
记一次线上商城系统高并发的优化
对于线上系统调优,它本身是个技术活,不仅需要很强的技术实战能力,很强的问题定位,问题识别,问题排查能力,还需要很丰富的调优能力。
本篇文章从实战角度,从问题识别,问题定位,问题分析,提出解决方案,实施解决方案,监控调优后的解决方案和调优后的观察等角度来与大家一起交流分享本次线上高并发调优整个闭环过程。
一、项目简要情况概述
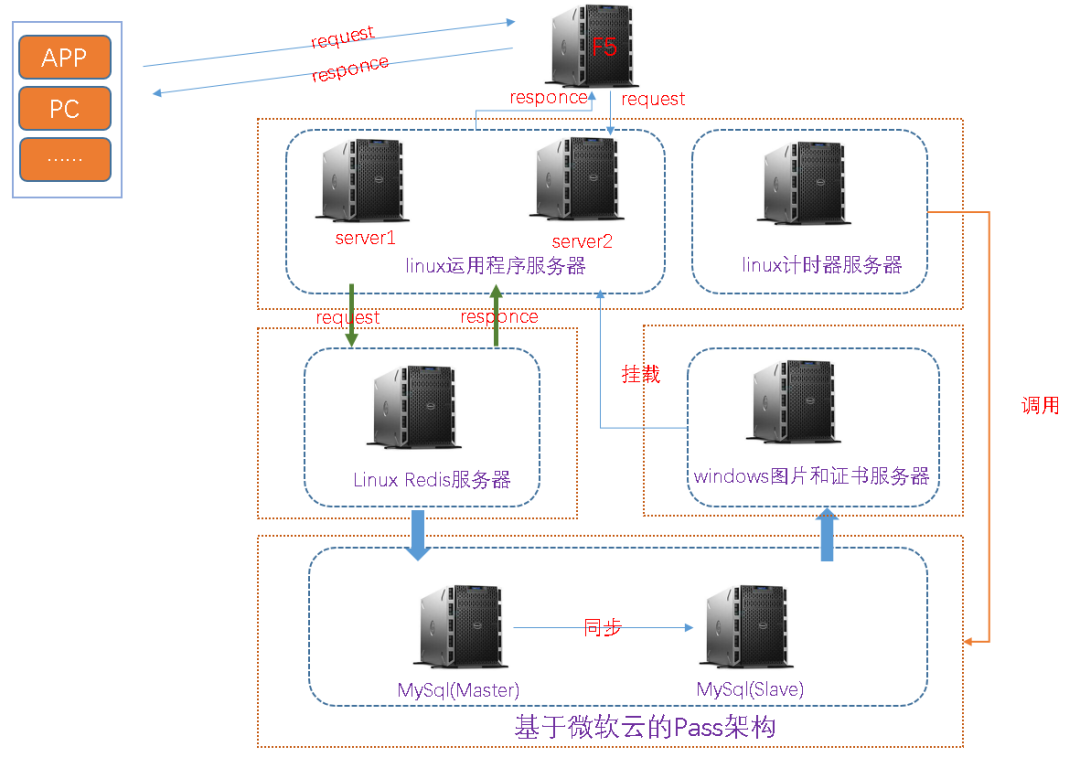
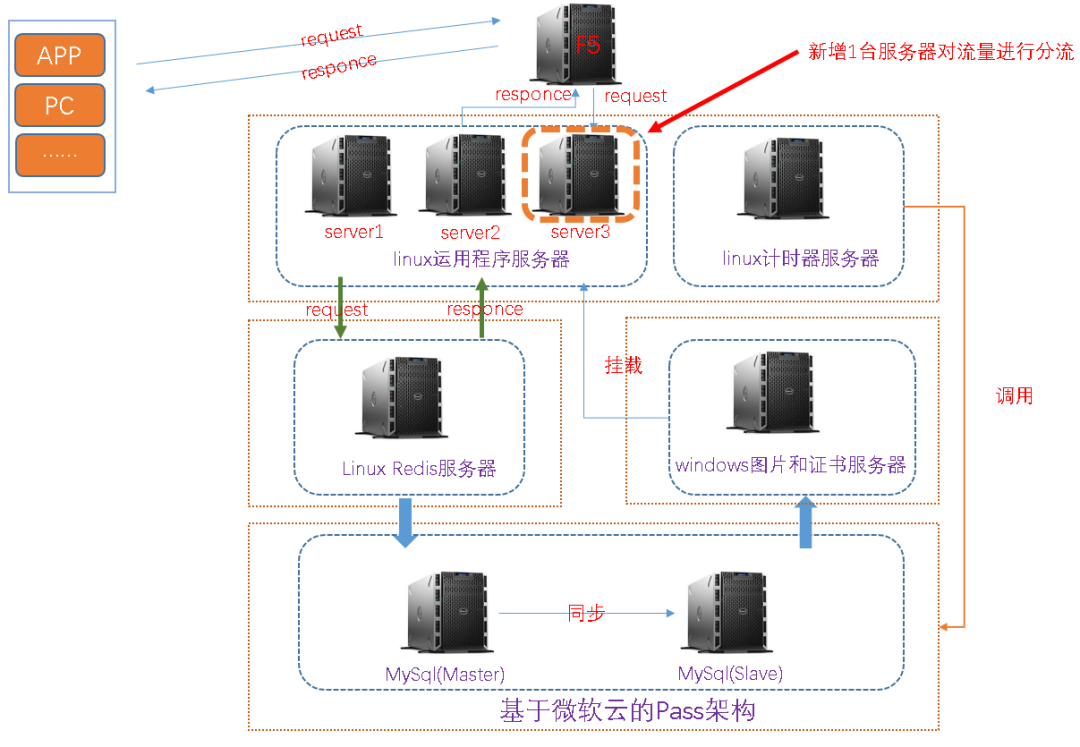
该项目为基于SSM架构的商城类单体架构项目,其中有一个秒杀重磅模块,如下为当前线上环境的简要架构部署图,大致描述一下:
(1)项目为SSM架构
(2)服务器类别:1台负载均衡服务器(F5),3台运用程序服务器,1台计时器服务器,1台redis服务器,1台图片服服务器和1台基于Pass架构的Mysql主从服务器(微软云)
