
从数据库、代码层、缓存使用3个方向,聊聊如何减少bug?
前言
今天跟大家聊聊日常开发中,如何减少bug?本文将从数据库、代码层面、缓存使用篇3个大方向,总结出一共50多个注意点,助大家成为开发质量之星。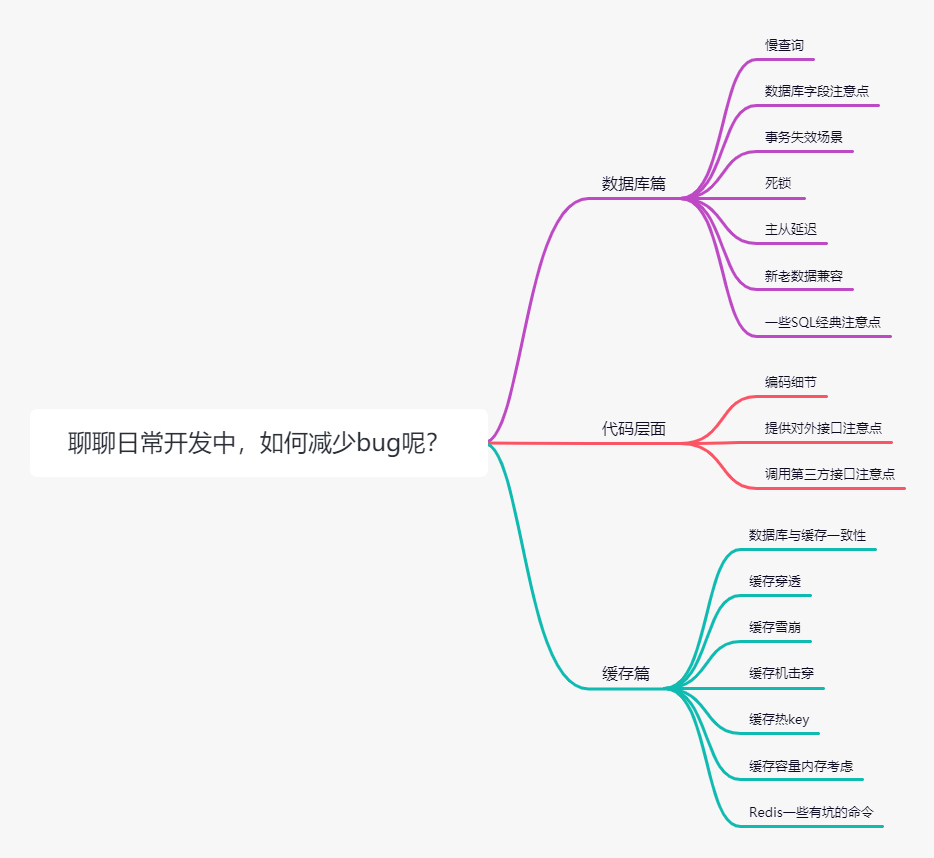
1. 数据库篇
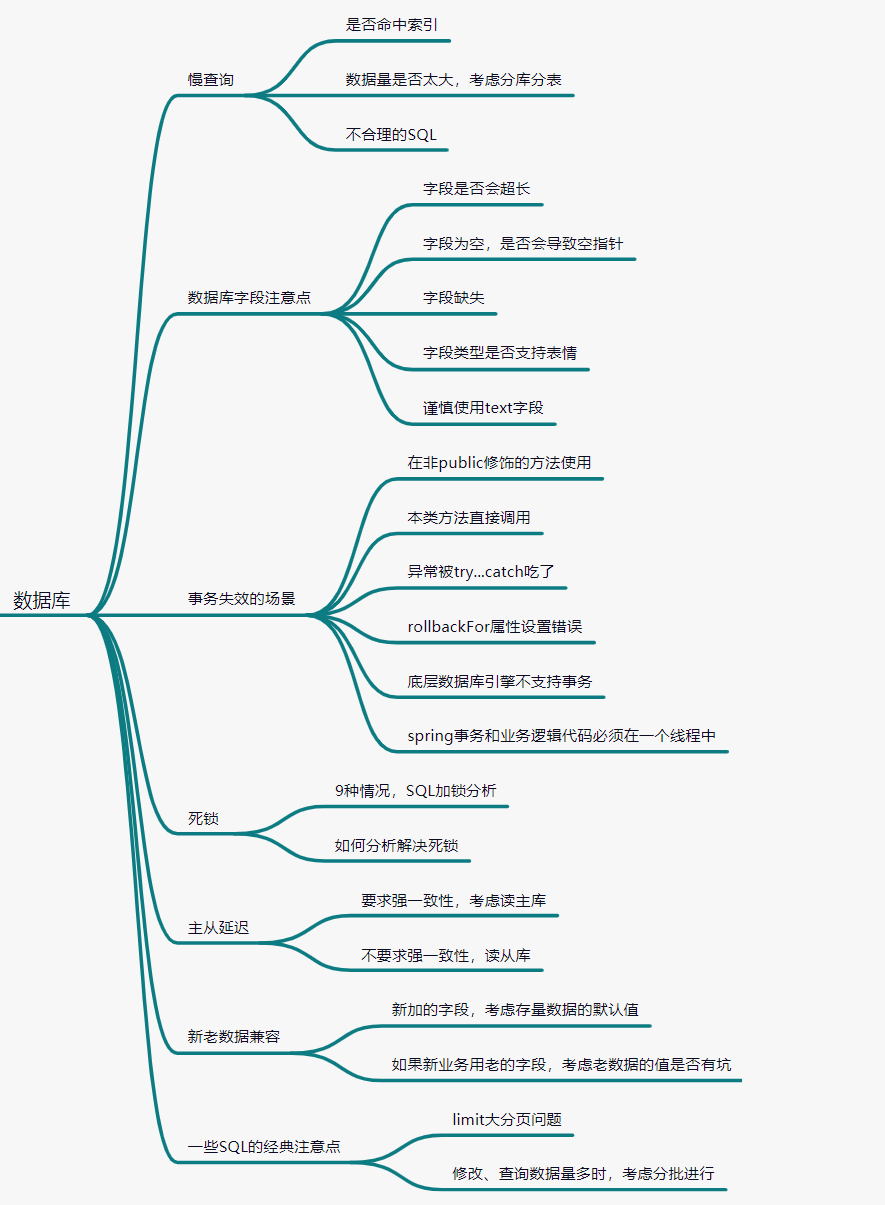
数据库篇的话,哪些地方容易导致bug出现呢?我总结了7个方面:慢查询、数据库字段注意点、事务失效的场景、死锁、主从延迟、新老数据兼容、一些SQL经典注意点。
1.1 慢查询

1.1.1 是否命中索引
提起慢查询,我们马上就会想到加索引。如果一条SQL没加索引,或者没有命中索引的话,就会产生慢查询。
索引哪些情况会失效?
