
Pandas 还能这么玩儿?这样排序才叫真功夫!

标签:排序
时间:2019 年 12 月 31 日,晚 9 点
地点:XXX 公司 数据分析部 办公室
龙少终于完成了年终分析报表,把邮件发给了严总,正收拾东西打卡回家,突然,叮铃铃……,手机响了,“怎么是严总的电话!”,龙少心里一紧,但也不能不接,别看严总岁数比龙少小,但平时的严厉可是名副其实。
刚一接通,电话那头就传来严总一通霹雳巴拉的责问,“你这表怎么搞的,知不知道北京、上海、广州是咱们最重要的分公司,要把这几家摆在前面,不能按拼音顺序显示,这样让人怎么看!细节决定成败!懂不懂!!!赶紧改!!!” 说完,严总就挂了电话,龙少本已穿上羽绒服开始冒汗的身体,犹如被屋外的寒风一样吹了个透心凉。
龙少心想,这 Pandas 提供的 sort_index() 也好,sort_values() 也罢,都不支持自定义排序啊,天啊,严总,你没女朋友,可以全情投入工作,我还想赶紧回家陪老婆娃娃过新年呢。咋整,求助呆鸟吧。
呆鸟云:“为了帮龙少实现赶紧回家老婆孩子热炕头的愿望,呆鸟总结了 Pandas 几种自定义排序方法:
自定义索引排序
自定义列值排序
利用辅助列实现自定义列值排序
自定义列序
掌握了这几种方式,就能更灵活的排序,这才叫排序真功夫。”
0. 准备工作
导入 Pandas:
import pandas as pd
导入数据,销售数据放在 data/自定义排序.xlsx 的 销售数据 表里,在导入时,把序号列设为索引。
sales = pd.read_excel("data/自定义排序.xlsx","销售数据",index_col="序号")

1. 自定义索引排序
要是数据量不多,可以尝试一下自定义索引排序。
只需提供索引列表,用 reindex() 就能重设数据排序。
reorder = [4,8,9,1,5,7,2,6,3]
sales.reindex(reorder)