(3)调用逻辑:下图为简要调用逻辑
二、何为单体架构项目
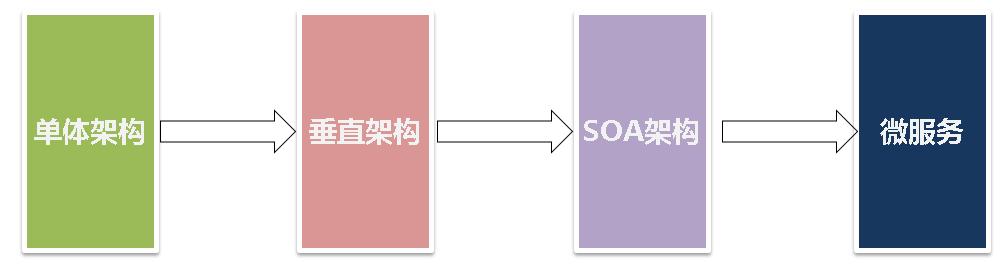
从架构发展角度,软件项目经历了如下阶段的发展:
1.单体架构:可理解为传统的前后端未分离的架构
2.垂直架构:可理解为前后端分离架构
3.SOA架构:可理解为按服务类别,业务流量,服务间依赖关系等服务化的架构,如以前的单体架构ERP项目,划分为订单服务,采购服务,物料服务和销售服务等
4.微服务:可理解为一个个小型的项目,如之前的ERP大型项目,划分为订单服务(订单项目),采购服务(采购项目),物料服务(物料项目)和销售服务(销售项目),以及服务之间调用
三、本SSM项目引发的线上问题
1.当秒杀的时候,cpu暴增
该系统每天秒杀分为三个时间端:10点,13点和20点,如下为秒杀的简要页面
