
斗鱼 Juno 监控中心的设计与实现
前言
伴随微服务的推广,程序粒度的日趋小型化,服务数量逐渐增长,需要更多的关注服务本身的监控,服务上下游服务情况,以及相关数据源中间件的状态。我们需要更加多维度服务监控,能够对服务调用链路进行可视化、对目标服务调用时客户端与服务端的实时监控。在 Juno 监控中心,我们尝试解决这些问题。
为什么需要监控中心
在行业内越来越多的公司需要开发人员懂得服务器基础架构、操作系统、网络、语言特性、业务整体架构、面对线上问题快速分析快速定位、还包括服务性能调优,对这些方面的要求就是 Google 倡导的 SRE(站点可靠性工程师)。这项工作依赖于很多工具才能顺利完成,例如日志系统、发布系统、监控系统等等。
在斗鱼微服务管理系统 Juno,其中的监控中心的设计就是为协助开发人员进行高效的服务稳定性维护工作,完成对微服务系统的健康支持:
水位瓶颈,在斗鱼进行全链路压测,通过监控系统可以找到服务链路中的瓶颈,了解核心项目的具体水位;
故障预防,采用环比和同步数据进行服务健康波动分析,进行一定程度上的异常预防;
故障排查,线上故障快速定位,给出服务调用链路,从监控异常数据开始分析,排查影响范围,定位问题触发点。
主流产品差异性
只针对市场上的免费解决方案进行分析,目前分析的 Zabbix、Nagios 都比较偏向于基础运维监控工具。Juno 监控中心是 Grafana 和 Prometheus 的最佳实践之一,更偏向于业务监控。
| 优点 | 缺点 | |
|---|---|---|
| Zabbix | - 数据采集方式多样 - 可用性高 - 历史数据可查询 - 安全审计 | - 性能瓶颈 - 二次开发难度 - housekeeping 的数据库压力 |
| Nagios | - 配置灵活 - 多样性的报警条件设置 | - 无历史数据存储 - 配置复杂 - 控制台功能较弱 |
Juno 监控中心简介
Juno 监控中心理念
Juno 监控中心有三个核心理念:容量水位;监控预警;快速定位。
容量水位
容量水位:服务可以承受多少的 QPS。通过全链路压测的方式获取对外提供 API 在微服务体系中的整体链路,首先探测服务本身可承载的容量是多少,针对危险水位进行数据采集,并以此作为流量变化后的扩容依据。
监控预警
监控预警:多个维度进行监控预警。
