Python 爬虫进阶 - 前后端分离有什么了不起,过程超详细!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
我们要抓取下面这个网站上的所有图书列表:
https://www.epubit.com/books
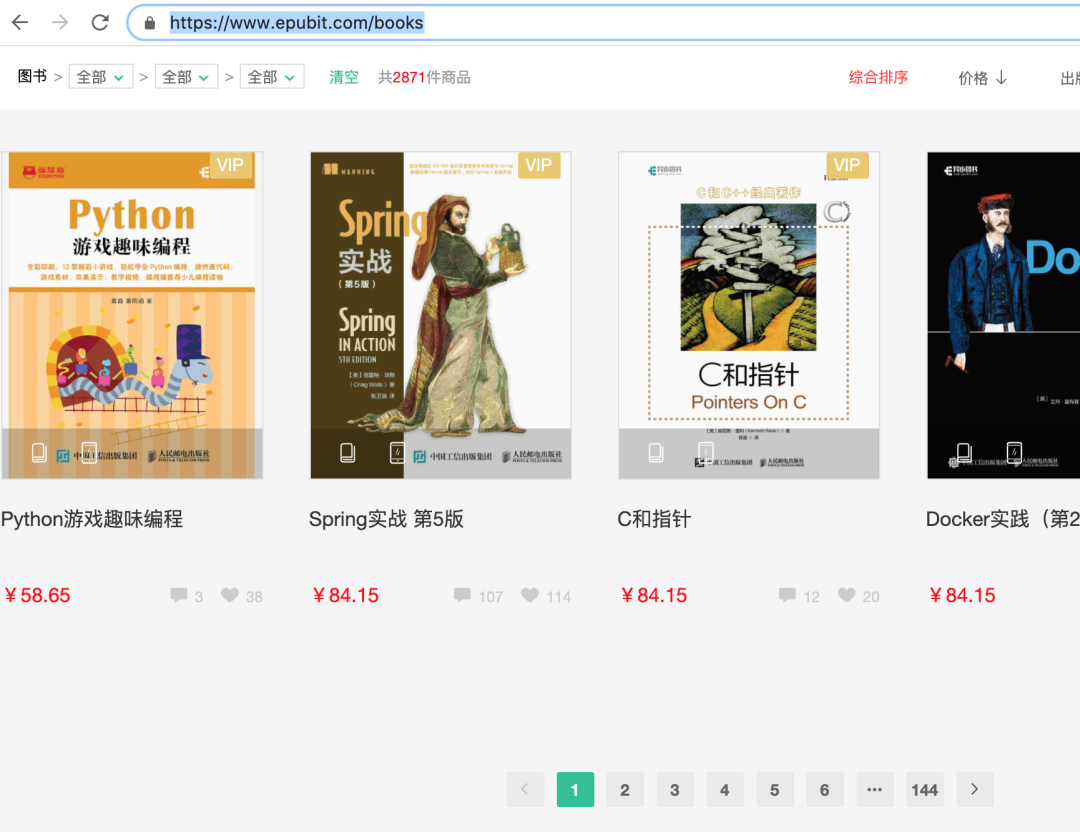
1) 探索研究
创建一个新的python文件,写入如下代码:
import requests
url = 'https://www.epubit.com/books'
res = requests.get(url)
print(res.text)
运行发现打印结果如下:
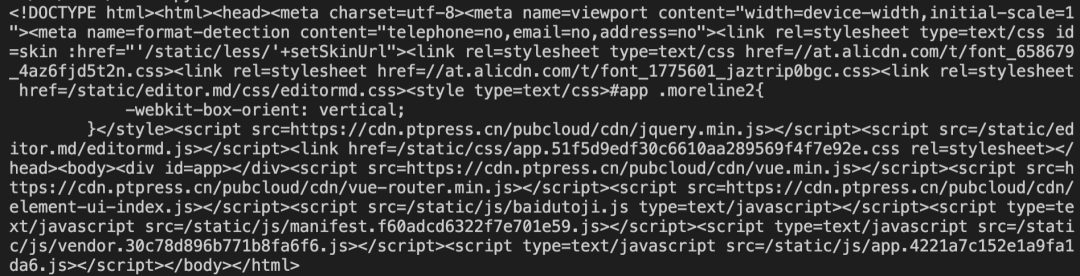
这里面根本没有图书的信息。但使用浏览器检查器可以看到图书的信息:
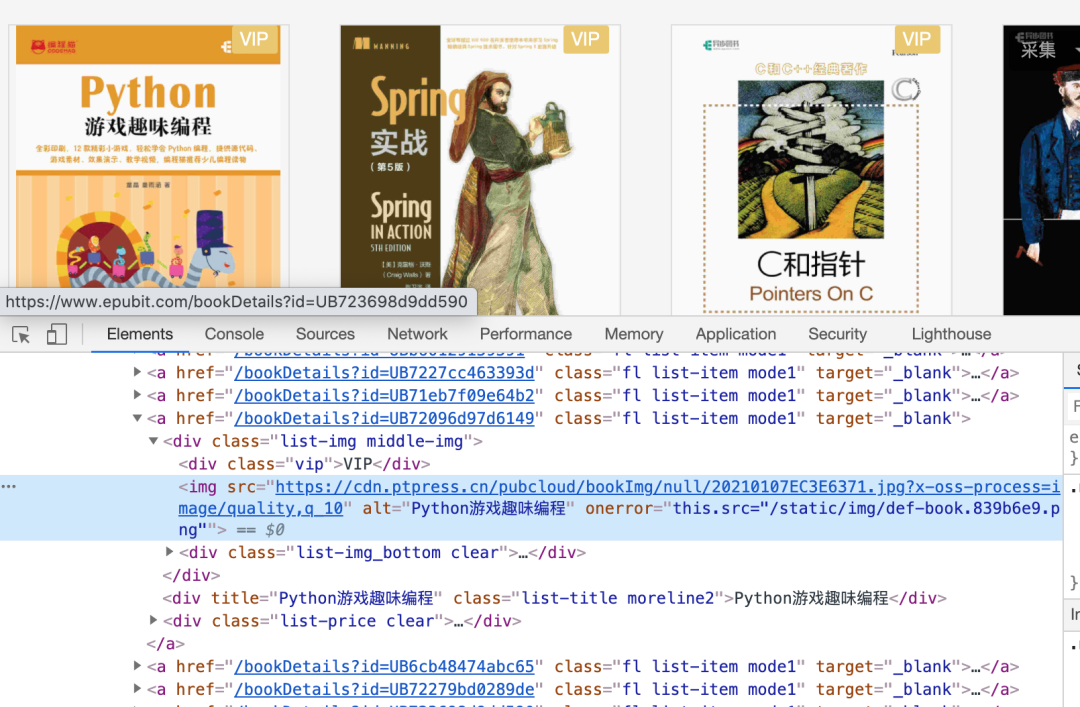
我们碰到了一个基于前后端分离的网站,或者说一个用JavaScript获取数据的网站。这种网站的数据流程是这样的:
初次请求只返回了网页的基本框架,并没有数据。就是前面截图看到那样。 但网页的基本框架中包含JavaScript的代码,这段代码会再发起一次或者多次请求获取数据。我们称为后续请求。