图1
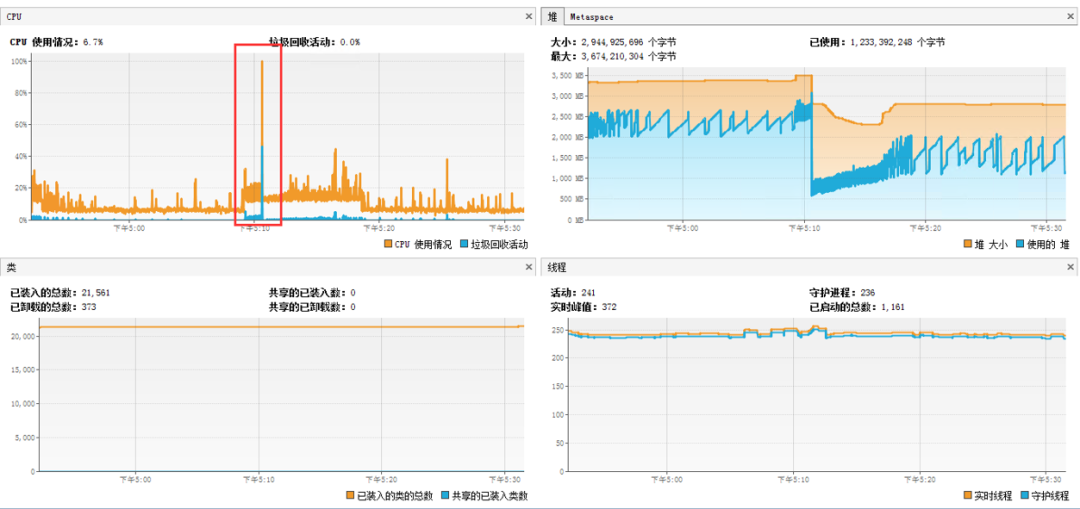
图2
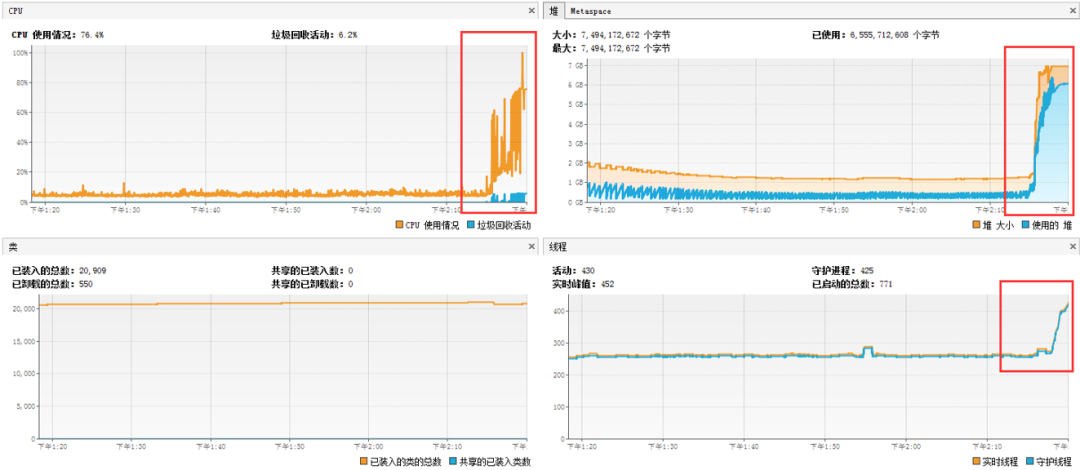
图3
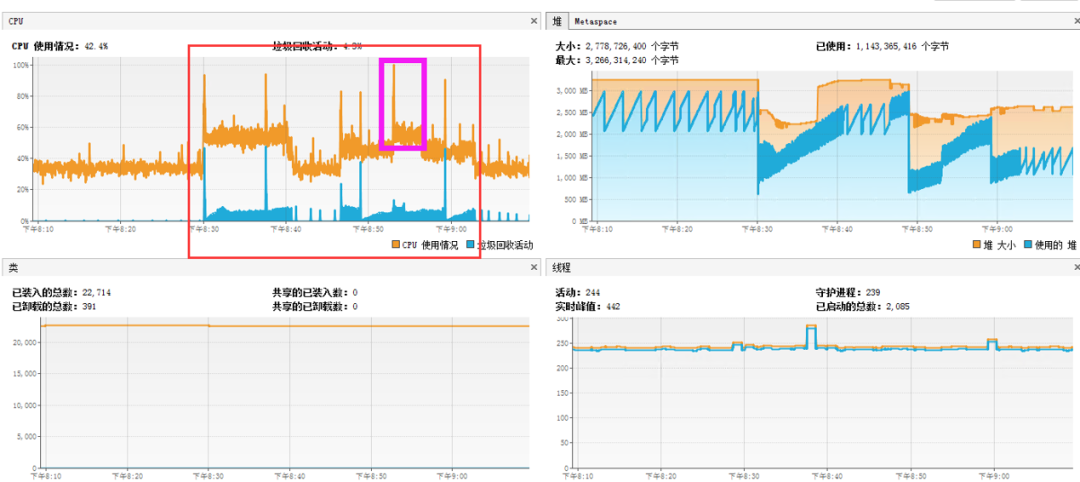
2.单台运用服务器cpu
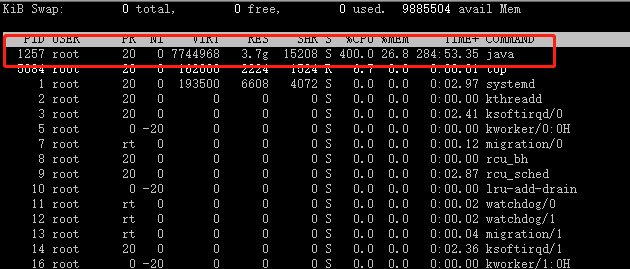
3.单台运用服务器请求数
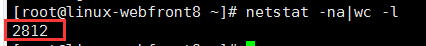
4.rdis连接数(info clients)
这个未保存截图,记得是600左右
connected_clients:600
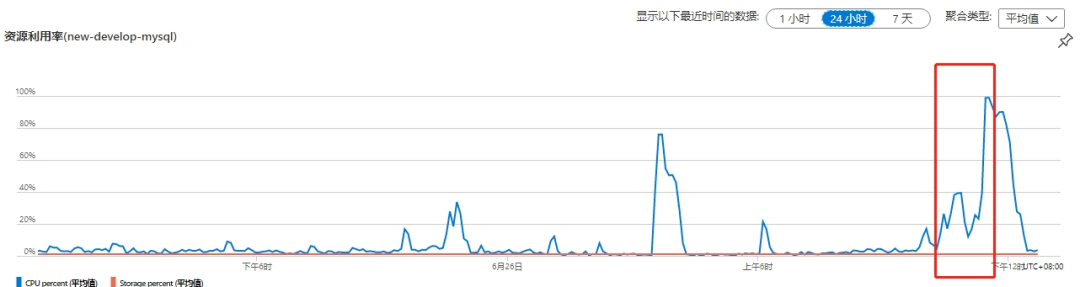
5.mysql请求截图
四、排查过程及分析
(一)排查思路
