聊聊服务治理中的路由设计
点击上方“服务端思维”,选择“设为星标”
回复”669“获取独家整理的精选资料集
回复”加群“加入全国服务端高端社群「后端圈」
前言
路由(Route)的设计广泛存在于众多领域,以 RPC 框架 Dubbo 为例,就有标签路由、脚本路由、权重路由、同机房路由等实现。
在框架设计层面,路由层往往位于负载均衡层之前,在进行选址时,路由完成的是 N 选 M(M <= N),而负载均衡完成的是 M 选一,共同影响选址逻辑,最后触发调用。
在业务层面,路由往往是为了实现一定的业务语义,对流量进行调度,所以服务治理框架通常提供的都是基础的路由扩展能力,使用者根据业务场景进行扩展。

今天这篇文章将会围绕路由层该如何设计展开。
路由的抽象建模
先参考 Dubbo 2.7 的实现,进行第一个版本的路由设计,该版本也最直观,非常容易理解。
public interface Router {
List route(List invokers, Invocation invocation) ;
}
Invoker:服务提供方地址的抽象 Invocation:调用的抽象
上述的 route 方法实现的便是 N 选 M 的逻辑。
接下来,以业务上比较常见的同机房路由为例继续建模。顾名思义,在部署时,提供者采用多机房部署,起到容灾的效果,同机房路由最简单的版本即过滤筛选出跟调用方同一机房的地址。
伪代码实现如下:
List route(List invokers, Invocation invocation) {
String site = invocation.getSite();
List result = new ArrayList<>();
for (Invoker invoker: invokers) {
if (invoker.getSite().equals(site)) {
result.add(invoker);
}
}
return result;
}
Dubbo 在较新的 2.7 版本中,也是采用了这样的实现方式。这种实现的弊端也是非常明显的:**每一次调用,都需要对全量的地址进行一次循环遍历!注意,这是调用级别!**在超大规模的集群下,开销之大,可想而知。
路由的改进方案
基于之前路由的抽象建模,可以直观地理解路由选址的过程,其实也就是 2 步:
根据流量特性与路由规则特性选出对应的路由标。 根据路由标过滤对应的服务端地址列表
纵观整个调用过程:
第一步:一定是动态的,Invocation 可能来自于不同的机房,自然会携带不同的机房标。
第二步:根据路由标过滤对应的服务地址列表,完全是可以优化的,因为服务端的地址列表基本是固定的(在不发生上下线时),可以提前计算好每个机房的地址列表,这样就完成了算法复杂度从 O(N) 到 O(1) 的优化。
基于这个优化思路继续完善,路由选址的过程不应该发生在调用级别,而应该发生在下面两个场景:
地址列表变化时。需要重新计算路由地址列表。 路由规则发生变化时。例如路由规则不再是静态的,可以接受动态配置的推送,此时路由地址列表也需要重新计算。
但无论是哪个场景,相比调用级别的计算量,都是九牛一毛的存在。
优化过后的路由方案,伪代码如下:
Map> invokerMap = new ArrayList<>();
String originRule;
List originInvokers;
void generateRoute(List invokers, String rule) {
// 不同路由有不同的路由地址列表计算方式
invokerMap = calculate(invokers, rule);
}
// 地址推送
void addressNotify(List invokers) {
originInvokers = invokers;
generateRoute(originInvokers, originRule);
}
// 规则变化
void ruleChange(String rule) {
originRule = rule;
generateRoute(originInvokers, originRule);
}
List route(Invocation invocation) {
String site = invocation.getSite();
return invokerMap.get(site);
}
这份伪代码仅供参考,如果需要实现,仍然需要考虑非常多的细节,例如:
下一级路由如何触发构建 如何确保路由的可观测性
优化过后的方案,路由过程如下:
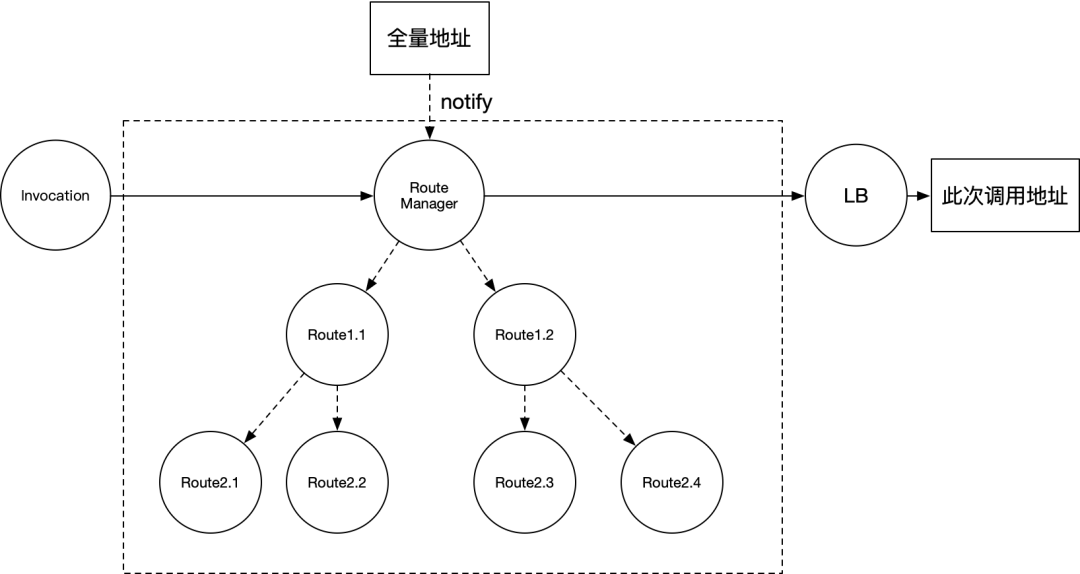
对比之前,主要是两个变化:
路由的代码组织结构从 pipeline 的链式结构,变成树型结构 建树的过程发生在地址 notify 和规则推送时,在 invocation 级别无需计算
静态路由和动态路由
上述的新方案,并不是特别新奇的概念,正是我们熟知的”打表“。这里也要进行说明,并不是所有的路由场景都可以提前打表,如果某一个路由的实现中,服务地址列表的切分依赖了调用时的信息,自然需要将 N 选 M 的过程延迟到调用时。但根据我个人的经验,大多数的路由实现,基本都是标的匹配过程,无非是路由标的类型,计算标的逻辑不一样而已。
对于这类可以提前打表的路由实现,我们不妨称之为静态路由;而必须在调用级别计算的路由实现,可以称之为动态路由。
上述的优化方案,适用于静态路由场景,并且在真实业务场景中,几乎 90% 的路由实现都是静态路由。
总结
本文以 Dubbo2.7 为例,在其基础上提出了一种静态路由策略的优化方案,可以大大减少路由过程中的计算量。这里也给大家卖个关子,Dubbo 3.0 有没有对这块进行优化呢,采取的是不是本文的静态路由方案呢,背后会不会有其他的思考呢?嘿嘿,本文先不给结论,有知道的小伙伴可以留言告诉大家哦。
— 本文结束 —

关注我,回复 「加群」 加入各种主题讨论群。
对「服务端思维」有期待,请在文末点个在看
喜欢这篇文章,欢迎转发、分享朋友圈