为了抓取这样的网站,有两个办法:
分析出后续请求的地址和参数,写代码发起同样的后续请求。 使用模拟浏览器技术,比如selenium。这种技术可以自动发起后续请求获取数据。
2) 分析后续请求
打开谷歌浏览器的检查器,按图中的指示操作: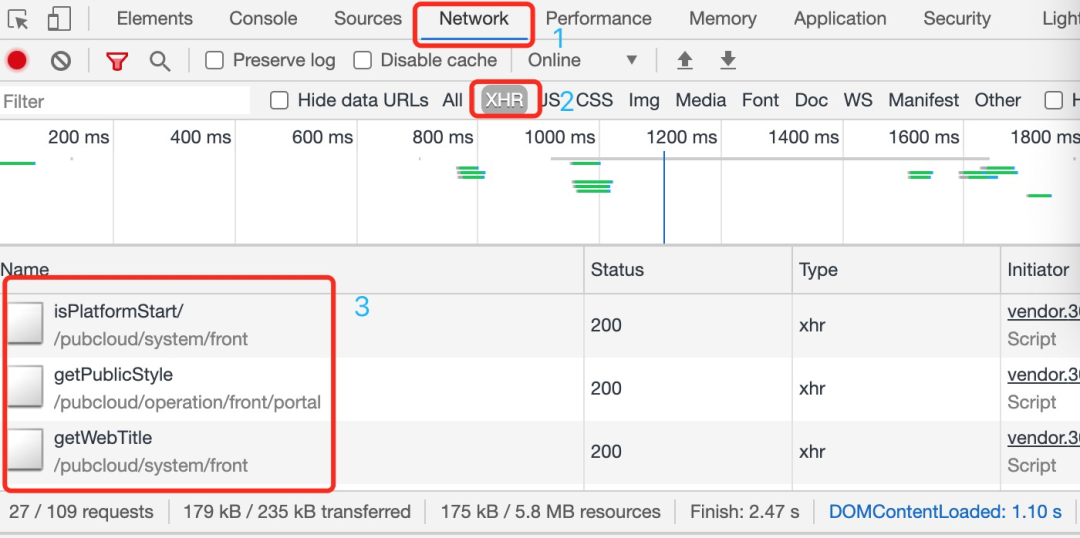
点击Network,这里可以查看浏览器发送的所有网络请求。 选XHR,查看浏览器用JavaScript发送的请求。 下面可以看到很多请求。我们要一个个看过去找到包含商品列表的请求。
再来理解一下浏览器打开一个网页的过程,一般并不是一个请求返回了所有的内容,而是包含多个步骤:
第一个请求获得HTML文件,里面可能包含文字,数据,图片的地址,样式表地址等。HTML文件中并没有直接包含图片。 浏览器根据HTML中的链接,再次发送请求,读取图片,样式表,基于JavaScript的数据等。
所以我们看到有这么不同类型的请求:XHR, JS,CSS,Img,Font, Doc等。
我们爬取的网站发送了很多个XHR请求,分别用来请求图书列表,网页的菜单,广告信息,页脚信息等。我们要从这些请求中找出图书的请求。