根据服务部署和项目架构,从如下几个方面排查:
(1)运用服务器:排查内存,cpu,请求数等;
(2)文件图片服务器:排查内存,cpu,请求数等;
(3)计时器服务器:排查内存,cpu,请求数等;
(4)redis服务器:排查内存,cpu,连接数等;
(5)db服务器:排查内存,cpu,连接数等;
(二)排查过程
在秒杀后30分钟内,
1.运用程序服务器cpu暴增,内存暴增,造成cpu和内存暴增的根本原因是请求数过高,单台运用服务器达到3000多;
2.redis请求超时

3.jdbc连接超时

4.通过gc查看,发现24小时内,FullGC发生了152次

5.再看看堆栈,发现有一些线程阻塞和死锁
jstat -l pid,也可以通过VisualVM分析
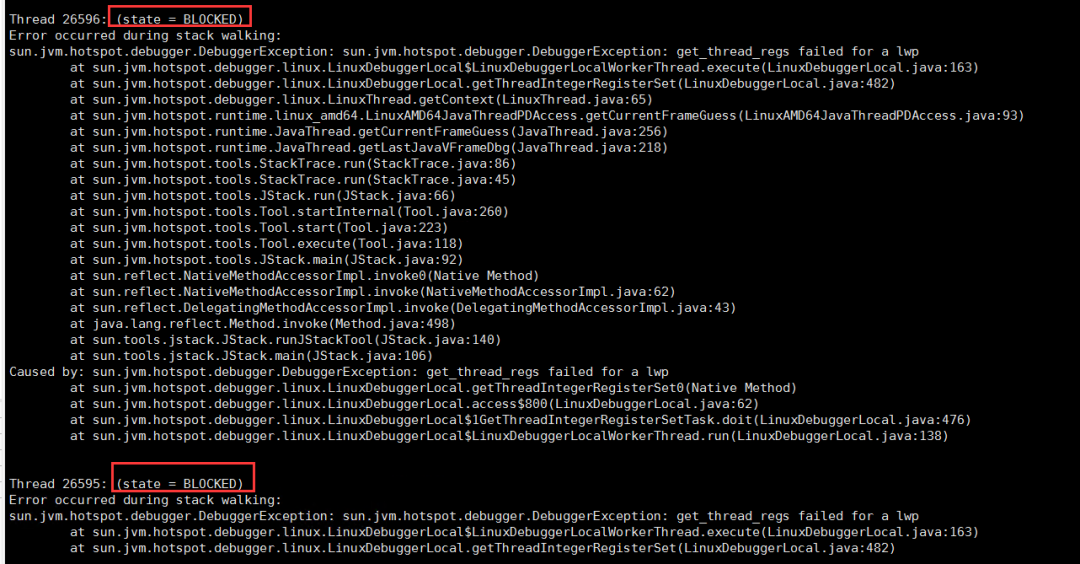
6.发现有2000多个线程请求无效资源
