
微博图床挂了!
一直担心的事情还是发生了。
作为hexo多年的使用者,微博图床一直是我的默认选项,hexo+typora+iPic更是我这几年写文章的黄金组合。而图床中,新浪图床一直都是我的默认选项,速度快、稳定同时支持大图片批量上传更是让其成为了众多图床工具的默认选项。虽然今年早些的时候,部分如「ws1、ws2……」的域名就已经无法使用了,但通过某些手段还是可以让其存活的,而最近,所有调用的微博图床图片都无法加载并提示“403 Forbidden”了。
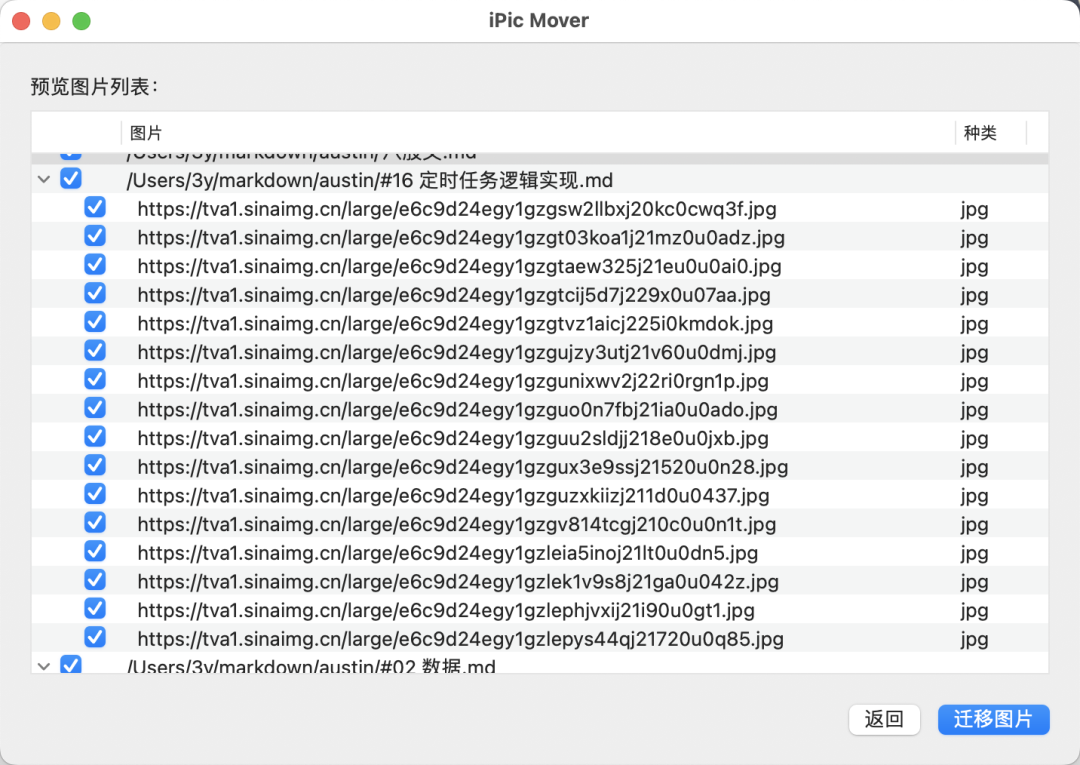
如果是Mac用户,又想偷懒,我这推荐ipic Move迁移工具,可以把微博的图床自动下载下来,转成ipic域名的图床。
💡Tips:图片中出现的Tengine是淘宝在Nginx的基础上修改后开源的一款Web服务器,基本上,Tengine可以被看作一个更好的Nginx,或者是Nginx的超集,详情可参考👉淘宝Web服务器Tengine正式开源 - The Tengine Web Server
刚得知这个消息的时候,我的第一想法其实是非常生气的,毕竟自己这几年上千张图片都是用的微博图床,如今还没备份就被403了,可仔细一想,说到底还是把东西交在别人手里的下场,微博又不是慈善企业,也要控制成本,一直睁一只眼闭一只眼让大家免费用就算了,出了问题还是不太好怪到微博上来的。
那么有什么比较好的办法解决这个问题呢?