具体操作步骤如图: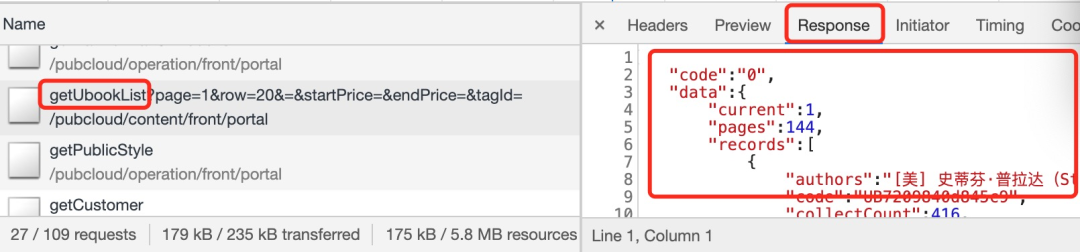
在左边选中请求 在右边选择Response 下面可以看到这个请求返回的数据,从数据可以判断是否包含图书信息。
Javascript请求返回的格式通常是JSON格式,这是一种JavaScript的数据格式,里面包含用冒号隔开的一对对数据,比较容易看懂。JSON很像Python中的字典。
在众多的请求中,可以根据请求的名字大致判断,提高效率。比如上图中getUBookList看起来就像是获取图书列表。点开查看,返回的果然是图书列表。
请记住这个链接的地址和格式,后面要用到:

https://www.epubit.com/pubcloud/content/front/portal/getUbookList?page=1&row=20&=&startPrice=&endPrice=&tagId=
分析一下,可以看到:
网址是:https://www.epubit.com/pubcloud/content/front/portal/getUbookList page=1表示第1页,我们可以依次传入2,3,4等等。 row=20表示每一页有20本书 startPrice和endPrice表示价格条件,他们的值都是空,表示不设定价格限制。