服务响应时间、QPS、成功率这三个基础维度进行告警配置;
对各指标根据历史数据进行环比计算预警;
进一步根据服务各自的水位进行兜底告警。
快速定位
快速定位:在故障发生是,通过响应速度来判断在哪个服务出现了问题,通过 TOP 指标和上下游链路解析快速定位异常点,再进一步结合异常服务上下文监控数据和日志数据进行错误分析。在异常恢复后也可以通过监控进行判断服务状态。
Juno 监控中心特点
| 部署简单 | 依赖 ETCD 和 prometheus 进行部署,数据采集和服务治理采用基本一致的组件 |
|---|---|
| 插件支持 | 结合 Juno Agent 进行数据采集插件化配置 |
| 管理后台 | 在 web 界面进行配置定制化加载,定制化的交互 |
| 配置监控 | 客户端配置信息监控;管理后台直接展示配置在哪些实例上被哪些服务使用 |
| 自动发现 | 基于 Juno Agent 的心跳上报进行监控数据节点发现 |
| 告警配置 | 服务告警条件配置丰富 |
Juno 监控中心设计
总体设计
层次设计
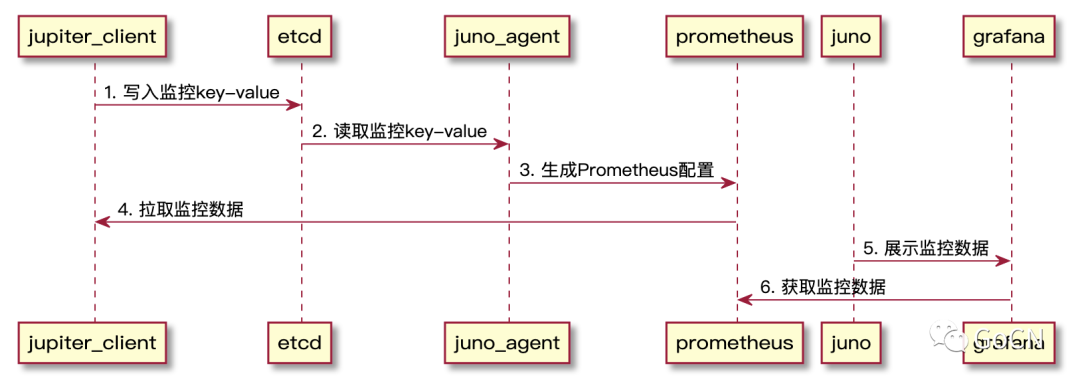
下图描述 Juno 监控中心的总体设计,从下往上分析:
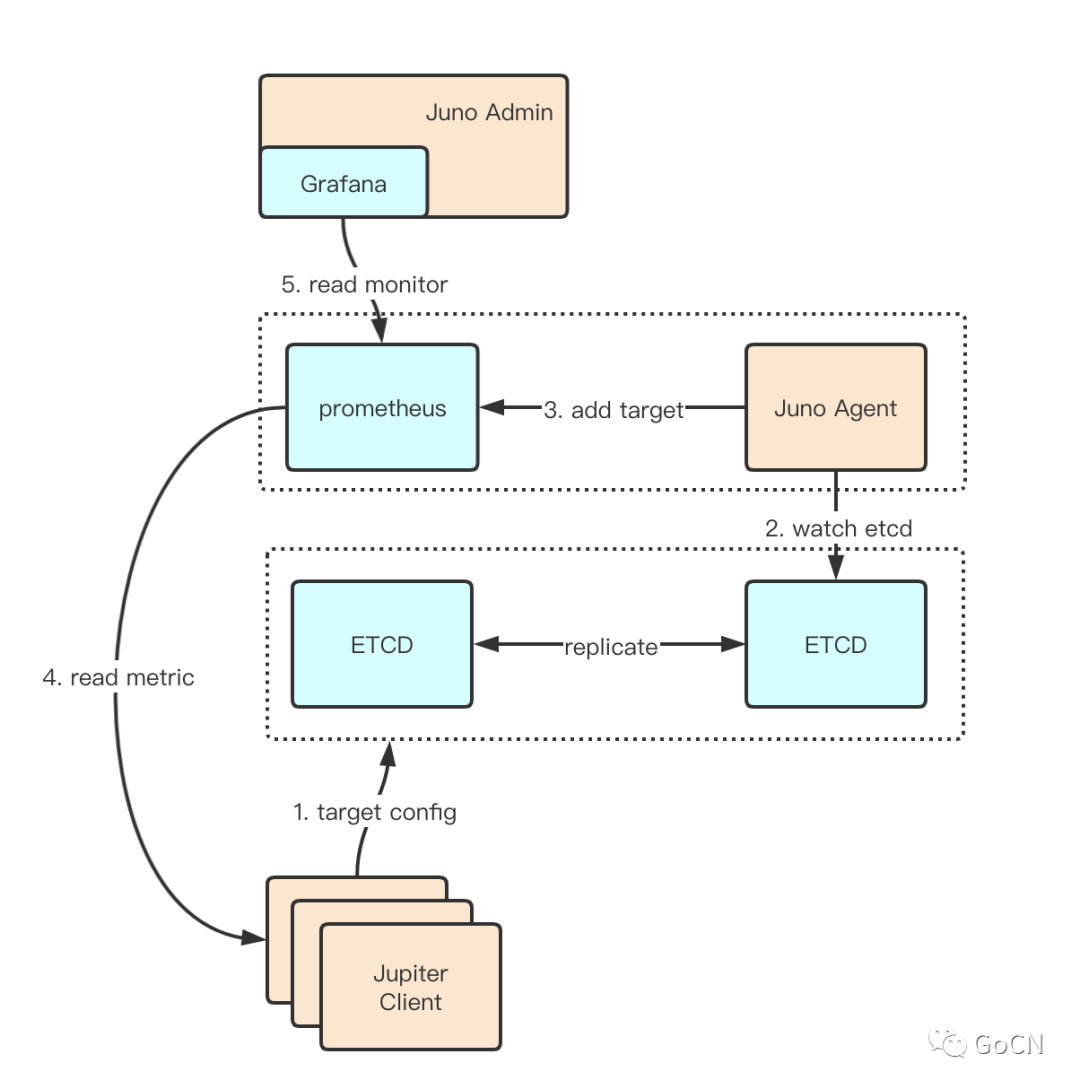
采用 Jupiter 框架构建的客户端,服务启动之后会在 ETCD 中写入监控的 KEY;
Juno Agent 服务监听到监控的 KEY,生成 Prometheus 的 Target 配置;
Prometheus 根据 Target 配置读取 Jupiter Client 的监控数据;
在 Juno Admin 内嵌 Grafana 读取 Prometheus 进行监控数据展示。
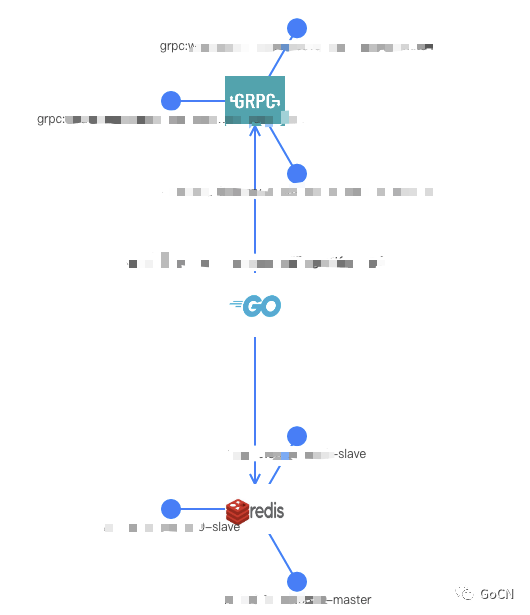
客户端设计
下图简要描述 Jupiter 客户端(Jupiter Client)的部分:
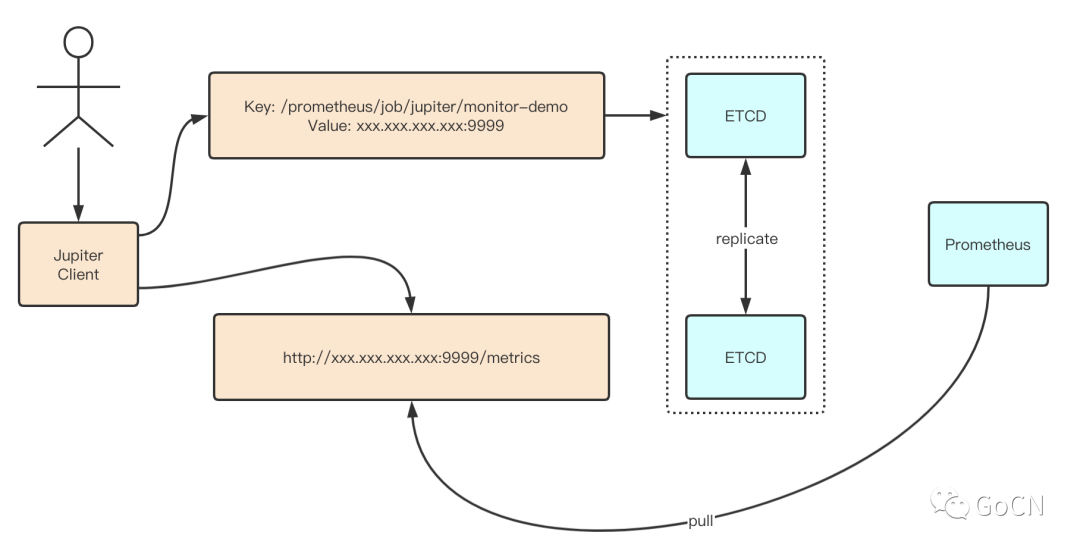
用户构建 Jupiter Client,在 ETCD 中写入监控的 key-value;
同时 Jupiter Client 提供一个自建的 Prometheus
Pushgateway(http://xxx.xxx.xxx.xxx:9999/metrics);
