
为什么 SQL 语句不要过多的 join?

送分题
free 或者 toptotal 总内存
used 已用内存
free 空闲内存
buff/cache 已使用的缓存
avaiable 可用内存

sync; echo 3 > /proc/sys/vm/drop_caches就可以清理buff/cache了,你说说我在线上执行这条命令做好不好?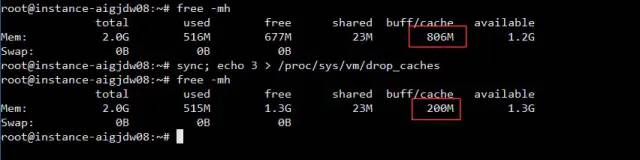
再谈SQL Join
回顾
joinjoininner join内连接
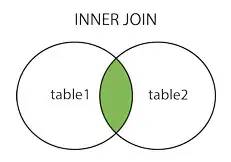
left join左连接
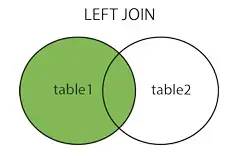
right join右连接
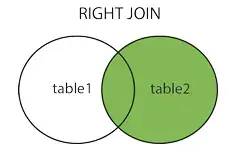
full join全连接
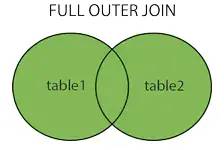
以上图片源:https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
join语句,如何优化提升性能?数据规模较小 全部干进内存就完事了嗷 数据规模较大
可以通过增加索引来优化 join语句的执行速度 可以通过冗余信息来减少join的次数 尽量减少表连接的次数,一个SQL语句表连接的次数不要超过5次
join缓冲区
内存块中, 以MySQL的InnoDB引擎为例,使用以下语句我们必然可以查到相关的内存区域show variables like '%buffer%'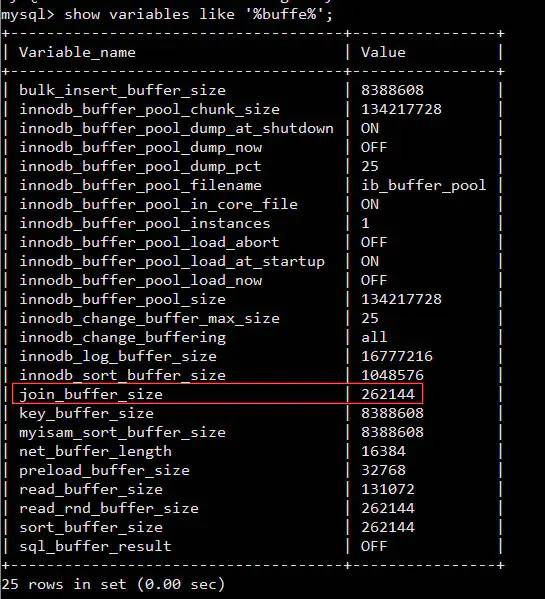
join_buffer_size的大小将会影响我们join语句的执行性能一个大前提
硬盘上,并且以文件的形式进行存储。InnoDB以 页(page)为基本的IO单位,每个页的大小为16KBInnoDB会为每个表创建用于存储数据的 .ibd文件
hbase、kafkaLinux有对此做出优化吗?提示,你可以再执行一次free命令看一下

图片来源:https://www.linuxatemyram.com/
buff/cache里面存的是什么,?为什么 buff/cache占了那么多内存,可用内存即availlable还有1.1G?为什么你可以通过两条命令来清理 buff/cache占用的内存,而想要释放used只能通过结束进程来实现?
buff/cache所占用的内存,说明它就不重要, 清除它不会对系统的运行造成影响存储器层次结构的本质是,每一层存储设备都是较低一层设备的缓存
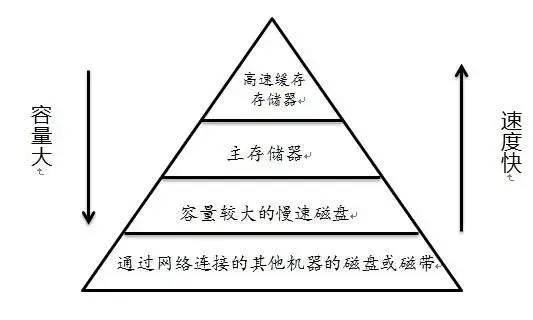
相关资料:http://tldp.org/LDP/sag/html/buffer-cache.html