3) 使用postman测试猜想
为了验证这个设想打开谷歌浏览器,在地址栏中输入以下网址:
https://www.epubit.com/pubcloud/content/front/portal/getUbookList?page=1&row=20&=&startPrice=&endPrice=&tagId=
可是得到了如下的返回结果:
{
"code": "-7",
"data": null,
"msg": "系统临时开小差,请稍后再试~",
"success": false
}
这并不是系统出了问题,而是系统检测到我们是非正常的请求,拒绝给我们返回数据。
这说明除了发送这个URL,还需要给服务器传送额外的信息,这些信息叫做Header,翻译成中文是请求头的意思。
在下图中可以看到正常的请求中包含了多个请求头: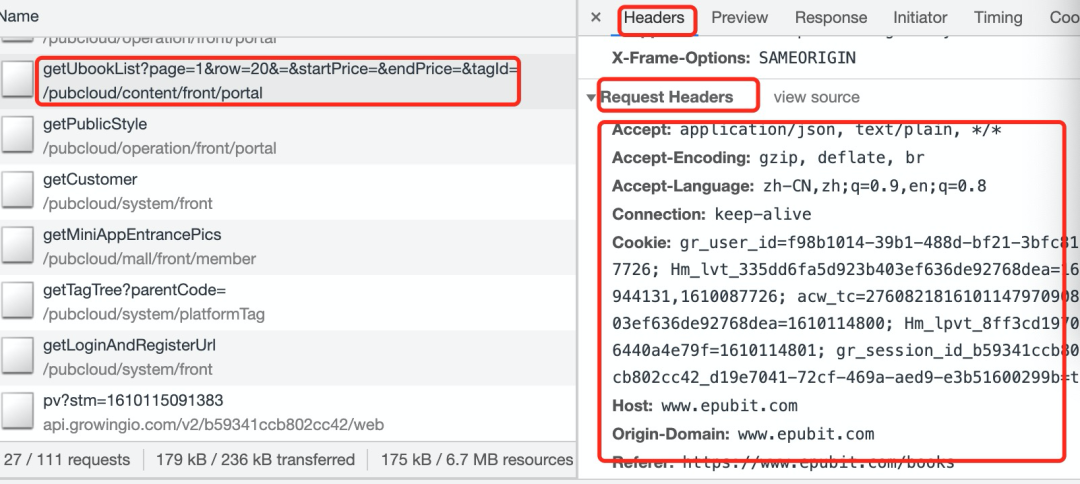
选中要查看的请求 在右边选Headers 往下翻,可以看到Request Headers,下面就是一项项数据: Accept: application/json, text/plain, / Accept-Encoding:gzip, deflate, br ....