Prometheus 由 Juno Agent 生成 Target 配置后周期性的 pull 监控数据;
服务端设计
核心流程就是 Grafana 增加 Prometheus 数据源,Prometheus 通过 Juno Agent 生成的配置进行监控数据拉取。这里 Juno Agent 仅仅只用于 Prometheus 配置的生成,不上报任何的监控数据。
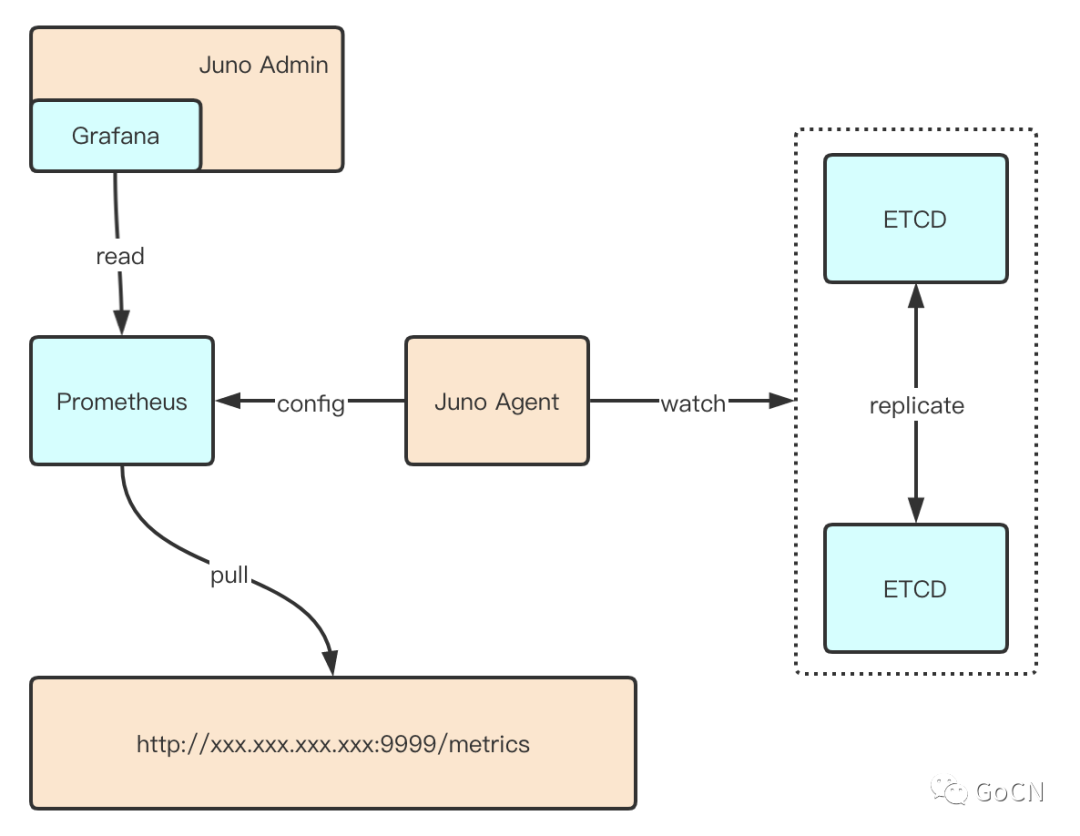
Juno Agent 生成的 Target 配置如下:
- targets:
- "127.0.0.1:9999"
labels:
instance: monitor-demo
job: jupiter
如果需要增加其他的监控数据,可以不使用 Juno Agent,直接在 Prometheus 中增加期望的 Pushgateway,并且在 Juno Admin 中的 Grafana 配置管理中直接增加模板地址即可进行嵌入展示。以下按照我们使用的监控数据上报格式举例,Jupiter Client 会将服务启动时相关的:应用版本、机器 IP、机器名称、应用信息写入 buid_info 中,这些基础数据会作为其他监控直接的基础 label,进行后续的监控条件筛选。
kubernetes 集群部署方案
虚拟容器化是大势所趋,Juno 监控中心对 k8s 集群的支持方案基本与物理机部署方案一致,容器会产生 Pushgateway 地址漂移,从管理后台通过 UI 界面查询需要根据历史 POD 数据进行历史监控数据查询。
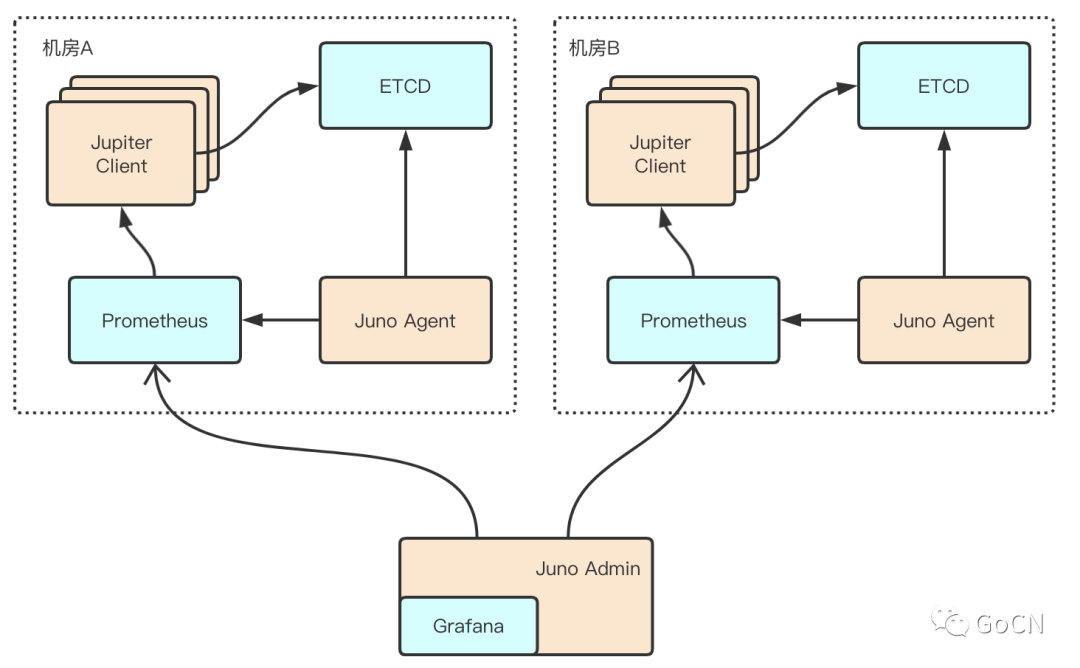
多机房部署方案设计
Juno 监控中心支持多机房(IDC),在实际业务场景中会同时使用多地区的机房,机房之间不进行跨机房通信,
每个机房都搭建独立的 ETCD 和 Prometheus,监控数据在各机房进行独立存储,管理后台(Juno Admin)通过内嵌 Grafana 访问各机房 Prometheus。所有的数据流转由某一个部署监控中心管理后台的机房完成,该机房依靠专线与其他机房进行通信,在遭遇专线网络故障时,可直接切换到外网 IP 保证服务稳定,对不同机房间的操作互相隔离,不产生依赖影响。
!
