
从用户态、内核态、全局变量、BSS函数看进程运行状态
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达
转载:一口Linux


收集项目组需求的时候,我们知道一个进程要运行起来需要以下的内存结构。
用户态:
代码段、全局变量、BSS
函数栈
堆
内存映射区
内核态:
内核的代码、全局变量、BSS
内核数据结构例如 task_struct
内核栈
内核中动态分配的内存
现在这些事是不是已经都有了着落?
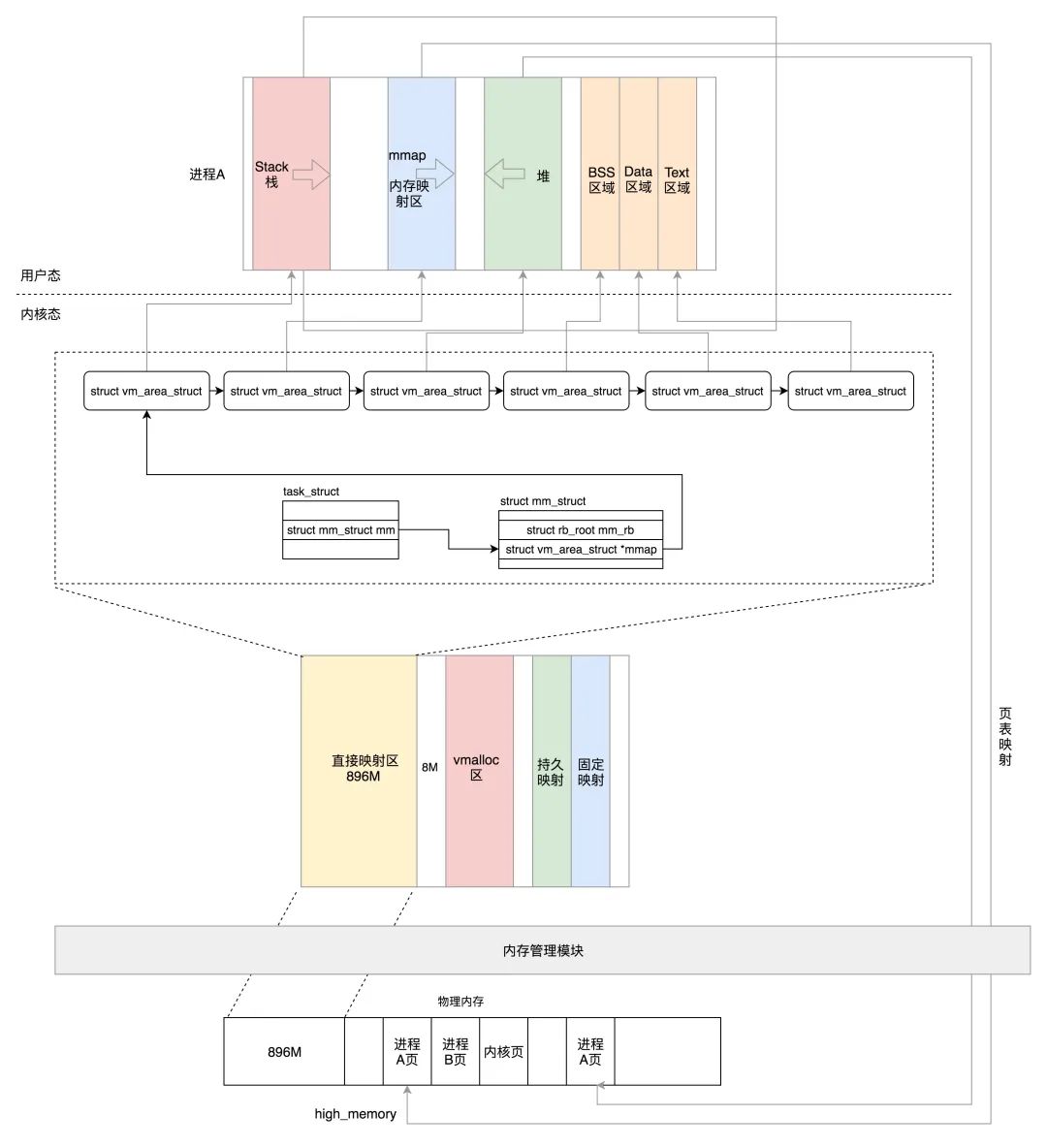
我画了一个图,总结一下进程运行状态在 32 位下对应关系。
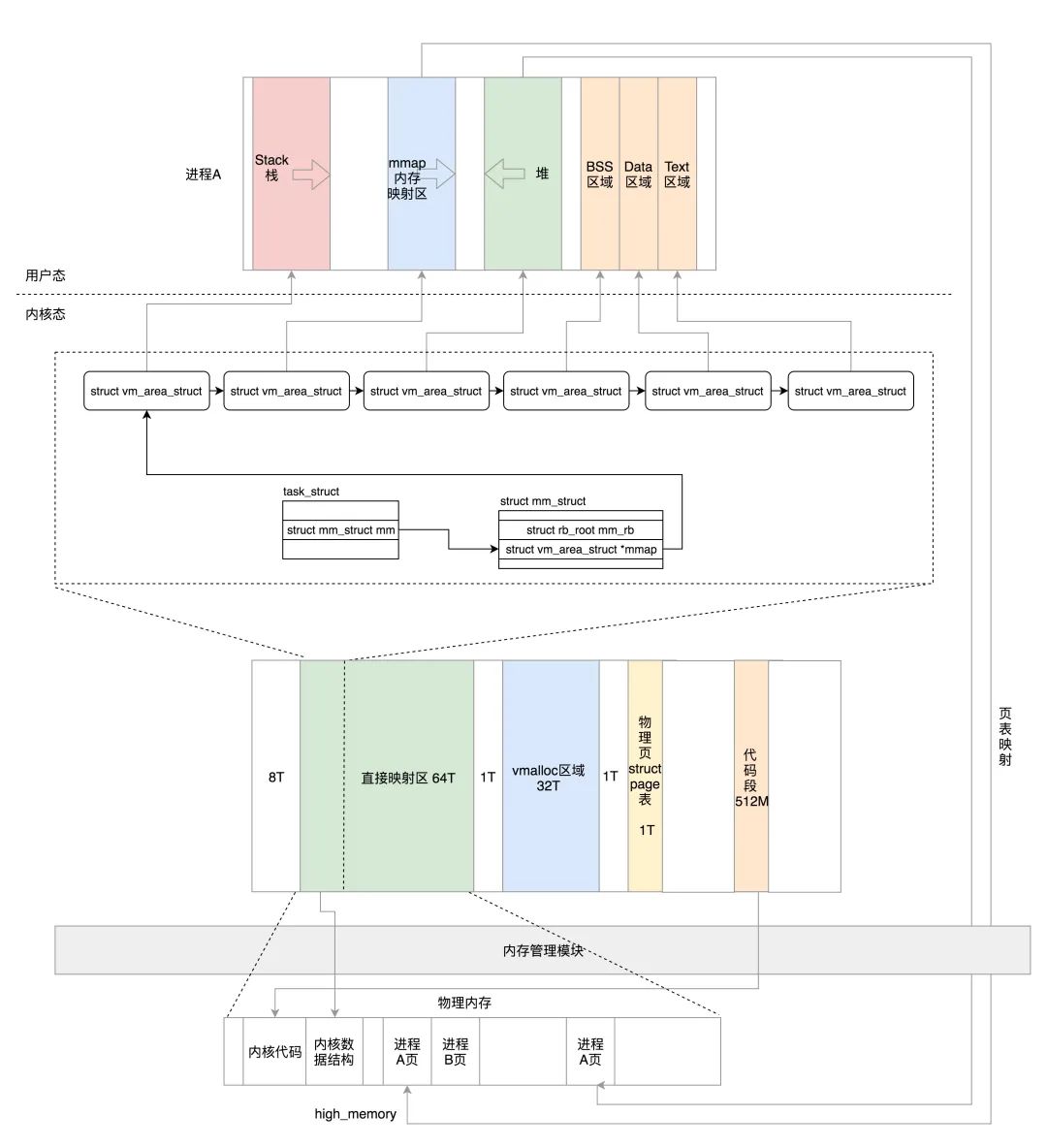
对于 64 位的对应关系,只是稍有区别,我这里也画了一个图,方便你对比理解。
用户态和内核态的划分
进程的虚拟地址空间,其实就是站在项目组的角度来看内存,所以我们就从 task_struct 出发来看。这里面有一个 struct mm_struct 结构来管理内存。
struct mm_struct *mm;在 struct mm_struct 里面,有这样一个成员变量:
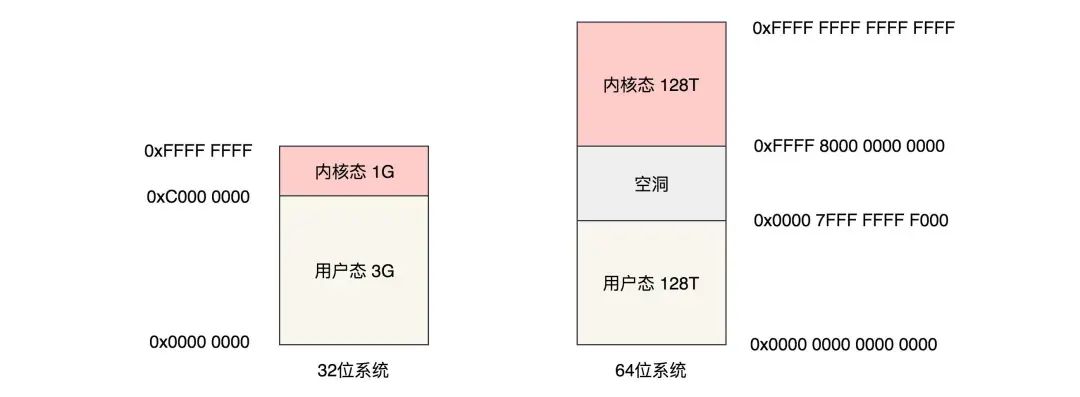
unsigned long task_size; /* size of task vm space */我们之前讲过,整个虚拟内存空间要一分为二,一部分是用户态地址空间,一部分是内核态地址空间,那这两部分的分界线在哪里呢?这就要 task_size 来定义。
对于 32 未来的系统,内核里面是这样定义 TASK_SIZE 答:
#ifdef CONFIG_X86_32
/*
* User space process size: 3GB (default).
*/
#define TASK_SIZE PAGE_OFFSET
#define TASK_SIZE_MAX TASK_SIZE
/*
config PAGE_OFFSET
hex
default 0xC0000000
depends on X86_32
*/
#else
/*
* User space process size. 47bits minus one guard page.
*/