为了让服务器正常处理请求,我们要模拟正常的请求,也添加相应的header。如果给的Header也都一样,服务器根本不可能识别出我们是爬虫。后面我们会学习如何在发送请求时添加header。
但通常服务器并不会检查所有的Header,可能只要添加一两个关键Header就可以骗服务器给我们数据了。但我们要一个个测试那些Header是必须的。
在浏览器中无法添加Header,为了发送带Header的HTTP请求,我们要使用另一个软件叫做Postman。这是一个API开发者和爬虫工程师最常使用的工具之一。
首先在postman的官网下载:www.postman.com。根据指示一步步安装软件,中间没有额外的设置。
打开postman后可以看到如下界面:
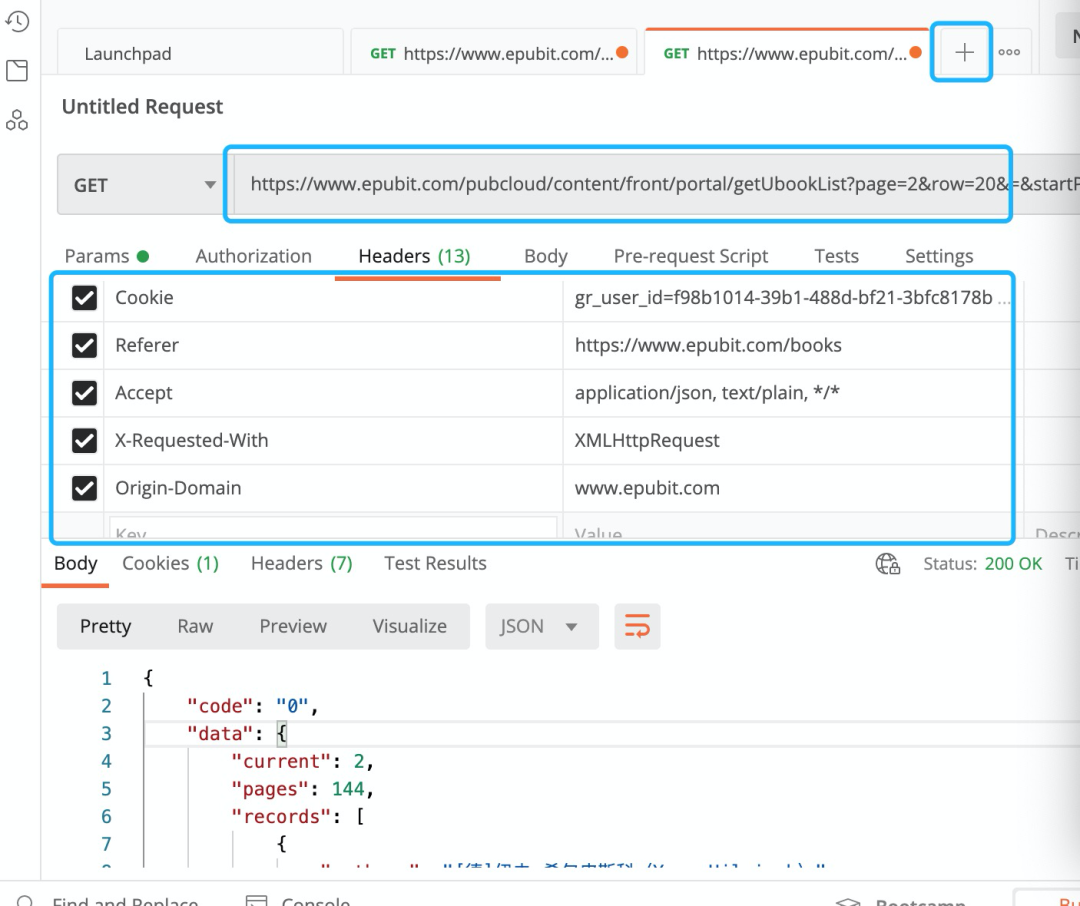
在最上面点击加号,可以添加一个新的请求 中间填写请求的URL 点Headers进入Headers的设置界面,添加Header。
这些Header的名字和值可以在检查器中复制过来。如果自己拼写,注意千万不要写错。
我们来了解一下几个常见的header:
User-Agent: 这个Header表示请求者是谁,一般是一个包括详细版本信息的浏览器的名字,比如:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
如果爬虫不添加这个Header,服务器一下就能识别出这是不正常请求,可以予以拒绝。当然,是否拒绝取决于程序员的代码逻辑。
Cookie: 如果一个网站需要登录,登录的信息就保存在Cookie中。服务器通过这个Header判定是否登陆了,登陆的是谁。
假设我们要自动在京东商城下单,我们可以先人工登录,复制Cookie的值,用Python发送请求并包含这个Cookie,这样服务器就认为我们已经登陆过了,允许我们下单或做其他操作。如果在程序中加上计时的功能,指定具体下单的时间点,这就是秒杀程序。这是爬取需要登录的网站的一种常用方法。
Accept:指浏览器接受什么格式的数据,比如**application/json, text/plain, */***是指接受JSON,文本数据,或者任何数据。
Origin-Domain: 是指请求者来自那个域名,这个例子中是:www.epubit.com
关于更多的HTTP的Header,可以在网上搜索HTTP Headers学习。
我一个个添加常用的Header,但服务器一直不返回数据,直到添加了Origin-Domain这个Header。这说明这个Header是必备条件。
