
Python骚操作:一行代码实现探索性数据分析
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
dataprep.eda
在使用数据前,我们首先要做的是观察数据,包括查看数据的类型、数据的范围、数据的分布等。dataprep.eda是个非常不错的工具,它可以帮你快速生成数据概览。dataprep.eda包含的一些智能特性:
为每个 EDA 任务选择正确的图形来可视化数据 列类型推断(数字型、类别型和日期时间型) 选择合适的时间单位(用户也可以指定) 对数量庞大的类型数据输出清晰的可视化方案(用户也可以指定)
dataprep安装
安装dataprep仅需要执行pip instal dataprep即可,由于依赖比较多,安装过程比较慢,需要耐心等待。

如果报错,多半是权限问题,可以在后面加上--user

实例
为了看到这一点的实际应用,我们将使用一个泰坦尼克数据集,我们从数据集的概述开始:
from dataprep.eda import *import pandas as pdtrain_df = pd.read_csv('titanic/train.csv')train_df
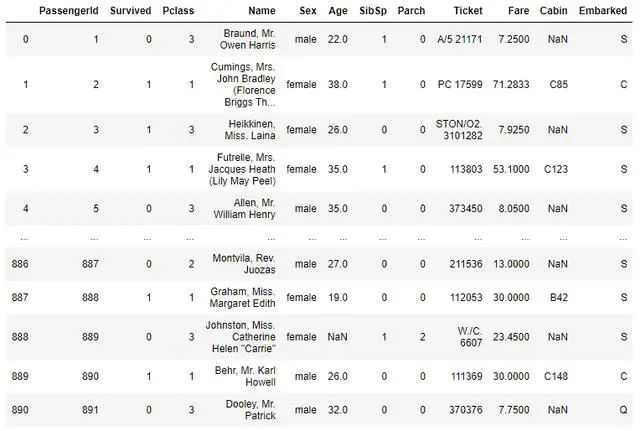
一行代码实现数据集可视化探索
plot(train_df)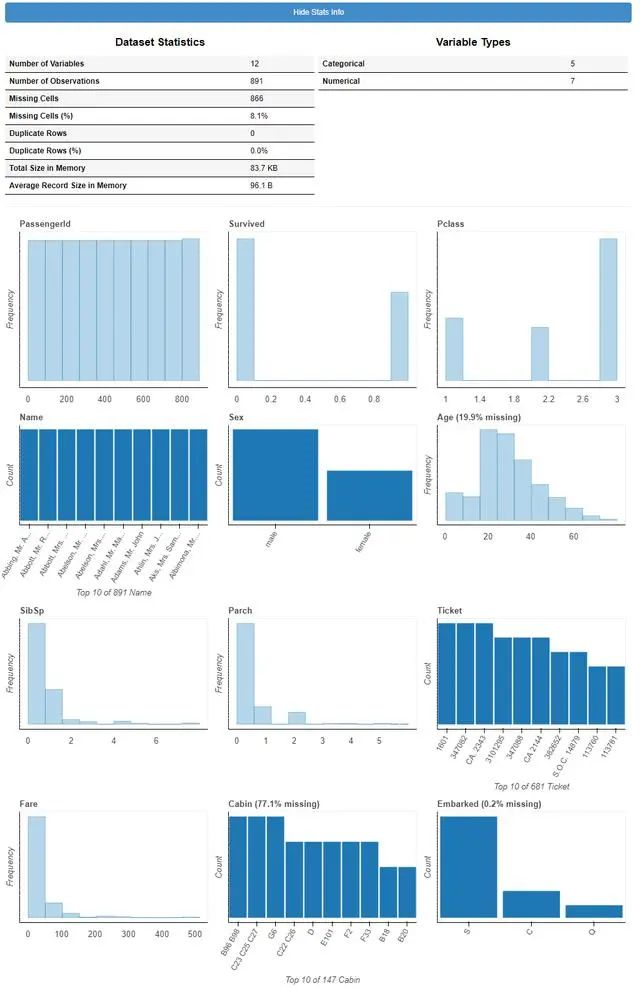
plot(df)显示每列的分布。对于分类列,它以蓝色显示条形图。对于数字列,它以灰色显示直方图。从图的输出,我们知道:
所有列:有1个标签列和11个特征 分类栏:幸存,PassengerId,Pclass,姓名,性别,票证,出发。 数字列:年龄,SibSp,parch,票价。 缺失值:从图形标题中,我们可以找到3列缺失值。即年龄(19.9%),机舱(77.1%),登机(0.2%)。 标签余额:来自幸存者的分布,我们知道,正面和负面的训练实例并不太平衡。 有38%的数据带有标签Survived = 1。当前,列类型(即分类或数字)基于输入数据框中的列类型。因此,如果某些列类型被错误地标识,则可以在数据框中更改其类型。例如,通过调用df [col] = df [col] .astype(“ object”),可以将col标识为分类列。