#define TASK_SIZE_MAX ((1UL << 47) - PAGE_SIZE)
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
......当执行一个新的进程的时候,会做以下的设置:
current->mm->task_size = TASK_SIZE;
对于 32 位系统,最大能够寻址 2^32=4G,其中用户态虚拟地址空间是 3G,内核态是 1G。
对于 64 位置系统,虚拟地址只使用了 48 位。就像代码里面写的一样,1 左移了 47 位,就相当于 48 位地址空间一半的位置,0x0000800000000000,然后减去一个页,就是 0x00007FFFFFFFF000,共 128T。同样,内核空间也是 128T。内核空间和用户空间之间隔着很大的空隙,以此来进行隔离。
用户态布局
我们先来看用户态虚拟空间的布局。
之前我们讲了用户态虚拟空间里面有几类数据,例如代码、全局变量、堆、栈、内存映射区等。在 struct mm_struct 里面,有下面这些变量定义了这些区域的统计信息和位置。
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;其中,total_vm 是总共映射的页的数目。我们知道,这么大的虚拟地址空间,不可能都有真实内存对应,所以这里是映射的数目。当内存吃紧的时候,有些页可以换出到硬盘上,有的页因为比较重要,不能换出。locked_vm 就是被锁定不能换出,pinned_vm 是不能换出,也不能移动。
data_vm 是存放数据的页的数目,exec_vm 是存放可执行文件的页的数目,stack_vm 是栈所占的页的数目。
start_code 和 end_code 表示可执行代码的开始和结束位置,start_data 和 end_data 表示已初始化数据的开始位置和结束位置。
start_brk 是堆的起始位置,brk 是堆当前的结束位置。前面咱们讲过 malloc 申请一小块内存的话,就是通过改变 brk 位置实现的。
start_stack 是栈的起始位置,栈的结束位置在寄存器的栈顶指针中。
arg_start 和 arg_end 是参数列表的位置, env_start 和 env_end 是环境变量的位置。它们都位于栈中最高地址的地方。
