,在测试期间,如果需要,我们可以很容易地用模拟实现来替换任何类。
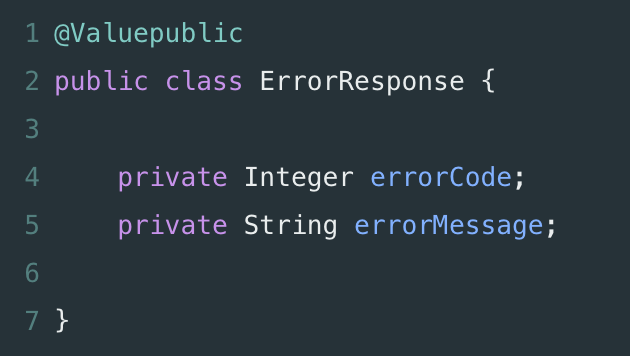
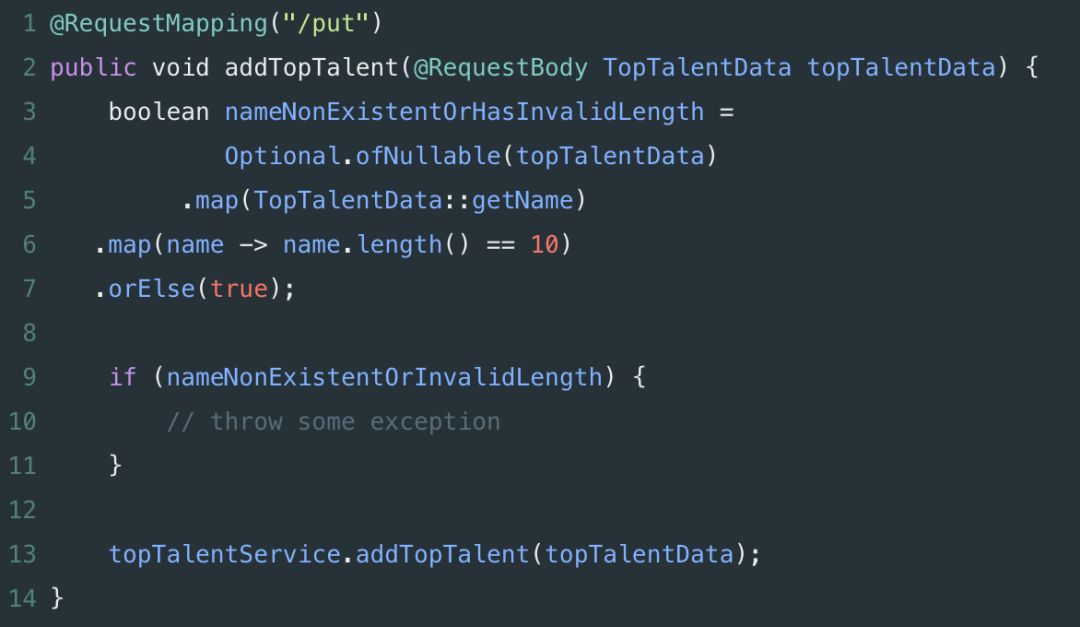
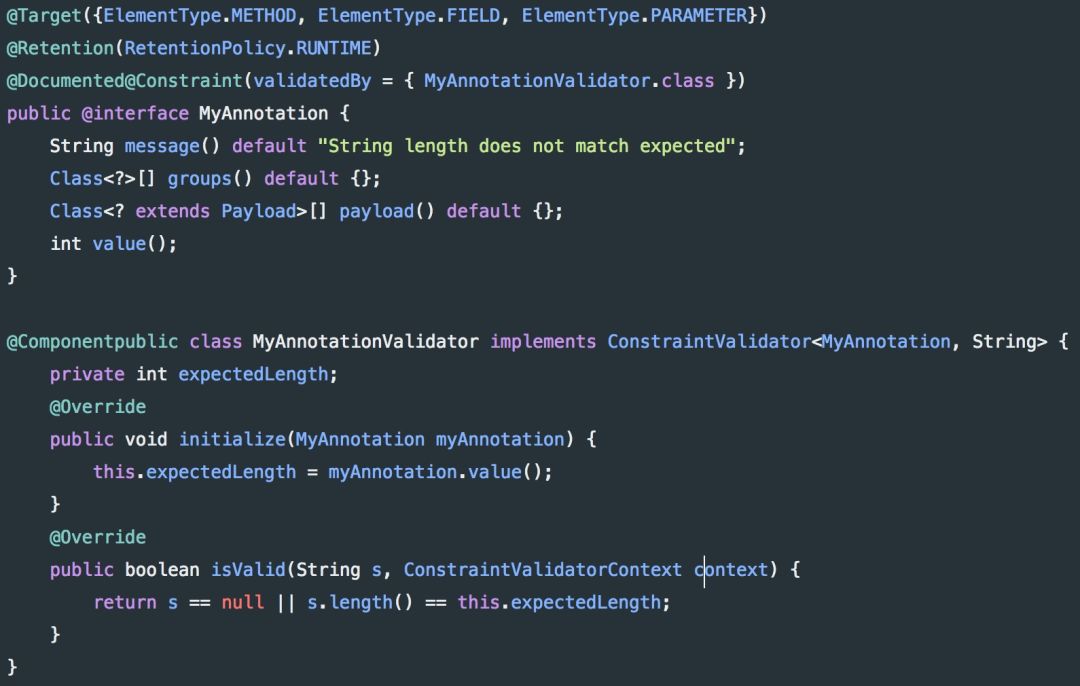
一致性的主题并非是 Spring(或 Java)所独有的,但仍然是处理 Spring 项目时需要考虑的一个重要方面。虽然编码风格可能存在争议(通常团队或整个公司内部已达成一致),但拥有一个共同的标准最终会极大地提高生产力。对多人团队尤为如此;一致性允许交流发生,而不需要花费很多资源在手把手交接上,也不需要就不同类的职责提供冗长的解释。考虑一个包含各种配置文件、服务和控制器的 Spring 项目。在命名时保持语义上的一致性,可以创建一个易于搜索的结构,任何新的开发人员都可以按照自己的方式管理代码;例如,将 Config 后缀添加到配置类,服务层以 Service 结尾,以及控制器用 Controller 结尾。与一致性主题密切相关,服务器端的错误处理值得特别强调。如果你曾经不得不处理编写很差的 API 的异常响应,那你可能知道原因 —— 正确解析异常会是一件痛苦的事情,而确定这些异常最初发生的原因则更为痛苦。作为一名 API 开发者,理想情况下你希望覆盖所有面向用户的端点,并将他们转换为常见的错误格式。这通常意味着有一个通用的错误代码和描述,而不是逃避解决问题:a) 返回一个 “500 Internal Server Error”信息。b) 直接返回异常的堆栈信息给用户。(实际上,这些都应该不惜一切代价地去避免,因为除了客户端难以处理以外,它还暴露了你的内部信息)。与此类似的事情在大多数流行的 API 中也经常遇到,由于可以容易且系统地记录,效果往往很不错。将异常转换为这种格式可以通过向方法提供 @ExceptionHandler 注解来完成(注解案例可见于第六章)。