技术点详解
监控数据采集实现
部署基础服务包括 ETCD 和 Prometheus;
采用 Jupiter 框架构建服务,成功启动服务后会完成两个操作:
写入监控 key-value;
通过服务治理端口提供 Pushgateway;
在 Prometheus 部署的机器上,进行 Juno Agent 服务部署完成两个功能:
进行 ETCD 的监控 key-value 监听;
通过监听的数据产生 Prometheus 需要的 Target 配置;
在 Prometheus 配置生成完毕后,直接拉取 Jupiter Client 的 Pushgateway 数据,完成监控数据的采集。
监控采集时序图
配置的整个生命周期流转如下图所示,归纳为四个配置点进行表述:管理后台(前端交互 UI)、配置服务(管理后台服务)、下发服务(Minerva Proxy+Minerva Agent)、应用。
网关功能
采用 Grafana 子域名配置,直接使用 Juno Admin 的域名例如(http://jupiterconsole.douyu.com/),配置为(http://jupiterconsole.douyu.com/grafana)直接进行访问,采用 juno 系统的登录态以及用户信息,统一了用户权限管理。
!
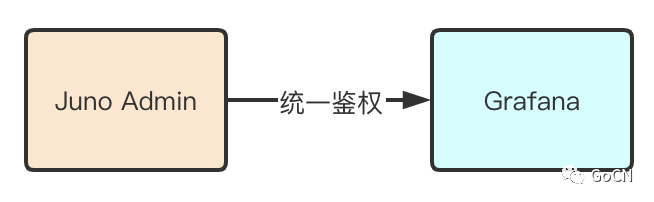
目前网关功能在后期可扩展成对任意无状态的三方系统的鉴权支持,只需要在 Juno Admin 网关设置中进行域名以及目标地址的配置即可。
可用性分析
分析多故障场景,当前 Juno 监控中心的降级方案如下:
| 场景 | 影响 | 降级方案 |
|---|---|---|
| Juno Agent 挂掉 | 新增服务无法生成对应的 Prometheus Target 配置,拉取不到监控数据。不影响已有服务的监控采集与查询 | |
| 某个 ETCD 节点挂掉 | 无影响 | Juno Agent 可以重连其他 ETCD 节点 |
| 全部 ETCD 节点挂掉 | Jupiter Client 启动后无法成功写入监控 Key,同样无法生成 Target 配置。不影响已有服务的监控采集与查询 | |
| Prometheus 挂掉 | 无法采集监控数据 | |
| Grafana 挂掉 | 无法查询监控数据 | |
| 专线故障 | 监控数据拉取失败 | 使用公网 IP 继续相关操作 |
为什么选择 ETCD
为什么采用 ETCD 作为监控中心和配置存储/订阅通知引擎,而不是使用传统的 ZK,Eureka?我们大致总结了一下,有以下几方面的原因:
它提供了强大和灵活的 K-V 存储能力,可以在保证性能的前提下对配置项进行最小粒度对存储;
它提供了对 key 或者 key 前缀的监听功能,正好满足我们对某些配置项需要动态下发的需求;
我们的项目本身就使用了 ETCD 做服务注册与发现和存储功能,维护和使用相对于 zk,Eureka 会熟练的多。
为什么采用 Prometheus
为什么监控中心采用 Prometheus 进行监控指标存储,有以下几个原因:
Prometheus 是 CNCF 旗下成熟的开源项目,社区活跃;
数据模型灵活,多样性的 label,在数据采集阶段支持数据属性自定义;
PromQL,强大的查询能力,多功能封装的查询语句,能满足绝大多数业务场景;
良好的性能,支持每秒十万条以上的监控数据采集。
交互设计
界面概览
下图是 Juno 监控中心的首页。
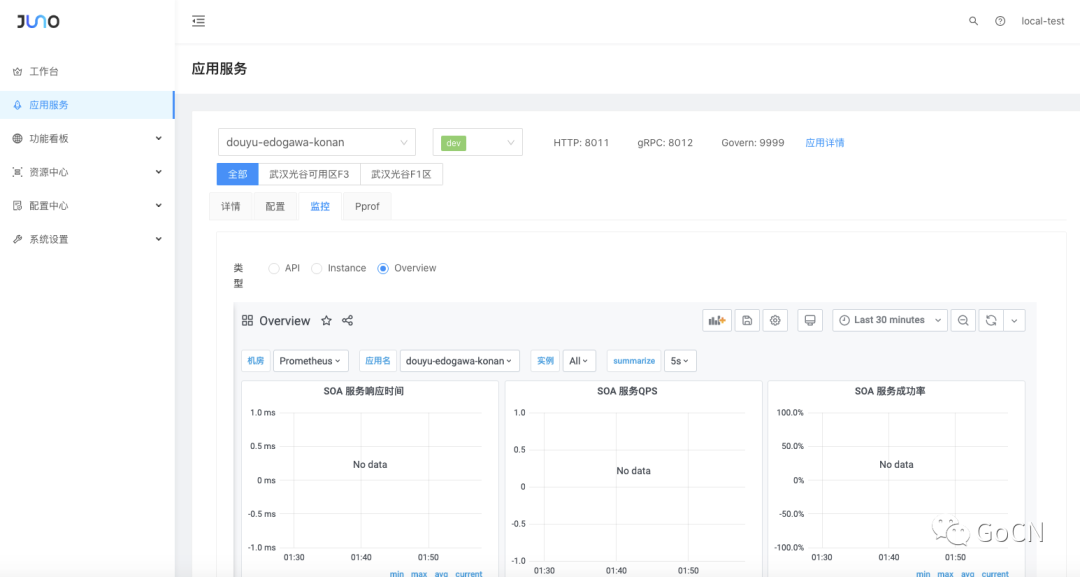
页面上方:
应用选择以及环境切换,展示了应用相关的基础信息;
机房切换;
应用服务可用功能模块切换;
页面中央,采用按钮形式展示了可用 Dashboard;
页面下方,嵌入 Grafana 监控页面。
服务概览
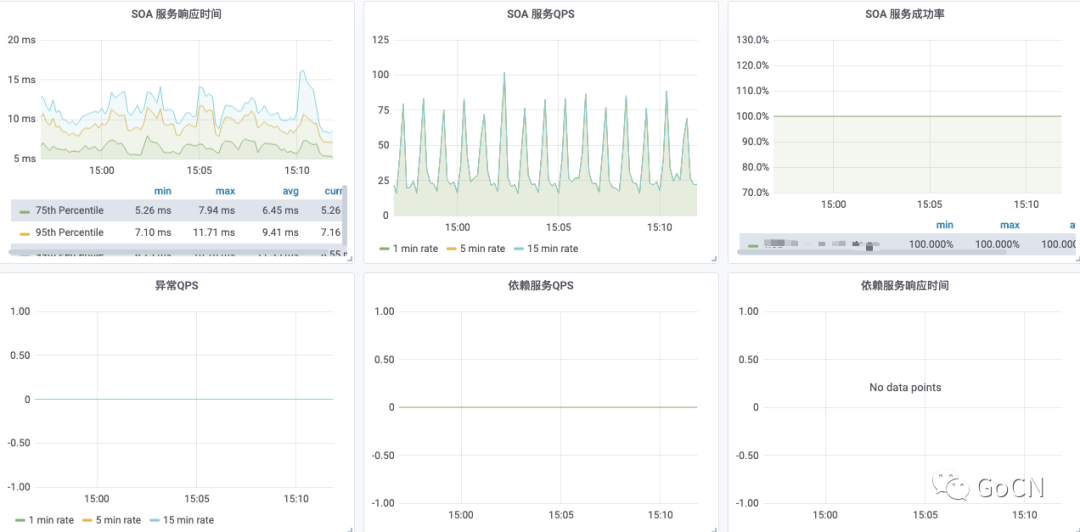
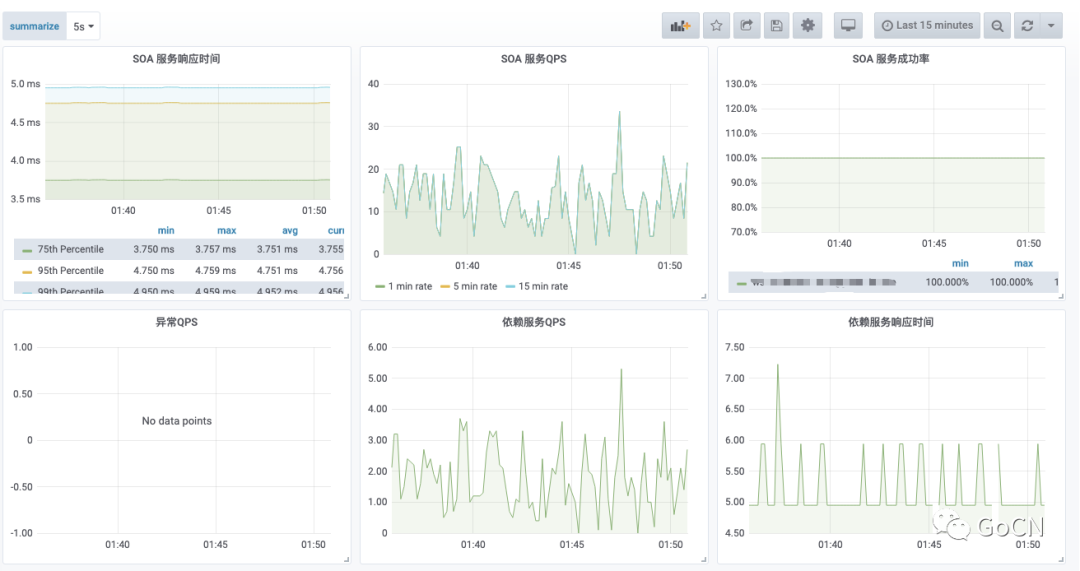
服务概览有三个侧重点:响应时间、QPS、成功率。这是对服务整体质量的评价。
健康检查
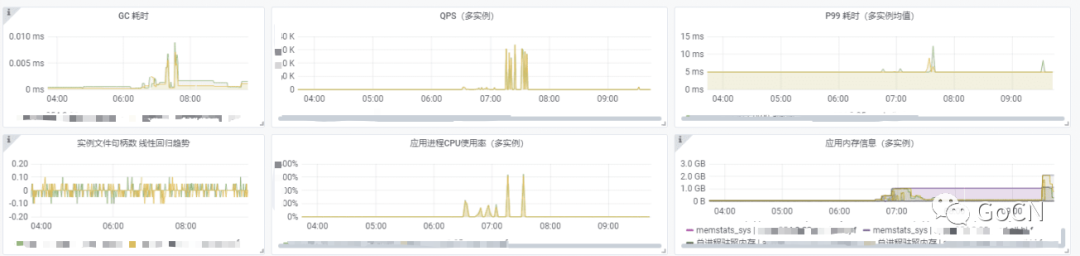
目前服务在某一环境中部署的实例数量,是否存在异常情况,最大的文件句柄数、CPU 消耗、内存使用、QPS 指标,能帮助用户在第一时间了解的当前服务的具体情况,进一步服务心跳更新时间,当前采用的框架版本相关的 git 提交版本,都进行表格化展示,可以为问题排查提供更多的客观数据。
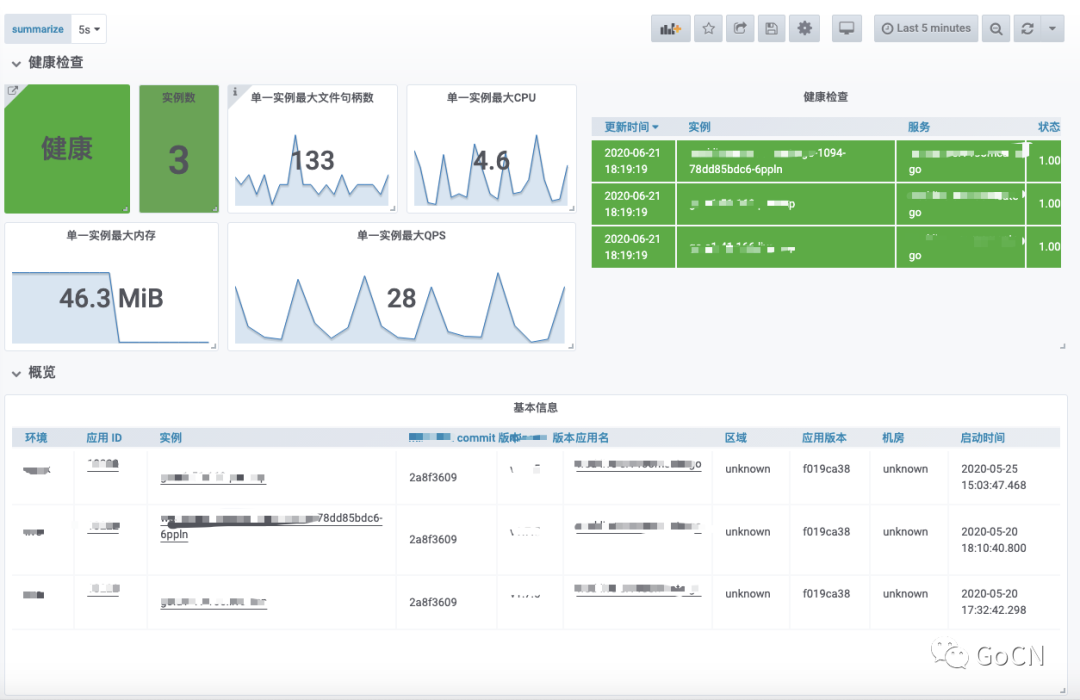
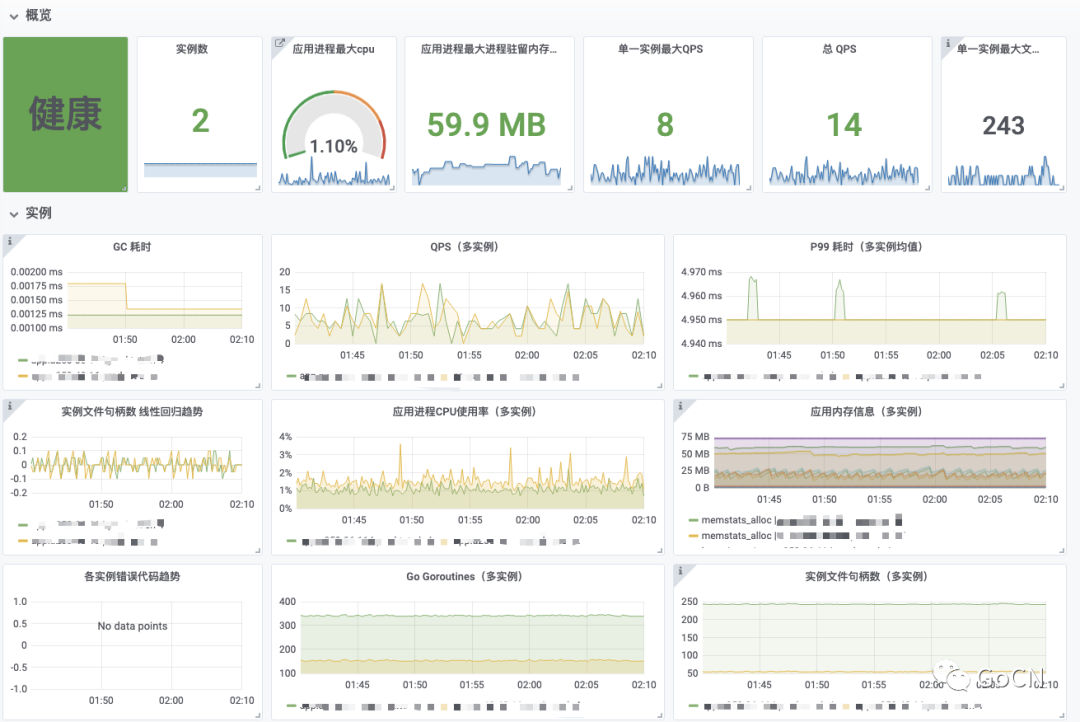
实例监控
从实例维度进行服务监控分析。
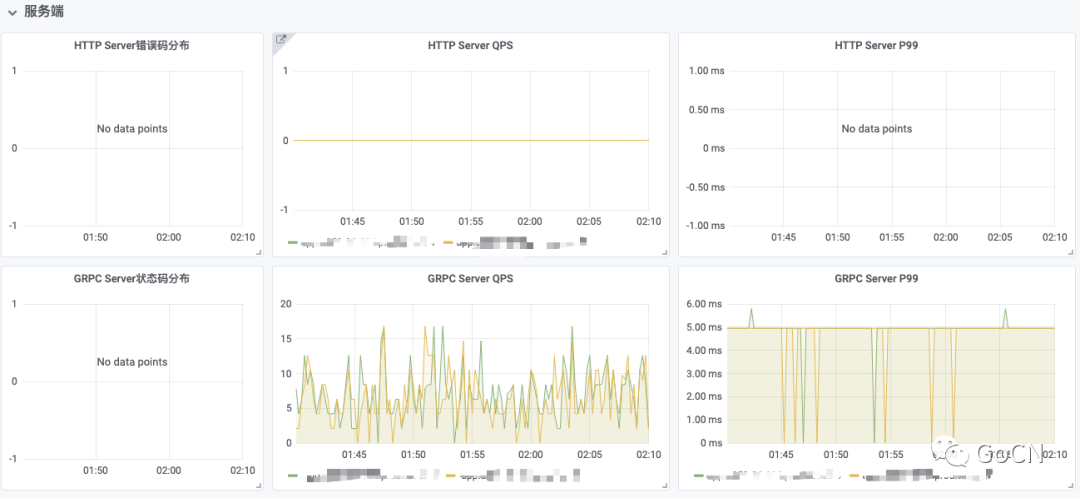
服务端监控
服务本身对外提供服务的情况,依据 HTTP 和 GRPC 进行区分,给出 QPS 和 P99 的数据。
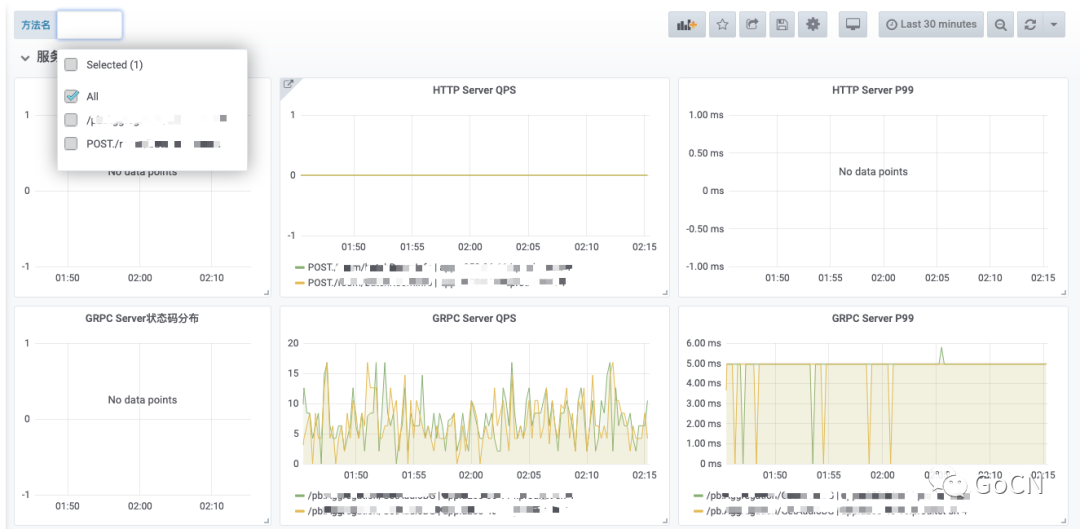
接口监控
对服务提供的具体 API 进行监控指标采集和展示。
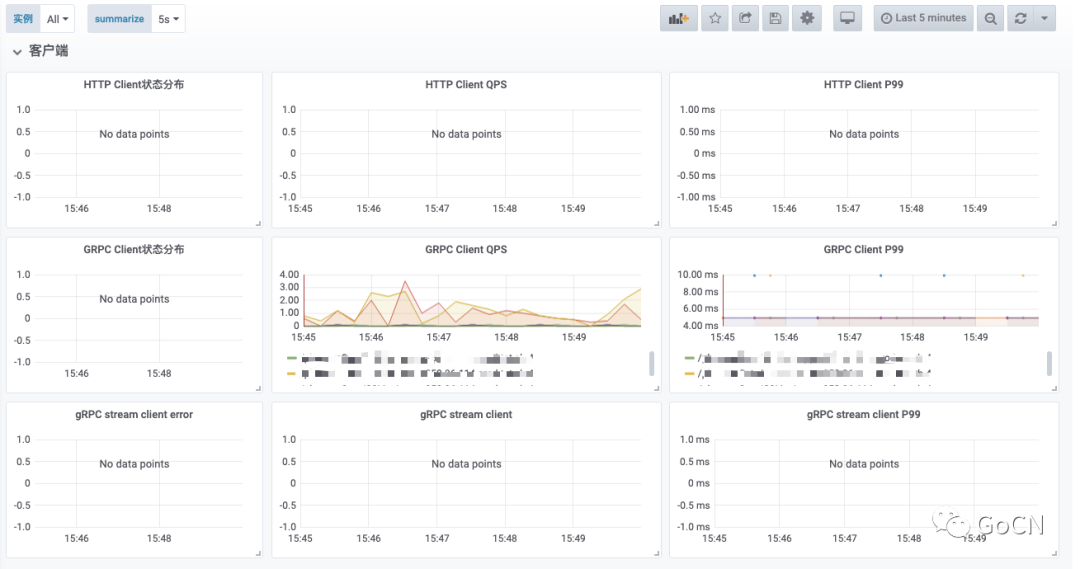
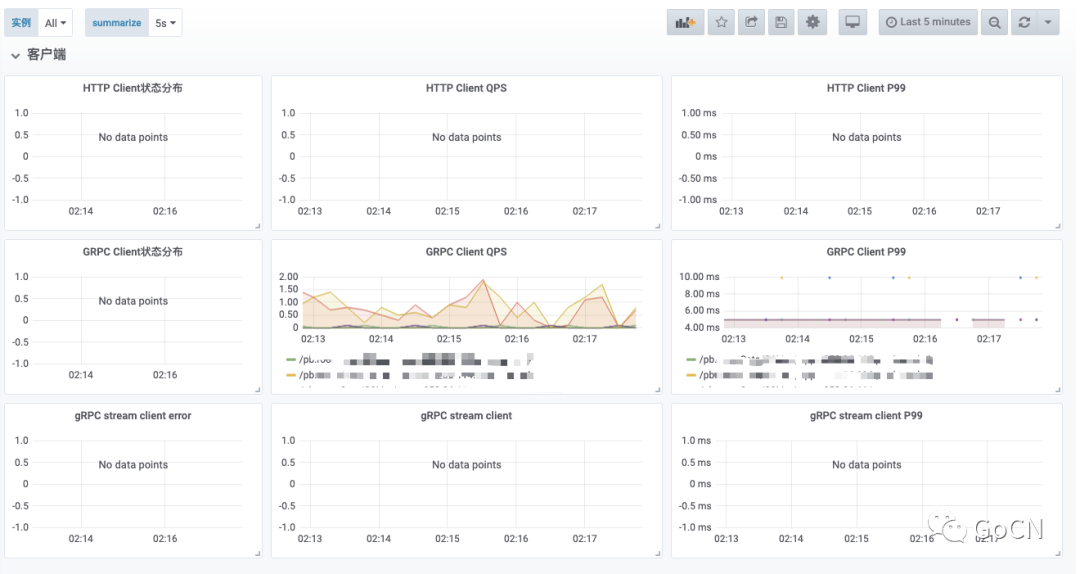