mmap_base 表示虚拟地址空间中用于内存映射的起始地址。一般情况下,这个空间是从高地址到低地址增长的。前面咱们讲 malloc 申请一大块内存的时候,就是通过 mmap 在这里映射一块区域到物理内存。咱们加载动态链接库 so 文件,也是在这个区域里面,映射一块区域到 so 文件。
这下所有用户状态的区域的位置基本上都描述清楚了。整个布局就像下面这张图这样。虽然 32 位和 64 位置的空间相差很大,但是区域的类别和布局是相似的。

除了位置信息之外,struct mm_struct 里面还专门有一个结构 vm_area_struct,来描述这些区域的属性。
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;这里面一个是单链表,用于将这些区域串起来。另外还有一个红黑树。又是这个数据结构,在进程调度的时候我们用的也是红黑树。它的好处就是查找和修改都很快。这里用红黑树,就是为了快速查找一个内存区域,并在需要改变的时候,能够快速修改。
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
struct mm_struct *vm_mm; /* The address space we belong to. */
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
} __randomize_layout;vm_start 和 vm_end 指定了该区域在用户空间中的起始和结束地址。vm_next 和 vm_prev 将这个区域串在链表上。vm_rb 将这个区域放在红黑树上。vm_ops 里面是对这个内存区域可以做的操作的定义。
虚拟内存区域可以映射到物理内存,也可以映射到文件,映射到物理内存的时候称为匿名映射,anon_vma 中,anoy 就是 anonymous,匿名的意思,映射到文件就需要有 vm_file 指定被映射的文件。
那这些 vm_area_struct 是如何和上面的内存区域关联的呢?
这个事情是在 load_elf_binary 里面实现的。没错,就是它。加载内核的是它,启动第一个用户态进程 init 的是它,fork 完了以后,调用 exec 运行一个二进制程序的也是它。
