
快递单号导出再也不费事
之前写了网易云,qq音乐,下厨房的爬虫介绍,这期写一写快递单号的爬取。N久之前,由于业务需要,我需要将一批寄出去的快递单号发送给收件人。数量有100个左右。当时就在顺丰官网上查了半天,发现还真没有一键导出按钮。于是就咨询了万能的客服。客服说我是尊敬的钻石会员,可以关注顺丰官网公众号,然后提交申请,试试有没有导出功能。我当时很纳闷,难道导出快递单这个功能大家都用不着么?
由于时间比较紧急,没空跟客服扯皮,我就开始了最原始的征途,复制粘贴。没错,每一个码农都是ctrl+c,ctrl+v的好手。而且复制粘贴也是有艺术的。登录过顺丰官网查过快递的朋友就知道了,查询页面是不能复制快递单号的,得点开详情页才能复制,这样就要不停的点击详情,再切回查询页面。此处得得瑟一下我的鼠标,带侧边按键功能,点击一下就可以返回到上一个页面,不需要移动到页面上的后退键。
保持着匀速稳定不出错的频率,我大概在30-60分钟之内,完成了复制100个快递单号并且与收件人挂钩的操作。
今天在对python爬虫有了一点点的了解的基础上,再回顾这个过程。发现那时候的自己太蠢了。(如果你不觉得过去的自己傻逼,那你这一年就没有进步了)。python的理念是,一件事情,如果你做了重复3次以上,就可以考虑用python。后面还有一句话,当然,重复2次也行。我当时能坚持重复了100次,可把我牛逼坏了,插腰。
接下来我们就进入利用python爬虫导出顺丰快递信息到excel的分享。
看过我前几期爬虫推送的朋友应该知道,我们要做的第一件事就是找网址。找到需要爬取内容的网站。
百度搜索顺丰快递官网,打开。因为需要查询我寄出的快递单号信息,所以需要右上角扫码麻溜的登录。
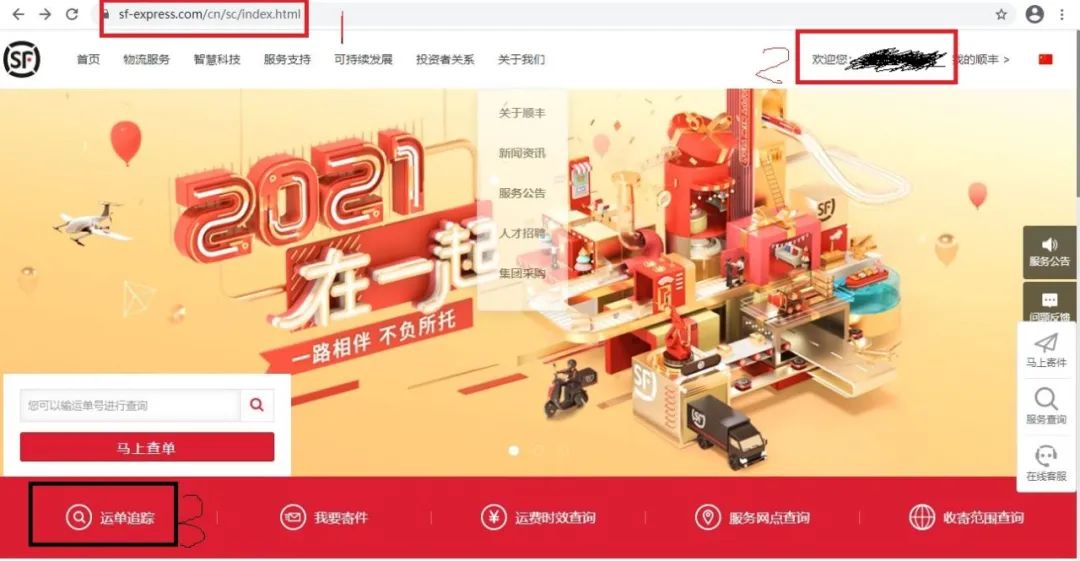
按照123的步骤,就可以成功的查询到历史的快递信息。如下图。
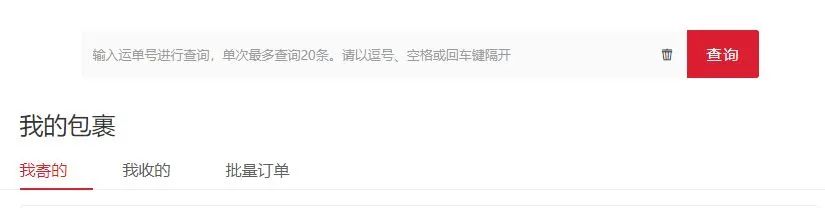
和往常一样,结果不出所料的没有拿到想要的数据。接下来开始分析网站链接。老规矩,F12进入开发者模式。刷新一下页面,可以看到有很多个请求,我们点开最上面的请求。如下:import requestsurl = 'https://www.sf-express.com/cn/sc/dynamic_function/waybill/'res = requests.get(url)print(res.status_code)print(res.text)
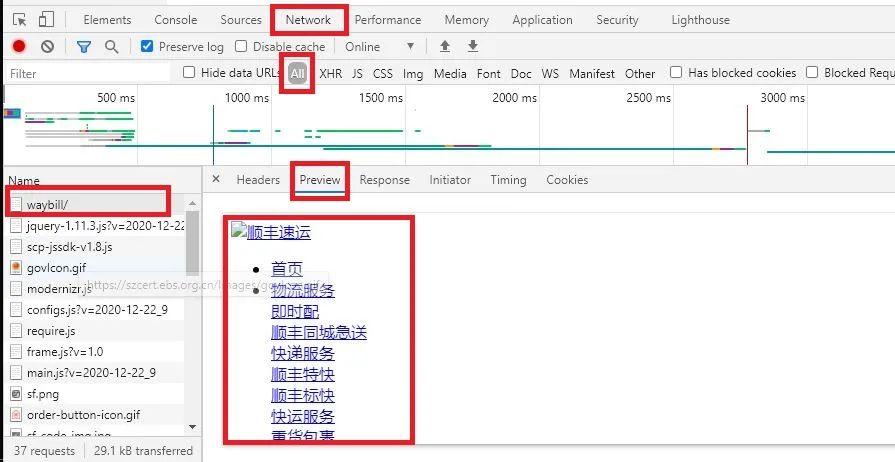
返回的并不是查询页面的内容,更像是顺丰主页的介绍。这时候就查看其他的请求。(此处有经验的爬虫工程师和新手会有差别,有经验的可以很快定位到请求的页面)我查找的时候,点击下一页发现浏览器地址没有发生变化,判断页面是动态加载出来的,所以就勾选了XHR,过滤掉其他的请求。可以看到,只有几条XHR请求,这查找起来就方便多了。
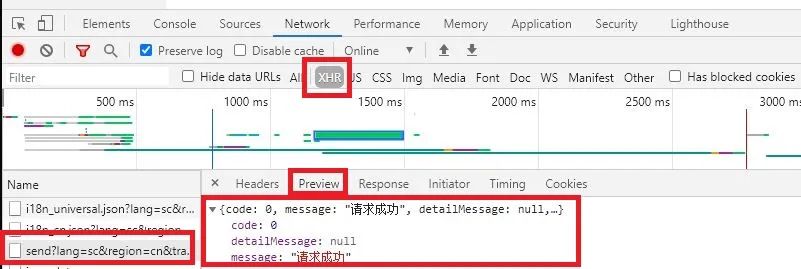
正确请求的链接就是左边框出来的,可以看到preview里面正确的返回了需要的数据。所以我们对这个页面使用request.get方法,url链接在headers里查看。
{"code":121,"message":"用户未登录","detailMessage":"用户未登录","result":null}简单介绍一下浏览器的cookie。我们在使用浏览器输入账号密码的时候经常可以看到一个选项叫记住我。如果你勾选上之后,下次再次登录,不需要输入账号密码,就可以直接登录。这是因为你的登录信息缓存在了浏览器的cookie中。再次查看headers选项卡。可以看到一串信息。我们需要的cookies也在其中。
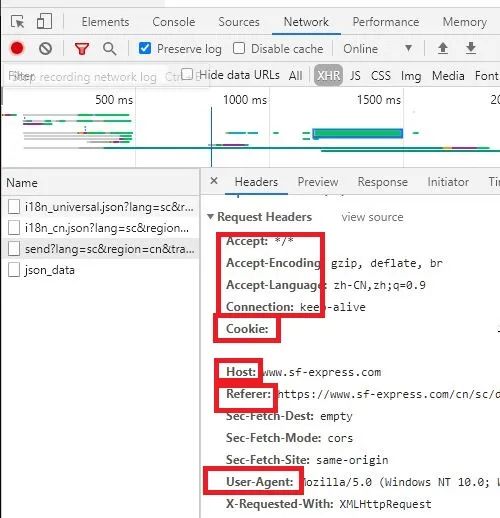
浏览器向服务器发出数据请求的时候,带上了cookie还有其他信息,让服务器知道是浏览器在操作,是我刚登录过的浏览器在操作。(cookie你可以想象为,浏览器对服务器说,是我啊,我刚才还在和你说话呢)加上这些信息就可以获取需要的数据了。此处我们完善headers信息。个人数据保护,略去cookie具体内容。
再次调用requests.get方法,加入headers参数可收到正确响应。headers = {'Connection': 'keep-alive','Cookie': '','Host': 'www.sf-express.com','Referer': 'https://www.sf-express.com/cn/sc/dynamic_function/waybill/','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',}
res = requests.get(url,headers=headers){"code":0,"message":"请求成功","detailMessage":null,"result"...
接下来的步骤就是对数据进行分析处理输出。这部分简单带过,不详细说明。可以将网页爬取的内容保存到json文件里,然后从文件里抓取需要的内容,也可以一边爬,一边同步分析数据。部分语句如下:
waybillinfos = []waybillno_list = dict['result']['content']for item in waybillno_list:waybillinfo = []waybillinfo.append(item['waybillno'])waybillinfo.append(item['originateContacts'])waybillinfo.append(item['destinationContacts'])waybillinfos.append(waybillinfo)
最后将处理好的数据输出到excel,这一步很简单,使用pandas来处理。三行代码搞定。
dataframe = pd.DataFrame(waybillinfos)dataframe.columns = ['快递单号', '寄件人', '收件人']dataframe.to_excel('result.xls',index=False)
可以看到在当前目录下多了一个excel文件,打开一看,就是我们刚才爬下来的数据。除了快递单号,寄件人,收件人之外,其他数据也是可以的。如果需要详细的物流情况,还需要爬取每一个详情页,这里不展开。

问题到这里结束了么?并没有。我们要对自己有要求。刚才使用的cookie有瑕疵。这个cookie是有时限的!我们点了记住我之后,也不是以后都不需要再输入密码的,浏览器和服务器之间的链接隔断时间就要重新来一次。
解决方案是有的。在实际需要请求数据前,先通过request方法发送登录数据,返回的数据里带有需要的cookie数据,把这个cookie保存下来。下次请求的时候带上就可以。这部分留给自己去尝试。阅读原文是git链接,代码里的cookie空着没有填,填入你的cookie就可以获取你的数据。登录后获取cookie的操作会在下一次提交更新。
不过瘾?也许你还想看:批量爬取小姐姐高清美图,批量爬取王者荣耀皮肤,登录12306自动抢票,登录淘宝自动抢鞋抢酒抢锅(混入了奇怪的东西,抢锅是什么鬼!),爬取本周热门菜谱定时发送到邮箱……别着急,我慢慢写,您呐,慢慢看。
相关文章: