
聊聊字节跳动 Node.js RPC 的设计实现
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
背景
大家好,我们是字节跳动 Web Infra 团队,目前团队主要专注的方向包括现代 Web 开发解决方案、低代码搭建、Serverless、跨端解决方案、终端基础体验、ToB 等等。Node.js 基础设施建设是我们负责的方向之一,包括但不限于:
服务发现:Consul 服务治理:Logger、Metrics、Trace 服务调用:HTTP ( Fetch )、RPC ( Thrift ) 数据库:MySQL ( Sequelize / TypeORM )、Redis、ClickHouse 消息队列: Kafka、RocketMQ 结合框架,提供遵循公司流量调度等规范的 Node.js 插件 支持 Node.js、Golang 等后端语言的性能分析平台 维护 Node.js 应用的容器镜像
在 2021 年上半年,由于现有的 Node.js RPC 实现逐渐跟不上字节跳动业务发展节奏,我们决定对其进行重构,在本文将会介绍到 RPC 重构过程中的设计思路以及落地中所遇到的问题。
什么是 RPC?
RPC ( Remote Procedure Call ) 是一种通用的网络调用方式,其广泛应用于后端服务之间,像 Dubbo、SOAP、Thrift、gRPC、RESTful 等,从广义上来说都是一种 RPC 的实现。几乎可以这么说,只要公司达到一定量级,其后端服务之间必定会采用 RPC 而非简单 HTTP 的形式来进行互相调用。因此,对于想做全栈或者后端 Node.js 的同学来说,早点了解与使用 RPC 是非常有必要的。
既然 RPC 这么重要,那么到底该怎么去理解它呢?
按照上面的说法,RPC 是一种通用的网络调用方式,是一个抽象的概念,那么直接对其进行理解是行不通的。所以我们需要把 RPC 映射到我们的现实生活中,这样就会发现,我们的每一次交谈、打字、打电话其实都是一次 “RPC 调用”,RPC 是一种 “沟通” 方式。
现状 & 需求
在字节跳动内,由于各种原因,存在有多种序列化协议、网络协议,这导致我们没有办法直接使用开源的 Apache Thrift、gRPC,只能选择自建 RPC 实现。而对于 RPC 实现,我们希望可以做到以下几点:
支持多种序列化协议,如 Thrift、Protobuf、JSON。 支持多种网络协议,如 TCP、HTTP、HTTP/2。 尽量复用老代码。
设计 RPC
DDD (Domain Driven Design)
在开始介绍之前,考虑到部分同学可能对于后面使用到的概念不太了解,所以我们需要先科普一下使用到的方法论,有相关经验的同学可以跳过这一节。
摘自 Wikipedia
Domain-driven design ( DDD ) is the concept that the structure and language of software code ( class names, class methods, class variables ) should match the business domain.
Domain-driven design is predicated on the following goals:
placing the project's primary focus on the core domain and domain logic; basing complex designs on a model of the domain; initiating a creative collaboration between technical and domain experts to iteratively refine a conceptual model that addresses particular domain problems.
领域驱动设计 (DDD) 是一种将代码结构、命名与业务领域概念相匹配的方法论。领域驱动设计基于以下几个目标:
将项目重心放在核心领域与领域逻辑上 以领域模型为基础进行复杂设计 让技术专家与领域专家进行合作,以迭代的方式来解决特性领域的概念模型
说白了就是由在某个领域摸爬滚打了多年的专家来梳理业务逻辑,与技术人员合作设计领域模型,然后再由技术人员根据领域模型进行实现的一套软件设计与迭代方法。
在下文中,我们将会利用领域驱动设计的思路来探讨 RPC 该如何进行设计。
分解 RPC
在进行设计之前,我们必须要先对 RPC 进行分解,了解其基础是什么?