Join算法
join_buffer 你认为join_buffer里面存储的是什么?join_bufferNested Loop Join
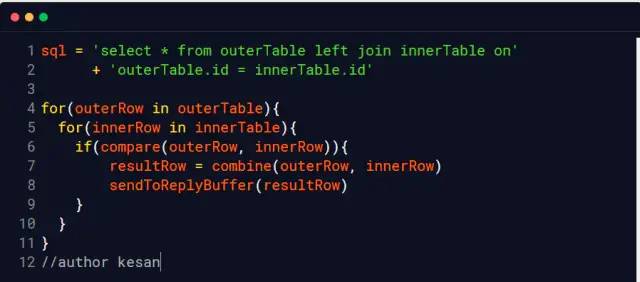
10000000次(假设这两个表的文件没有被操作系统给缓存到内存, 我们称之为冷数据表)Block nested loop
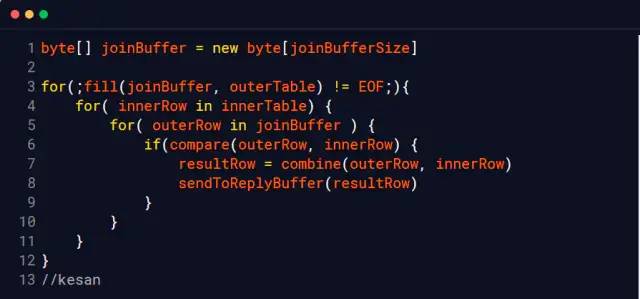
Block 块,也就是说每次都会取一块数据到内存以减少I/O的开销t_a 和t_b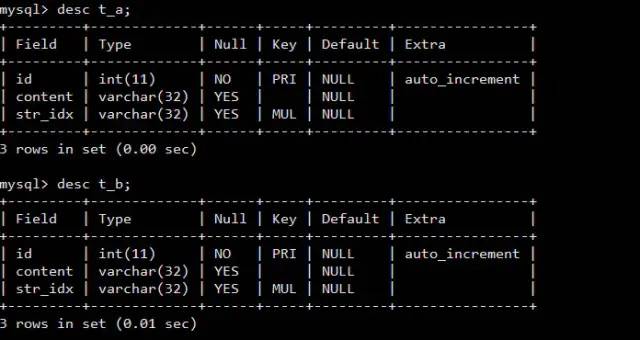
Block nested loop 算法
总结
join如果join真的影响到性能。试着调大你的join_buffer_size, 或者换固态硬盘。参考资料
《深入理解计算机系统》- 第6章 存储器层次结构https://www.linuxatemyram.com/play.html 作者通过几个例子来说明硬盘缓存对程序执行性能的影响https://www.linuxatemyram.com/ Free参数的解释https://www.thegeekdiary.com/how-to-clear-the-buffer-pagecache-disk-cache-under-linux/ 文章开头送分题命令的解释
https://juejin.im/book/5bffcbc9f265da614b11b731/section/5c061a4de51d451df113c10d MySQL 是怎样运行的:从根儿上理解 MySQL
https://mariadb.com/kb/en/block-based-join-algorithms/ 来自MariaDB官方文档解释了Block-Nested-Loop算法的实现
- END - 最近热文
• 12门课100分,直博清华的学霸火了!“造假都不敢这么写” • 微信这项功能即将下线,赶快导出数据! • 华为奇葩面试题:一头牛重800公斤一座桥承重700公斤,请问牛怎么过桥? • 985研究生组团诈骗,一个中招就关App,涉案金额超1亿,受害人遍布全国
评论