当 exec 运行一个二进制程序的时候,除了解析 ELF 的格式之外,另外一个重要的事情就是建立内存映射。
static int load_elf_binary(struct linux_binprm *bprm)
{
......
setup_new_exec(bprm);
......
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
......
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
......
retval = set_brk(elf_bss, elf_brk, bss_prot);
......
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
......
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
......
}load_elf_binary 会完成以下的事情:
调用 setup_new_exec,设置内存映射区 mmap_base;
调用 setup_arg_pages,设置栈的 vm_area_struct,这里面设置了 mm->arg_start 是指向栈底的,current->mm->start_stack 就是栈底;
elf_map 会将 ELF 文件中的代码部分映射到内存中来;
set_brk 设置了堆的 vm_area_struct,这里面设置了 current->mm->start_brk = current->mm->brk,也即堆里面还是空的;
load_elf_interp 将依赖的 so 映射到内存中的内存映射区域。
最终就形成下面这个内存映射图。
映射完毕后,什么情况下会修改呢?
第一种情况是函数的调用,涉及函数栈的改变,主要是改变栈顶指针。
第二种情况是通过 malloc 申请一个堆内的空间,当然底层要么执行 brk,要么执行 mmap。关于内存映射的部分,我们后面的章节讲,这里我们重点看一下 brk 是怎么做的。
brk 系统调用实现的入口是 sys_brk 函数,就像下面代码定义的一样。
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
......
