
为什么 Java 不采用 Redis 这种渐进式 rehash?
Redis 中的 hash 扩容是渐进式 rehash,这个扩容过程和我们 Java 中的 HashMap 有很大不同。那么在面试过程中,很多面试官喜欢问,为什么 Java 不采用 Redis 这种渐进式 rehash 呢?
借这个周末的空闲时间,我们先来看看 Redis 是如何进行渐进式 rehash,然后再回答大家,Java 为什么不采用 Redis 这种渐进式 rehash。
Redis 中的 rehash 过程
redis 字典(hash 表)当数据越来越多的时候,就会发生扩容,也就是 rehash。
对比 Java 中的 hashmap,当数据数量达到阈值的时候(0.75),就会发生rehash,hash 表长度变为原来的二倍,将原 hash 表数据全部重新计算 hash 地址,重新分配位置,达到 rehash 目的。
redis 中的 hash 表采用的是渐进式 hash 的方式。
redis 字典(hash 表)底层有两个数组,还有一个 rehashidx 用来控制rehash。
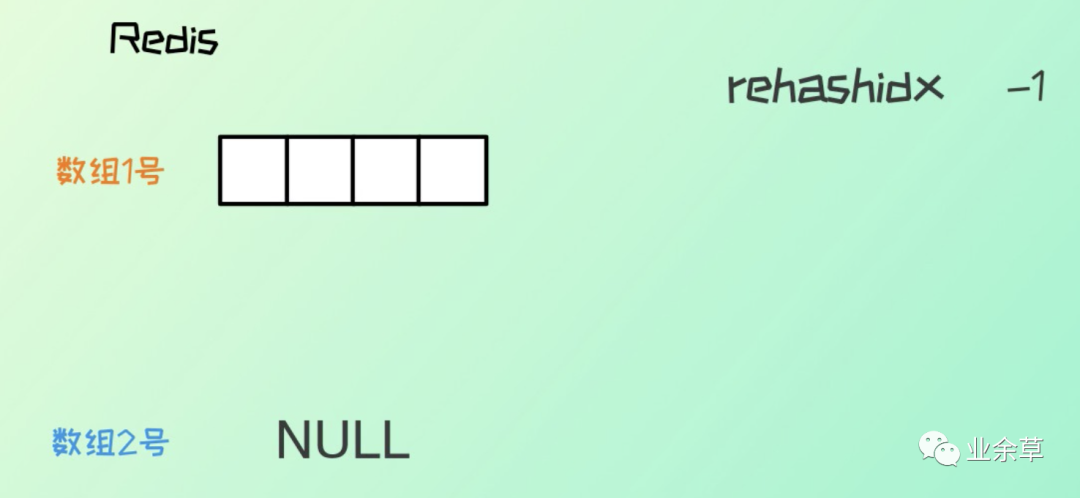

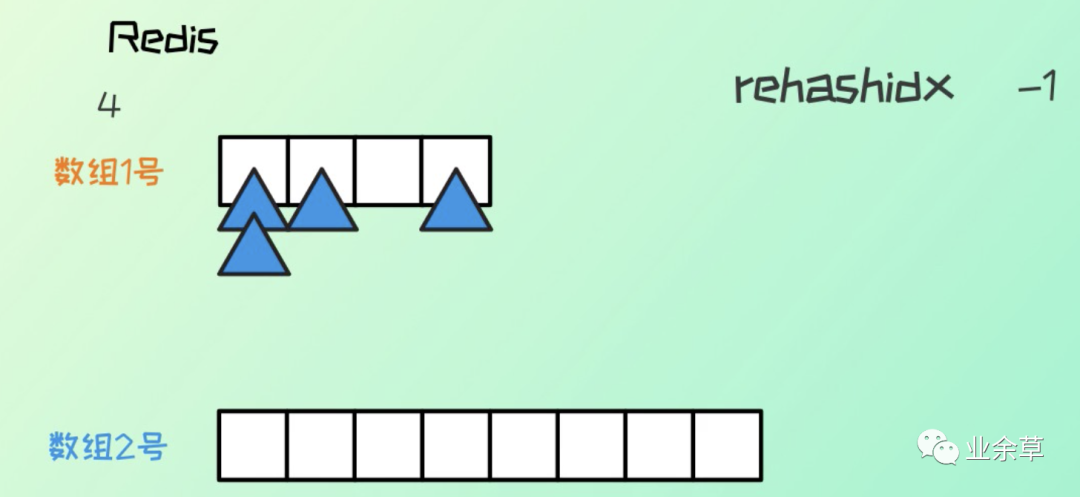
初始默认 hash 长度为 4,当元素个数与 hash 表长度一致时,就发生扩容,hash 长度变为原来的二倍。
redis 中的 hash 则是执行的单步 rehash 的过程。
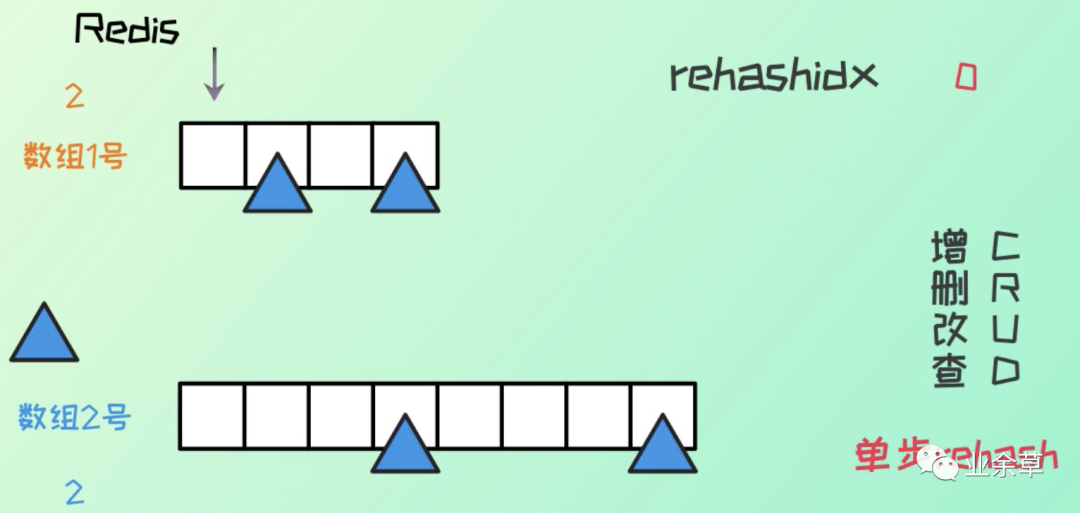
每次的增删改查,rehashidx + 1,然后执行对应原 hash 表 rehashidx 索引位置的 rehash。
总结
在扩容和收缩的时候,如果哈希字典中有很多元素,一次性将这些键全部 rehash 到ht[1]的话,可能会导致服务器在一段时间内停止服务。所以,采用渐进式 rehash 的方式,详细步骤如下:
为
ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表将
rehashindex的值设置为0,表示rehash工作正式开始在 rehash 期间,每次对字典执行增删改查操作是,程序除了执行指定的操作以外,还会顺带将
ht[0]哈希表在rehashindex索引上的所有键值对 rehash 到ht[1],当 rehash 工作完成以后,rehashindex的值+1随着字典操作的不断执行,最终会在某一时间段上
ht[0]的所有键值对都会被 rehash 到ht[1],这时将rehashindex的值设置为-1,表示 rehash 操作结束。
渐进式 rehash 采用的是一种分而治之的方式,将 rehash 的操作分摊在每一个的访问中,避免集中式 rehash 而带来的庞大计算量。
需要注意的是在渐进式 rehash 的过程,如果有增删改查操作时,如果index大于rehashindex,访问ht[0],否则访问ht[1]。
Java 为什么不采用渐进式 rehash?
jdk 中的 HashMap 的重排过程没有采用渐进的方法。尽管 Jdk HashMap 的重新哈希计算非常优雅和有效,但是当原始 HashMap 中的元素数量包含许多条目时,仍然需要花费大量时间。
像 Redis 这样的渐进式哈希可以有效地将工作负载均匀分配,这可以显着减少调整大小/哈希的时间。
那么 Java 为什么不用呢?
因为,如果考虑类似的增量重新哈希的成本和收益,通过国外网友对 HashMap 的实验,证明这些成本并不是微不足道的,收益也并不理想。
逐步重新哈希 HashMap:
平均使用 50% 以上的内存,因为它需要在增量重新哈希期间保留旧表和新表。 每次操作的计算成本较高。 重新哈希仍然不是完全增量的,因为分配新哈希表数组必须一次完成。 任何操作的渐进复杂性都没有改善。 由于无法预测的 GC 暂停,几乎完全不需要增量哈希的任何事情都可以在 Java 中实现,那么为什么要麻烦呢?
以上就是 Java 不采用渐进式 rehash 的原因。如果你也有其他理由或想法,欢迎留言 + 点赞 + 转发!