查遍了网上一堆复制/粘贴出来的文章,不是开启反向代理就是更改请求头,真正愿意从根本上解决问题的没几个。
如果不想将自己沉淀的博客、文章托管在印象笔记、notion、语雀这些在线平台的话,想要彻底解决这个问题最好的方式是:自建图床!
为了更好的解决问题,我们先弄明白,403是什么,以及我们存在微博上的图片究竟是如何被403的。
403
百度百科,对于403错误的解释很简单
403错误是一种在网站访问过程中,常见的错误提示,表示资源不可用。服务器理解客户的请求,但拒绝处理它,通常由于服务器上文件或目录的权限设置导致的WEB访问错误。
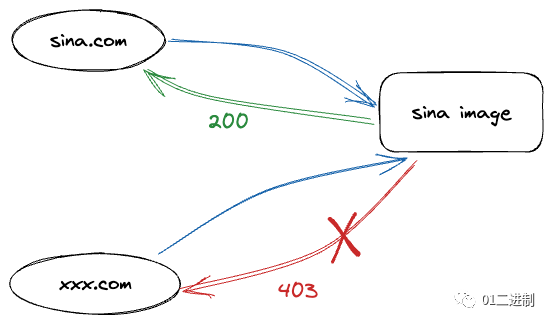
所以说到底是因为访问者无权访问服务器端所提供的资源。而微博图床出现403的原因主要在于微博开启了防盗链。
防盗链的原理很简单,站点在得知有请求时,会先判断请求头中的信息,如果请求头中有Referer信息,然后根据自己的规则来判断Referer头信息是否符合要求,Referer 信息是请求该图片的来源地址。
如果盗用网站是 https 的 协议,而图片链接是 http 的话,则从 https 向 http 发起的请求会因为安全性的规定,而不带 referer,从而实现防盗链的绕过。官方输出图片的时候,判断了来源(Referer),就是从哪个网站访问这个图片,如果是你的网站去加载这个图片,那么 Referer 就是你的网站地址;你的网址肯定没在官方的白名单内,(当然作为可操作性极强的浏览器来说 referer 是完全可以伪造一个官方的 URL 这样也也就也可以饶过限制🚫)所以就看不到图片了。
解决问题
解释完原理之后我们发现,其实只要想办法在自己的个人站点中设置好referer就可以解决这个问题,但说到底也只是治标不治本,真正解决这个问题就是想办法将图片迁移到自己的个人图床上。
现在的图床工具很多,iPic、uPic、PicGo等一堆工具既免费又开源,问题在于选择什么云存储服务作为自己的图床以及如何替换自己这上千张图片。
选择什么云存储服务
如何替换上千张图片
什么是OSS以及如何选择
「OSS」的英文全称是Object Storage Service,翻译成中文就是「对象存储服务」,官方一点解释就是对象存储是一种使用HTTP API存储和检索非结构化数据和元数据对象的工具。
白话文解释就是将系统所要用的文件上传到云硬盘上,该云硬盘提供了文件下载、上传等一列服务,这样的服务以及技术可以统称为OSS,业内提供OSS服务的厂商很多,知名常用且成规模的有阿里云、腾讯云、百度云、七牛云、又拍云等。
对于我们这些个人用户来说,这些云厂商提供的服务都是足够使用的,我们所要关心的便是成本💰。
笔者使用的是七牛云,它提供了10G的免费存储,基本已经够用了。
有人会考虑将GitHub/Gitee作为图床,并且这样的文章在中文互联网里广泛流传,因为很多人的个人站点都是托管在GitHub Pages上的,但是个人建议是不要这么做。
