
你问我DataX是谁?对不起,我活在Apache SeaTunnel的时代!

SeaTunnel正式通过世界顶级开源组织Apache软件基金会的投票决议,以全票通过的优秀表现正式成为Apache孵化器项目!

根据Apache官方网站显示:针对SeaTunnel进入Apache的投票全部持赞同意见,无弃权票和反对票,投票顺利通过。
Apache SeaTunnel是中国开发者主导的项目,也是Apache基金会中第一个诞生自中国的数据集成平台项目。
我个人在2018-2019年还专门做过离线异构数据交换的中间件,对海量数据交换中的一些痛点体会很深。
Seatunnel这样的产品出现几乎是大数据领域发展的必然结果。
简介
熟悉离线数据同步的同学应该对DataX不陌生。同样,Seatunnel是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,架构于Apache Spark和Apache Flink之上。
SeaTunnel原名Waterdrop,于2017年由乐视创建,并于同年在GitHub 上开源,2021年10月改名为SeaTunnel。
Seatunnel的中文是"水滴",来自中国当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波,表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰。
场景和能力
根据Seatunnel的官网显示,Seatunnel适用于以下场景:
海量数据ETL 海量数据聚合 多源数据处理
目前支持的能力包括:
使用 Spark、Flink 作为底层数据同步引擎使其具备分布式执行能力,提高数据同步的吞吐性能; 集成多种能力缩减Spark、Flink应用到生产环境的周期与复杂度; 利用可插拔的插件体系支持超过100种数据源; 引入管理与调度能力做到自动化的数据同步任务管理; 特定场景做端到端的优化提升数据同步的数据一致性; 开放插件化与 API 集成能力帮助企业实现快速定制与集成
我大概看了一下Seatunnel的设计文档和简介,是典型的插件式开发,类似DataX。
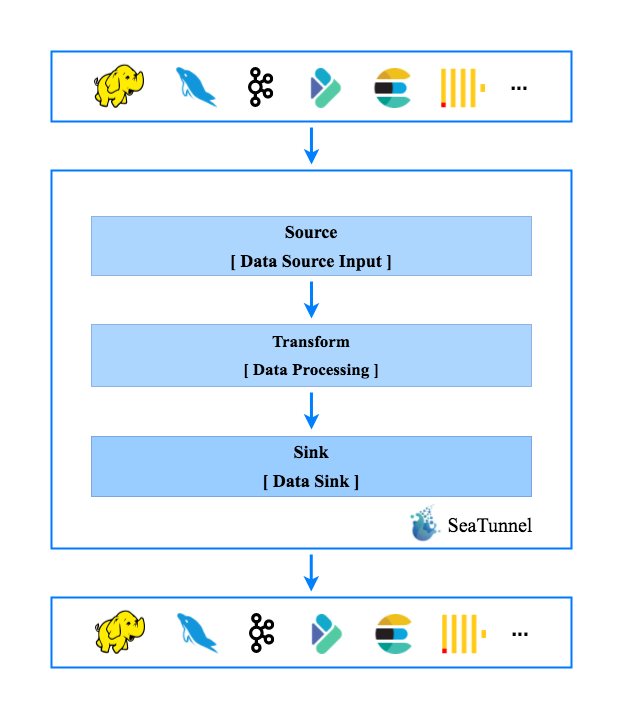
目前支持的插件如下:
Source插件:
File, Hdfs, Kafka, S3, Socket, 自行开发的 Input plugin
Filter插件
Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, 自行开发的Filter plugin
Output插件
Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, S3, Stdout, 自行开发的 Output plugin
如果你想要使用Seatunnel,那么需要满足:
java 运行环境,java >= 8
如果您要在集群环境中运行 seatunnel,那么需要以下 Spark 集群环境的任意一种:Spark on Yarn、Spark Standalone。
如果您的数据量较小或者只是做功能验证,也可以仅使用local模式启动,无需集群环境,Seatunnel支持单机运行。Seatunnel2.0支持Spark 和 Flink上运行。
实际应用
如果大家的工作中是以Spark或者Flink为主的实时计算体系,Seatunnel可以非常方便的融入你的技术体系中。
根据Seatunnel的文档显示,已经有非常多的企业在使用Seatunnel:
微博, 增值业务部数据平台 微博某业务有数百个实时流式计算任务使用内部定制版 SeaTunnel,以及其子项目Guardian 做 seatunnel On Yarn 的任务监控。
新浪, 大数据运维分析平台 新浪运维数据分析平台使用 SeaTunnel 为新浪新闻,CDN 等服务做运维大数据的实时和离线分析,并写入 Clickhouse。
搜狗 ,搜狗奇点系统 搜狗奇点系统使用 SeaTunnel 作为 ETL 工具, 帮助建立实时数仓体系
趣头条 ,趣头条数据中心 趣头条数据中心,使用 SeaTunnel 支撑 mysql to hive 的离线 ETL 任务、实时 hive to clickhouse 的 backfill 技术支撑,很好的 cover 离线、实时大部分任务场景。
一下科技, 一直播数据平台
永辉超市子公司-永辉云创,会员电商数据分析平台 SeaTunnel 为永辉云创旗下新零售品牌永辉生活提供电商用户行为数据实时流式与离线 SQL 计算。
水滴筹, 数据平台 水滴筹在 Yarn 上使用 SeaTunnel 做实时流式以及定时的离线批处理,每天处理 3~4T 的数据量,最终将数据写入 Clickhouse。
最后
你可以在这里快速了解Seatunnel:
https://interestinglab.github.io/seatunnel-docs/#/
我个人从2年前开始关注到Seatunnel这个项目,随着大数据实时数据处理方向的发展,期待Seatunnel这样的项目能够在海量数据ETL上能更上一层楼!
一些相关网站如下:
问题&建议
https://github.com/apache/incubator-seatunnel/issues
贡献代码
https://github.com/apache/incubator-seatunnel/pulls
社区开发邮件列表
dev-subscribe@seatunnel.apache.org
Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。
「PDF」就可以看到阿里云盘下载链接了!
Hi,我是王知无,一个大数据领域的原创作者。 放心关注我,获取更多行业的一手消息。
