
源码上看 .NET 中 StringBuilder 拼接字符串的实现
前几天写了一篇StringBuilder与TextWriter二者之间区别的文章(链接)。当时提了一句没有找到相关源码,于是随后有很多热心人士给出了相关的源码链接(链接),感谢大家。这几天抽了点时间查看了下StringBuilder是如何动态构造字符串的,发现在.NET Core中字符串的构建似乎和我原先猜想的并不完全一样,故此写了这篇文章,如有错误,欢迎指出。
StringBuilder字段和属性
字符数组
明确一点的是,StringBuilder的内部确实使用字符数组来管理字符串信息的,这一点上和我当时的猜测是差不多的。相较于字符串在大多数情况下的不变性而言,字符数组有其优点,即修改字符数组内部的数据不会全部重新创建字符数组(字符串的不变性)。下面是StringBuilder的部分源码,可以看到,内部采用m_ChunkChars字段存储字符数组信息。
public sealed class StringBuilder
{
internal char[] m_ChunkChars;
...
}
然而,采用字符数组并不是没有缺点,数组最大的缺点就是在在使用前就需要指定它的空间大小,这种固定大小的数组空间不可能有能力处理多次的字符串拼接,总有某次,数组中的空余部分塞不下所要拼接的字符串。如果某次拼接的字符串超过数组的空闲空间时,一种易想到做到的方法就是开辟一个更大的空间,并将原先的数据复制过去。这种方法能够保证数组始终是连续的,然而,它的问题在于,复制是一个非常耗时的操作,如非必要,尽可能地降低复制的频率。在.NET Core中,StringBuilder采用了一个新方法避免了复制操作。
单链表
为了能够有效地提高性能,StringBuilder采用链表的形式规避了两个字符数组之间的复制操作。在其源代码中,可以发现每个StringBuilder内部保留对了另一个StringBuilder的引用。
public sealed class StringBuilder
{
internal StringBuilder? m_ChunkPrevious;
...
}
在StringBuilder中,每个对象都维护了一个m_ChunkPrevious引用,按字段命名的意思来说,就是每个类对象都维护指向前一个类对象的引用。这一点和我们常见的单链表结构有点一点不太一样,常见的单链表结构中每个节点维护的是指向下一个节点的引用,这和StringBuilder所使用的模式刚好相反,挺奇怪的。整理下,这部分有两个问题:
为什么说采用单链表能避免复制操作?
为什么采用逆向链表,即每个节点保留指向前一个节点的引用?
对于第一个问题,试想下,如果又有新的字符串需要拼接且其长度超过字符数组空闲的容量时,可以考虑新开辟一个新空间专门存储超额部分的数据。这样,先前部分的数据就不需要进行复制了,但这又有一个新问题,整个数据被存储在两个不相连的部分,怎么关联他们,采用链表的形式将其关联是一个可行的措施。以上就是StringBuilder拼接字符串最为核心的部分了。
那么,对于第二个问题,采用逆向链表对的好处是什么?这里我给出的原因属于我个人的主观意见,不一定对。从我平时使用上以及一些开源类库中来看,对StringBuilder使用最广泛的功能就是拼接字符串了,即向尾部添加新数据。在这个基础上,如果采用正向链表(每个节点保留下一个节点的引用),那么多次拼接字符串在数组容量不够的情况下,势必需要每次循环找到最后一个节点并添加新节点,时间复杂度为O(n)。而采用逆向链表,因为用户所持有的就是最后一个节点,只需要在当前节点上做些处理就可以添加新节点,时间复杂度为O(1)。因此,StringBuilder内的字符数组可以说是字符串的一个部分,也被称为Chunk。
举个例子,如果类型为
Stringbuilder变量sb内已经保存了HELLO字符串,再添加WORLD时,如果字符数组满了,再添加就会构造一个新StringBuilder节点。注意的是调用类方法不会改变当前变量sb指向的对象,因此,它会移动内部的字符数组引用,并将当前变量的字符数组引用指向WORLD。下图中的左右两图是添加前后的说明图,其中黄色StringBuilder是同一个对象。
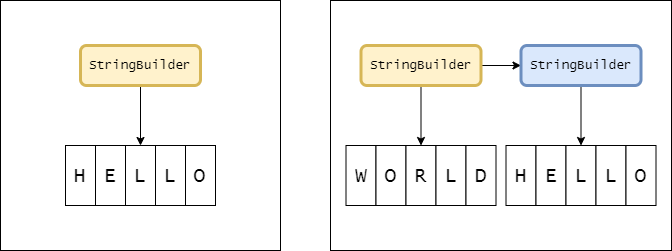
当然,采用链表并非没有代价。因为链表没有随机读取的功能。因此,如果向指定位置添加新数据,这反而比只使用一个字符数组来得慢。但是,如果前面的假设没错的话,也就是最频繁使用的是尾部拼接的话,那么使用链表的形式是被允许的。根据使用场景频率的不同,提供不同的实现逻辑。
各种各样的长度