上文说过了,RPC 是一个抽象的概念,所以直接分析其基础是行不通的,只能透过现实场景来进行分析。就拿交谈这个简单场景来说:我们跟什么人、说什么话,其实都是不确定的,但是可以确定的是,我们说话的声音是通过空气振动传达给对方的 ( 物理原理 ),如果没有空气振动,那么声音也传达不到对方的耳朵 ( 真空环境 )。所以可以得出空气振动 ( 传播途径 ) 是交谈的一个重要基础。
除此之外,其实还有一个很重要的基础,那就是语言互通。如果语言不通,那么驴唇不对马嘴也是很正常的事情。所以我们见到中国人会下意识的说普通话,见到外国人会下意识的说英语,见到家里人也会下意识的说方言 (如果有的话)。
从上面的推断,我们可以得到交谈的两个重要基础:
传播途径:存在空气震动。 语言互通:同样说普通话 / 英语 / 方言。
同理的,在 RPC 的场景下,也必然会有它们的一席之地。
其实在 RPC 中,网络协议就相当于传播途径,用于传输数据,而序列化协议则相当于语言,用于转换传输的数据。所以我们可以做一个假设:对于一个 RPC 实现来说,有两个很重要的基础因素:
网络协议:用于传输数据。 序列化协议:用于转换数据。
模型构建
接下来,我们就根据上面的假设构建一个理论模型。
网络协议 ( Network Protocol ),其重点在 Network 上,说到 Network 就不得不让人联想到连接 ( Connection ) 了,它在许多网络协议中都有体现,比如:TCP 协议的 Socket,HTTP 协议的 Request & Response,所以我们就以 Connection 作为网络协议的模型。同时为了避免与序列化协议相混淆,我们还需要为 Connection 模型上一道限制,即网络协议只关心网络 IO 读写与 IO 事件处理,不关心任何序列化相关的事情。说到 Connection 那自然就逃不过 read / write 了,所以可以建立一个简单的 Connection 模型如下:
interface Connection {