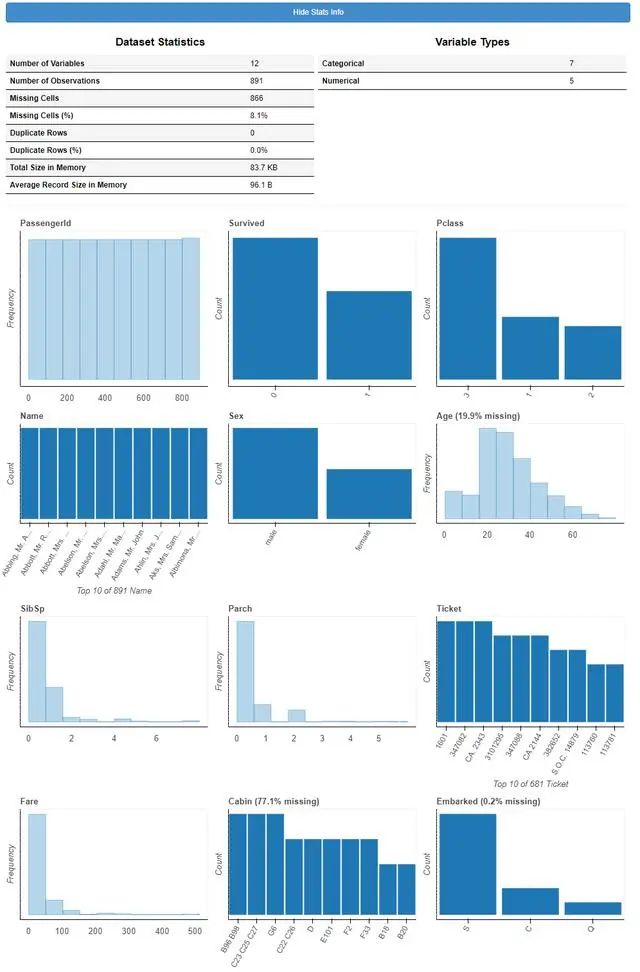
for col in ['Survived', 'Pclass']:train_df[col] = train_df[col].astype("object")plot(train_df)
要了解缺失值,我们首先调用plot_missing(df)来查看缺失值。
plot_missing(train_df)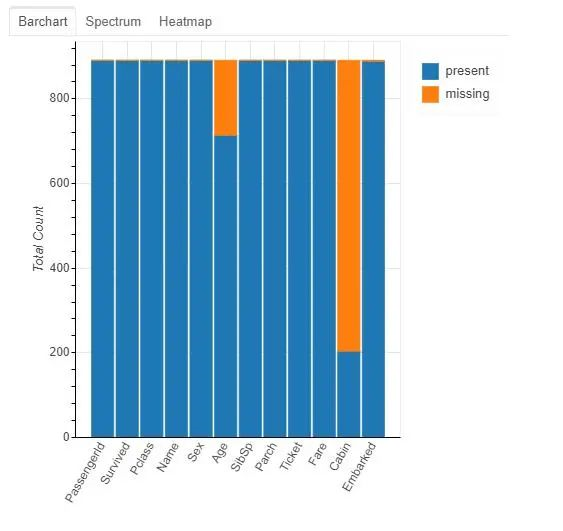
顶部是可选的,比如选择spectrum可以更具体的看出缺失情况
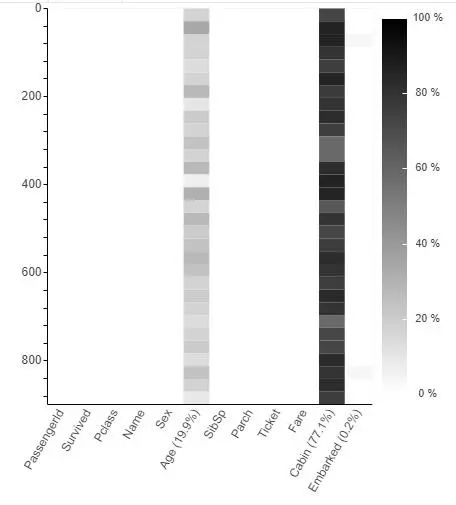
选择heatmap可以用热力图形式查看缺失情况
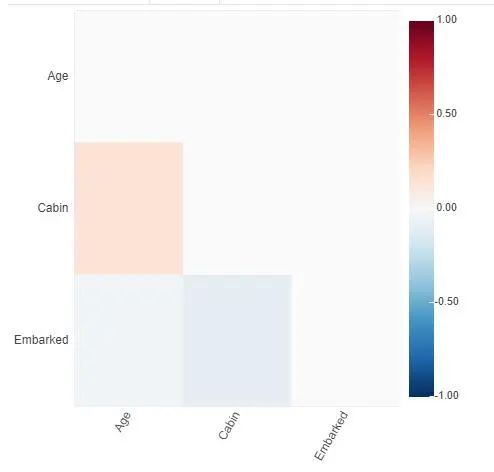
接下来,我们决定如何处理缺失值:如果要删除缺失特征,删除包含缺失值的行还是填充缺失值?我们首先分析它们是否与生存相关。如果它们是相关的,则我们可能不想删除该特征。我们通过调用plot(df,x,y)分析两列之间的相关性。这里就不展示了,大家可以探索一下,代码如下
for feature in ['Age', 'Cabin', 'Embarked']:plot(train_df, feature, 'Survived')
现在,我们逐一确定了有用的特征,并删除了无用的特征。虽然每个特征都可用于预测Survived,但是当我们将它们一起考虑时,我们可能不想要相关特征。因此,我们首先进行身份相关的特征。这可以通过简单地调用plot_correlation(df)来完成。

骚操作学到了吗?欢迎给个转发、在看、点赞支持
—END— 欢迎添加我的微信,更多精彩,尽在我的朋友圈。 ↓扫描二维码添加好友↓ 推荐阅读
(点击标题可跳转阅读)

评论