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {
if (!do_munmap(mm, newbrk, oldbrk-newbrk, &uf))
goto set_brk;
goto out;
}
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk(oldbrk, newbrk-oldbrk, &uf) < 0)
goto out;
set_brk:
mm->brk = brk;
......
return brk;
out:
retval = mm->brk;
return retval前面我们讲过了,堆是从低地址向高地址增长的,sys_brk 函数的参数 brk 是新的堆顶位置,而当前的 mm->brk 是原来堆顶的位置。
首先要做的第一个事情,将原来的堆顶和现在的堆顶,都按照页对齐地址,然后比较大小。如果两者相同,说明这次增加的堆的量很小,还在一个页里面,不需要另行分配页,直接跳到 set_brk 那里,设置 mm->brk 为新的 brk 就可以了。
如果发现新旧堆顶不在一个页里面,麻烦了,这下要跨页了。如果发现新堆顶小于旧堆顶,这说明不是新分配内存了,而是释放内存了,释放的还不小,至少释放了一页,于是调用 do_munmap 将这一页的内存映射去掉。
如果堆将要扩大,就要调用 find_vma。如果打开这个函数,看到的是对红黑树的查找,找到的是原堆顶所在的 vm_area_struct 的下一个 vm_area_struct,看当前的堆顶和下一个 vm_area_struct 之间还能不能分配一个完整的页。如果不能,没办法只好直接退出返回,内存空间都被占满了。
如果还有空间,就调用 do_brk 进一步分配堆空间,从旧堆顶开始,分配计算出的新旧堆顶之间的页数。
static int do_brk(unsigned long addr, unsigned long len, struct list_head *uf)
{
return do_brk_flags(addr, len, 0, uf);
}
static int do_brk_flags(unsigned long addr, unsigned long request, unsigned long flags, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
unsigned long len;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
len = PAGE_ALIGN(request);
......
find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent);
......
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
......
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
INIT_LIST_HEAD(&vma->anon_vma_chain);
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
mm->data_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return 0;在 do_brk 中,调用 find_vma_links 找到将来的 vm_area_struct 节点在红黑树的位置,找到它的父节点、前序节点。接下来调用 vma_merge,看这个新节点是否能够和现有树中的节点合并。如果地址是连着的,能够合并,则不用创建新的 vm_area_struct 了,直接跳到 out,更新统计值即可;如果不能合并,则创建新的 vm_area_struct,既加到 anon_vma_chain 链表中,也加到红黑树中。
内核态的布局
用户态虚拟空间分析完毕,接下来我们分析内核态虚拟空间。
内核态的虚拟空间和某一个进程没有关系,所有进程通过系统调用进入到内核之后,看到的虚拟地址空间都是一样的。
这里强调一下,千万别以为到了内核里面,咱们就会直接使用物理内存地址了,想当然地认为下面讨论的都是物理内存地址,不是的,这里讨论的还是虚拟内存地址,但是由于内核总是涉及管理物理内存,因而总是隐隐约约发生关系,所以这里必须思路清晰,分清楚物理内存地址和虚拟内存地址。
在内核态,32 位和 64 位的布局差别比较大,主要是因为 32 位内核态空间太小了。
我们来看 32 位的内核态的布局。
32 位的内核态虚拟地址空间一共就 1G,占绝大部分的前 896M,我们称为直接映射区。
所谓的直接映射区,就是这一块空间是连续的,和物理内存是非常简单的映射关系,其实就是虚拟内存地址减去 3G,就得到物理内存的位置。
在内核里面,有两个宏:
__pa(vaddr) 返回与虚拟地址 vaddr 相关的物理地址;
__va(paddr) 则计算出对应于物理地址 paddr 的虚拟地址。
#define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET))
#define __pa(x) __phys_addr((unsigned long)(x))
#define __phys_addr(x) __phys_addr_nodebug(x)
#define __phys_addr_nodebug(x) ((x) - PAGE_OFFSET)但是你要注意,这里虚拟地址和物理地址发生了关联关系,在物理内存的开始的 896M 的空间,会被直接映射到 3G 至 3G+896M 的虚拟地址,这样容易给你一种感觉,是这些内存访问起来和物理内存差不多,别这样想,在大部分情况下,对于这一段内存的访问,在内核中,还是会使用虚拟地址的,并且将来也会为这一段空间建设页表,对这段地址的访问也会走上一节我们讲的分页地址的流程,只不过页表里面比较简单,是直接的一一对应而已。
这 896M 还需要仔细分解。在系统启动的时候,物理内存的前 1M 已经被占用了,从 1M 开始加载内核代码段,然后就是内核的全局变量、BSS 等,也是 ELF 里面涵盖的。这样内核的代码段,全局变量,BSS 也就会被映射到 3G 后的虚拟地址空间里面。具体的物理内存布局可以查看 /proc/iomem。
在内核运行的过程中,如果碰到系统调用创建进程,会创建 task_struct 这样的实例,内核的进程管理代码会将实例创建在 3G 至 3G+896M 的虚拟空间中,当然也会被放在物理内存里面的前 896M 里面,相应的页表也会被创建。
在内核运行的过程中,会涉及内核栈的分配,内核的进程管理的代码会将内核栈创建在 3G 至 3G+896M 的虚拟空间中,当然也就会被放在物理内存里面的前 896M 里面,相应的页表也会被创建。
896M 这个值在内核中被定义为 high_memory,在此之上常称为“高端内存”。这是个很笼统的说法,到底是虚拟内存的 3G+896M 以上的是高端内存,还是物理内存 896M 以上的是高端内存呢?
