
Hudi 演进 | Apache Hudi PMC 畅谈 Hudi 未来演进之路



大纲:
1.Hudi简介2.表元数据3.缓存4.社区

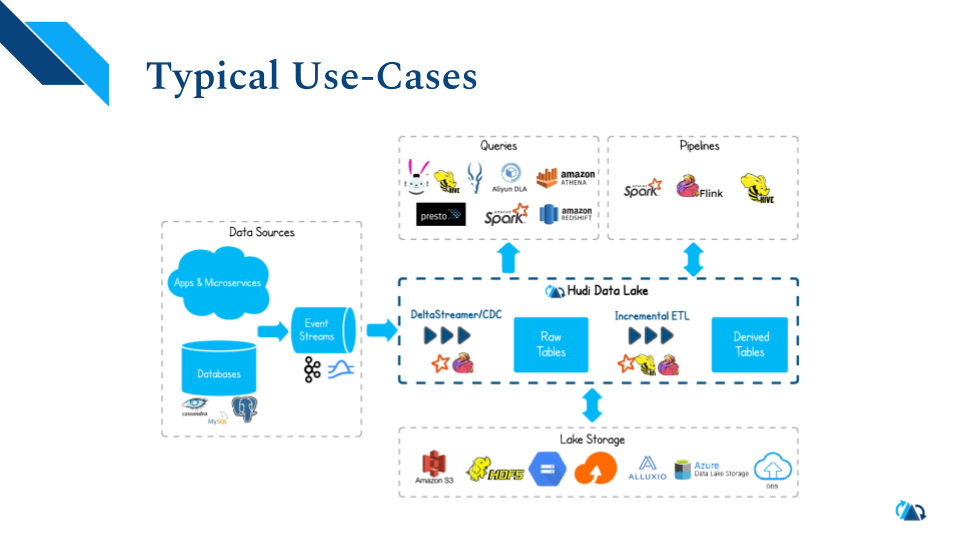
上图展示了大部分用户使用Hudi的场景。通常用Flink或者Spark或者Hudi内置工具DeltaStreamer读取数据源,写入原始表。这些表可以被不同的查询引擎读取,做常规的数据湖分析,或者做批处理。同时用Hudi提供的库可以搭建增量ETL管道,写入衍生表中。Hudi促进形成了一套生态系统,包含众多管理数据的功能,可以有效地分离高度优化的数据层和其上面搭建的查询层。
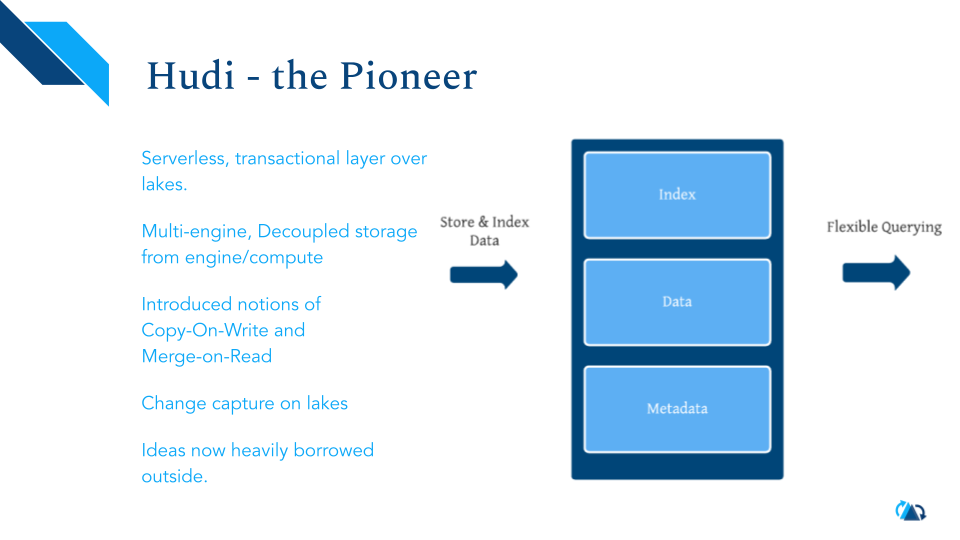
Hudi - 先行者
成立于2016年,Hudi项目是在数据湖上建立事务层系统的原创者。最初的设计是一个支持多引擎、与计算分离的存储系统。引入了Copy-On-Write和Merge-On-Read的概念,本质上提供了不同的组织管理数据的方式,迎合了快速写入和查询的需求。把变更捕获(change capture)引入了数据湖。很多这些概念被广泛地借鉴和采用了。