read(): Promise<Buffer>;
write(buf: Buffer): Promise<void>;
}
序列化协议 ( Serialization Protocol ),就词组上来看,重点是在 Serialization 上,但如果用 Protocol 来表示,也好像差的不太多,所以这里就取更短的 Protocol 作为序列化协议的模型。序列化协议也肯定都会有 encode / decode,所以可以建立一个简单的 Protocol 模型如下:
interface Protocol {
encode(): Promise<void>;
decode(): Promise<void>;
}
接下来的问题就是怎么组合使用这两个模型了。一般来说,根据人的习惯,都是先想好说什么然后再开口说话的,所以我们把 Protocol 模型放在 Connection 模型之前,就可以得到如下的一条调用路径:
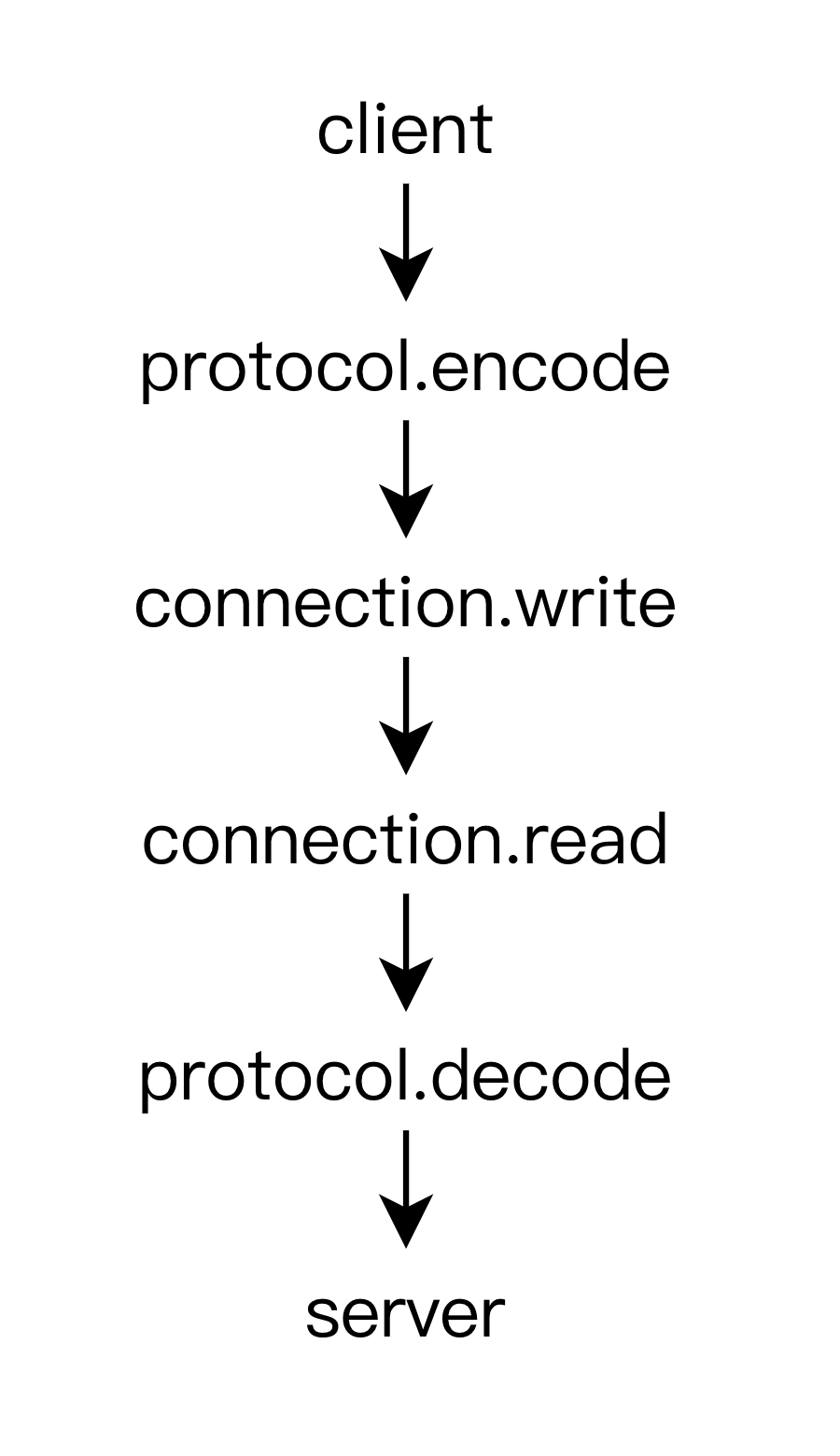
上面的调用路径虽然看起来简洁,但太过于简单,并没有说明具体是怎样的调用方式。而在实际的 RPC 调用中,可能会存在多种调用方式,比如:TCP Socket 随意读写,HTTP 一次 Request 对应一次 Response,HTTP2 一次 Request 对应多次 Response,所以这里必定还缺了些什么东西来抽象这些具体的 RPC 调用方式。在这里我们使用 Handle 来作为调用方式的模型抽象,它代表的是一次 RPC 该如何去调用,其模型如下:
interface Handle {
execute(): Promise<any>;
}
这样就可以将调用路径改成如下的形式:
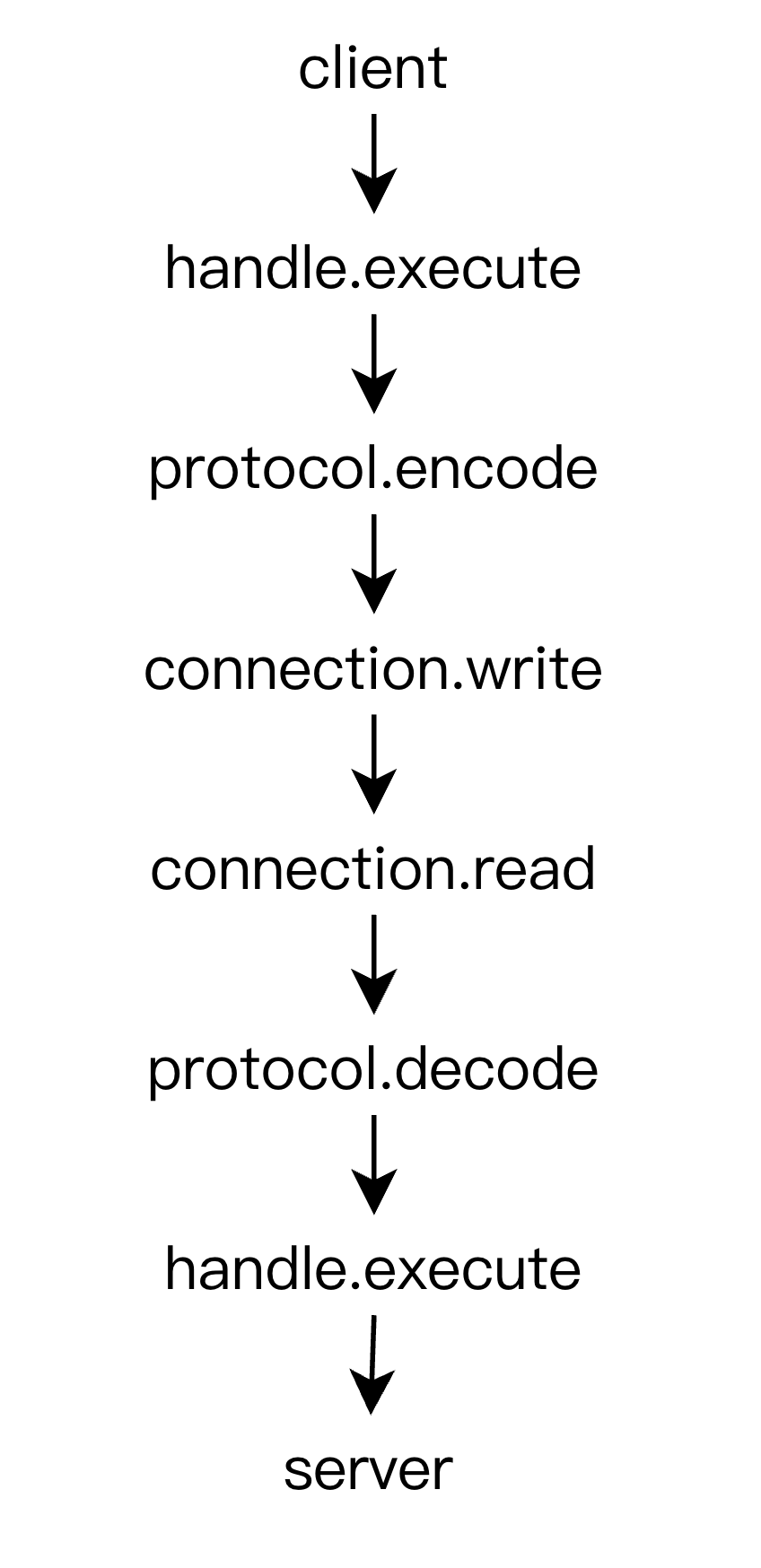
到这里我们就可以根据上面的调用路径写一下伪代码了,伪代码如下:
createServer((socket) => {
const connection = new ServerConnection(socket);
const protocol = new ServerProtocol();
const handle = new ServerHandle((ctx) => {
console.log('Server got', ctx.request);
ctx.response = { pong: 'pong' };
});
const ctx = { connection, protocol, handle } as Context;
(async () => {
/**
* 内部执行
* const buf = await ctx.connection.read();
* ctx.request = ctx.protocol.decode(buf);
* ...
* const buf = ctx.protocol.encode(ctx.response);
* await ctx.connection.write(buf);
*/
await handle.execute(ctx);
})();
}).listen(3000);
(async () => {
const socket = connect({ port: 3000 });
const connection = new ClientConnection(socket);
const protocol = new ClientProtocol();
const handle = new ClientHandle();
const ctx = { connection, protocol, handle } as Context;
ctx.request = { ping: 'ping' };
/**
* 内部执行
* const buf = ctx.protocol.encode(ctx.request);
* await ctx.connection.write(buf);
* ...
