
为什么不建议使用 Java 自带的序列化?
点击关注公众号,Java干货及时送达
作者:rickiyang
出处:www.cnblogs.com/rickiyang/p/11074232.html
谈到序列化我们自然想到 Java 提供的 Serializable 接口,在 Java 中我们如果需要序列化只需要继承该接口就可以通过输入输出流进行序列化和反序列化。
但是在提供很用户简单的调用的同时他也存在很多问题:
1、无法跨语言
当我们进行跨应用之间的服务调用的时候如果另外一个应用使用c语言来开发,这个时候我们发送过去的序列化对象,别人是无法进行反序列化的因为其内部实现对于别人来说完全就是黑盒。
2、序列化之后的码流太大
这个我们可以做一个实验还是上一节中的Message类,我们分别用java的序列化和使用二进制编码来做一个对比,下面我写了一个测试类:
@Test
public void testSerializable(){
String str = "哈哈,我是一条消息";
Message msg = new Message((byte)0xAD,35,str);
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
ObjectOutputStream os = new ObjectOutputStream(out);
os.writeObject(msg);
os.flush();
byte[] b = out.toByteArray();
System.out.println("jdk序列化后的长度: "+b.length);
os.close();
out.close();
ByteBuffer buffer = ByteBuffer.allocate(1024);
byte[] bt = msg.getMsgBody().getBytes();
buffer.put(msg.getType());
buffer.putInt(msg.getLength());
buffer.put(bt);
buffer.flip();
byte[] result = new byte[buffer.remaining()];
buffer.get(result);
System.out.println("使用二进制序列化的长度:"+result.length);
} catch (IOException e) {
e.printStackTrace();
}
}
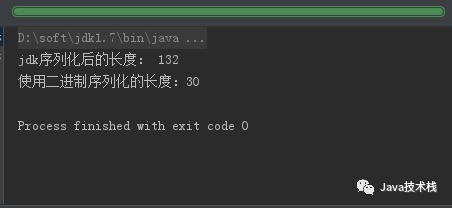
我们可以看到差距是挺大的,目前的主流编解码框架序列化之后的码流也都比java序列化要小太多。Java 核心技术系列教程和示例整理好了:https://github.com/javastacks/javastack
3、序列化效率
这个我们也可以做一个对比,还是上面写的测试代码我们循环跑100000次对比一下时间:
@Test
public void testSerializable(){
String str = "哈哈,我是一条消息";
Message msg = new Message((byte)0xAD,35,str);
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
long startTime = System.currentTimeMillis();
for(int i = 0;i < 100000;i++){
ObjectOutputStream os = new ObjectOutputStream(out);
os.writeObject(msg);
os.flush();
byte[] b = out.toByteArray();
/*System.out.println("jdk序列化后的长度: "+b.length);*/
os.close();
out.close();
}
long endTime = System.currentTimeMillis();
System.out.println("jdk序列化100000次耗时:" +(endTime - startTime));
long startTime1 = System.currentTimeMillis();
for(int i = 0;i < 100000;i++){
ByteBuffer buffer = ByteBuffer.allocate(1024);
byte[] bt = msg.getMsgBody().getBytes();
buffer.put(msg.getType());
buffer.putInt(msg.getLength());
buffer.put(bt);
buffer.flip();
byte[] result = new byte[buffer.remaining()];
buffer.get(result);
/*System.out.println("使用二进制序列化的长度:"+result.length);*/
}
long endTime1 = System.currentTimeMillis();
System.out.println("使用二进制序列化100000次耗时:" +(endTime1 - startTime1));
} catch (IOException e) {
e.printStackTrace();
}
}
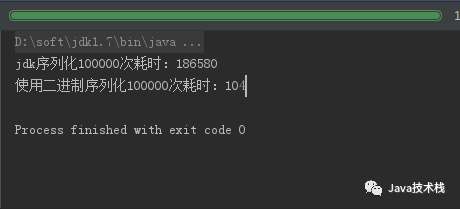
结果为毫秒数,这个差距也是不小的。另外,关注公众号Java技术栈,在后台回复:面试,可以获取我整理的 Java 系列面试题和答案,非常齐全。
结合以上我们看到:
目前的序列化过程中使用 Java 本身的肯定是不行,使用二进制编码的话又的我们自己去手写,所以为了让我们少搬砖前辈们早已经写好了工具让我们调用,目前社区比较活跃的有 google 的 Protobuf 和 Apache 的 Thrift。







关注Java技术栈看更多干货

评论