接下来快速的浏览Hudi主要功能特点。以上是我们技术栈里所有的层。建立在廉价的可扩展的存储上,也可以在内存文件系统上工作,比如Alluxio。完全建立在开放的格式上。在底层我们提供的是一个事务性的数据库核心,也是项目建立的初始理念。现在我们把这个成为表格式。还包括快速更删的索引,内置的后台运行的表服务,还有并行控制。表格式之上我们提供了一套读写API和SQL支持。在最上层提供了一套运行编排工具和平台服务。很多Hudi贡献者的开发贡献了各种各样的很棒的功能。

这里的介绍的核心点是,Hudi是一个平台。接下来的几个页面会快速过一下。
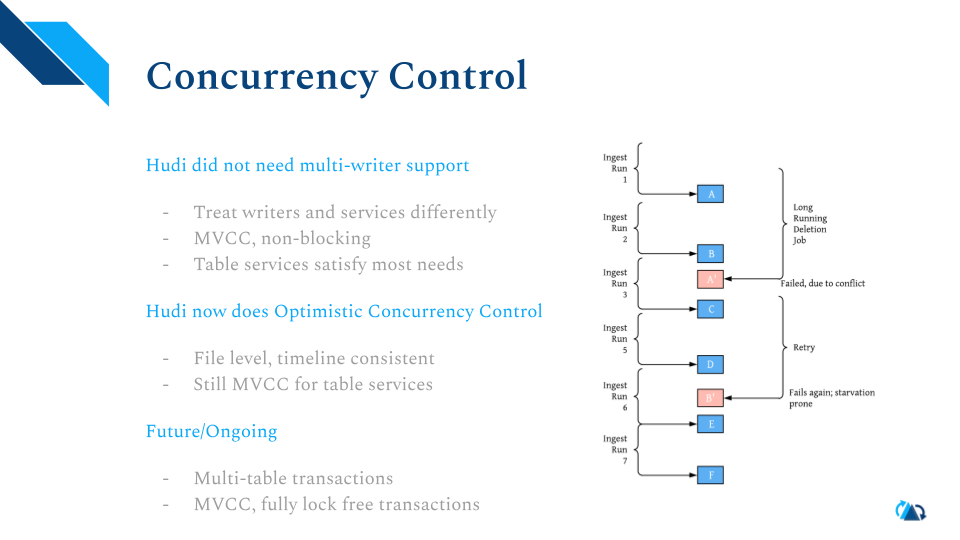
以上几页快速提到了表格式、文件格式、索引、并发控制、写入、读取、表服务和平台服务。重点提一下并发控制:Hudi内部的进程不会彼此阻塞,因为它们相互知晓。写入器自身目前用到了传统的锁模式控制,我们在朝着完全无锁的方向开发。