不管是桌面应用还是 Web 应用,无论是 Spring 还是 No Spring,多线程都是很难破解的。由并行执行程序所引起的问题是令人毛骨悚然且难以捉摸的,而且常常难以调试 —— 实际上,由于问题的本质,一旦你意识到你正在处理一个并行执行问题,你可能就不得不完全放弃调试器了,并 “手动” 检查代码,直到找到根本上的错误原因。不幸的是,这类问题并没有千篇一律的解决方案;根据具体场景来评估情况,然后从你认为最好的角度来解决问题。当然,理想情况下,你也希望完全避免多线程错误。同样,不存在那种一刀切的方法,但这有一些调试和防止多线程错误的实际考虑因素:首先,牢记 “全局状态” 问题。如果你正创建一个多线程应用,那么应该密切关注任何可能全局修改的内容,如果可能的话,将他们全部删掉。如果某个全局变量有必须保持可修改的原因,请仔细使用 synchronization,并对程序性能进行跟踪,以确定没有因为新引入的等待时间而导致系统性能降低。这点直接来自于 函数式编程,并且适用于 OOP,声明应该避免类和状态的改变。简而言之,这意味着放弃 setter 方法,并在所有模型类上拥有私有的 final 字段。这样,你可以确定不会出现争用问题,且访问对象属性将始终提供正确的值。评估你的程序可能会在何处发生异常,并预先记录所有关键数据。如果发生错误,你将很高兴可以得到信息说明收到了哪些请求,并可更好地了解你的应用程序为什么会出现错误。需要再次注意的是,日志记录引入了额外的文件 I/O,可能会严重影响应用的性能,因此请不要滥用日志。每当你需要创建自己的线程时(例如:向不同的服务发出异步请求),复用现有的安全实现来代替创建自己的解决方案。这在很大程度上意味着要使用 ExecutorServices 和 Java 8 简洁的函数式 CompletableFutures 来创建线程。