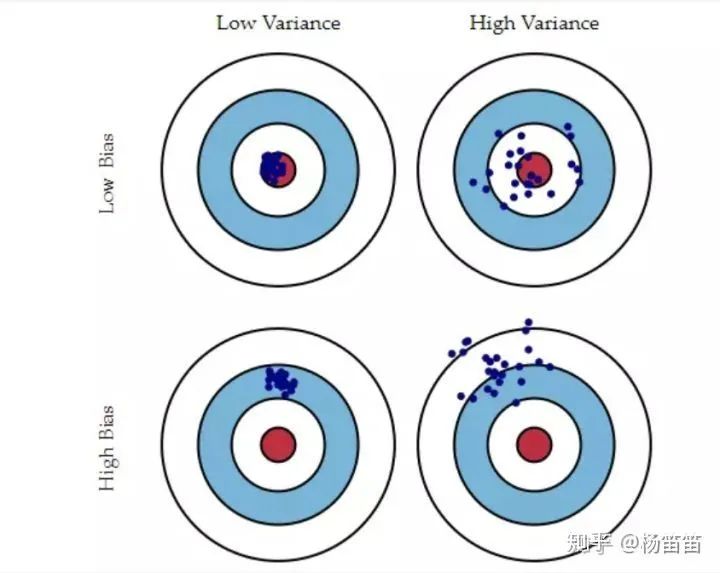
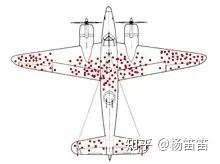
2. 在现在这个例子中,总体是所有的上海顾客,样本呢?可以代表所有上海客人吗?不是的,我的样本是“那些愿意来这家新开的餐厅吃饭的上海客人”。这家餐厅开在一家商场的最高层,如果不是想好了要找来的话,很难有人闲逛进店吃饭。因此样本和总体的差异导致了我的结论不准确,因为那些愿意来川菜餐厅吃饭的客人显然平均上是比一个普通上海人更能接受辣味的。换句话说,我的样本不够有“代表性”(representative)。这个总体和样本在本质上的差异,在统计学上叫作偏差(Bias)。用下面这个图再给大家解释一下方差和偏差的区别。 左上角是低方差低偏差,所有的飞镖都扔中了中间那一环。这时候你瞄对了地方,并且随机性很低。在数据上就是样本随机性小,并且很有代表性。右上角是高方差低偏差,飞镖散落在了红心周围。这时候表示你瞄准的地方是对的,但是随机性太大了。在数据上就是样本有代表性,但是随机性很高。左下角是低方差高偏差,飞镖都落在了距离红心一段距离的地方。这时候是你瞄准的地方错了,虽然随机性很低。在数据上就是样本随机性低,但是没有代表性。右下角是高方差高偏差,说明你既没瞄准,还不会扔。数据上就是随机性又高,还没有代表性。其实所有的调研都会面临这两个问题:一是随机性,也就是方差。二是样本和总体有本质性的区别,也叫作偏差。在调研里,方差的问题很好解决,钱给够,扩大样本就行。而偏差的问题往往会复杂很多,需要更细致的抽样设计来尽量避免。说起偏差这个话题,前年的高考作文中出现的“幸存者偏差”其实就是个很有趣的故事。二战期间,盟军想要给战斗机加一些装甲增加防御性。但是当时物资有限,他们无法给整架飞机都加上装甲。因此军方的专家就需要研究出飞机上的哪些部位是最脆弱的并给这些部位加上装甲。为了做出推断,军方专家从那些受伤了并飞回来的飞机中采集数据进行分析。他们最终发现这些飞机上的引擎和机舱都没有中弹(如下图所示)。自然而然地专家们得出结论“应该给给机翼和机身还有机尾增加装甲,驾驶舱和引擎不用管,这两个地方不会中弹。”这时候有一位叫Abraham Wald的数学家指出了他们推断中的漏洞:军方专家只分析了这些成功飞回基地的飞机。这些飞机之所以能飞回基地,是因为机身机翼中弹并没有对飞机造成致命伤害,不然它们早就被打下去了。他建议给引擎和机舱加装甲,因为并不是说德军的防空炮刻意打机身机翼而漏掉机舱和引擎(那个时候的防空炮扫射基本上就是看运气,不可能说精确地瞄准某个部位),之所以飞回来的飞机这些部位没中弹,是因为这些部位中弹的飞机都没飞回来!通过分析那些被击落的飞机,Wald孕育出了“幸存者偏差”这个概念。二战时期还有很多统计学概念被提出运用,并且大多得到了比军方智库更好的效果,感兴趣的可以看一下“德军坦克问题”(The German Tank Problem)。刚才这个故事里,盟军想研究的总体是所有盟军的飞机,而样本是那些可以飞回来的飞机。这些飞回来的飞机显然不具有足够的代表性。那么如果用这些样本来对总体做推断,就会出现偏差。还有个常见的例子就是那些宣传读书无用论的人。“啊你看看比尔盖茨,乔布斯,扎克伯格他们都没有大学毕业,现在全是亿万富翁。” 这里我们关心的总体是所有高中没毕业的人,而样本是“高中没毕业并且很出名人人都知道的人。”你怎么不想想那些被忽略掉的成千上万的其他辍学的人过得怎么样了?用这样有严重偏差的样本去对总体做推断的人,不是蠢就是坏。