剩下来的部分,就是描述各种各样的长度及其他数据。主要如下:
public sealed class StringBuilder
{
internal int m_ChunkLength;
internal int m_ChunkOffset;
internal int m_MaxCapacity;
internal const int DefaultCapacity = 16;
internal const int MaxChunkSize = 8000;
public int Length
{
get => m_ChunkOffset + m_ChunkLength;
}
...
}
m_ChunkLength描述当前Chunk存储信息的长度。也就是存储了字符数据的长度,不一定等于字符数组的长度。m_ChunkOffset描述当前Chunk在整体字符串中的起始位置,方便定位。m_MaxCapacity描述构建字符串的最大长度,通常设置为int最大值。DefaultCapacity描述默认设置的空间大小,这里设置的是16。MaxChunkSize描述Chunk的最大长度,也就是Chunk的容量。Length属性描述的是内部保存整体字符串的长度。
构造函数
上述讲述的是StringBuilder的各个字段和属性的意义,这里就深入看下具体函数的实现。首先是构造函数,这里仅列举本文所涉及到的几个构造函数。
public StringBuilder()
{
m_MaxCapacity = int.MaxValue;
m_ChunkChars = new char[DefaultCapacity];
}
public StringBuilder(string? value, int startIndex, int length, int capacity)
{
...
m_MaxCapacity = int.MaxValue;
if (capacity == 0)
{
capacity = DefaultCapacity;
}
capacity = Math.Max(capacity, length);
m_ChunkChars = GC.AllocateUninitializedArray<char>(capacity);
m_ChunkLength = length;
unsafe
{
fixed (char* sourcePtr = value)
{
ThreadSafeCopy(sourcePtr + startIndex, m_ChunkChars, 0, length);
}
}
}
private StringBuilder(StringBuilder from)
{
m_ChunkLength = from.m_ChunkLength;
m_ChunkOffset = from.m_ChunkOffset;
m_ChunkChars = from.m_ChunkChars;
m_ChunkPrevious = from.m_ChunkPrevious;
m_MaxCapacity = from.m_MaxCapacity;
...
}
这里选出了三个和本文关系较为紧密的构造函数,一个个分析。
首先是默认构造函数,该函数没有任何的输入参数。代码中可以发现,其分配的长度就是16。也就是说不对其做任何指定的话,默认初始长度为16个Char型数据,即32字节。
第二个构造函数是当构造函数传入为字符串时所调用的,这里我省略了在开始最前面的防御性代码。这里的构造过程也很简单,比较传入字符串的大小和默认容量
DefaultCapacity的大小,并开辟二者之间最大值的长度,最后将字符串复制到数组中。可以发现的是,这种情况下,初始字符数组的长度并不总是16,毕竟如果字符串长度超过16,肯定按照更长的来。第三个构造函数专门用来构造
StringBuilder的节点的,或者说是StringBuilder的复制,即原型模式。它主要用在容量不够构造新的节点,本质上就是将内部数据全部赋值过去。
从前两个构造函数可以看出,如果第一次待拼接的字符串长度超过16,那么直接将该字符串以构造函数的参数传入比构建默认
StringBuilder对象再使用Append方法更加高效,毕竟默认构造函数只开辟了16个char型空间。
Append方法
这里主要看StringBuilder Append(char value, int repeatCount)这个方法(位于第710行)。该方法主要是向尾部添加char型字符value,一共添加repeatCount个。
public StringBuilder Append(char value, int repeatCount)
{
...
int index = m_ChunkLength;
while (repeatCount > 0)
{
if (index < m_ChunkChars.Length)
{
m_ChunkChars[index++] = value;
--repeatCount;
}
else
{
m_ChunkLength = index;
ExpandByABlock(repeatCount);
Debug.Assert(m_ChunkLength == 0);
index = 0;
}
}
m_ChunkLength = index;
AssertInvariants();
return this;
}
这里仅列举出部分代码,起始的防御性代码以及验证代码略过。看下其运行逻辑:
依次循环当前字符
repeatCount次,对每一次执行以下逻辑。(while大循环)如果当前字符数组还有空位时,则直接向内部进行添加新数据。(if语句命中部分)
如果当前字符数组已经被塞满了,首先更新
m_ChunkLength值,因为数组被塞满了,因此需要下一个数组来继续放数据,当前的Chunk长度也就是整个字符数组的长度,需要更新。其次,调用了ExpandByABlock(repeatCount)函数,输入参数为更新后的repeatCount数据,其做的就是构建新的节点,并将其挂载到链表上。更新
m_ChunkLength值,记录当前Chunk的长度,最后将本身返回。
接下来就是ExpandByABlock方法的实现。
private void ExpandByABlock(int minBlockCharCount)
{
...
int newBlockLength = Math.Max(minBlockCharCount, Math.Min(Length, MaxChunkSize));
...
// Allocate the array before updating any state to avoid leaving inconsistent state behind in case of out of memory exception
char[] chunkChars = GC.AllocateUninitializedArray<char>(newBlockLength);
// Move all of the data from this chunk to a new one, via a few O(1) pointer adjustments.
// Then, have this chunk point to the new one as its predecessor.
m_ChunkPrevious = new StringBuilder(this);
m_ChunkOffset += m_ChunkLength;
m_ChunkLength = 0;
m_ChunkChars = chunkChars;
AssertInvariants();
}
和上面一样,仅列举出核心功能代码。
设置新空间的大小,该大小取决于三个值,从当前字符串长度和Chunk最大容量取较小值,然后从较小值和输入参数长度中取最大值作为新Chunk的大小。值得注意的是,这里当前字符串长度通常是Chunk已经被塞满的情况下,可以理解成所有Chunk的长度之和。
开辟新空间。
通过上述最后一个构造函数,构造向前的节点。当前节点仍然为最后一个节点,更新其他值,即偏移量应该是原先偏移量加上一个Chunk的长度。清空当前Chunk的长度以及将新开辟空间给Chunk引用。
对于Append(string? value)这个函数的实现功能和上述说明是差不多的,基本都是新数据先往当前的字符数组内塞,如果塞满了就添加新节点并刷新当前字符数组数据再塞。详细的功能可以从L802开始看。这里不做过多说明。
验证
当然,以上只是阅读代码的流程,具体是否正确还可以做点测试来验证。这里我做了一个小测试demo。
var sb = new StringBuilder();
sb.Append('1', 10);
