
Go 语言的并发
并发
前言
在学习 Go 的并发之前,先复习一下操作系统的基础知识。
并发与并行
先来理一理并发与并行的区别。
并行:指的是在同一时间,多个程序在不同的 CPU 上共同运行,互相之间并没有对 CPU 资源进行竞争。比如,我在看书的时候,左手用来翻书,右手做笔记,两者可以同时进行。
并发:如果系统只有一个 CPU,有多个程序要运行,系统只能将 CPU 的时间划分为多个时间片,然后分配给不同的程序。比如,我看书的时候,只能用右手翻完书之后,才能腾出手来做笔记。
可是明确的是并发≠并行,但是只要 CPU 运行足够快,每个时间片划分足够小,就会给人们造成一种假象,认为计算机在同一时刻做了多个事情。
进程、线程、协程
进程是一个程序执行的过程,也是系统进行资源分配和调度的基本单位。简单来说,一个进程就是我们电脑上某个独立运行的程序。
而线程是系统能够调度的最小单位,它被包含在进程里面,是进程中的实际运作单位,一个进程可以包含多个线程。可以将进程理解为一个工厂,而工厂里面的工人就是线程。就像工厂里面必须要有一个工人才能工作一样,每个进程里面也必须有一个线程才能工作。比如,JavaScript 就被成为单线程的语言,说明 JavaScript 工厂里面只有一个打工人,这个打工人就是工头,称为主线程。多线程的进程中也会有一个主线程,主线程一般随着进程一起创建和销毁。

进程与线程都是操作系统上的概念,程序中如果要进行进程或者线程的切换,在切换的过程中,需要先保存当线程的状态,然后恢复另一个线程的状态,这是需要耗费时间的,如果是进程的切换还可能跨 CPU,无法利用 CPU 缓存,导致进程比线程的切换成本更加高昂。
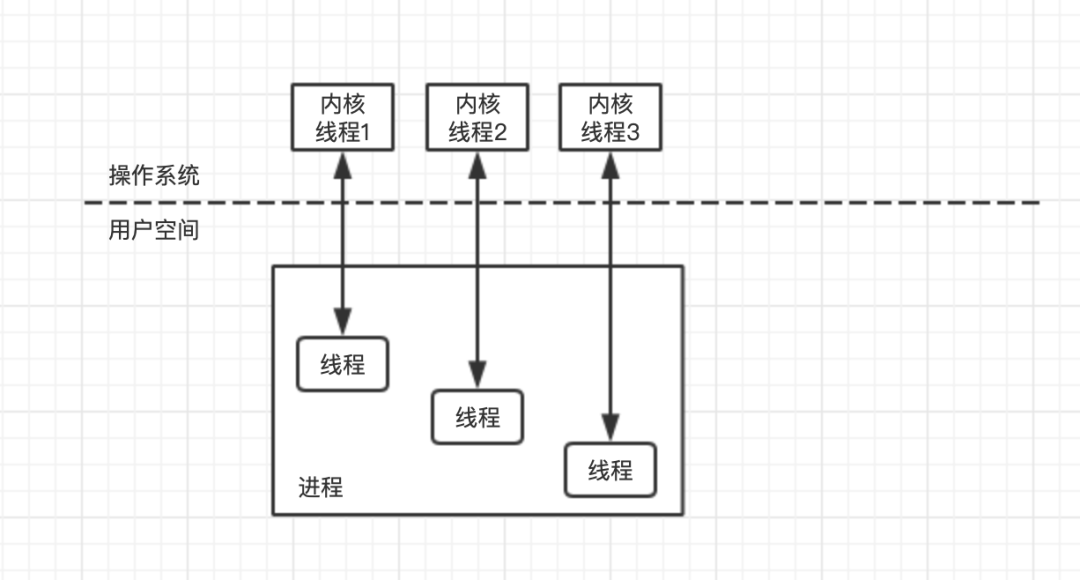