客户端监控
查询当前服务对下游服务的调用情况监控,可以快速定位是服务本身异常,还是下游服务异常。
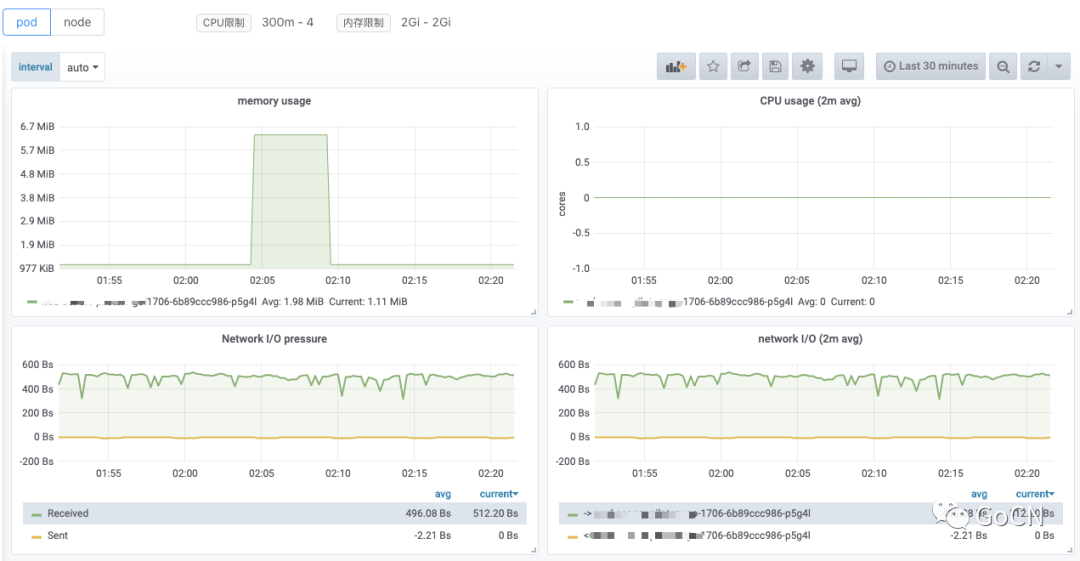
容器监控
服务容器化部署之后,给出对 pod 情况的独立监控,可结合服务本身监控进行交集查询。
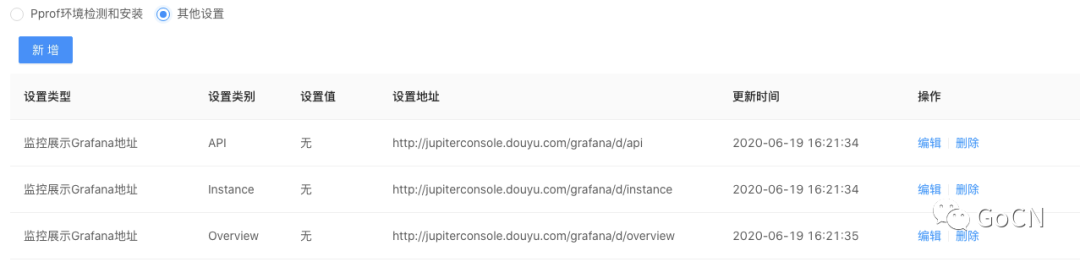
模板配置
提供模板配置的功能,用户可以自行修改 Dashboard 地址,系统会依次展示这些 Dashboard。
总结
本文从 Juno 监控中心的层次结构开始分析,说明了服务监控采集流程包括客户端、服务端的设计,讲解了部分技术点包括采集时序图、网关设计等;在架构分析的基础上对各个功能点进行分析,希望帮助各位进一步理解我们的设计思维;最后展示监控相关的交互页面,以及斗鱼 Juno 监控中心设计的监控系统设置界面。
相关资料
jupiter 官网 http://jupiter.douyu.com
jupiter 仓库地址
https://github.com/douyu/jupiter
juno 仓库地址
https://github.com/douyu/juno
demo 演示地址
http://jupiterconsole.douyu.com