首先GitHub在国内的访问就很受限,很多场景都需要科学上网才能获得完整的浏览体验。再加上GitHub官方也不推荐将Git仓库存储大文件,GitHub建议仓库保持较小,理想情况下小于 1 GB,强烈建议小于 5 GB。
如何替换上千张图片
替换文章中的图片链接和“把大象放进冰箱里”步骤是差不多的
下载所有的微博图床的图片
上传所有的图片到自己的图床(xx云)
对文本文件执行replaceAll操作
考虑到我们需要迁移的文件数量较多,手动操作肯定是不太可行的,因此我们可以采用代码的方式写一个脚本完成上述操作。考虑到自己已经是一个成熟的Java工程师了,这个功能就干脆用Java写了。
为了减少代码量,精简代码结构,我这里引入了几个第三方库,当然不引入也行,如果不引入有一些繁琐而又简单的业务逻辑需要自己实现,有点浪费时间了。
整个脚本逻辑非常简单,流程如下:
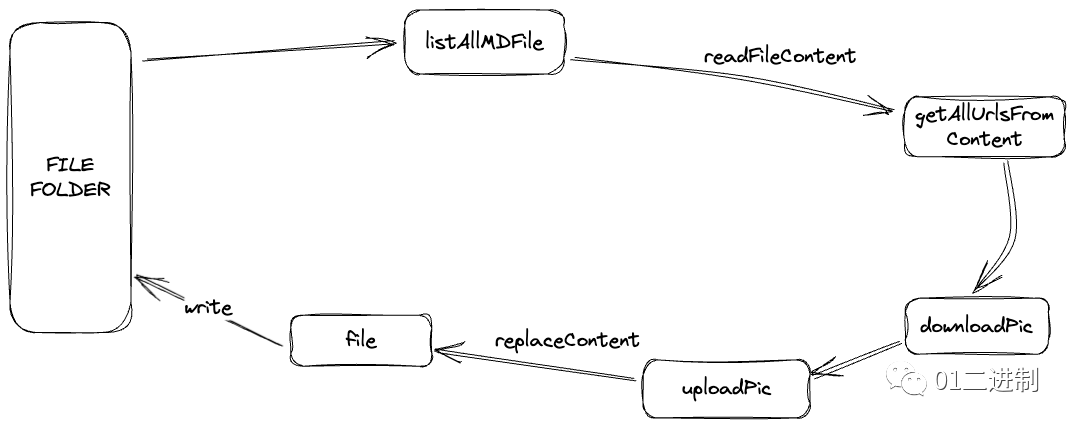
获取博客文件夹下的Markdown文件
这里我们直接使用hutool这个三方库,它内置了很多非常实用的工具类,获取所有markdown文件也变得非常容易
/**
* 筛选出所有的markdown文件
*/
public static List<File> listAllMDFile() {
List<File> files = FileUtil.loopFiles(VAULT_PATH);
return files.stream()
.filter(Objects::nonNull)
.filter(File::isFile)
.filter(file -> StringUtils.endsWith(file.getName(), ".md"))
.collect(Collectors.toList());
}
获取文件中的所有包含微博图床的域名
通过Hutools内置的FileReader我们可以直接读取markdown文件的内容,因此我们只需要解析出文章里包含微博图床的链接即可。我们可以借助正则表达式快速获取一段文本内容里的所有url,然后做一下filter即可。
/**
* 获取一段文本内容里的所有url
*
* @param content 文本内容
* @return 所有的url
*/
public static List<String> getAllUrlsFromContent(String content) {
List<String> urls = new ArrayList<>();
Pattern pattern = Pattern.compile(
"\\b(((ht|f)tp(s?)\\:\\/\\/|~\\/|\\/)|www.)" + "(\\w+:\\w+@)?(([-\\w]+\\.)+(com|org|net|gov"
+ "|mil|biz|info|mobi|name|aero|jobs|museum" + "|travel|[a-z]{2}))(:[\\d]{1,5})?"