查询条件包含or,可能导致索引失效 如何字段类型是字符串,where时一定用引号括起来,否则索引失效 like通配符可能导致索引失效。 联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。 在索引列上使用mysql的内置函数,索引失效。 对索引列运算(如,+、-、*、/),索引失效。 索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。 索引字段上使用is null, is not null,可能导致索引失效。 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。 mysql估计使用全表扫描要比使用索引快,则不使用索引。
1.1.2 数据量大,考虑分库分表
单表数据量太大,就会影响SQL执行性能。我们知道索引数据结构一般是B+树,一棵高度为3的B+树,大概可以存储两千万的数据。超过这个数的话,B+树要变高,查询性能会下降。
因此,数据量大的时候,建议分库分表。分库分表的中间件有mycat、sharding-jdbc
1.1.3 不合理的SQL
日常开发中,笔者见过很多不合理的SQL:比如一个SQL居然用了6个表连接,连表太多会影响查询性能;再比如一个表,居然加了10个索引等等。索引是会降低了插入和更新SQL性能,所以索引一般不建议太多,一般不能超过五个。
1.2 数据库字段注意点
数据库字段这块内容,很容易出bug。比如,你测试环境修改了表结构,加了某个字段,忘记把脚本带到生产环境,那发版肯定有问题了。
1.2.1 字段是否会超长
假设你的数据库字段是:
`name` varchar(255) DEFAULT NOT NULL
如果请求参数来了变量name,字段长度是300,那插入表的时候就报错了。所以需要校验参数,防止字段超长。
1.2.2 字段为空,是否会导致空指针等
我们设计数据库表字段的时候,尽量把字段设置为not null。
如果是整形,我们一般使用0或者-1作为默认值。 如果字符串,默认空字符串
如果数据库字段设置为NULL值,容易导致程序空指针;如果数据库字段设置为NULL值,需要注意count(具体列) 的使用,会有坑。
1.2.3 字段缺失
我们的日常开发任务,如果在测试环境,对表进行修改,比如添加了一个新字段,必须要把SQL脚本带到生产环境,否则字段缺失,发版就有问题啦。
1.2.4 字段类型是否支持表情
如果一个表字段需要支持表情存储,使用utf8mb4。
1.2.5 谨慎使用text、blob字段
如果你要用一个字段存储文件,考虑存储文件的路径,而不是保存整个文件下去。使用text时,涉及查询条件时,注意创建前缀索引。
1.3 事务失效的场景
1.3.1 @Transactional 在非public修饰的方法上失效
@Transactional注解,加在非public修饰的方法上,事务是不会生效的。spring事务是借鉴了AOP的思想,也是通过动态代理来实现的。spring事务自己在调用动态代理之前,已经对非public方法过滤了,所以非public方法,事务不生效。
1.3.2 本地方法直接调用
以下这个场景,@Transactional事务也是无效的
public class TransactionTest{
public void A(){
//插入一条数据
//调用方法B (本地的类调用,事务失效了)
B();
}
@Transactional
public void B(){
//插入数据
}
}
1.3.3 异常被try...catch吃了,导致事务失效。
@Transactional
public void method(){
try{
//插入一条数据
insertA();
//更改一条数据
updateB();
}catch(Exception e){
logger.error("异常被捕获了,那你的事务就失效咯",e);
}
}
1.3.4 rollbackFor属性设置错误
Spring默认抛出了未检查unchecked异常(继承自RuntimeException 的异常)或者Error才回滚事务;其他异常不会触发回滚事务。如果在事务中抛出其他类型的异常,就需要指定rollbackFor属性。
1.3.5 底层数据库引擎不支持事务
MyISAM存储引擎不支持事务,InnoDb就支持事务
1.3.6 spring事务和业务逻辑代码必须在一个线程中
业务代码要和spring事务的源码在同一个线程中,才会受spring事务的控制。比如下面代码,方法mothed的子线程,内部执行的事务操作,将不受mothed方法上spring事务的控制,这一点大家要注意。这是因为spring事务实现中使用了ThreadLocal,实现同一个线程中数据共享。
@Transactional
public void mothed() {
new Thread() {
事务操作
}.start();
}
1.4 死锁
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
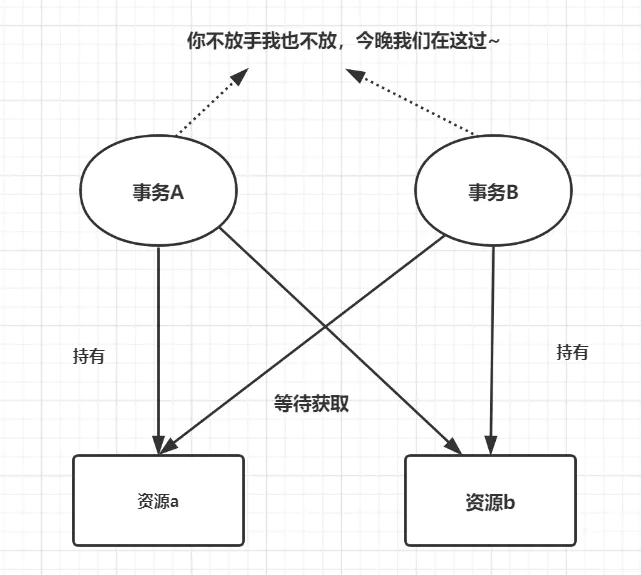
MySQL内部有一套死锁检测机制,一旦发生死锁会立即回滚一个事务,让另一个事务执行下去。但死锁有资源的利用率降低、进程得不到正确结果等危害。
1.4.1 9种情况的SQL加锁分析
要避免死锁,需要学会分析:一条SQL的加锁是如何进行的?一条SQL加锁,可以分9种情况进行探讨:
组合一:id列是主键,RC隔离级别 组合二:id列是二级唯一索引,RC隔离级别 组合三:id列是二级非唯一索引,RC隔离级别 组合四:id列上没有索引,RC隔离级别 组合五:id列是主键,RR隔离级别 组合六:id列是二级唯一索引,RR隔离级别 组合七:id列是二级非唯一索引,RR隔离级别 组合八:id列上没有索引,RR隔离级别 组合九:Serializable隔离级别
1.4.2 如何分析解决死锁?