所以,除了系统级别的内核线程外,一些程序中创建了用户线程这一说,这么做可以减少与操作系统交互,将线程的切换控制在程序内,这种用户态的线程被称为协程。用户线程的切换完全由程序控制,实际上使用的内核线程就只存在一个,内核线程与用户线程之间的关系为一对多。虽然这样做可以减少线程上下文切换带来的开销,但是,无法避免阻塞的问题。一旦某个用户线程被阻塞会导致内核线程的阻塞,无法进行用户线程进行切换,从而整个进程都被挂起,
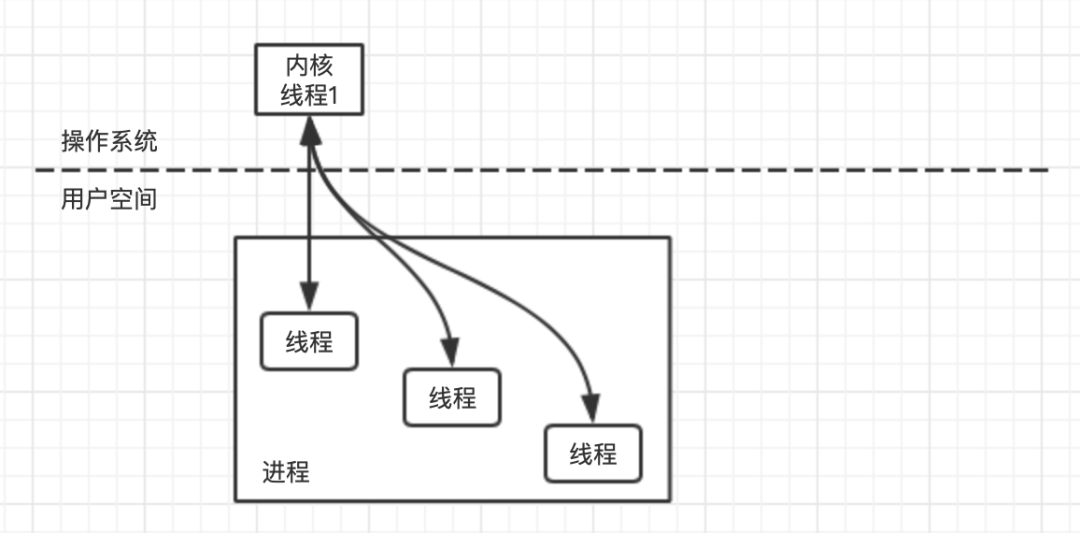
协程
Go 语言中的线程模型既不是使用内核线程,也不是完全的用户线程,而是一种混合型的线程模型。用户线程与内核线程的对应关系为多对多,用户线程与内核线程动态关联,当某个线程出现阻塞的时候,可以动态切换到另外的内核线程上。
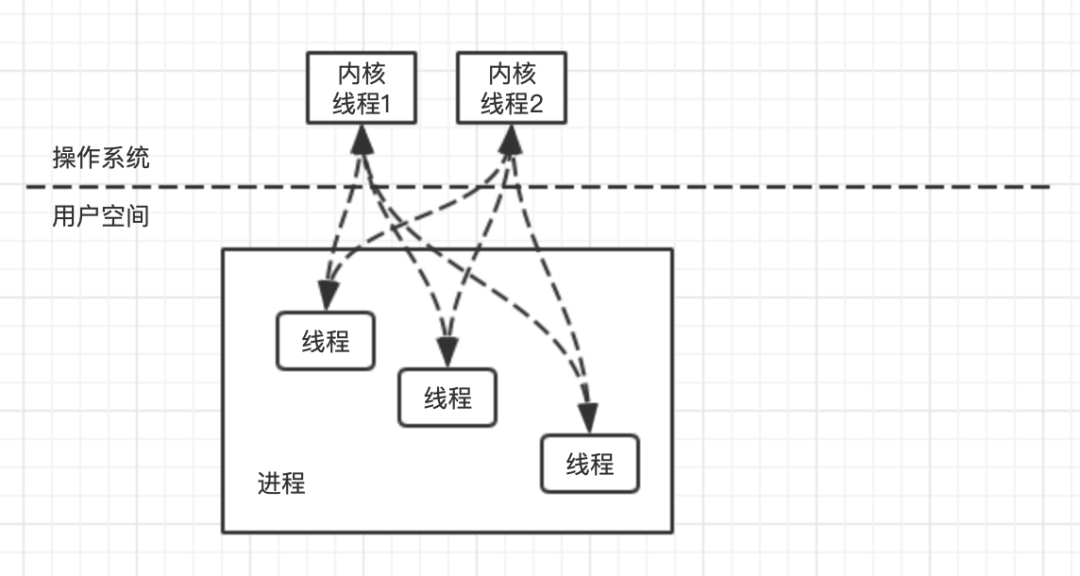
G-P-M模型
上面只是 Go 语言中抽象层面的线程模型,具体是如何进行线程调度的,还是看看 Go 语言的代码。
func log(msg string) {
fmt.Println(msg)
}
func main() {
log("hello")
go log("world")
}
之前的文章介绍过,Go 程序在运行时,默认以 main 函数为入口,main 函数中运行的代码会到一个 goroutine 中运行。如果我们在调用的函数前,加上一个 go 关键词,那么这个函数就放到另外一个 goroutine 中运行。
这里说的 goroutine 就是 Go 语言中的用户线程,也就是协程。Go 语言在运行时,会建立一个 G-P-M 模型,这个模型专门负责 goroutine 的调度。
G:gotoutine(用户线程); P:processor(逻辑处理器); M:machine(机器资源);
每个 goroutine 都会放到一个 goroutine 队列中,由于是用户自主创建,上下文的切换成本极低。P(processor)的主要作用是管理用户线程,将 goroutine 合理的安排到内核线程上,也就是这个模型的 M。通常情况下,G 的数量远远多于 M。
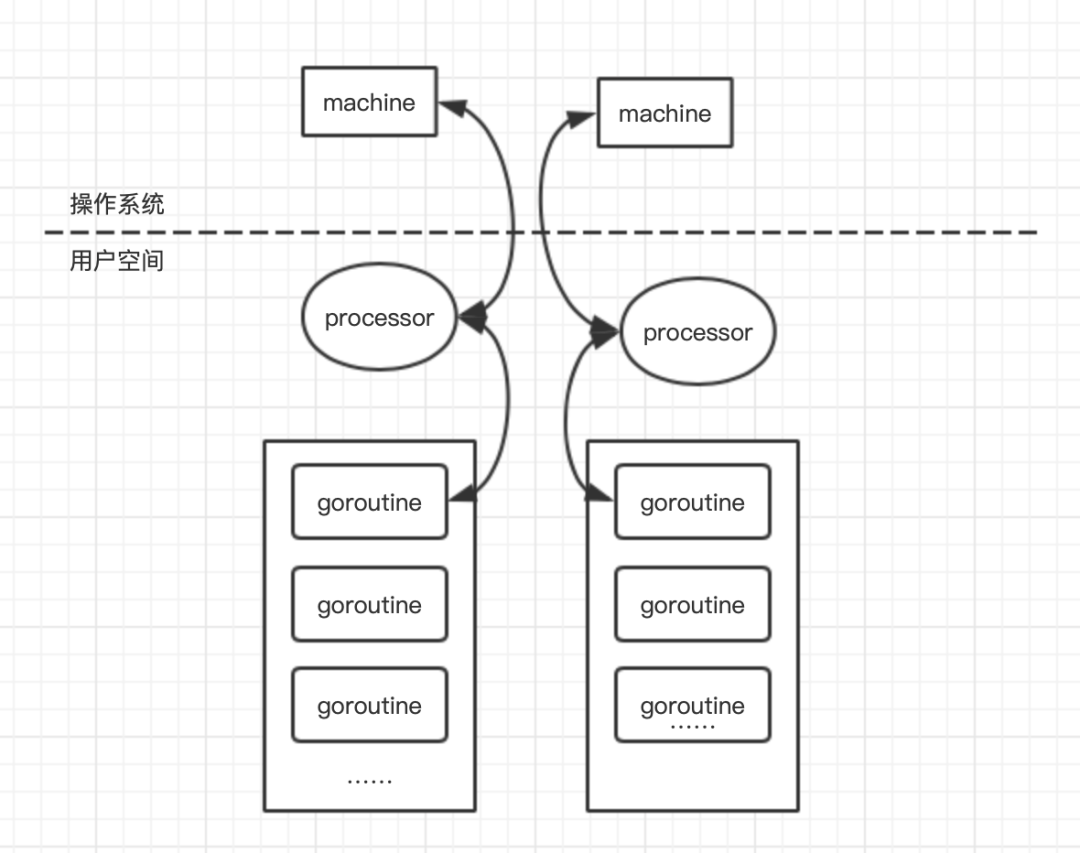
Goroutine
如果你有运行过上面的代码,你会发现,go 关键词后的函数并没有真正执行。
func log(msg string) {
fmt.Println(msg)
}
func main() {
log("hello")
go log("world")
}
运行后,终端只输出了 hello,并没有输出 world。
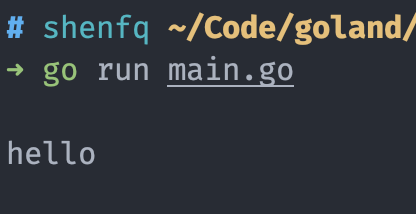
这是因为 main 函数会在主 goroutine 中运行,类似于主线程,而每个 go 语句会启动一个新的 goroutine,启动后的 goroutine 并不会直接执行,而是会放入一个 G 队列中,等待 P 的分配。但是主 goroutine 结束后,就意味着程序结束了,G 队列中的 goroutine 还没有等到执行时间。所以,go 语句后的函数是一个异步的函数,go 语句调用后,会立即去执行后面的语句,而不会等待 go 语句后的函数执行。
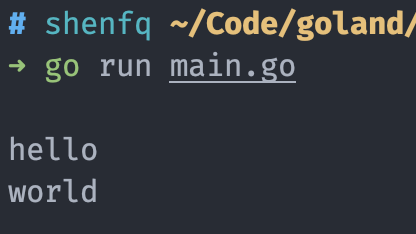
如果要 world 输出,我们可以在 main 函数后面加一个休眠,延长主 goroutine 的执行时间。
import (
"fmt"
"time"
)
func log(msg string) {