sb.Append('2', 6);
sb.Append('3', 24);
sb.Append('4', 15);
sb.Append("hello world");
sb.Append("nice to meet you");
Console.WriteLine($"结果:{sb.ToString()}");
var p = sb;
char[] data;
Type type = sb.GetType();
int count = 0;
while (p != null)
{
count++;
data = (char[])type.GetField("m_ChunkChars", BindingFlags.NonPublic | BindingFlags.Instance).GetValue(p);
Console.WriteLine($"倒数第{count}个StringBuilder内容:{new string(data)}");
p = (StringBuilder)type.GetField("m_ChunkPrevious", BindingFlags.NonPublic | BindingFlags.Instance).GetValue(p);
}
这里主要做的是利用Append方法添加不同的数据并将最终结果输出。考虑到内部的细节并没有对外公开,只能通过反射的操作来获取,通过遍历每一个StringBuilder的节点,反射获取内部的字符数组并将其输出。最终的结果如下。
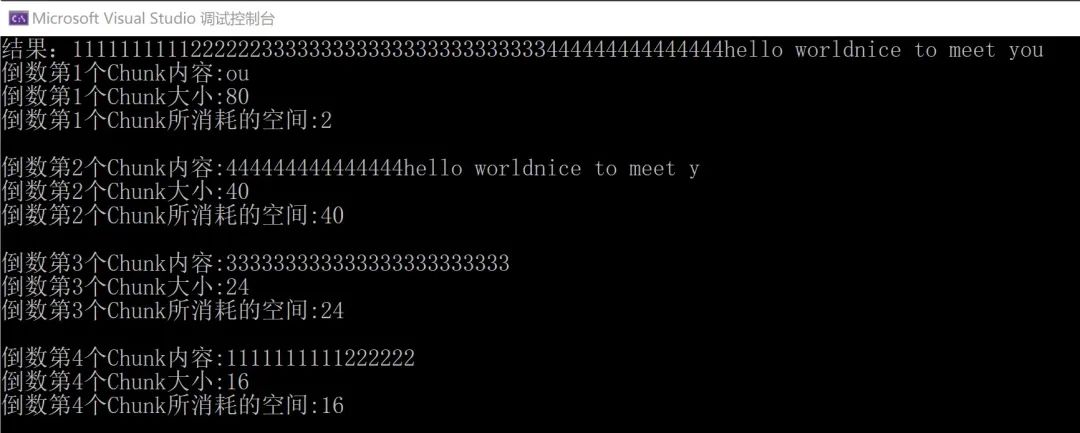
这里分析下具体的过程:
第一句
sb = new StringBuilder()。从之前的构造函数代码内可以得知,无参构造函数会生成一个16长度的字符数组。第二句
sb.Append('1', 10)。这句话意思是向sb内添加10个1字符,因为添加的长度小于给定的默认值16,因此直接将其添加即可。第三句
sb.Append('2', 6)。在经过上面添加操作后,当前字符数组还剩6个空间,刚好够塞,因此直接将6个2字符直接塞进去。第四句
sb.Append('3', 24)。在添加字符3之前,StringBuilder内部的字符数组就已经没有空间了。为此,需要构造新的StringBuilder对象,并将当前对象内的数据传过去。对于当前对象,需要创建新的字符数组,按照之前给出的规则,当前Chunk之和(16)和Chunk长度(8000)取最小值(16),最小值(16)和输入字符串长度(24)取最大值(24)。因此,直接创建24个字符空间并存下来。此时,sb对象有一个前置节点。第五句
sb.Append('4', 15)。上一句代码只创建了长度为24的字符数组,因此,新数据依然无法再次塞入。此时,依旧需要创建新的StringBuilder节点,按照同样的规则,取当前所有Chunk之和(16+24=40)。因此,新字符数组长度为40,内部存了15个字符数据4。sb对象有两个前置节点。第六句
sb.Append("hello world")。这个字符串长度为11,当前字符数组能完全放下,则直接放下。此时字符数组还空余14个空间。第七句
sb.Append("nice to meet you")。这个字符串长度为16,可以发现超过了剩余空间,首先先填充14个字符。之后多出的2个,则按照之前的规则再构造新的节点,新节点的长度为所有Chunk之和(16+24+40=80),即有80个存储空间。当前Chunk只存储最后两个字符ou。sb对象有3个前置节点。符合最终的输出结果。
总结
总的来说,采用定长的字符数组来保存不定长的字符串,不可能完全避免所添加的数据超出剩余空间这样的情况,重新开辟新空间并复制原始数据过于耗时。StringBuilder采用链表的形式取消了数据的复制操作,提高了字符串连接的效率。对于StringBuilder来说,大部分的操作都在尾部添加,采用逆向链表是一个不错的形式。当然StringBuilder这个类本身有很多复杂的实现,本篇只是介绍了Append方法是如何进行字符串拼接的。