分析解决死锁的步骤如下:
模拟死锁场景 show engine innodb status;查看死锁日志 找出死锁SQL SQL加锁分析,这个可以去官网看哈 分析死锁日志(持有什么锁,等待什么锁) 熟悉锁模式兼容矩阵,InnoDB存储引擎中锁的兼容性矩阵。
有兴趣的小伙伴,可以看下我之前写的这篇文章:手把手教你分析Mysql死锁问题
1.5 主从延迟问题考虑
先插入,接着就去查询,这类代码逻辑比较常见,这可能会有问题的。一般数据库都是有主库,从库的。写入的话是写主库,读一般是读从库。如果发生主从延迟,,很可能出现你插入成功了,但是查询不到的情况。

1.5.1 要求强一致性,考虑读主库
如果是重要业务,要求强一致性,考虑直接读主库
1.5.2 不要求强一致性,读从库
如果是一般业务,可以接受短暂的数据不一致的话,优先考虑读从库。因为从库可以分担主库的读写压力,提高系统吞吐。
1.6 新老数据兼容
1.6.1 新加的字段,考虑存量数据的默认值
我们日常开发中,随着业务需求变更,经常需要给某个数据库表添加个字段。比如在某个APP配置表,需要添加个场景号字段,如scene_type,它的枚举值是 01、02、03,那我们就要跟业务对齐,新添加的字段,老数据是什么默认值,是为空还是默认01,如果是为NULL的话,程序代码就要做好空指针处理。
1.6.2 如果新业务用老的字段,考虑老数据的值是否有坑
如果我们开发中,需要沿用数据库表的老字段,并且有存量数据,那就需要考虑老存量数据库的值是否有坑。比如我们表有个user_role_code 的字段,老的数据中,它枚举值是 01:超级管理员 02:管理员 03:一般用户。假设业务需求是一般用户拆分为03查询用户和04操作用户,那我们在开发中,就要考虑老数据值的问题啦。
1.7 一些SQL的经典注意点
1.7.1 limit大分页问题
limit大分页是一个非常经典的SQL问题,我们一般有这3种对应的解决方案
方案一: 如果id是连续的,可以这样,返回上次查询的最大记录(偏移量),再往下limit
select id,name from employee where id>1000000 limit 10.
方案二: 在业务允许的情况下限制页数:
建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。谷歌搜索页也是限制了页数,因此不存在limit大分页问题。
方案三: 利用延迟关联或者子查询优化超多分页场景。(先快速定位需要获取的id段,然后再关联)
SELECT a.* FROM employee a, (select id from employee where 条件 LIMIT 1000000,10 ) b where a.id=b.id
1.7.2 修改、查询数据量多时,考虑分批进行。
我们更新或者查询数据库数据时,尽量避免循环去操作数据库,可以考虑分批进行。比如你要插入10万数据的话,可以一次插入500条,执行200次。
正例:
remoteBatchQuery(param);
反例:
for(int i=0;i<100000;i++){
remoteSingleQuery(param)
}
2. 代码层面篇
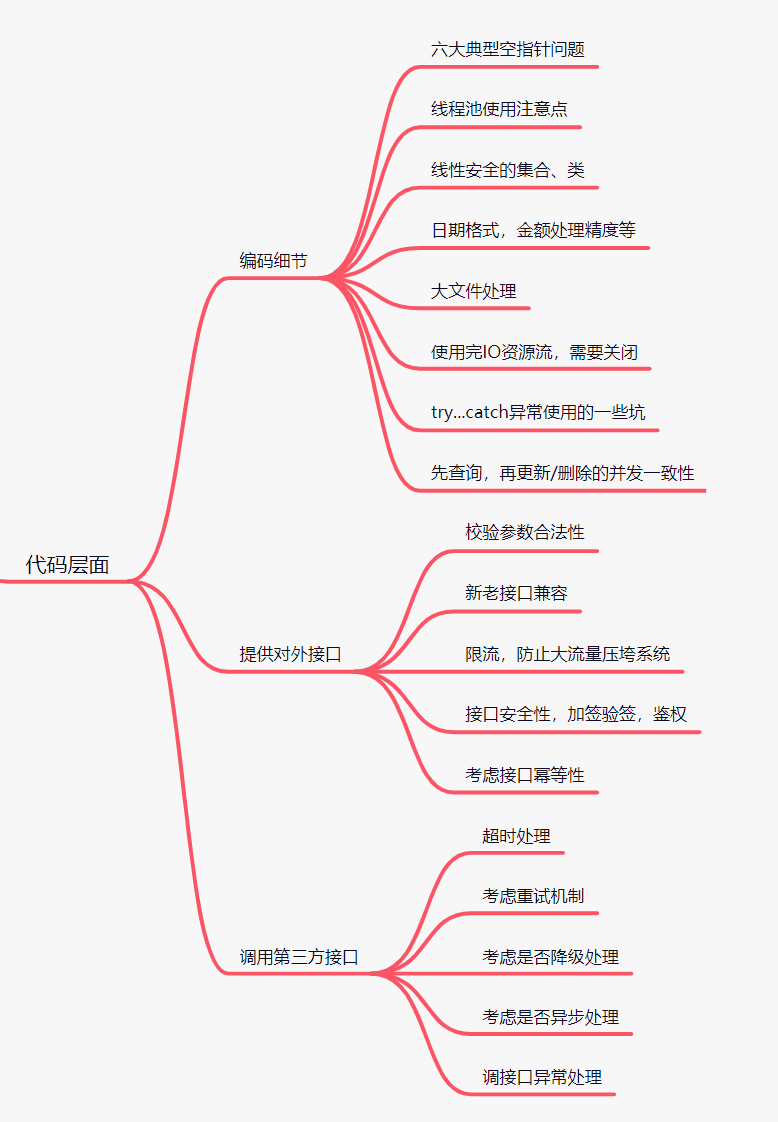