Spring 还允许通过 DeferredResult 类来进行异步请求处理。假设我们之前的 TopTalent 服务需要一个端点来添加新的 TopTalent。此外,假设基于某些原因,每个新名词都需要为 10 个字符长度。然而,上面的方法(除了构造很差以外)并不是一个真正 “干净” 的解决办法。我们正检查不止一种类型的有效性(即 TopTalentData 不得为空,TopTalentData.name 不得为空,且 TopTalentData.name 为 10 个字符长度),以及在数据无效时抛出异常。通过在 Spring 中集成 Hibernate validator,数据校验可以更干净地进行。让我们首先重构 addTopTalent 方法来支持验证:现在,Spring 将在调用方法之前拦截其请求并对参数进行验证 —— 无需使用额外的手工测试。另一种实现相同功能的方法是创建我们自己的注解。虽然你通常只在需要超出 Hibernate的内置约束集 时才使用自定义注解,本例中,我们假设 @Length 不存在。你可以创建两个额外的类来验证字符串长度,一个用于验证,一个用于对属性进行注解:请注意,这些情况下,关注点分离的最佳实践要求在属性为 null 时,将其标记为有效(isValid 方法中的 s == null),如果这是属性的附加要求,则使用 @NotNull 注解。虽然之前版本的 Spring 需要 XML,但如今大部分配置均可通过 Java 代码或注解来完成;XML 配置只是作为附加的不必要的样板代码。本文(及其附带的 GitHub 仓库)均使用注解来配置 Spring,Spring 知道应该连接哪些 Bean,因为待扫描的顶级包目录已在 @SpringBootApplication 复合注解中做了声明,如下所示:复合注解(可通过 Spring 文档 了解更多信息)只是向 Spring 提示应该扫描哪些包来检索 Bean。