这里仍然需要辨析一下,高端内存是物理内存的概念。它仅仅是内核中的内存管理模块看待物理内存的时候的概念。前面我们也说过,在内核中,除了内存管理模块直接操作物理地址之外,内核的其他模块,仍然要操作虚拟地址,而虚拟地址是需要内存管理模块分配和映射好的。
假设咱们的电脑有 2G 内存,现在如果内核的其他模块想要访问物理内存 1.5G 的地方,应该怎么办呢?如果你觉得,我有 32 位的总线,访问个 2G 还不小菜一碟,这就错了。
首先,你不能使用物理地址。你需要使用内存管理模块给你分配的虚拟地址,但是虚拟地址的 0 到 3G 已经被用户态进程占用去了,你作为内核不能使用。因为你写 1.5G 的虚拟内存位置,一方面你不知道应该根据哪个进程的页表进行映射;另一方面,就算映射了也不是你真正想访问的物理内存的地方,所以你发现你作为内核,能够使用的虚拟内存地址,只剩下 1G 减去 896M 的空间了。
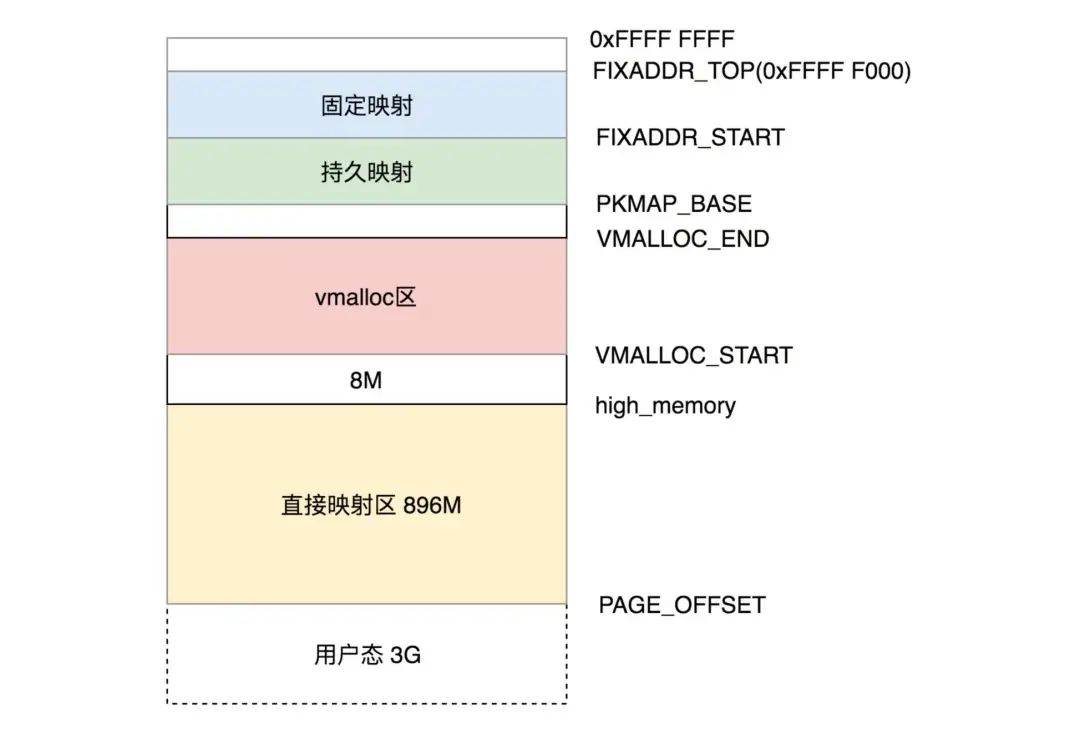
于是,我们可以将剩下的虚拟内存地址分成下面这几个部分。
在 896M 到 VMALLOC_START 之间有 8M 的空间。
VMALLOC_START 到 VMALLOC_END 之间称为内核动态映射空间,也即内核想像用户态进程一样 malloc 申请内存,在内核里面可以使用 vmalloc。假设物理内存里面,896M 到 1.5G 之间已经被用户态进程占用了,并且映射关系放在了进程的页表中,内核 vmalloc 的时候,只能从分配物理内存 1.5G 开始,就需要使用这一段的虚拟地址进行映射,映射关系放在专门给内核自己用的页表里面。
PKMAP_BASE 到 FIXADDR_START 的空间称为持久内核映射。使用 alloc_pages() 函数的时候,在物理内存的高端内存得到 struct page 结构,可以调用 kmap 将其在映射到这个区域。
FIXADDR_START 到 FIXADDR_TOP(0xFFFF F000) 的空间,称为固定映射区域,主要用于满足特殊需求。
