
数据可视化 | 20行代码玩转象限图!
Python 的绘图功能非常强大,如果能将已有的绘图库的各种复杂操作汇总在一个自己写的函数甚至是库/包中,并实现一行代码就调用并实现复杂的绘图功能,那就更是如虎添翼。
今天,我们就来讲讲一学就会的象限图。
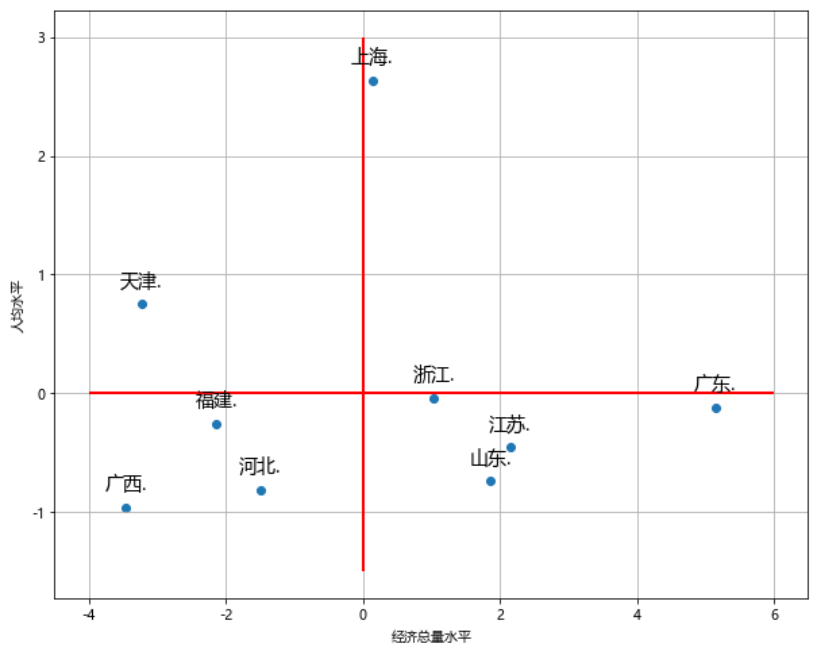
上图学名叫波士顿矩阵分析图,大白话四象限图。这种图经常用于两个维度的散点图中,根据特定的分割线(均值,目标值,实际值等)将数据分为四类,使人一目了然。
常用的场景为分析两个维度的变化比如:比较商品的库存天数和库存周转率,充值人数和每付费用户平均收益,购物篮系数和购物篮数量等。
如何使用 Python 画出此图是本文的目标,事不宜迟,赶快开始!
任何复杂的 Python 绘图都不是一蹴而就的,而是先画出基础图形,后在此基础上按需添加元素并优化而成。这里以一组城市经济数据为例来讲解绘图步骤
基础散点图
df = pd.read_csv('data.csv')df; df.plot(kind='scatter', x='经济总量水平', y='人均水平')
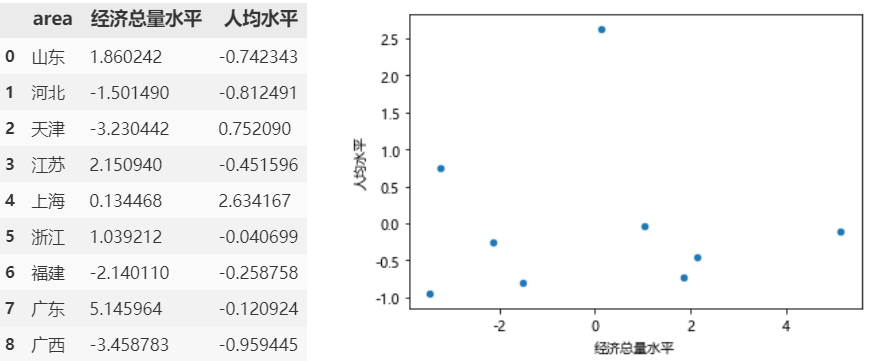
简洁又朴素的散点图,仅需一行代码。离期望成图还差几步
为每个点添加对应的城市名称
添加特定的分割线(均值,目标值,实际值)
背景添加网格
一些其他的定制需求...

广西,河北,福建三地的人均水平和经济总量水平都偏低
上海的人均经济水平很高,但经济总量水平缺只是略优于均值
广东的人均经济水平稍次于均值,但经济总量水平很高
等等~
大量重复的工作懂得批处理。
反复要做的固定操作固化成 " 模板 “,” 套路 "。
碰到异常情况,知道如何准确高效的解决。
import matplotlib.pyplot as plt# 为每个点添加对应的城市名称plt.figure(figsize=(10, 8))# 基础散点图:这里需要单独拆开 x,y 轴和希望配对的标签,为下面的轮子做准备x, y = df['经济总量水平'], df['人均水平']label = df['area']plt.scatter(x, y)plt.xlabel('经济总量水平'); plt.ylabel('人均水平')# 对散点图中的每一个点进行文字标注## 固定代码,无需深究,拿来即用for a,b,l in zip(x,y,label): # zip 拉链函数将其配对组合plt.text(a, b+0.1, '%s.' % l, ha='center', va='bottom',fontsize=14)# 0.1 向上轻微偏移# 添加特定分割线## vlines: vertical 垂直于 x 轴的线,在变量'经济总量'的均值处开始画,## y 轴的范围[1.5, 3]plt.vlines(x=df['经济总量水平'].mean(), ymin=-1.5, ymax=3,colors='red', linewidth=2)plt.hlines(y=df['人均水平'].mean(), xmin=-4, xmax=6,colors='red', linewidth=2)# 背景网格plt.grid(True)# 定制需求:隐去四周的边框线条# sns.despine(trim=True, left=True, bottom=True)
评论