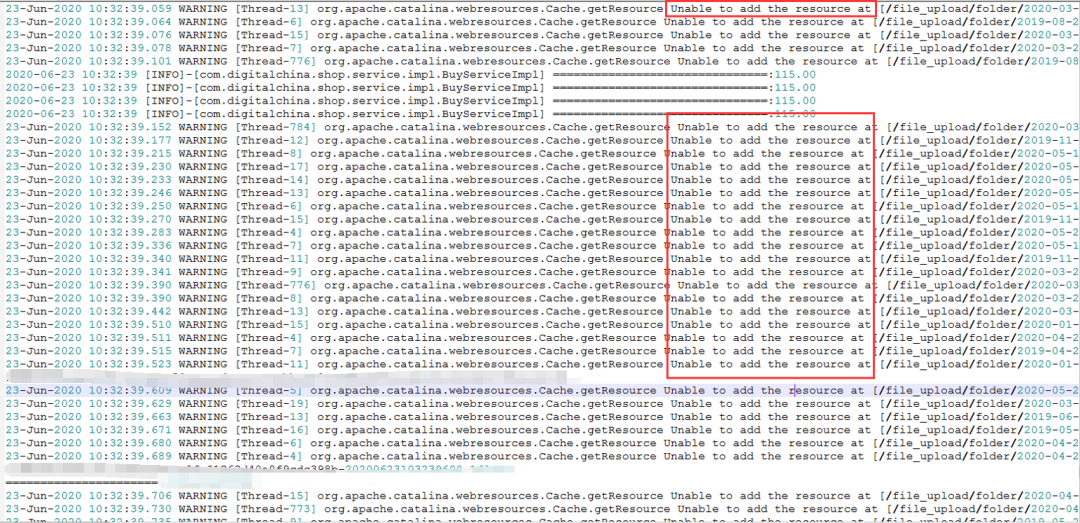
(三)造成本次系统异常主要因素分析
(1)在秒杀时,请求量过高,导致运用服务器负载过高;
(2)redis连接池满,获取不到连接,connot get a connection from thread pool
(3)jdbc连接池满,获取不到连接和超时
(4)存在大对象代码,如向list集合中不停添加对象,不能及时回收对象导致内存增加,频繁发生Full GC
(5)tomcat并发参数,jvm优化参数,jedis配置参数,jdbc配置参数不合理
(6)未对请求量进行削峰和限流
(7)资源连接未及时释放,如redis连接,jdbc连接未及时释放
五、最终解决方案
1.增加运用服务,做流量削峰和分流
由于该项目未增加MQ,因此只能采用硬负载,增加服务器水平扩展方式来实现流量削峰和流量分流