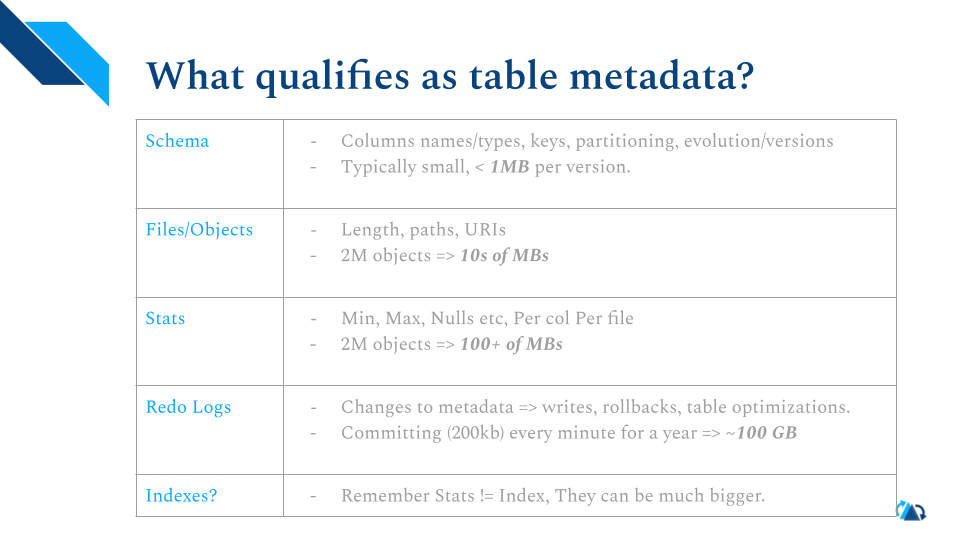
什么样的数据我们称为元数据?Schema,文件相关,统计数据,重做日志。至于索引,因为索引不等同于统计数据,量也可能很大,Hudi有另一套机制来管理,所以这里不把索引包含在元数据范围内介绍。

Hudi现在如何储存以上这些元数据呢?Schema存储在重做日志里,可以和不同的元数据存储服务同步。文件相关的存在一个内部的元数据Hudi表中。重做日志存在时间线文件夹".hoodie"。事务完成可以存档。统计数据目前没有单独存放,从footer里提取。有时候并行读取footer反而更快,尤其在云端存储上。