* const buf = await ctx.connection.read();
* ctx.response = ctx.protocol.decode(buf);
*/
await handle.execute(ctx);
console.log('Client got', ctx.response);
})();
在这个伪代码中,Handle、Protocol、Connection 实现都是可以自由替换的,换句话说,我们只需要实现了 TCP Connection、HTTP Connection、Thrift Protocol、Protobuf Protocol,就可以做到 Thrift on TCP、Protobuf on TCP、Thrift on HTTP、Protobuf on HTTP。
但在后续的实现过程中,我们遇到了一个问题:由于创建 Socket 与监听 Server 都是比较复杂的行为,特别是还需要考虑到服务发现、Service Mesh、连接池等的存在,这导致了 Connection 的实现代码变得极其复杂,并且与 Server 实现严重耦合,稍微有一点不同就会产生大量冗余代码。
因此为了解决这个问题,我们为 Connection 模型引入了 ConnectionProvider 模型,让其负责 Connection 的创建与回收,考虑服务发现、Service Mesh、连接池等问题。
Tips:出于对称设计原则的考虑,也为 Protocol 模型引入了 ProtocolProvider 模型。
模型总览
最终所有涉及到的模型如下:
Connection:网络协议,专注于网络 IO 性能,只关心网络 IO 读写与 IO 事件处理,不关心任何序列化相关的事情。 Protocol:序列化协议,专注于运算 CPU 性能,不关心任何网络相关的事情。 Handle:RPC 调用方式,用于描述一次 RPC 该如何去调用。 ConnectionProvider:网络协议生产者,用于解除 Client、Server 与具体 Connection 模型实现之间的耦合。 ProtocolProvider:序列化协议生产者,出于对称设计考虑,暂时没有太多的作用。 Context:RPC 调用上下文,是整个 RPC 调用过程的信息载体。 ConfigCenter:配置中心,用于远程配置扩展。 Middleware:中间件,用于外部功能扩展。
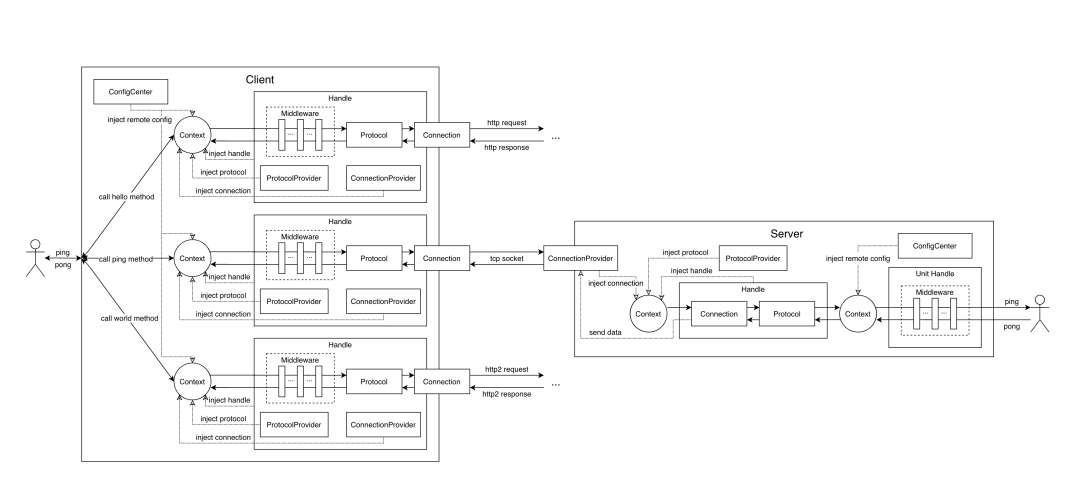
Tips:Unit Handle 是为了实现 Service、Method 级别中间件而加入的设计,本质上与 Handle 一样。
遇到的问题
创建 Client 与 Server
从上面的模型总览中来看,涉及到的模型还是比较多的,这也导致了 Client 与 Server 的创建过程会比较繁琐,不容易理解,所以在我们的 RPC 实现中,同时对外提供了两套 API。
对于普通业务开发同学,可以使用封装好的 createClient() 与 createServer() API,自动集成了字节跳动内大多数基建 ( Logger、Metrics、Trace、Service Mesh 等 )。 对于有定制化需求的同学,可以使用 Client 与 Server API,来获得更自由的 RPC 使用体验。
多协议嵌套
在实际应用中,我们发现 Protocol 模型还是太过于简单了。根据公司体量的大小、技术债的积累程度,最终都会不可避免的会出现协议变种、协议组合的情况,这时需要实现的协议可能就会出现成倍的增长。以我们内部情况为例:在字节跳动的 RPC 调用中,同时存在着 Binary Thrift、TTHeader + Binary Thrift、Framed Thrift、Mesh + TTHeader + Binary Thrift 等情况。