在最后一个区域可以通过 kmap_atomic 实现临时内核映射。假设用户态的进程要映射一个文件到内存中,先要映射用户态进程空间的一段虚拟地址到物理内存,然后将文件内容写入这个物理内存供用户态进程访问。给用户态进程分配物理内存页可以通过 alloc_pages(),分配完毕后,按说将用户态进程虚拟地址和物理内存的映射关系放在用户态进程的页表中,就完事大吉了。这个时候,用户态进程可以通过用户态的虚拟地址,也即 0 至 3G 的部分,经过页表映射后访问物理内存,并不需要内核态的虚拟地址里面也划出一块来,映射到这个物理内存页。但是如果要把文件内容写入物理内存,这件事情要内核来干了,这就只好通过 kmap_atomic 做一个临时映射,写入物理内存完毕后,再 kunmap_atomic 来解映射即可。
32 位的内核态布局我们看完了,接下来我们再来看 64 位的内核布局。
其实 64 位的内核布局反而简单,因为虚拟空间实在是太大了,根本不需要所谓的高端内存,因为内核是 128T,根本不可能有物理内存超过这个值。
64 位的内存布局如图所示。

64 位的内核主要包含以下几个部分。
从 0xffff800000000000 开始就是内核的部分,只不过一开始有 8T 的空档区域。
从 __PAGE_OFFSET_BASE(0xffff880000000000) 开始的 64T 的虚拟地址空间是直接映射区域,也就是减去 PAGE_OFFSET 就是物理地址。虚拟地址和物理地址之间的映射在大部分情况下还是会通过建立页表的方式进行映射。
从 VMALLOC_START(0xffffc90000000000)开始到 VMALLOC_END(0xffffe90000000000)的 32T 的空间是给 vmalloc 的。
从 VMEMMAP_START(0xffffea0000000000)开始的 1T 空间用于存放物理页面的描述结构 struct page 的。
从 __START_KERNEL_map(0xffffffff80000000)开始的 512M 用于存放内核代码段、全局变量、BSS 等。这里对应到物理内存开始的位置,减去 __START_KERNEL_map 就能得到物理内存的地址。这里和直接映射区有点像,但是不矛盾,因为直接映射区之前有 8T 的空当区域,早就过了内核代码在物理内存中加载的位置。
到这里内核中虚拟空间的布局就介绍完了。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!