Selenium拦截页面后台请求及响应数据
selenium的设计并不支持对页面后台数据的获取,这在很大程度上限制的selenium的功能。但是如果有方法使selenium获取后台加载数据如同获取页面元素那么简单的话,对于selenium速度和功能都是很大的扩展。
Selenium官方开发团队明确告知不会增加Ajax数据获取的相关功能,要获取selenium控制下的页面后台交互数据,有两个思路。
一个是上一篇博客文章中的开启Selenium自带的日志记录器,可以获得交互的一些基本信息如请求地址请求头相关信息,但是无法获取响应内容;另一个思路是使用代理从而获取到数据交互的信息,使用代理的话又有两种实现方案,第一个使用mitmproxy,mitmproxy是Python开发的一款抓包工具,可以对记录的流量进行处理,并运行自定义处理脚本;另一个是使用browsermob-proxy代理库。browsermob-proxy是一个Python库,它可以调用java写的代理工具Browsermob-Proxy,Browsermob-Proxy是一个开源的Java编写的基于LittleProxy的代理服务。Browsermob-Proxy的具体流程有点类似Flidder或Charles。即开启一个端口并作为一个标准代理存在,当HTTP\HTTPS客户端(浏览器等)设置了这个代理,则可以抓取所有的请求细节并获取返回内容。
使用mitmproxy好处是问题少,因为是Python开发的工具,所以使用起来问题少,扩展性也很高,缺点是需要单独部署mitmproxy服务,过程比较繁琐,也增加了许多不确定性。browsermob-proxy的优点是完全为Selenium而生,可以很好的嵌入到正常业务流程的代码中,不需要独立的设置,也支持LIunx,使用起来比较方便,但是缺点是调用了java的代码,环境部署不正确的话会出现新的问题。
本篇将演示browsermob-proxy的使用流程。
browsermob-proxy支持Python3,安装使用下列命令:
pip install browsermob-proxy
安装jdk并设置环境变量,windows下参考:https://jingyan.baidu.com/article/6dad5075d1dc40a123e36ea3.html
目前可用的jdk版本:
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
然后下载Browsermob-Proxy的工具包,下载地址:https://github.com/lightbody/browsermob-proxy/releases/download/browsermob-proxy-2.1.4/browsermob-proxy-2.1.4-bin.zip
下载之后解压文件,将解压后文件完整放入项目目录下:
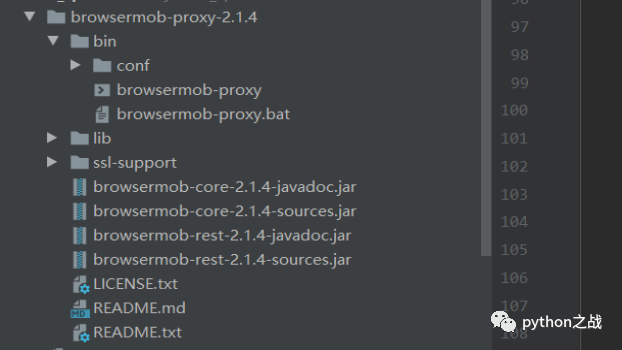
其中browsermob-proxy-2.1.4\bin\browsermob-proxy.bat文件是windows下需要用于初始化代理服务的文件,browsermob-proxy-2.1.4\bin\browsermob-proxy是Mac和Liunx下需要用于初始化代理服务的软件。
基本的使用:
from browsermobproxy import Server # 导入Server模块
server = Server(os.getcwd()+r'\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat') # 初始化服务
server.start() # 启动服务
proxy = server.create_proxy() # 创建一个代理,返回代理地址和端口号
# new_har可以设置捕获的地址或页面标题或地址中含有的关键字,options设置捕获请求头、响应内容
proxy.new_har(options={'captureHeaders': True, 'captureContent': True})
result = proxy.har # 获取捕获的信息对象
上面源码是基本使用流程,如果java配置不正确,在启动Server时、proxy.new_har操作将失败,本质上Python的browsermob-proxy和java的Browsermob-Proxy是通过web接口进行通信的,核心的操作还是通过java程序来实现,所以如果java环境有问题,那么相关的功能也将出现问题。
下面是一个完整的案例:
该案例以访问http://www.weather.com.cn/forecast/全国天气预报页面,获取其中的天气数据。
from browsermobproxy import Server
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import os
server = Server(os.getcwd() + r'\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat')
server.start()
proxy = server.create_proxy()
chrome_options = Options()
chrome_options.add_argument(f'--proxy-server={proxy.proxy}')
chrome_options.add_argument('--ignore-certificate-errors') # 忽略不安全证书提示
driver = webdriver.Chrome(chrome_options=chrome_options)
# 要访问的地址
base_url = "http://www.weather.com.cn/forecast/"
proxy.new_har('http://www.weather.com.cn/forecast/', options={'captureHeaders': True, 'captureContent': True})
driver.get(base_url)
time.sleep(5)
result = proxy.har
for entry in result['log']['entries']:
url = entry['request']['url']
print(url)
if "http://map.weather.com.cn/static_data/101.js" in url:
response = entry['response'] # 响应对象
content = response['content'] # 响应内容对象
text = content['text'] # 响应内容
print(response)
break
server.stop()
driver.quit()
输出信息:
https://hm.baidu.com/hm.js?73b1c219c5ae0b60546433ec777d2e18
https://t12.baidu.com/it/u=1696181861,2912059618&fm=76
https://t10.baidu.com/it/u=3880050090,4098450047&fm=76
https://t12.baidu.com/it/u=1282916783,2603439215&fm=76
https://t10.baidu.com/it/u=2061622323,2920558181&fm=76
https://t12.baidu.com/it/u=918092513,2400575504&fm=76
https://t11.baidu.com/it/u=1999697701,488042932&fm=76
http://map.weather.com.cn/static_data/101.js
var map_config_101={"viewBox":[-1300,-1900,3500,3500],"shapes":{"nearby":[],"mask":{"x":-1300,"y":-1900,"width":"1000","height":"780","data-name":"全国","data-id":"1","text-x":450,"text-y":-50,"fill":"none"},············
该功能最主要的作用是解决一些瓶颈性的问题,有些验证可以解决selenium来解决,验证的结果可以通过browsermob-proxy来获取,让爬虫突破变得更加简单。
github源码地址点击阅读原文即可获取,或公众号后台回复selenium代理。