2.1 编码细节

2.1.1 六大典型空指针问题
我们编码的时候,需要注意这六种类型的空指针问题
包装类型的空指针问题 级联调用的空指针问题 Equals方法左边的空指针问题 ConcurrentHashMap 类似容器不支持 k-v为 null。 集合,数组直接获取元素 对象直接获取属性
if(object!=null){
String name = object.getName();
}
2.1.2 线程池使用注意点
使用 Executors.newFixedThreadPool,可能会出现OOM问题,因为它使用的是无界阻塞队列 建议使用自定义的线程池,最好给线程池一个清晰的命名,方便排查问题 不同的业务,最好做线程池隔离,避免所有的业务公用一个线程池。 线程池异常处理要考虑好
2.1.3 线性安全的集合、类
在高并发场景下,HashMap可能会出现死循环。因为它是非线性安全的,可以考虑使用ConcurrentHashMap。所以我们使用这些集合的时候,需要注意是不是线性安全的。
Hashmap、Arraylist、LinkedList、TreeMap等都是线性不安全的; Vector、Hashtable、ConcurrentHashMap等都是线性安全的
2.1.4 日期格式,金额处理精度等
日常开发,经常需要对日期格式化,但是呢,年份设置为YYYY大写的时候,是有坑的哦。
Calendar calendar = Calendar.getInstance();
calendar.set(2019, Calendar.DECEMBER, 31);
Date testDate = calendar.getTime();
SimpleDateFormat dtf = new SimpleDateFormat("YYYY-MM-dd");
System.out.println("2019-12-31 转 YYYY-MM-dd 格式后 " + dtf.format(testDate));
运行结果:
2019-12-31 转 YYYY-MM-dd 格式后 2020-12-31
还有金额计算也比较常见,我们要注意精度问题:
public class DoubleTest {
public static void main(String[] args) {
System.out.println(0.1+0.2);
System.out.println(1.0-0.8);
System.out.println(4.015*100);
System.out.println(123.3/100);
double amount1 = 3.15;
double amount2 = 2.10;
if (amount1 - amount2 == 1.05){
System.out.println("OK");
}
}
}
运行结果:
0.30000000000000004
0.19999999999999996
401.49999999999994
1.2329999999999999
2.1.5 大文件处理
读取大文件的时候,不要Files.readAllBytes直接读到内存,会OOM的,建议使用BufferedReader一行一行来,或者使用NIO
2.1.6 使用完IO资源流,需要关闭