看到了吗,上图就是我们想排列数据的顺序,分公司按北京、上海、广州、深圳排序,门店按一店、二店、三店排序。
虽然只有 9 条数据,但这种一个一个写索引,呆鸟已经看的头晕眼花了,这要再多点,更受不了了,显然,数据量稍微多一些,这种方式就不适合了。
2. 自定义列值排序
下面,我们学习一种更简单,更直观的方式。
这里的原理是把列转换为类别型,通过指定类别排序,按列值排序。
sales['分公司'] = pd.Categorical(sales['分公司'], categories=[
'北京', '上海', '广州', '深圳'], ordered=True)
sales.sort_values(by='分公司')
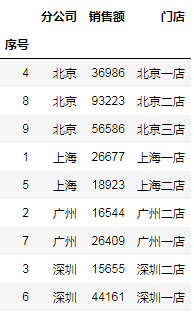
这样很方便地就实现了按分公司排列,但并未实现门店列的排序,比如,广州与深圳的二店排在了一店前面。
虽然,也可以把门店列改为类别型,但门店很多就不直观了,因此,我们再引入一种方式。
同时,也请注意,类似这种分公司与门店名称的排序,要在设计数据库时提供分公司与门店代码,在数据导出时也要导出相应代码,代码依据规律创建,在排序时就可以用上。
如果代码规律与排序规律还是不一致,就只好自行维护一套自定义规律表了。
3. 利用辅助列实现自定义列值排序
首先,要导入自定义的分公司与门店代码表。
这两个表分别放在了自定义排序的 Excel 文件里,如果从数据库导出的文件较大,推荐单独放在一个 Excel 文件里,避免打开大文件效率低。
branch = pd.read_excel('data/自定义排序.xlsx','分公司代码')
department = pd.read_excel('data/自定义排序.xlsx','门店代码')
然后,把为分公司与门店匹配对应的代码,这个操作,类似 Excel 的 vlookup()。
sales = pd.merge(sales, branch, on="分公司", how="left")
sales = pd.merge(sales, department, on="门店",how="left")
这里简要说明一下 merge(),
sales 是 left ~ 左,因为 sales 放在左边;
branch 或 department 是 right ~ 右,因为这两个 df 放在了右边,瞧,就是这么简单;
on="分公司",以两个 df 的
分公司列为依据,进行合并;how="left",如何 merge,以左边的为主,还可以写
right、outer、inner,分别表示按右边的 df、两个 df 的并集、两个 df 的交集;
merge() 还有其它参数,这里先不多说,有兴趣的朋友可以去看下 Pandas 官档里关于 merge() 的说明。
现在,用 sort_values(),就可以实现自定义排序了。
sales.sort_values(['分公司代码','门店代码'],inplace=True)
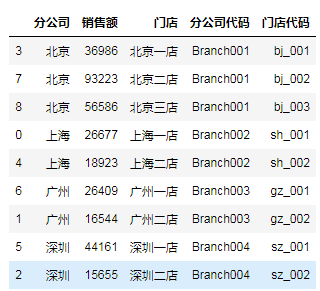
看到了吗?行序已经按要求排好了。
4. 自定义列序
至此,列序还有些乱,严总看了,肯定又会批评不注意细节了,还要按以下顺序重排列序:分公司代码、分公司、门店代码、门店、销售额。
Pandas 的 sort_index() 可以实现按列名排序,但对中文不友好不说,还不支持自定义排序:
sales.sort_index(axis='columns',ascending=True)
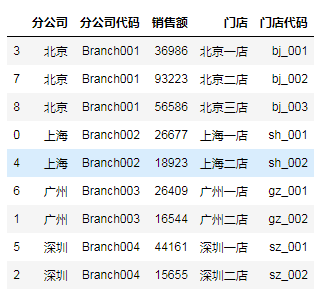
从上面的列子可以看到,sort_index() 只支持按字母或数字排序,不支持自定义列排序,咱们还得想办法。
其实很简单!
sales = sales[['分公司代码', '分公司', '门店代码', '门店', '销售额']]
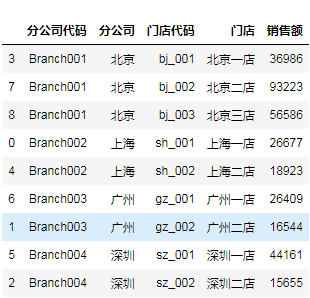
至此,列序也排好了,但这就完了吗?
如果这样给严总,肯定还会挨批!
为什么呢?
大家看下 index, 也就是索引序号,是不是乱序的?另外,对严总来说,他并不关心这些代码,这些只是冗余信息,影响他看数据的效率与效果,也应该去掉。
# 删掉没用的列
del sales['分公司代码'], sales['门店代码']
# 重置索引
sales.reset_index(drop=True,inplace=True)
这里说明一下 reset_index():
drop=True,代表不保留原来的索引,如果是False,就会在生成的新 df 里保留原来的索引。inplace=True,代表直接在这个 df 里重置索引,无需生成新的 df。
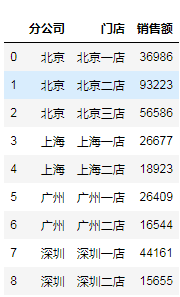
到此为止,这个简单的小表,已经完工了。
龙少又学了几招,终于在 10 点前把新的年度销售表交给了严总,严总也没再提出什么异议。龙少对呆鸟说:“这方法真是不错,省了我大事啦,改天我请你吃饭!”,呆鸟云:“吃饭就免啦,多帮我把文章转转朋友圈,点点在看就好啦。另外,我接的广告,也看一下,我的文章可都是费心写的,也不收费,就靠广告金主大佬施舍点午饭钱,要不我就白忙活啦。”
龙少说:“转朋友圈,点在看,看广告,都是举手之劳,小事一桩!”
就在此时,严总的声音也在空中回荡:“转朋友圈,点在看,看广告,别让呆鸟当白劳!”
龙少一看严总回公司了,赶紧来了句“严总,2020,新年快乐”,就速速溜了。
最后,再总结下:
数据量少,可以直接写自定义列表,用
reindex()重排行序;单列,且列中唯一值少,适合改为类别型,用类别值排序;
多列,或列中唯一值较多,可以做辅助列自定义排序;
列排序,按列名写个自定义列表就可以了。
希望大家有所收获,感谢龙少、严总友情出演。
相关阅读: