
视频也能P!谷歌CVPR 2021最新视频P图模型omnimatte
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达


来源:Google AI 、新智元
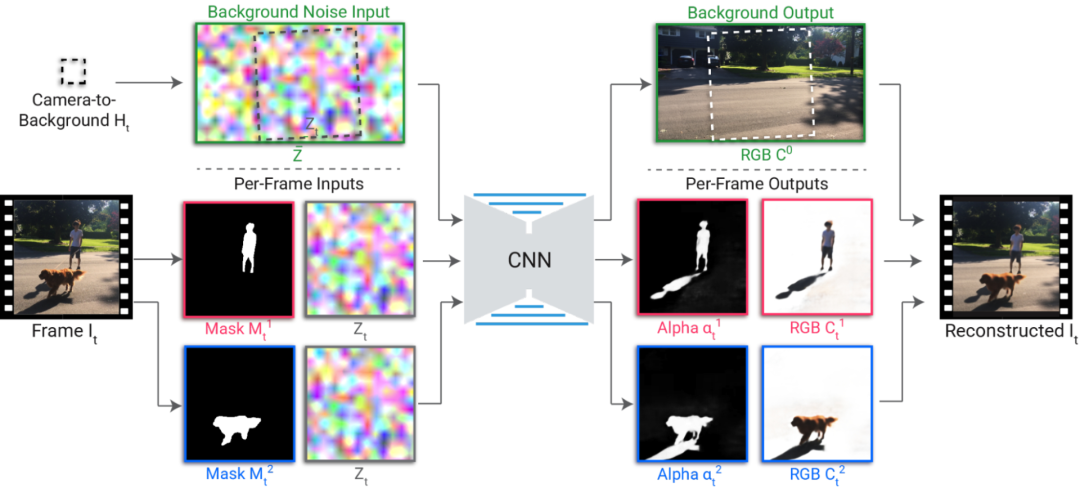
【导读】你是否还在受视频P图不能分割主体的苦?是否还在被人说P图不真实,影子都没有?谷歌在CVPR 2021发布的omnimatte将彻底解决你的烦恼,只需一键操作,视频立刻分为背景和前景主体,影子水花都能抠,多个蒙版,视频想怎么P就怎么P!








参考资料:
https://ai.googleblog.com/2021/08/introducing-omnimattes-new-approach-to.html

点个在看 paper不断!
评论