所以我们通过人为的将 Protocol 模型分为 HeaderProtocol 与 PayloadProtocol 模型,并通过 connection.cork、connection.uncork 与动态 buffer 技巧实现了多协议组合,伪代码如下:
class DynamicBuffer {}
connection.cork(new DynamicBuffer());
await payloadProtocol.encode(ctx);
let payload = connection.uncork();
for (let i = headerProtocols.length - 1; i >= 1; i--) {
const headerProtocol = headerProtocols[i];
connection.cork(new DynamicBuffer());
await headerProtocol.encode(ctx, payload);
payload = connection.uncork();
}
await headerProtocols[0].encode(ctx, payload);
Tips: 由于是人为规定的分类,所以:
HeaderProtocol 模型不意味着实现没有 payload 部分,只是经常作为在外部的序列化协议使用。 PayloadProtocol 模型不意味着实现没有 header 部分,只是经常作为在内部的序列化协议使用。
Context 扩展性能
在后续的性能测试中,我们发现在 Middleware 中对 Context 进行扩展时,消耗了大量性能。通过排查发现,是由于业务属性需要,大量运用了 Object.defineProperty()、Object.defineProperties() 等 API 所导致的。比如我们需要在 Context 上动态创建 ctx.logId 属性,并将它存储到 ctx.tags.log_id,那么代码基本上需要写成这样:
const ctx = { tags: { log_id: '' } };
Object.defineProperty(ctx, 'logId', {
get() {
return ctx.tags.log_id;
},
set(logId: string) {
ctx.tags.log_id = logId;
},
});
需要消耗一次 Object.defineProperty() 的性能。如果这时还需要同时兼容 ctx.log_id 的获取与设置方式,那么消耗的性能将翻一倍,因此这种做法的性能基本上好不到哪里去。但如果通过 class extend 的形式扩展,又会陷入实现与具体 Middleware 耦合的尴尬境地。所以我们参考 fastify.decorate()[1] 的实现,通过动态修改 Context 原型,来实现了近乎零消耗的 Context 扩展能力。
总结
在本文中,我们聊到了 RPC 的设计细节,从最基础的 RPC 分解,到模型设计,再到落地中遇到的问题。但如果要实现一个完善的 RPC 库,所涉及到的细节将远非这些,同时也会有许多其它概念将会对现有的模型造成冲击,这需要我们耐心分析其本质,并将这些概念逐步的融入到设计实现中。
在我们内部的 RPC 实现中,已经支持了 Thrift 序列化协议与 TCP、HTTP 网络协议,在不久后的将来也会支持 JSON、Protobuf 与 HTTP/2,甚至可能会将这套设计搬上浏览器,让前端可以直接在浏览器上发起 RPC 调用,来丰富前后端调用技术选型,促进框架生态发展。


“分享、点赞、在看” 支持一波 