
用同样的Benchmark测试,Zilliz 急了?
3月15日,知乎用户“几点James”(Zilliz 合伙人和技术总监栾小凡)对“零一万物笛卡尔(Descartes)包揽权威榜单ANN-Benchmarks 6 项数据集评测第一名”发表了看法,称“已经有一年多没关注这个排行榜(ANN-Benchmarks)了。主要是因为它测试的内容与用户的实际需求渐行渐远。”
然而栾小凡所谓 “一年多没有关注” 这个ANN-Benchmarks的说法着实匪夷所思。就在短短几周前,2月22日Zilliz官方发布了核心向量搜索引擎——Cardinal,使用的主要测试工具之一就是“ANN-Benchmarks”,这篇文章放出了五张ANN-Benchmarks离线测试的曲线图,测试结果占了相当大的篇幅。
感觉这是一个大型双标现场。同样使用测试工具,同样是进行的自测,自己测试时是一个“标准的性能测试工具”,几周后别人发布的测试就变成 “很难作为生产环境性能优化的实际指导”了?
两家公司都测了ANN-Benchmarks
Zilliz 公然双标?
2月22日,Zilliz发布官方微信文章《2024 年,向量数据库的性能卷到什么程度了?”》(https://mp.weixin.qq.com/s/4xx2U8Xyr1RetTkMtRrxyw)一文中称“Zilliz Cloud 最近发布的核心向量搜索引擎 Cardinal,文章先是用了Zilliz 自制自评的 VectorDBBench,接着说明采用了 ANN-benchmarks”,介绍“ANN Benchmarks 是一个标准的性能测试工具,用于评估 ANNS 实现,并在使用不同距离度量的几个标准数据集上运行”。
Zilliz对于测试结果进行了展示,称展示是“通过 ANN-benchmark GitHub 页面上呈现的图表结果,并添加一个 Cardinal 曲线而生成的。”结论是“在所有性能测试中,Cardinal 的表现都十分出色。” 这,自家的合伙人和技术主管一年多没关注?
到了三月,零一万物对使用ANN-Benchmark测试笛卡尔(Descartes)在公号文章进行了说明,它在文中称,ANN-Benchmarks 是全球范围内最权威和常用的向量检索技术性能评测榜单之一,经评估其评测方式可以反应大部份大模型向量数据库所需要的主要能力,因此选用 ANN-Benchmarks 来验证自研向量数据库搜索内核的性能表现。
此外,零一万物还对于开展的离线评测方法做了说明。从说明中可以看出,零一万物先在 GitHub 按正规流程提交pull request,和组织方做了沟通,“组织方反馈近期不做线上评测更新”。然后技术人员才严格还原ANN-Benchmarks官方测试条件进行了离线测试。
GitHub ANN-Benchmarks官方网站上
查不到Cardinal提交信息
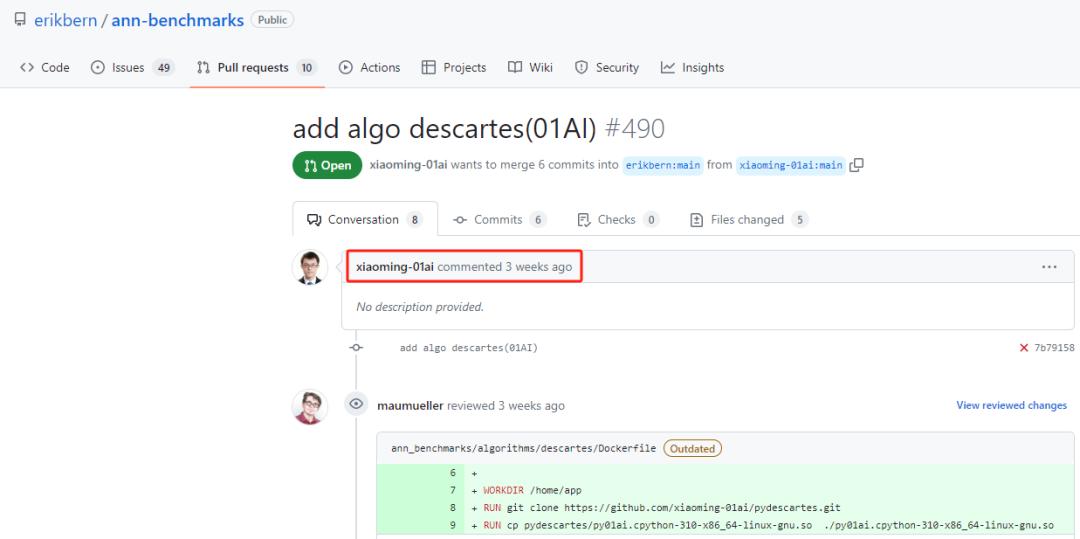
求证了一下,零一万物曾经在 GitHub ANN-Benchmarks上提交了pull request 。在GitHub上,确实能够查到笛卡尔 于 2月29日 "add algo descartes(01AI)" 的提交记录。今天查询时,显示当前状态还是“Open”。

截止到今天(3月18日),Zilliz官宣Cardinal的评测榜单成绩后的25天,在GitHub上的Zilliz机构主页上,查找Cardinal,却怎样都搜不到相关信息。
梳理一下事件时间线,Zilliz为啥急了?
3月11日,零一万物对外发布研发出基于全导航图的新型向量数据库 “笛卡尔(Descartes)”,称其检索内核包揽了权威榜单 ANN-Benchmarks 6项数据集评测第一名。
榜单发布以后,被称为“向量数据库先锋”的Zilliz创始人星爵在朋友圈进行了回应,套用了一份容易让人产生其他联想的零一万物的“写作模版”,阴阳零一万物,朋友圈也能看到这份回应被Zilliz员工大量转发。
随后零一万物联合创始人、技术副总裁 Ethan戴宗宏发表朋友圈进行回复。他说:“技术人应该PK的是技术指标和性能表现,专注于自身技术研发和选代,而不是打口水仗。”
3月15日,栾一凡再次发难,知乎上批判零一万物发布的ANN-Benchmarks榜单结果,措辞激烈。零一万物向量技术负责人王高飞进行了实名回应。
3月17日,零一万物宣布开放笛卡尔向量数据库搜索内核,将技术成果回归社区,免费商用。其称笛卡尔向量数据库定位专注于大模型场景,没有作为单独商业产品的计划。
看完之后,有个感觉:榜单这事,有输有赢很正常,下次再华山论剑就是。这么急,看来零一万物确实动到了Zilliz的蛋糕。不论两家怎么斗,对于技术人员来说,谁向大家开放使用,并且能够好用,谁就是好的。