在高写入的场景下,把统计元数据写入额外的文件也会对读效率造成影响,以上的测试数据显示,1TB的快速写入文件,分成了16MB的块,若是100列的数据,则产生了650万以上的统计记录,读取需要10秒左右,会大幅降低查询规划的速度。Hudi RFC-27 在做的是基于区间树的范围查询可以大幅提高读取效率。
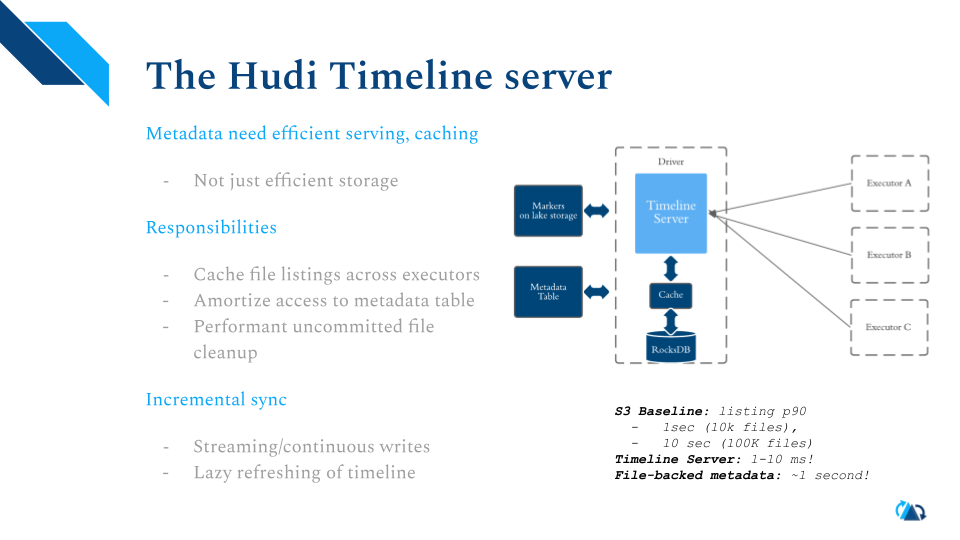
即使有了范围查询,读取效率还是很难满足需要join比如20-30个表的需求。假如每个表读取需要2秒,整个查询规划很难在1分钟内完成。Hudi 内置了元数据服务器,运行在driver上,为executor缓存了文件列举的结果,能缓解在云储存比如S3上限流的问题。内部的元数据Hudi表也利用了元数据服务器缓存查询结果,相当于给表建立了多级缓存。
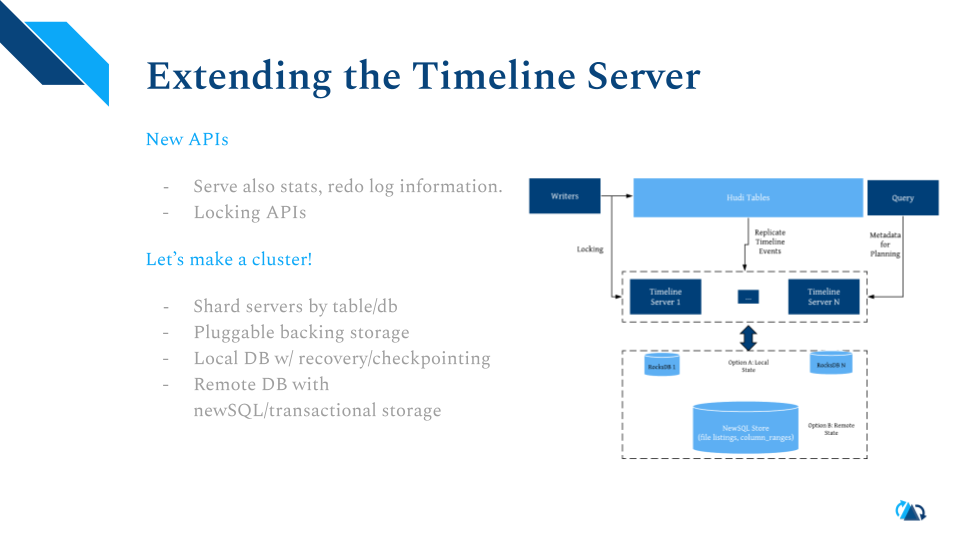
我们正在加大对元数据服务器扩展性的投入。比如开发关于统计,重做日志和锁定的API。也可以支持集群化,本地存档恢复,远程数据库集成等。


接下来介绍缓存的设计思路。频繁写入的场景会产生大量的commit,不可避免的产生了大量小文件。文件系统层面上的缓存很难满足性能需求。所以我们需要高效率的内存缓存。Hudi的文件组(FileGroup)是一个天生和缓存契合的模型。右图展示了文件组的概念:随着时间推移,新写入的文件(log file)会和本文件(base file)不断合并。同一个记录的更新会待在同一个文件组里。文件组是合并(compact)的最小单元,可以通过调节设置来使它匹配缓存容量大小,缓存合并后的数据可以很好地节省计算成本。

