深入理解Linux内核之主调度器(上)
1.开场白
环境:
处理器架构:arm64
内核源码:linux-5.11
ubuntu版本:20.04.1
代码阅读工具:vim+ctags+cscope
本文步进到Linux内核进程管理的核心部分,打开调度器的黑匣子,来看看Linux内核如何调度进程的。实际上,进程调度器主要做两件事:选择下一个进程,然后进行上下文切换。而何时调用主调度器调度进程那是调度时机所关注的问题,而调度时机在之前的内核抢占文章已经做了详细讲解,在此不在赘述,而本文关注的调度时机是真正调用主调度器的时机。
本文分析的内核源代码主要集中在:
kernel/sched/core.c
kernel/sched/fair.c
2.调用时机
关于调度时机,网上的文章也五花八门,之前在内核抢占文章已经做了详细讲解,而在本文我们从源码注释中给出依据(再次强调一下:本文的调度时机关注的是何时调用主调度器,不是设置重新调度标志的时机,之前讲解中我们知道他们都可以称为调度时机)。
先来说一下什么是主调度器,其实和主调度器并列的还有一个叫做周期性调度器的东西(后面有机会会讲解,主要用于时钟中断tick调来使夺取处理器的控制权),他们都是内核中的一个函数,在合适的时机被调用。
主调度器函数如下:
kernel/sched/core.c
__schedule()
内核的很多路径会包装这个函数,主要分为主动调度和抢占式调度场景。
内核源码中主调度器函数也给出了调度时机的注释,下面我们就以此为依据来看下:
kernel/sched/core.c
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPTION=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPTION is not set)
* then at the next:
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
static void __sched notrace __schedule(bool preempt)
我们对注释做出解释,让大家深刻理解调度时机(基本上是原样翻译,用颜色标注)。
1.显式阻塞场景:包括互斥体、信号量、等待队列等。
这个场景主要是为了等待某些资源而主动放弃处理器,来调用主调度器,如发现互斥体被其他内核路径所持有,则睡眠等待互斥体被释放的时候来唤醒我。
解释如下:这实际上是说重新调度标志(TIF_NEED_RESCHED)的设置和检查的情形。
1)重新调度标志设置情形:如scheduler_tick周期性调度器按照特定条件设置、唤醒的路径上按照特定条件设置等。当前这样的场景并不会直接调用主调度器,而会在最近的调度点到来时调用主调度器。
2)重新调度标志检查情形:是真正的调用主调度器,下面的场景都会涉及到,在此不在赘述。
3.唤醒并不会真正导致schedule()的进入。他们添加一个任务到运行队列,仅此而已。
现在,如果添加到运行队列中的新任务抢占了当前任务,那么唤醒设置TIF_NEED_RESCHED, schedule()在最近的可能情况下被调用:
1)如果内核是可抢占的(CONFIG_PREEMPTION=y)
-在系统调用或异常上下文中,最外层的preempt_enable()。(这可能和wake_up()的spin_unlock()一样快!)
-在IRQ上下文中,从中断处理程序返回到抢占上下文
注释中很简洁的几句话,但其中的含义需要深刻去体会。
首先需要知道一点是:内核抢占说的是处于内核态的任务被其他任务所抢占的情况(无论是不是可抢占式内核,处于用户态的任务都可以被抢占,处于内核态的任务是否能被抢占由是否开启内核抢占来决定),当然内核态的任务可以是内核线程也可以是通过系统调用请求内核服务的用户任务。
情况1:这是重新开启内核抢占的情况,即是抢占计数器为0时,检查重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器(这是抢占式调度)。
情况2:中断返回内核态的时候,检查重新调度标志(TIF_NEED_RESCHED),如果设置且抢占计数器为0时则调用主调度器,放弃处理器(这是抢占式调度)。
注:关于内核抢占可以参考之前发布的文章。
2)如果内核是不可抢占的(CONFIG_PREEMPTION=y)
cond_resched()调用 显式的schedule()调用 从系统调用或异常返回到用户空间 从中断处理器返回到用户空间
解释如下:
cond_resched()是为了在不可抢占内核的一些耗时的内核处理路径中增加主动抢占点(抢占计数器是否为0且当前任务被设置了重新调度标志),则调用主调度器进行抢占式调度,所进行低延时处理。
显式的schedule()调用,这是主动放弃处理器的场景,如一些睡眠场景,像用户任务调用sleep。
系统调用或异常返回到用户空间使会判断当前进程是否设置重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器。
中断处理器返回到用户空间会判断当前进程是否设置重新调度标志(TIF_NEED_RESCHED),如果设置则调用主调度器,放弃处理器。
其实还有一种场景也会调用到主调度器让出处理器,那就是进程退出时,这里不在赘述。
下面给出总结:
1.主动调度:
睡眠场景,如sleep。
显式阻塞场景,如互斥体,信号量,等待队列,完成量等。
任务退出时,调用do_exit去释放进程资源,最后会调用一次主调度器
2.抢占调度:
不可抢占式内核
cond_resched()调用
显式的schedule()调用
从系统调用或异常返回到用户空间
从中断处理器返回到用户空间
可抢占式内核(增加一些抢占点)
重新开启内核抢占
中断返回内核态的时候
3.主调度器调用时机源码窥探
下面给出主要的一些主调度器调用时机源码分析,作为学习参考。
3.1 常规场景
中断返回用户态场景:
arch/arm64/kernel/entry.S
el0_irq
-> ret_to_user
-> work_pending
-> do_notify_resume
-> if (thread_flags & _TIF_NEED_RESCHED) { // arch/arm64/kernel/signal.c
schedule();
-> __schedule(false); // kernel/sched/core.c false表示主动调度
异常返回用户态场景:
arch/arm64/kernel/entry.S
el0_sync
-> ret_to_user
...
任务退出场景:
kernel/exit.c
do_exit
->do_task_dead
->__schedule(false); // kernel/sched/core.c false表示主动调度
显式阻塞场景(举例互斥体):
kernel/locking/mutex.c
mutex_lock
->__mutex_lock_slowpath
->__mutex_lock
->__mutex_lock_common
->schedule_preempt_disabled
->schedule();
-> __schedule(false); // kernel/sched/core.c false表示主动调度
3.2 支持内核抢占场景
中断返回内核态场景
arch/arm64/kernel/entry.S
el1_irq
#ifdef CONFIG_PREEMPTION
->arm64_preempt_schedule_irq
->preempt_schedule_irq();
->__schedule(true); //kernel/sched/core.c true表示抢占式调度
#endif
内核抢占开启场景
preempt_enable
->if (unlikely(preempt_count_dec_and_test())) \ //抢占计数器减一 为0
__preempt_schedule(); \
->preempt_schedule //kernel/sched/core.c
-> __schedule(true) //调用主调度器进行抢占式调度
注:一般说异常/中断返回,返回是处理器异常状态,可能是用户态也可能是内核态,但是会看到很多资料写的都是用户空间/内核空间并不准确,但是我们认为表达一个意思,做的心中有数即可。
3.选择下一个进程
本节主要讲解主调度器是如何选择下一个进程的,这和调度策略强相关。
下面我们来看具体实现:
kernel/sched/core.c
__schedule
-> next = pick_next_task(rq, prev, &rf);
->if (likely(prev->sched_class <= &fair_sched_class &&
¦ rq->nr_running == rq->cfs.h_nr_running)) {
p = pick_next_task_fair(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto restart;
/* Assumes fair_sched_class->next == idle_sched_class */
if (!p) {
put_prev_task(rq, prev);
p = pick_next_task_idle(rq);
}
return p;
}
for_each_class(class) {
p = class->pick_next_task(rq);
if (p)
return p;
}
这里做了优化,当当前进程的调度类为公平调度类或者空闲调度类时,且cpu运行队列的进程个数等于cfs运行队列进程个数,说明运行队列进程都是普通进程,则直接调用公平调度类的pick_next_task_fair选择下一个进程(选择红黑树最左边的那个进程),如果没有找到说明当前进程调度类为空闲调度类,直接调用pick_next_task_idle选择idle进程。
否则,遍历调度类,从高优先级调度类开始调用其pick_next_task方法选择下一个进程。
下面以公平调度类为例来看如何选择下一个进程的:调用过程如下(这里暂不考虑组调度情况):
pick_next_task
->pick_next_task_fair //kernel/sched/fair.c
-> if (prev)
put_prev_task(rq, prev);
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
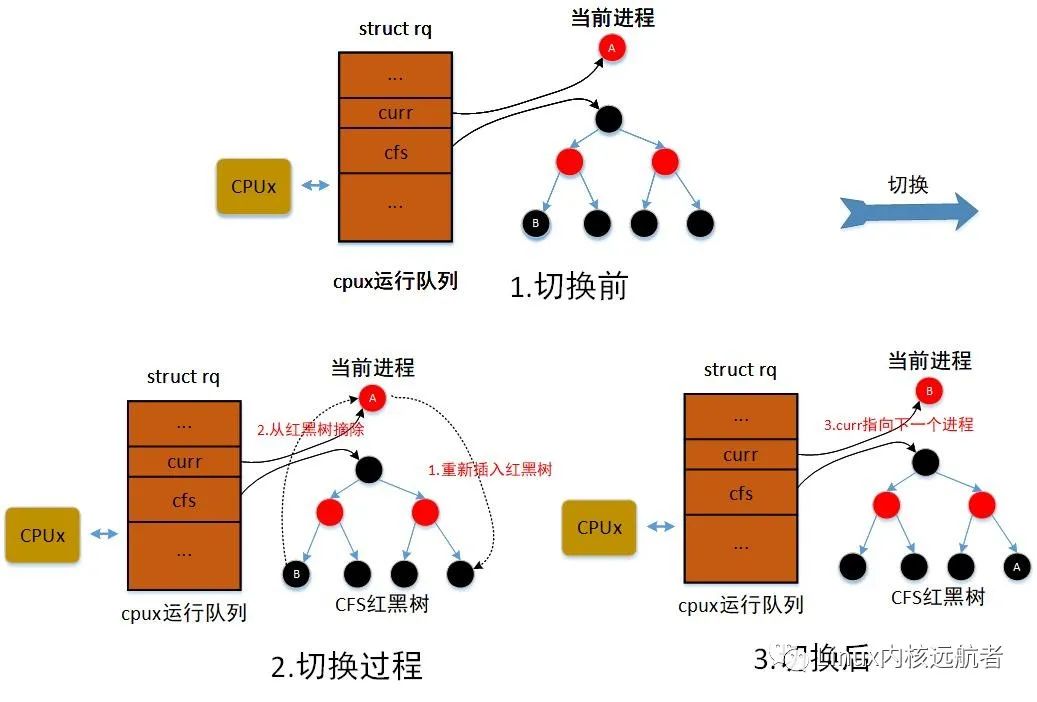
先看put_prev_task:
put_prev_task
->prev->sched_class->put_prev_task(rq, prev);
->put_prev_task_fair
->put_prev_entity(cfs_rq, se);
->/* Put 'current' back into the tree. */
__enqueue_entity(cfs_rq, prev);
cfs_rq->curr = NULL;
这里会调用__enqueue_entity将前一个进程重新加入到cfs队列的红黑树。然后将cfs_rq->curr 设置为空。
再看pick_next_entity:
pick_next_entity
->left = __pick_first_entity(cfs_rq);
->left = rb_first_cached(&cfs_rq->tasks_timeline);
将选择cfs队列红黑树最左边进程。
最后看set_next_entity:
set_next_entity
->__dequeue_entity(cfs_rq, se);
->cfs_rq->curr = se;
这里调用__dequeue_entity将下一个选择的进程从cfs队列的红黑树中删除,然后将cfs队列的curr指向进程的调度实体。
选择下一个进程总结如下:
运行队列中只有公平进程则选择公平调度类的pick_next_task_fair选择进程。
当前进程为idle进程,且没有公平进程存在情况下,调用pick_next_task_idle选择idle进程。
运行队列存在除了公平进程的其他进程,则从高优先级到低优先级调用具体调度类的pick_next_task选择进程。
对于公平调度类,选择下一个进程主要过程如下:1)调用put_prev_task方法将前一个进程重新加入cfs队列的红黑树。2)调用pick_next_entity 选择红黑树最左边的进程作为下一个进程。3)将下一个进程从红黑树中删除,cfs队列的curr指向进程的调度实体。
通用的调度类选择顺序为:
stop_sched_class -> dl_sched_class ->rt_sched_class -> fair_sched_class ->idle_sched_class
比如:当前运行队列都是cfs的普通进程,某一时刻发生中断唤醒了一个rt进程,那么在最近的调度点到来时就会调用主调度器选择rt进程作为next进程。
做了以上的工作之后,红黑树中选择下一个进程的时候就不会再选择到当前cpu上运行的进程了,而当前进程调度实体又被cfs队列的curr来记录着(运行队列的curr也会记录当前进程)。
下面给出公平调度类选择下一个进程图解(其中A为前一个进程,即是当前进程,即为前一个进程,B为下一个进程):