+ "(((\\/([-\\w~!$+|.,=]|%[a-f\\d]{2})+)+|\\/)+|\\?|#)?" + "((\\?([-\\w~!$+|.,*:]|%[a-f\\d{2}])+=?"
+ "([-\\w~!$+|.,*:=]|%[a-f\\d]{2})*)" + "(&(?:[-\\w~!$+|.,*:]|%[a-f\\d{2}])+=?"
+ "([-\\w~!$+|.,*:=]|%[a-f\\d]{2})*)*)*" + "(#([-\\w~!$+|.,*:=]|%[a-f\\d]{2})*)?\\b");
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
urls.add(matcher.group());
}
return urls;
}
下载图片
用Java下载文件的代码在互联网上属实是重复率最高的一批检索内容了,这里就直接贴出代码了。
public static void download(String urlString, String fileName) throws IOException {
File file = new File(fileName);
if (file.exists()) {
return;
}
URL url = null;
OutputStream os = null;
InputStream is = null;
try {
url = new URL(urlString);
URLConnection con = url.openConnection();
// 输入流
is = con.getInputStream();
// 1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
// 输出的文件流
os = Files.newOutputStream(Paths.get(fileName));
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
} finally {
if (os != null) {
os.close();
}
if (is != null) {
is.close();
}
}
}
上传图片
下载完图片后我们便要着手将下载下来的图片上传至我们自己的云存储服务了,这里直接给出七牛云上传图片的文档链接了,文档里写的非常详细,我就不赘述了👇
Java SDK_SDK 下载_对象存储 - 七牛开发者中心
全局处理
通过阅读代码的细节,我们可以发现,我们的方法粒度是单文件的,但事实上,我们可以先将所有的文件遍历一遍,统一进行图片的下载、上传与替换,这样可以节约点时间。
统一替换的逻辑也很简单,我们申明一个全局Map,
private static final Map<String, String> URL_MAP = Maps.newHashMap();
其中,key是旧的新浪图床的链接,value是新的自定义图床的链接。
我们将listAllMDFile这一步中所获取到的所有文件里的所有链接保存于此,下载时只需遍历这个Map的key即可获取到需要下载的图片链接。然后将上传后得到的新链接作为value存在到该Map中即可。
全文替换链接并更新文件
有了上述这些处理步骤,接下来一步就变的异常简单,只需要遍历每个文件,将匹配到全局Map中key的链接替换成Map中的value即可。
/**
* 替换所有的图片链接
*/
private static String replaceUrl(String content, Map<String, String> urlMap) {
for (Map.Entry<String, String> entry : urlMap.entrySet()) {
String oldUrl = entry.getKey();
String newUrl = entry.getValue();
if (StringUtils.isBlank(newUrl)) {
continue;
}
content = RegExUtils.replaceAll(content, oldUrl, newUrl);
}
return content;
}
我们借助commons-lang实现字符串匹配替换,借助Hutools实现文件的读取和写入。
files.forEach(file -> {
try {
FileReader fileReader = new FileReader(file.getPath());
String content = fileReader.readString();
String replaceContent = replaceUrl(content, URL_MAP);
FileWriter writer = new FileWriter(file.getPath());
writer.write(replaceContent);
} catch (Throwable e) {
log.error("write file error, errorMsg:{}", e.getMessage());
}
});
为了安全起见,最好把文件放在新的目录中,不要直接替换掉原来的文件,否则程序出现意外就麻烦了。
接下来我们只需要运行程序,静待备份结果跑完即可。
推荐项目
如果想学Java项目的,我还是
强烈推荐
我的开源项目消息推送平台Austin,可以用作
毕业设计
,可以用作
校招
,可以看看
生产环境是怎么推送消息
的。
仓库地址(可点击阅读原文跳转):https://gitee.com/zhongfucheng/austin
我开通了
股东服务
内容,感兴趣可以点击下方看看,主要针对的是项目哟