2.优化jvm参数,如下为本次优化后的参数
JAVA_OPTS="-server -Xmx9g -Xms9g -Xmn3g -Xss500k -XX:+DisableExplicitGC -XX:MetaspaceSize=2048m -XX:MaxMetaspaceSize=2048m -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -Dfile.encoding=UTF8 -Duser.timezone=GMT+08"关于这个jvm参数的优化,jvm理论是怎样的,官方建议是怎样的,实战是怎样的,将在下篇文章中分析。
3.优化tomcat并发相关参数
主要是两方面:
(1)修改bio协议为nio2 (2)根据服务器配置,业务场景,业务流量等合理设置相关参数,尽量达到最优
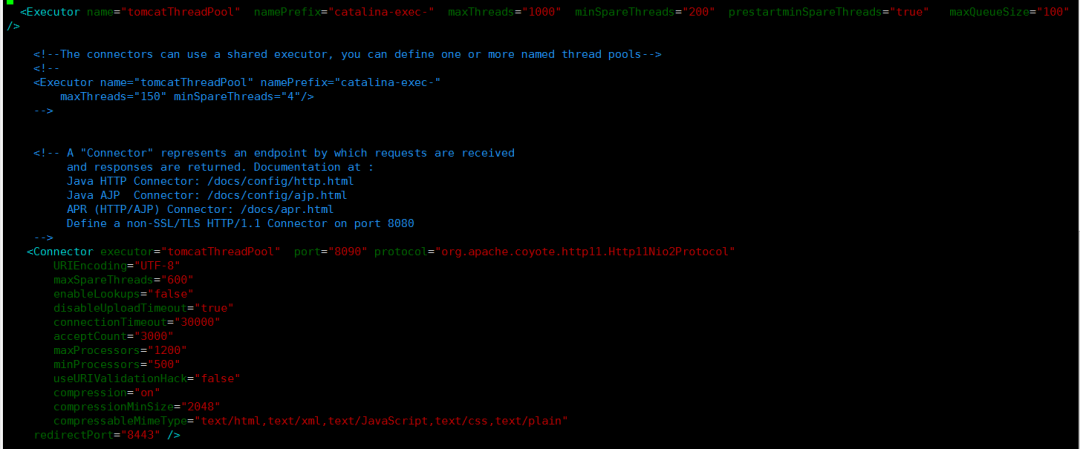
关于tomcat相关参数优化,在接下来的文章中分析。
4.redis 和jdbc参数优化
由于涉及到安全性问题,这里不列出
5.代码优化
(1)优化掉大对象
(2)优化未及时释放的对象和连接资源
6.解决000多个线程请求无效资源问题
在conf/context.xml增大缓存
cachingAllowed = "true"
cacheMaxSize = "102400"
/> 六、最终优化结果
经过几天观察,系统平稳
1.基本监控
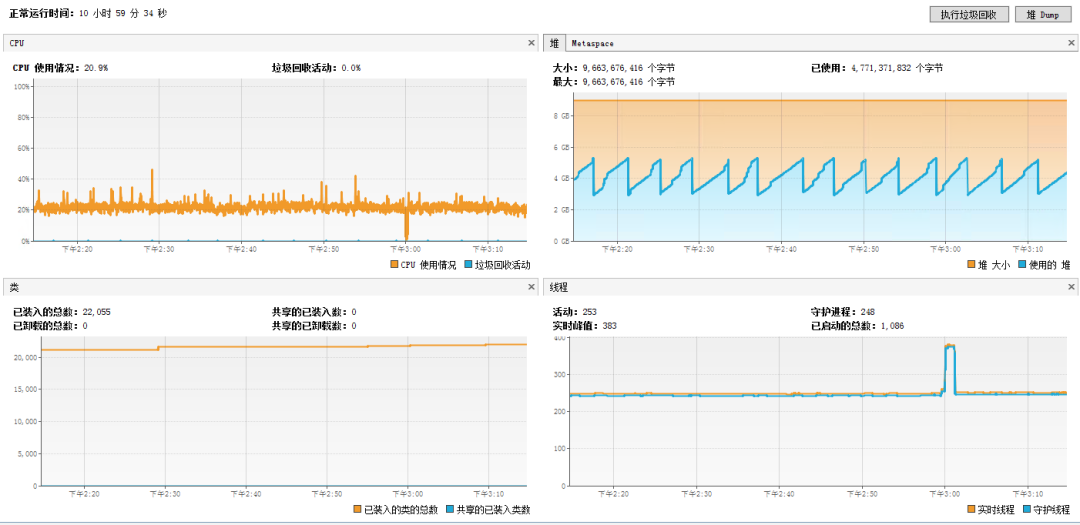
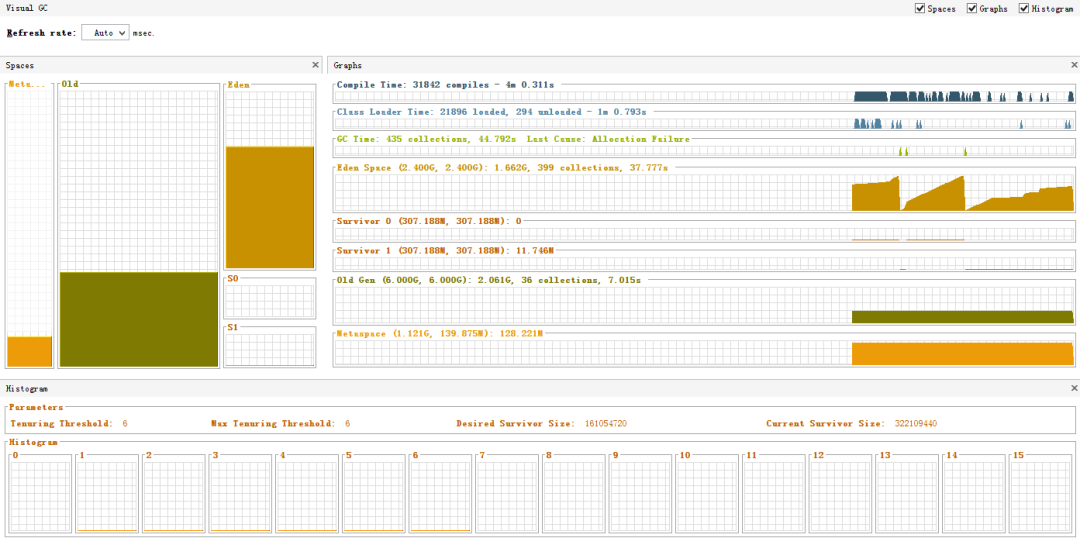
2.GC
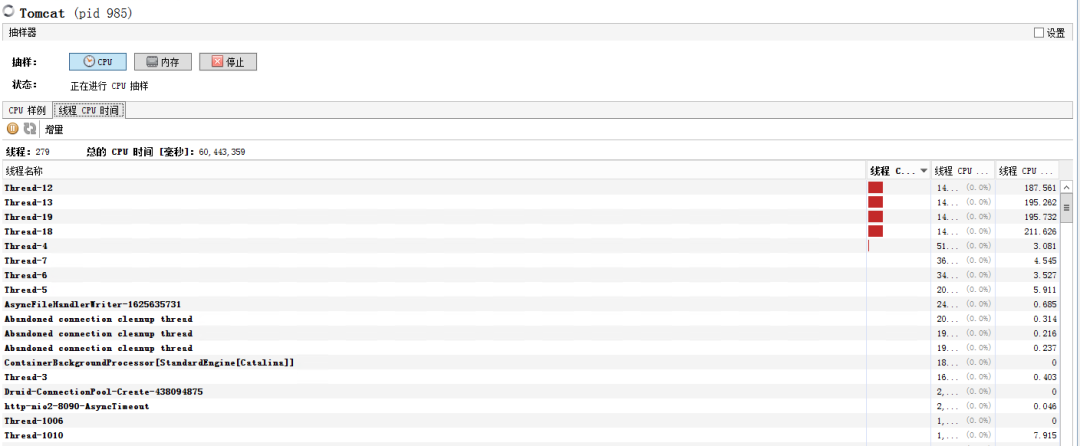