使用try-with-resource,读写完文件,需要关闭流
/*
* 关注公众号,捡田螺的小男孩
*/
try (FileInputStream inputStream = new FileInputStream(new File("jay.txt")) {
// use resources
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}
2.1.7 try...catch异常使用的一些坑
尽量不要使用e.printStackTrace()打印,可能导致字符串常量池内存空间占满 catch了异常,使用log把它打印出来 不要用一个Exception捕捉所有可能的异常 不要把捕获异常当做业务逻辑来处理
2.1.8 先查询,再更新/删除的并发一致性
日常开发中,这种代码实现经常可见:先查询是否有剩余可用的票,再去更新票余量。
if(selectIsAvailable(ticketId){
1、deleteTicketById(ticketId)
2、给现金增加操作
}else{
return “没有可用现金券”
}
如果是并发执行,很可能有问题的,应该利用数据库更新/删除的原子性,正解如下:
if(deleteAvailableTicketById(ticketId) == 1){
1、给现金增加操作
}else{
return “没有可用现金券”
}
2.2 提供对外接口
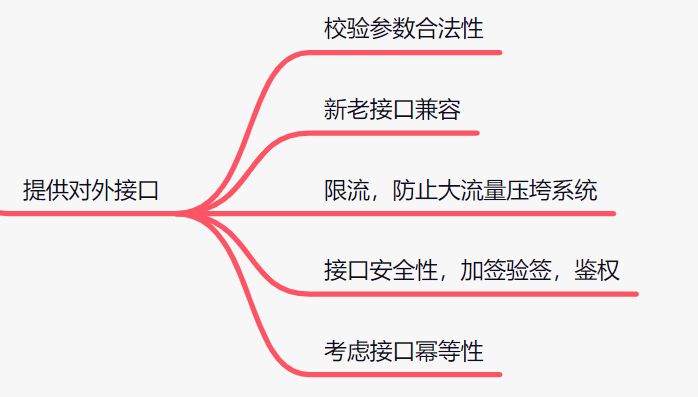
2.2.1 校验参数合法性
我们提供对外的接口,不管是提供给客户端、还是前端,又或是别的系统调用,都需要校验一下入参的合法性。
★如果你的数据库字段设置为varchar(16),对方传了一个32位的字符串过来,你不校验参数长度,插入数据库直接异常了。
”

2.2.2 新老接口兼容
很多bug都是因为修改了对外老接口,但是却不做兼容导致的。关键这个问题多数是比较严重的,可能直接导致系统发版失败的。新手程序员很容易犯这个错误哦~
比如我们有个dubbo的分布式接口,本次你修改了入参,就需要考虑新老接口兼容。原本是只接收A,B参数,现在你加了一个参数C,就可以考虑这样处理。
//老接口
void oldService(A,B){
//兼容新接口,传个null代替C
newService(A,B,null);
}
//新接口,暂时不能删掉老接口,需要做兼容。
void newService(A,B,C);
2.2.3 限流,防止大流量压垮系统
如果瞬间的大流量请求过来,容易压垮系统。所以为了保护我们的系统,一般要做限流处理。可以使用guava ratelimiter 组件做限流,也可以用阿里开源的Sentinel
2.2.4 接口安全性,加签验签,鉴权
我们转账等类型的接口,一定要注意安全性。一定要鉴权,加签验签,为用户交易保驾护航。
2.2.5 考虑接口幂等性
接口是需要考虑幂等性的,尤其抢红包、转账这些重要接口。最直观的业务场景,就是用户连着点击两次,你的接口有没有hold住。
★”
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。 在编程中.一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。