在我们的案例中,这意味着这个顶级包 (co.kukurin)将用于检索:@Component (TopTalentConverter, MyAnnotationValidator)@RestController (TopTalentController)@Repository (TopTalentRepository)@Service (TopTalentService) 类如果我们有任何额外的 @Configuration 注解类,它们也会检查基于 Java 的配置。在服务端开发中,经常遇到的一个问题是区分不同的配置类型,通常是生产配置和开发配置。在每次从测试切换到部署应用程序时,不要手动替换各种配置项,更有效的方法是使用 profile。考虑这么一种情况:你正在使用内存数据库进行本地开发,而在生产环境中使用 MySQL 数据库。本质上,这意味着你需要使用不同的 URL 和 (希望如此) 不同的凭证来访问这两者。让我们看看可以如何做到这两个不同的配置文件:假设你不希望在修改代码时意外地对生产数据库进行任何操作,因此将默认配置文件设为 dev 是很有意义的。然后,在服务器上,你可以通过提供 -Dspring.profiles.active=prod 参数给 JVM 来手动覆盖配置文件。另外,还可将操作系统的环境变量设置为所需的默认 profile。正确使用 Spring 的依赖注入意味着允许其通过扫描所有必须的配置类来将所有对象连接在一起;这对于解耦关系非常有用,也使测试变得更为容易,而不是通过类之间的紧耦合来做这样的事情:Misko Hevery 的 Google talk 深入解释了依赖注入的 “为什么”,所以,让我们看看它在实践中是如何使用的。
在关注点分离(常见错误 #3)一节中,我们创建了一个服务和控制器类。
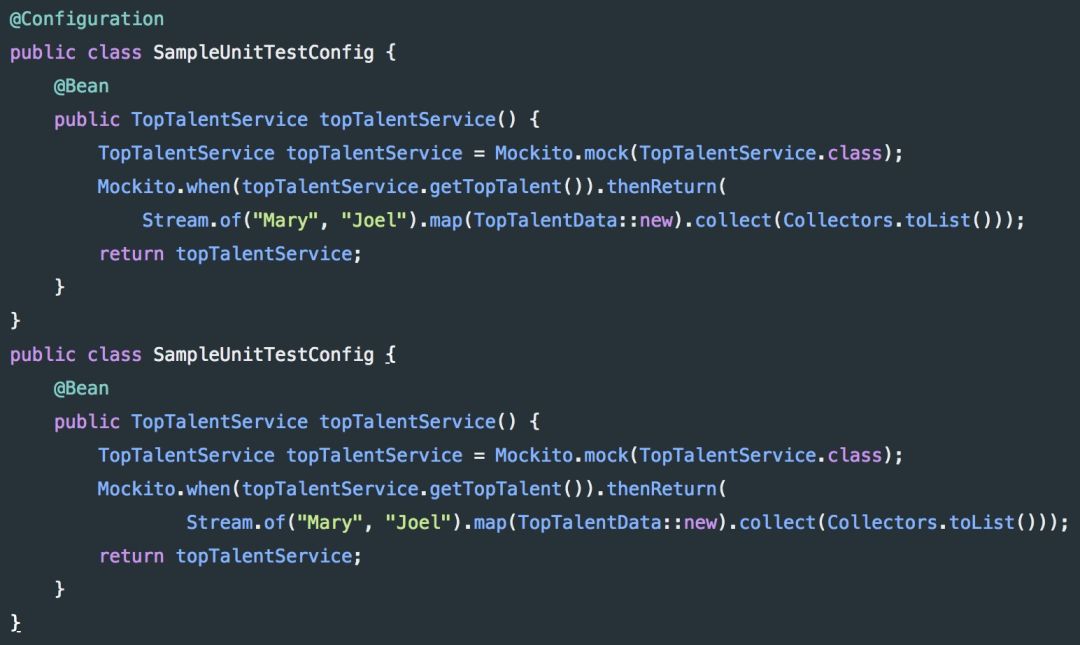
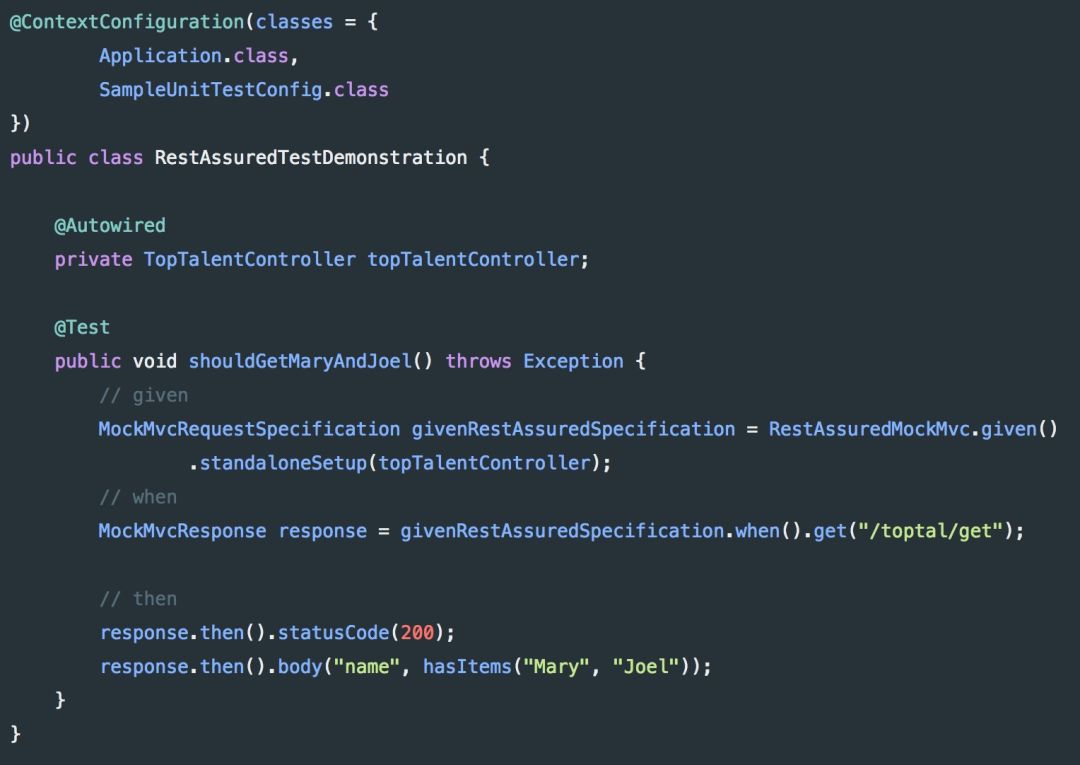