fmt.Println(msg)
}
func main() {
fmt.Println()
log("hello")
go log("world")
time.Sleep(time.Millisecond * 500)
}
通道
多线程编程中,由于各个线程之间需要共享数据,一般采用的是共享内存的方案。但是这么做,势必会出现多个线程同时修改同一份数据情况,为了保证数据的安全性,需要为数据加锁,处理起来就比较麻烦。
所以在 Go 语言社区有一句名言:
不要通过共享内存来通信,而应该通过通信来共享内存。
创建通道
这里说的通信的方式,就是 Go 语言中的通道(channel)。通道是 Go 语言中的一种特殊类型,需要通过 make 方法创建一个通道。
ch := make(chan int) // 创建一个 int 类型的通道
创建通道的时候,需要加上一个类型,表示该通道传输数据的类型。也可以通过指定一个空接口的方式,创建一个可以传送任意数据的通道。
ch := make(chan interface{})
创建的通道分为无缓存通道和有缓存通道,make 方法的第二个参数表示可缓存的数量(如果传入 0,效果和不传一样)。
ch := make(chan string, 0) // 无缓存通道,传入
ch := make(chan string, 1)
发送和接收数据
通道创建后,通过 <- 符号来接收和发送数据。
ch := make(chan string)
ch <- "hello world" // 发送一个字符串
msg := <- ch // 接收之前发送的字符串
实际在这个代码运行的时候,会提示一个错误。
fatal error: all goroutines are asleep - deadlock!