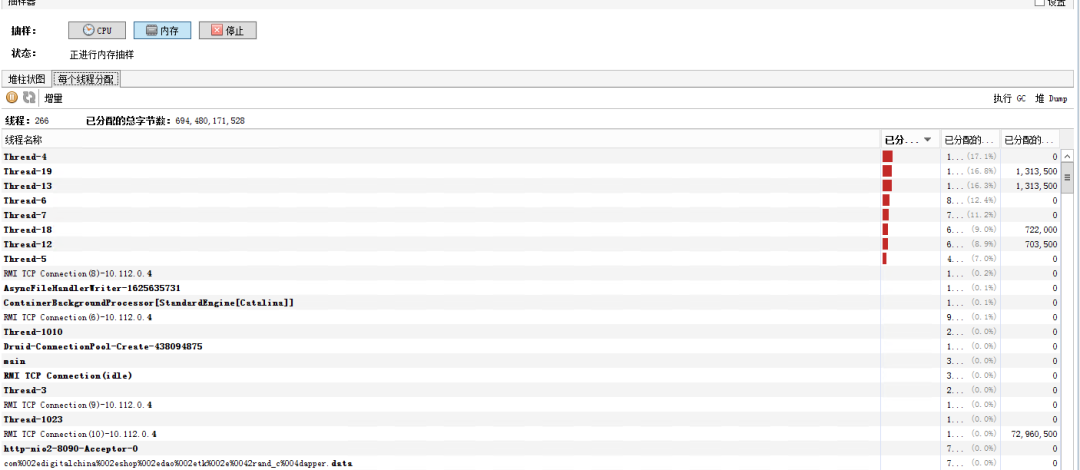
3.抽样器cou和内存
cpu
内存
七、总结
本篇文章从实战角度,从问题识别,问题定位,问题分析,提出解决方案,实施解决方案,监控调优后的解决方案和调优后的观察等角度来与大家一起交流分享本次线上高并发调优整个闭环过程,当然,由于篇幅的限制,有些细节和优化手段未在本篇文章中提及;虽然解决了该问题,但是从长远来看,该单体项目任然存在很大的问题和隐患,下面随便举几个:
前后端紧耦合,未分离;
由于该系统秒杀业务属于非持续性并发,即局部性并发,当前并未做局部并发架构的调整;
由于该系统秒杀业务与该项目紧紧耦合在一起,未进行隔离,未独立成单独模块,未单独部署,从而存在因秒杀业务造成整个系统瘫痪的风险;
未做流量削峰和流量限流,如加mq等软手段;
redis未做高可用集群。
- END -
精彩文章推荐:
点亮,服务器三年不宕机