文件组的缓存可以是提前更新(Refresh-Ahead)模式,也可以是读时缓存(Read-Through)模式。在典型的更新捕获的场景中,我们可以做微合并(Micro-compact)来主动缓存。根据读的需求规律,可以调整读时缓存的设置,比如针对特定分区的前缀设置LRU或LFU。
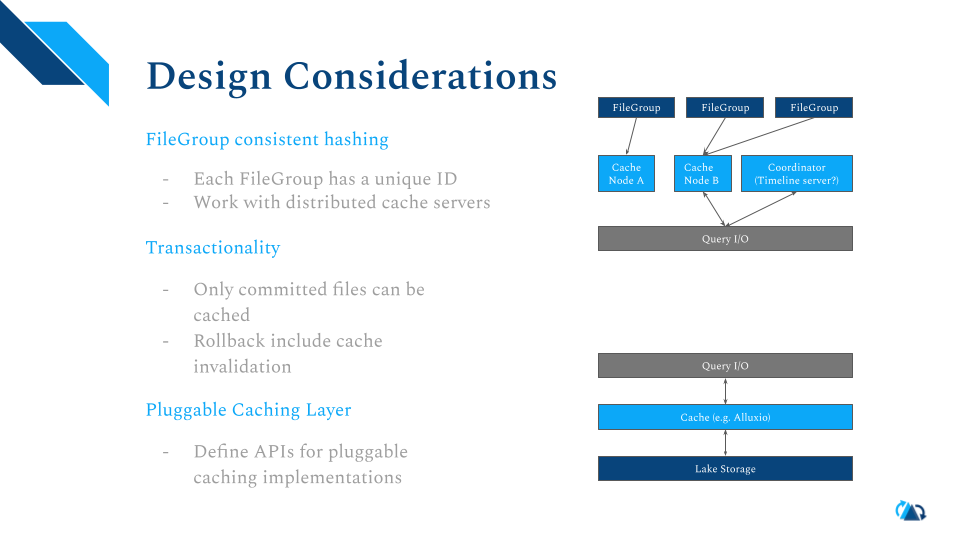
每个文件组都有唯一的ID,可以使用一致性哈希把缓存服务器扩展到分布式集群。考虑到Hudi本身的事务性,只有被commit的文件才可以被包括到缓存中,回滚操作也需要确保清空缓存。我们也考虑设计可插拔式的缓存层:只要支持了Hudi缓存API的缓存服务都可以被引入到架构里。

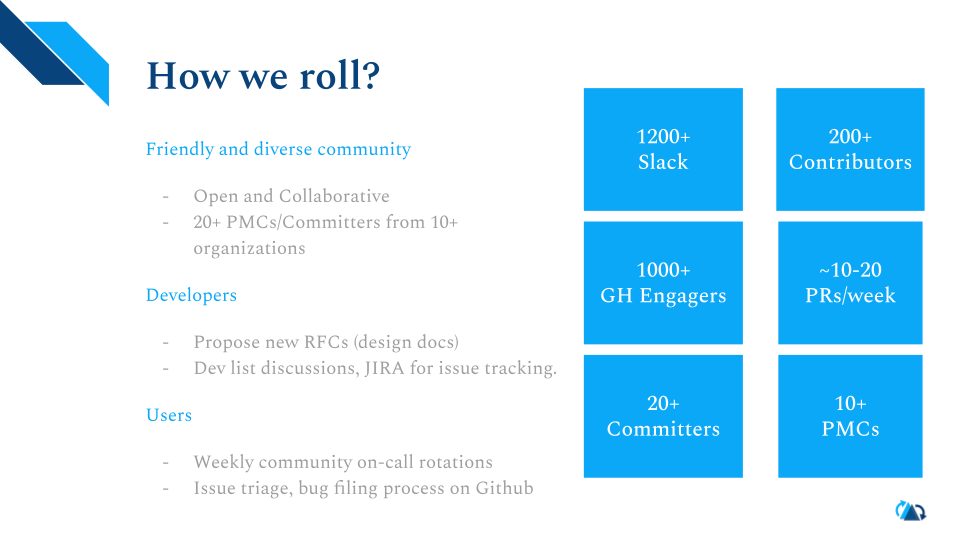 Hudi走到今天,得益于广大开发者给力的贡献。Slack上有1200+用户,GitHub有200+的贡献者,吸收了来自10+企业和组织的commiter和PMC。同时PMC和其他活跃者也对社区做着积极的维护。
Hudi走到今天,得益于广大开发者给力的贡献。Slack上有1200+用户,GitHub有200+的贡献者,吸收了来自10+企业和组织的commiter和PMC。同时PMC和其他活跃者也对社区做着积极的维护。


以上是一些正在开发的重大更新和功能。

Hudi已广泛地被众多企业采用。

感兴趣的同学欢迎通过以上方式(邮件列表、GitHub等)和社区进行互动。