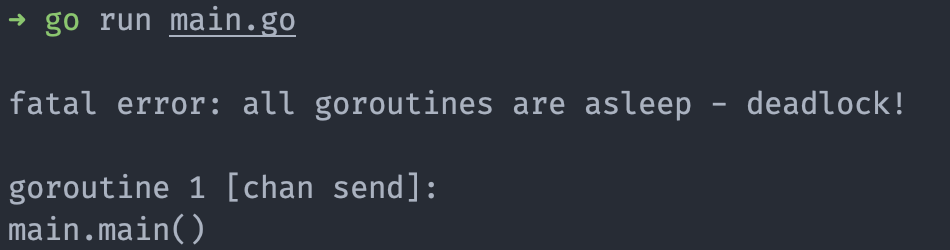
表明当前的 goroutine 处于挂起状态,并且后续不会有响应,只能直接中断程序。因为这里创建的是无缓存通道,发送数据后通道不会将数据缓存在通道中,导致后面要找通道要数据的时候无法正常从通道中获取数据。我们可以将通道的缓存设置为 1,让通道可以缓存一个数据在里面。
ch := make(chan string, 1)
ch <- "hello world" // 发送一个字符串
msg := <- ch // 接收之前发送的字符串
fmt.Println(msg)
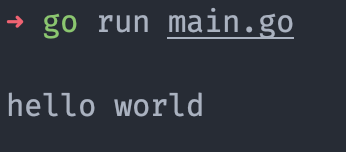
但是如果发送的数据超出了缓存数量,或者接受数据时,缓存里面已经没有数据了,依然会报错。
ch := make(chan string, 1)
ch <- "hello world"
ch <- "hello world"
// fatal error: all goroutines are asleep - deadlock!
ch := make(chan string, 1)
ch <- "hello world"
<- ch
<- ch
// fatal error: all goroutines are asleep - deadlock!
协程中使用通道
那么无缓存的通道中,应该怎么发送和接收数据呢?这就需要将通道与协程进行结合,也就是 Go 语言中常用的并发的开发模式。
无缓存的通道在收发数据时,由于一次只能同步的发送一个数据,会在两个 goroutine 间反复横跳,通道在接受数据时,会阻塞当前 goroutine,直到通道在另一个 goroutine 发送了数据。
ch := make(chan string) // 创建一个无缓存通道
temp := "我在地球"
go func () {
// 接收一个字符串
ch <- "hello world"
temp = "进入了异次元"
}()
// 运行到这里会被阻塞
// 直到通道在另一个 goroutine 发送了数据
msg := <- ch
fmt.Println(msg)
fmt.Println("temp =>", temp)
为了证明通道在接收数据时会被阻塞,我们可以在前面加上一个 temp 变量,然后在另外的 goroutine 中修改这个变量,看最后输出的值是否被修改,以此证明通道在接受数据时是否发生了阻塞。
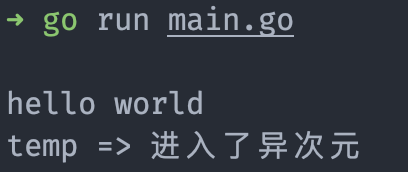
运行结果已经证明,当通道接收数据时,阻塞了主 goroutine 的执行。除了主动的从通道里面一条条的获取数据,还可以通过 range 的方式循环获取数据。
ch := make(chan string)
go func() {
for i := 0; i < 5; i++ {
ch <- fmt.Sprintf("数据 %d", i)
}
close(ch)
}()
for data := range ch {
fmt.Println("接收 =>", data)
}

如果使用 range 循环读取通道中的数据时,在数据发送完毕时,需要调用 close(ch) ,将通道关闭。
实战
在了解了前面的基础知识之后,我们可以通过协程 + 通道的写一段爬虫,来实战一下 Go 语言的并发能力。
首先确定爬虫需要爬取的网站,由于个人比较喜欢看电影,所以决定爬一爬豆瓣的电影 TOP 榜单。
其域名为 https://movie.douban.com/top250,翻到第二页后,域名为 https://movie.douban.com/top250?start=25 ,第三页的域名为 https://movie.douban.com/top250?start=50,说明每次这个 TOP 榜单每页会有 25 部电影,每次翻页就给 start 参数加上 25。
const limit = 25 // 每页的数量为 25
const total = 100 // 爬取榜单的前 100 部电影
const page = total / limit // 需要爬取的页数
func main() {
var start int
var url string
for i :=0; i < page; i++ {
start := i * limit
// 计算得到所有的域名
url := "https://movie.douban.com/top250?start=" + strconv.Itoa(start)
}
}
然后,我们可以构造一个 fetch 函数,用于请求对应的页面。
func fetch(url string) {
// 构造请求体
req, _ := http.NewRequest("GET", url, nil)
// 由于豆瓣会校验请求的 Header
// 如果没有 User-Agent,http code 会返回 418
req.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36")
// 发送请求
client := &http.Client{}
rsp, _ := client.Do(req)
// 断开连接
defer rsp.Body.Close()
}
func main() {
for i :=0; i < page; i++ {
url := ……
go fetch(url, ch)
}
}
然后使用 goquery 来解析 HTML,提取电影的排名以及电影名。
// 第二个参数为与主goroutine 沟通的通道
func fetch(url string, ch chan string) {
// 省略部分代码 ……
rsp, _ := client.Do(req)
// 断开连接
defer rsp.Body.Close()
// 解析 HTML
doc, _ := goquery.NewDocumentFromReader(rsp.Body)
// 提取 HTML 中的电影排行与电影名称
doc.Find(".item").Each(func(_ int, s *goquery.Selection) {
num := s.Find(".pic em").Text()
title := s.Find(".title::first-child").Text()
// 将电影排行与名称写入管道中
ch <- fmt.Sprintf("top %s: %s\n", num, title)
})
}
最后,在主 goroutine 中创建通道,以及接收通道中的数据。
func main() {
ch := make(chan string)
for i :=0; i < page; i++ {
url := ……
go fetch(url, ch)
}
for i :=0; i < total; i++ {
top := <- ch // 接收数据
fmt.Println(top)
}
}
最后的执行结果如下:
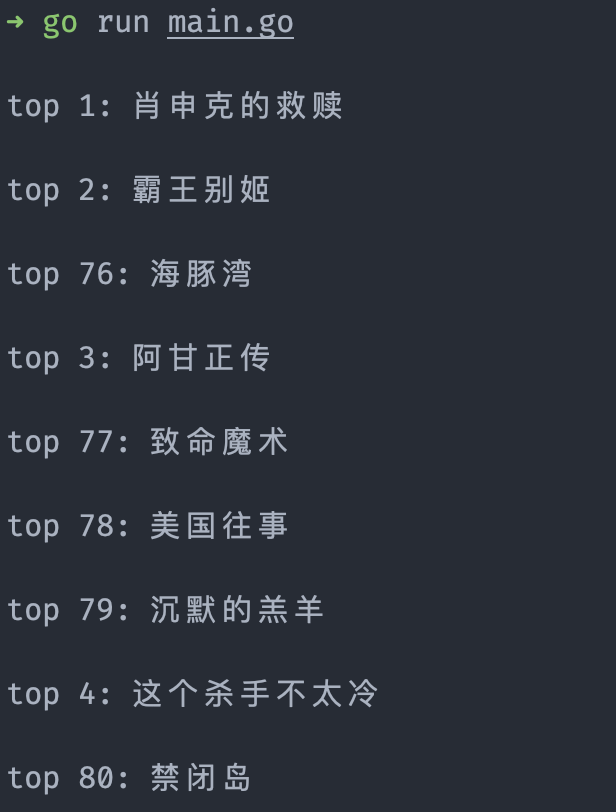
可以看到由于是并发执行,输出的顺序是乱序。
完整代码
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"net/http"
"strconv"
)
const limit = 25
const total = 100
const page = total / limit
func fetch(url string, ch chan string) {
req, _ := http.NewRequest("GET", url, nil)
req.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36")
client := &http.Client{}
rsp, _ := client.Do(req)
defer rsp.Body.Close()
doc, _ := goquery.NewDocumentFromReader(rsp.Body)
doc.Find(".item").Each(func(_ int, s *goquery.Selection) {
num := s.Find(".pic em").Text()
title := s.Find("span.title::first-child").Text()
ch <- fmt.Sprintf("top %s: %s\n", num, title)
})
}
func main() {
ch := make(chan string)
for i :=0; i < page; i++ {
start := i * limit
url := "https://movie.douban.com/top250?start=" + strconv.Itoa(start)
go fetch(url, ch)
}
for i :=0; i < total; i++ {
top := <- ch
fmt.Println(top)
}
}