假设我们想在 TopTalentService 行为正确的前提下测试控制器。我们可以通过提供一个单独的配置类来插入一个模拟对象来代替实际的服务实现:
然后,我们可以通过告诉 Spring 使用 SampleUnitTestConfig 作为它的配置类来注入模拟对象:之后,我们就可以使用上下文配置将 Bean 注入到单元测试中。尽管单元测试的概念已经存在很长时间了,但很多开发人员似乎要么 “忘记” 做这件事(特别是如果它不是 “必需” 的时候),要么只是在事后把它添加进来。这显然是不可取的,因为测试不仅应该验证代码的正确性,还应该作为程序在不同场景下应如何表现的文档。在测试 Web 服务时,很少只进行 “纯” 单元测试,因为通过 HTTP 进行通信通常需要调用 Spring 的 DispatcherServlet,并查看当收到一个实际的 HttpServletRequest 时会发生什么(使它成为一个 “集成” 测试,处理验证、序列化等)。REST Assured,一个用于简化测试REST服务的 Java DSL,在 MockMVC 之上,已经被证明提供了一个非常优雅的解决方案。SampleUnitTestConfig 类将 TopTalentService 的模拟实现连接到 TopTalentController 中,而所有的其他类都是通过扫描应用类所在包的下级包目录来推断出的标准配置。RestAssuredMockMvc 只是用来设置一个轻量级环境,并向 /toptal/get 端点发送一个 GET请求。推荐阅读:
推荐3个快速开发平台,前后端都有,项目经验又有着落了
Sharding-Jdbc实现读写分离、分库分表,妙!
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点个「在看」,点击上方小卡片,进入公众号后回复「面试题」领取,更多内容陆续奉上。朕已阅