一般幂等技术方案有这几种:
查询操作 唯一索引 token机制,防止重复提交 数据库的delete删除操作 乐观锁 悲观锁 Redis、zookeeper 分布式锁(以前抢红包需求,用了Redis分布式锁) 状态机幂等

2.3 调用第三方接口
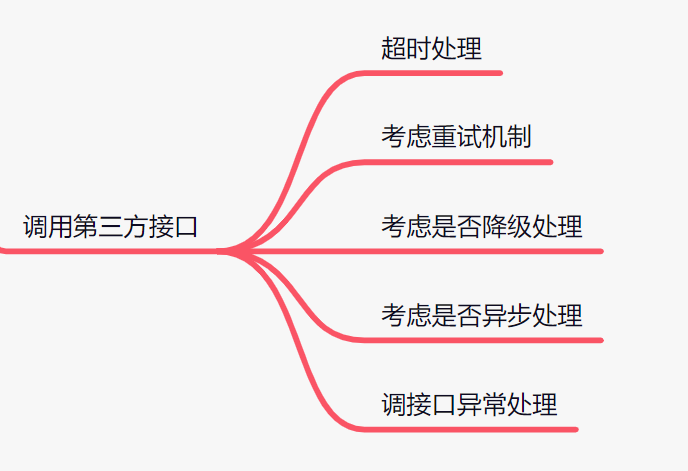
2.3.1 超时处理
我们调用别人的接口,如果超时了怎么办呢?
★举个例子,我们调用一个远程转账接口,A客户给B客户转100万,成功的时候就把本地转账流水置为成功,失败的时候就把本地流水置为失败。如果调用转账系统超时了呢,我们怎么处理呢?置为成功还是失败呢?这个超时处理可要考虑好,要不然就资金损失了。这种场景下,调接口超时,我们就可以先不更新本地转账流水状态,而是重新发起查询远程转账请求,查询到转账成功的记录,再更新本地状态状态
”
2.3.2 考虑重试机制
如果我们调用一个远程http或者dubbo接口,调用失败了,我们可以考虑引入重试机制。有时候网路抖动一下,接口就调失败了,引入重试机制可以提高用户体验。但是这个重试机制需要评估次数,或者有些接口不支持幂等,就不适合重试的。
2.3.3 考虑是否降级处理
假设我们系统是一个提供注册的服务:用户注册成功之后,调远程A接口发短信,调远程B接口发邮件,最后更新注册状态为成功。
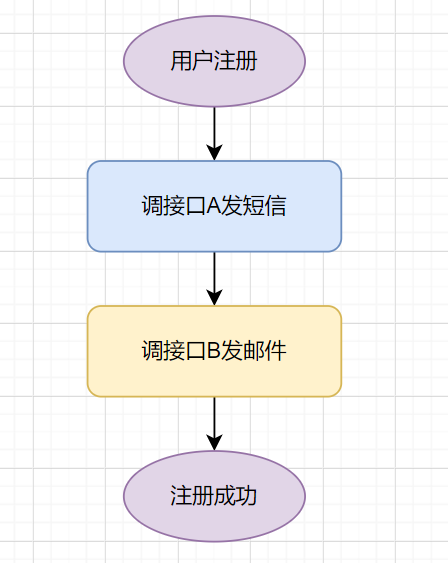
如果调用接口B发邮件失败,那用户就注册失败,业务可能就不会同意了。这时候我们可以考虑给B接口降级处理,提供有损服务。也就是说,如果调用B接口失败,那先不发邮件,而是先让用户注册成功,后面搞个定时补发邮件就好啦。
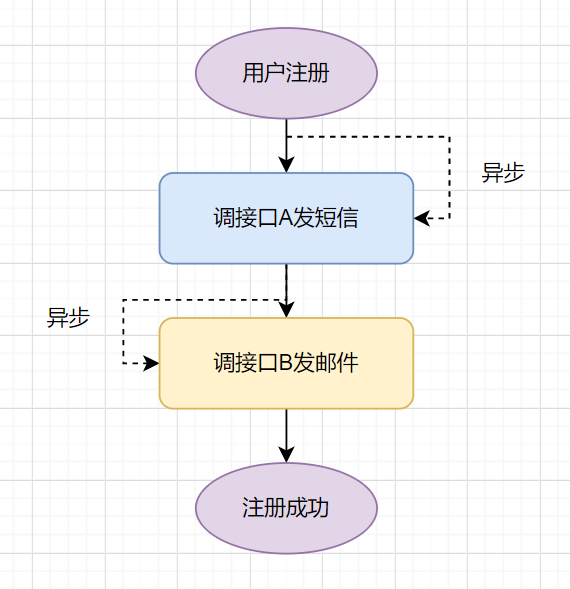
2.3.4 考虑是否异步处理
我还是使用上个小节的用户注册的例子。我们可以开个异步线程去调A接口发短信,异步调B接口发邮件,那即使A或者B接口调失败,我们还是可以保证用户先注册成功。
把发短信这些通知类接口,放到异步线程处理,可以降低接口耗时,提升用户体验哦。
2.3.5 调接口异常处理
如果我们调用一个远程接口,一般需要思考以下:如果别人接口异常,我们要怎么处理,怎么兜底,是重试还是当做失败?怎么保证数据的最终一致性等等。
3. 缓存篇
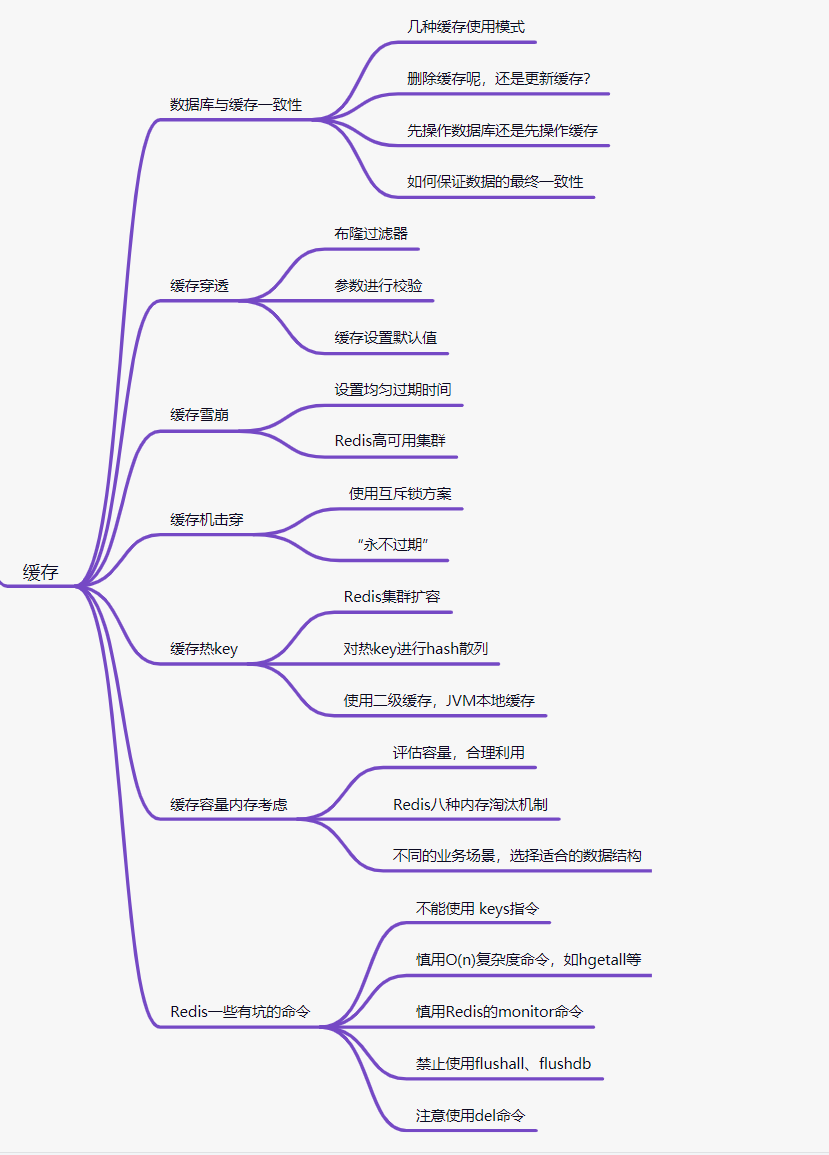
3.1 数据库与缓存一致性
使用缓存,可以降低耗时,提供系统吞吐性能。但是,使用缓存,会存在数据一致性的问题。
3.1.1 几种缓存使用模式
Cache-Aside Pattern,旁路缓存模式 Read-Through/Write-Through(读写穿透) Write- behind (异步缓存写入)
一般我们使用缓存,都是旁路缓存模式,读请求流程如下:
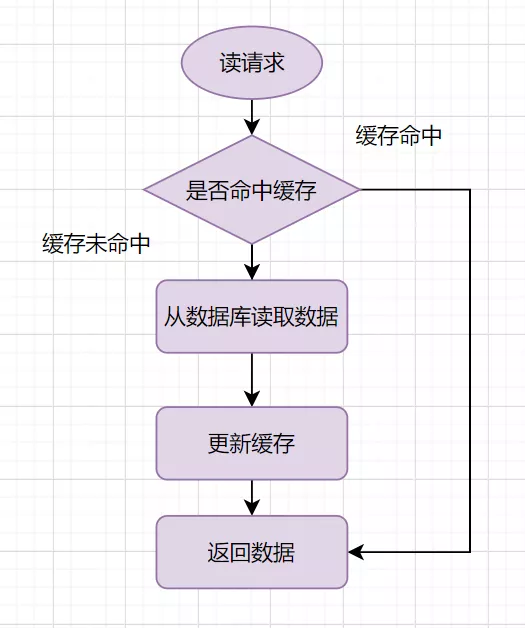
读的时候,先读缓存,缓存命中的话,直接返回数据 缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
旁路缓存模式的写流程: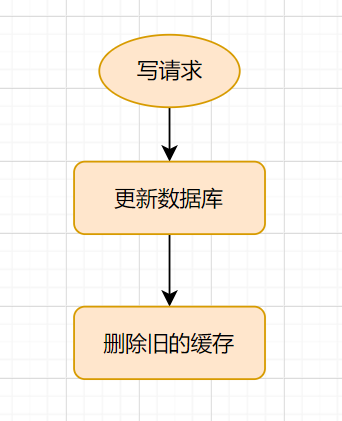
3.1.2 删除缓存呢,还是更新缓存?