网页的后台程序有可能不检查Header,也有可能检查一个Header,也有可能检查多个Header,这都需要我们尝试才能知道。
既然Origin-Domain是关键,也许后台程序只检查这一个Header,我们通过左边的选择框去掉其他的Header,只保留Origin-Domain,请求仍然成功,这说明后台只检查了这一个Header:
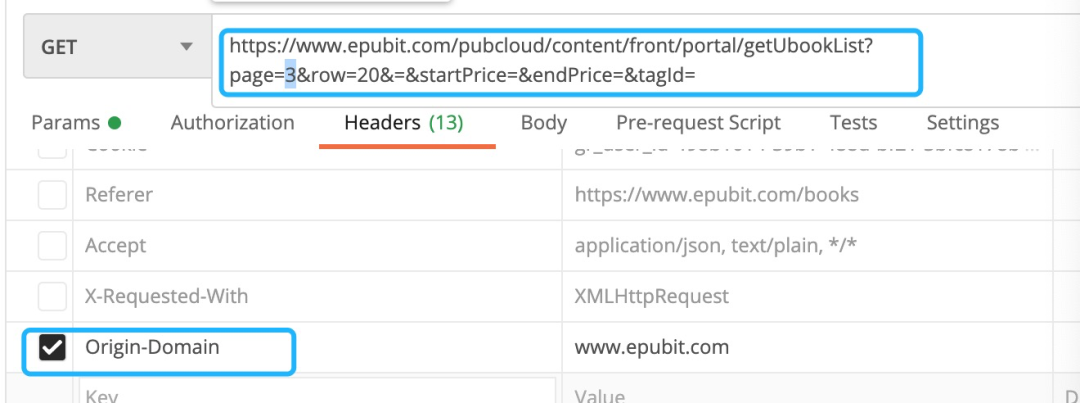
然后修改地址栏中的page参数,获取其他的页,比如截图中修改成了3,再发送请求,发现服务器返回了新的数据(其他的20本书)。这样我们的请求过程就成功了。
4) 写抓取程序
开发爬虫,主要的时间是分析,一旦分析清楚了,爬取代码并不复杂:
import requests
def get_page(page=1):
'''抓取指定页的数据,默认是第1页'''
# 使用page动态拼接URL
url = f'https://www.epubit.com/pubcloud/content/front/portal/getUbookList?page={page}&row=20&=&startPrice=&endPrice=&tagId='
headers = {'Origin-Domain': 'www.epubit.com'}
# 请求的时候同时传入headers
res = requests.get(url, headers=headers)
print(res.text)
get_page(5)
这里我们测试了抓取第5页的数据,比对打印出的JSON数据和网页上的第5页数据,结果是匹配的。
现在我们去分析JSON的数据结构,再来完善这个程序。
5) 分析JSON数据
JSON就像Python中的字典,用大括号存放数据,用冒号分割键和值。下面是省略的JSON数据:
{
"code": "0",
"data": {
"current": 1, //第一页
"pages": 144, //一共几页
"records": [ //很多本书的信息放在方括号中
{
"authors": "[美] 史蒂芬·普拉达(Stephen Prata)", //作者
"code": "UB7209840d845c9", //代码
"collectCount": 416, //喜欢数
"commentCount": 64, //评论数
"discountPrice": 0, //折扣价
"downebookFlag": "N",
"fileType": "",
...