我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?我们先来看个例子:
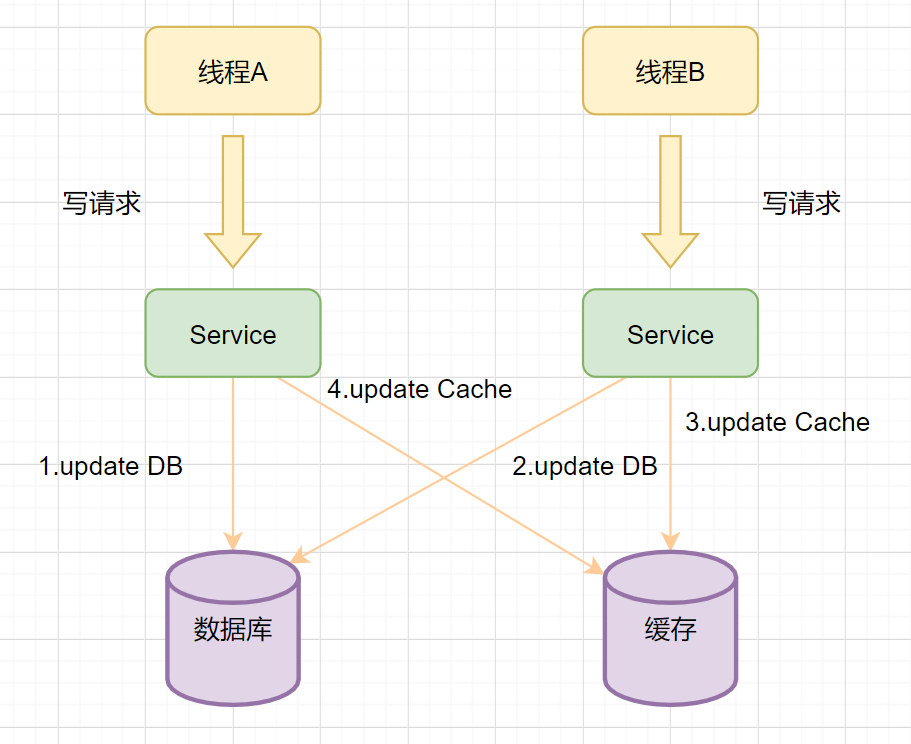
线程A先发起一个写操作,第一步先更新数据库 线程B再发起一个写操作,第二步更新了数据库 由于网络等原因,线程B先更新了缓存 线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
3.1.3 先操作数据库还是先操作缓存
双写的情况下,先操作数据库还是先操作缓存?我们再来看一个例子:假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
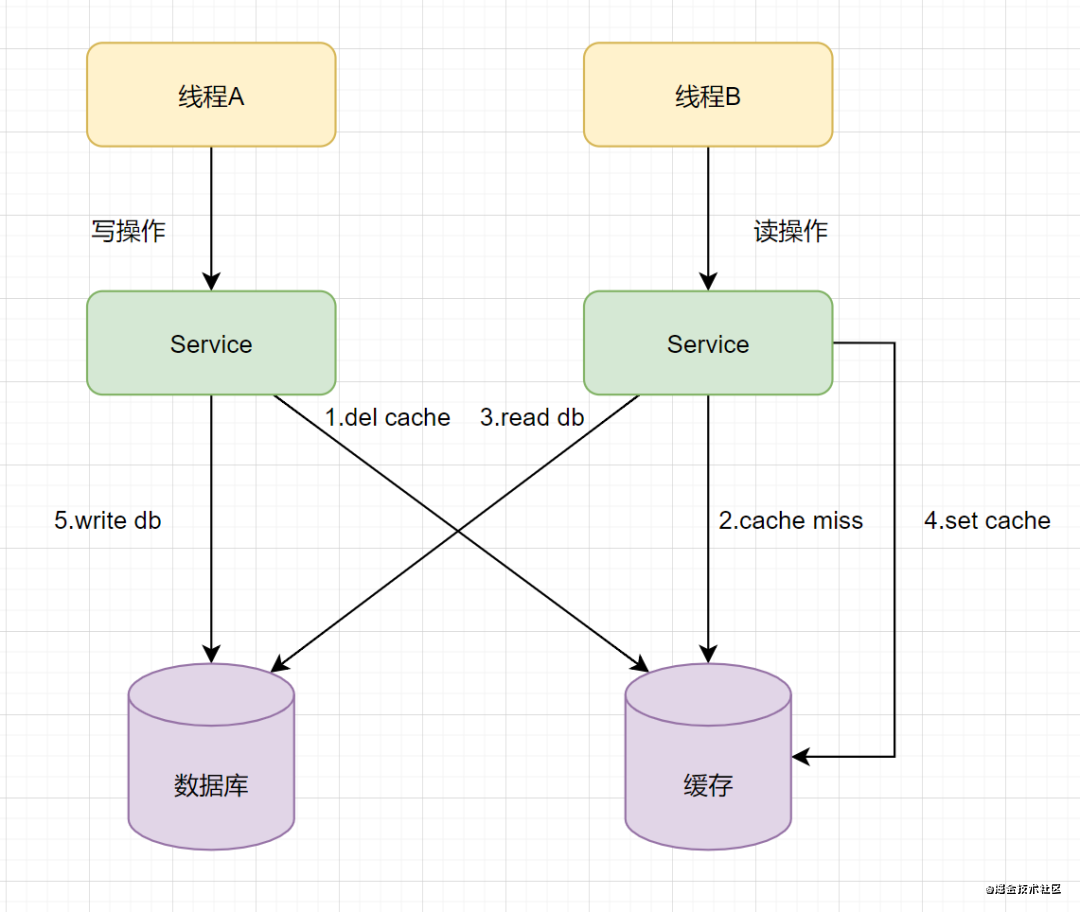
线程A发起一个写操作,第一步del cache 此时线程B发起一个读操作,cache miss 线程B继续读DB,读出来一个老数据 然后线程B把老数据设置入cache 线程A写入DB最新的数据
酱紫就有问题啦,缓存和数据库的数据不一致了。缓存保存的是老数据,数据库保存的是新数据。因此,Cache-Aside缓存模式,选择了先操作数据库而不是先操作缓存。
3.1.4 如何保证最终一致性
缓存延时双删 删除缓存重试机制 读取biglog异步删除缓存
3.2 缓存穿透
★缓存穿透:指查询一个一定不存在的数据,由于缓存不命中时,需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
”
缓存穿透一般都是这几种情况产生的:业务不合理的设计、业务/运维/开发失误的操作、黑客非法请求攻击。如何避免缓存穿透呢?一般有三种方法。
如果是非法请求,我们在API入口,对参数进行校验,过滤非法值。 如果查询数据库为空,我们可以给缓存设置个空值,或者默认值。但是如有有写请求进来的话,需要更新缓存哈,以保证缓存一致性,同时,最后给缓存设置适当的过期时间。(业务上比较常用,简单有效) 使用布隆过滤器快速判断数据是否存在。即一个查询请求过来时,先通过布隆过滤器判断值是否存在,存在才继续往下查。
3.3 缓存雪崩
★缓存雪崩:指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
”
缓存雪奔一般是由于大量数据同时过期造成的,对于这个原因,可通过均匀设置过期时间解决,即让过期时间相对离散一点。如采用一个较大固定值+一个较小的随机值,5小时+0到1800秒酱紫。 Redis 故障宕机也可能引起缓存雪奔。这就需要构造Redis高可用集群啦。
3.4 缓存机击穿
★缓存击穿:指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
”
缓存击穿看着有点像缓存雪崩,其实它两区别是,缓存雪奔是指数据库压力过大甚至down机,缓存击穿只是大量并发请求到了DB数据库层面。可以认为击穿是缓存雪奔的一个子集吧。有些文章认为它俩区别,是在于击穿针对某一热点key缓存,雪奔则是很多key。
解决方案就有两种:
使用互斥锁方案。缓存失效时,不是立即去加载db数据,而是先使用某些带成功返回的原子操作命令,如(Redis的setnx)去操作,成功的时候,再去加载db数据库数据和设置缓存。否则就去重试获取缓存。 “永不过期”,是指没有设置过期时间,但是热点数据快要过期时,异步线程去更新和设置过期时间。
3.5 缓存热Key
在Redis中,我们把访问频率高的key,称为热点key。如果某一热点key的请求到服务器主机时,由于请求量特别大,可能会导致主机资源不足,甚至宕机,从而影响正常的服务。
如何解决热key问题?
Redis集群扩容:增加分片副本,均衡读流量; 对热key进行hash散列,比如将一个key备份为key1,key2……keyN,同样的数据N个备份,N个备份分布到不同分片,访问时可随机访问N个备份中的一个,进一步分担读流量; 使用二级缓存,即JVM本地缓存,减少Redis的读请求。
3.6 缓存容量内存考虑
3.6.1 评估容量,合理利用
如果我们使用的是Redis,而Redis的内存是比较昂贵的,我们不要什么数据都往Redis里面塞,一般Redis只缓存查询比较频繁的数据。同时,我们要合理评估Redis的容量,也避免频繁set覆盖,导致设置了过期时间的key失效。
如果我们使用的是本地缓存,如guava的本地缓存,也要评估下容量。避免容量不够。
3.6.2 Redis的八种内存淘汰机制
为了避免Redis内存不够用,Redis用8种内存淘汰策略保护自己~
★”
volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰; allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。 volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。 allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰; volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。 allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。 volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰; noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
3.6.3 不同的业务场景,Redis选择适合的数据结构
排行榜适合用zset 缓存用户信息一般用hash 消息队列,文章列表适用用list 用户标签、社交需求一般用set 计数器、分布式锁等一般用String类型
3.7 Redis一些有坑的命令
不能使用 keys指令 慎用O(n)复杂度命令,如hgetall等 慎用Redis的monitor命令 禁止使用flushall、flushdb 注意使用del命令
最后
本文总结了50多个减少bug的编码注意点,都是日常开发经典的范例,希望对大家有帮助哈。
程序汪资料链接
卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
卧槽!阿里大佬总结的《图解Java》火了,完整版PDF开放下载!
欢迎添加程序汪个人微信 itwang007 进粉丝群或围观朋友圈