},
{
"authors": "笨叔",
"code": "UB7263761464b35",
"collectCount": 21,
"commentCount": 3,
"discountPrice": 0,
"downebookFlag": "N",
"fileType": "",
...
},
...
],
"size": 20,
"total": 2871
},
"msg": "成功",
"success": true
}
我们来学习一下这个JSON格式:
最外面是一个大括号,里面包含了code, data, msg, success四块信息。这个格式是开发这个网页的程序员自己设计的,不同的网页可能不同。 其中code, msg和sucess表示请求的状态码,请求返回的提示,请求是否成功。而真正的数据都在data中。 data的冒号后面是一个大括号,表示一个数据对象。里面包含了当前页数(current),总页数(pages),书的信息(records)等。 records表示很多本书,所以它用一个方括号表示,方括号里面又有很多大括号包起来的数据对象,每个大括号表示一本书。
{
"authors": "[美] 史蒂芬·普拉达(Stephen Prata)", //书名
"code": "UB7209840d845c9", //代码
"collectCount": 416, //喜欢数
"commentCount": 64, //评论数
"discountPrice": 0, //折扣0,表示没有折扣
...
"forSaleCount": 3, //在售数量
...
"logo": "https://cdn.ptpress.cn/pubcloud/bookImg/A20190961/20200701F892C57D.jpg",
"name": "C++ Primer Plus 第6版 中文版", //书名
...
"price": 100.30, //价格
...
}
每本书的信息有很多个字段,这里省略掉了很多字段,给重要的信息添加了注释。
6) 完成程序
现在来完善上面的程序,从JSON中解析出我们要的数据,为了简化,我们只抓取:书名,作者,编号和价格。
程序框架:
import requests
import json
import time
class Book:
# --省略--
def get_page(page=1):
# --省略--
books = parse_book(res.text)
return books
def parse_book(json_text):
#--省略--
all_books = []
for i in range(1, 10):
print(f'======抓取第{i}页======')
books = get_page(i)
for b in books:
print(b)
all_books.extend(books)
print('抓完一页,休息5秒钟...')
time.sleep(5)
定义了Book类来表示一本书 添加了parse_book函数负责解析数据,返回包含当前页的20本书的list 最下面使用for循环抓取数据,并放到一个大的列表中,range中添加要抓取的页数。通过前面的分析可以知道一共有几页。 抓取完一页后,一定要sleep几秒,一是防止给网站带来太大压力,二是防止网站会封锁你的IP,是为他好,也是为了自己好。 把抓来的信息保存到文件中的代码,请自行完成。
下面来看看,被省略掉的部分:
Book类:
class Book:
def __init__(self, name, code, author, price):
self.name = name
self.code = code
self.author = author
self.price = price
def __str__(self):
return f'书名:{self.name},作者:{self.author},价格:{self.price},编号:{self.code}'
下面是__str__函数是一个魔法函数,当我们使用print打印一个Book对象的时候,Python会自动调用这个函数。
parse_book函数:
import json
def parse_book(json_text):
'''根据返回的JSON字符串,解析书的列表'''
books = []
# 把JSON字符串转成一个字典dict类
book_json = json.loads(json_text)
records = book_json['data']['records']
for r in records:
author = r['authors']
name = r['name']
code = r['code']
price = r['price']
book = Book(name, code, author, price)
books.append(book)
return books
在最上面import了json模块,这是Python自带的,不用安装 关键的代码就是使用json把抓来的JSON字符串转成字典,剩下的是对字典的操作,就很容易理解了。
抓取基于 JavaScript 的网页,复杂主要在于分析过程,一旦分析完成了,抓取的代码比 HTML 的页面还要更简单清爽!
如果觉得好,建议:点赞,再看,加转发!
见面礼
扫码加我微信备注「三剑客」送你上图三本Python入门电子书
推荐阅读
点分享 点收藏 点点赞 点在看